简介
Elasticsearch (ES) 是一个基于 Lucene 的搜索引擎,分词器是其核心组件之一,负责对文本数据进行分析和处理。
1. 文本分析
分词器将输入的文本拆分成一个个单独的词(tokens),以便后续的索引和搜索。例如,输入的文本 "Elasticsearch分词器" 可能会被分词器拆分为 ["Elasticsearch", "分词器"]。2. 索引优化
在将文档存储到 Elasticsearch 中之前,分词器可以去除一些不必要的字符和停用词(如“的”、“是”等),并将文本标准化(例如小写化)。这有助于减少索引的大小和提高搜索效率。3. 多语言支持
Elasticsearch 支持多种语言的分词器,例如中文分词器、英文分词器等。不同的分词器使用不同的规则和算法来处理特定语言的文本,以便提供更精确的搜索结果。4. 提升搜索质量
通过有效的分词,分词器可以提高搜索的相关性和准确性。分词器能够识别出用户查询中的关键词,并将其与索引中的词进行匹配,从而提高搜索结果的质量。5. 分析文本数据
分词器还可以用于分析文本数据的特点,比如词频统计、短语提取等。这对后续的数据挖掘和分析工作非常重要。6. 自定义分词
Elasticsearch 允许用户自定义分词器,开发者可以根据具体需求定义分词规则和过滤器,以满足特定场景的需求。7. 创建和配置索引
在创建索引时,可以指定使用的分词器。根据文档类型或应用场景的不同,可以选择不同的分词器来满足需求。
常见的分词器
Elasticsearch 提供了多种分词器(analyzers)以支持不同类型的文本分析和搜索需求。以下是一些常见的分词器:1. 标准分词器(Standard Analyzer)
这是 Elasticsearch 默认的分词器,适用于大多数语言。它会将文本分割为单词,并去除停用词(如“的”、“是”等)。2. 中文分词器
IK Analyzer:一个流行的中文分词插件,支持细粒度和粗粒度两种分词模式,适合处理中文文本。
HanLP:另一种中文分词器,支持多种自然语言处理功能,包括分词、词性标注等。3. Whitespace 分词器
将输入文本按空白字符进行分词,适合处理不需要复杂分析的情况。4. Keyword 分词器
将整个输入文本视为一个单一的词,适用于需要精确匹配的场景,如 ID 和特定标签。5. NGram 分词器
生成输入文本的 N-gram 形式,适合用于模糊搜索和自动补全功能。6. Path Hierarchy 分词器
适用于处理文件路径和层级结构数据,能够正确分词层级关系。7. Edge NGram 分词器
仅生成输入文本的前 N 个字符的 N-gram,适合用于前缀匹配的搜索场景。8. Stop Token 分词器
用于去除常见的停用词,这些词通常不会对搜索结果产生实质性影响。9. Custom Analyzer
用户可以根据需求自定义分词器,组合不同的分词和过滤器,以满足特定的分析需求。
中文分词器 ik
默认的分词器是标准分词器,它会将文本分割为单词,并去除停用词(如“的”、“是”等),在生产实际使用过程中,是不符合国内的业务的
所以我们需要引入中文分词器 ik
- IK Analyzer:一个流行的中文分词插件,支持细粒度和粗粒度两种分词模式,适合处理中文文本。
安装步骤
注意:安装的版本需要跟es的版本保持一致,我这里使用的7.3.2的
下载
- 方式一:如果需要的ik是7.3.2 ,否则可以选择其他的方式
- 公众号获取,回复
ik<font style="color:rgb(26, 27, 28);">分词器</font>

- 方式二:github下载
https://github.com/infinilabs/analysis-ik/tags
找到自己需要的版本
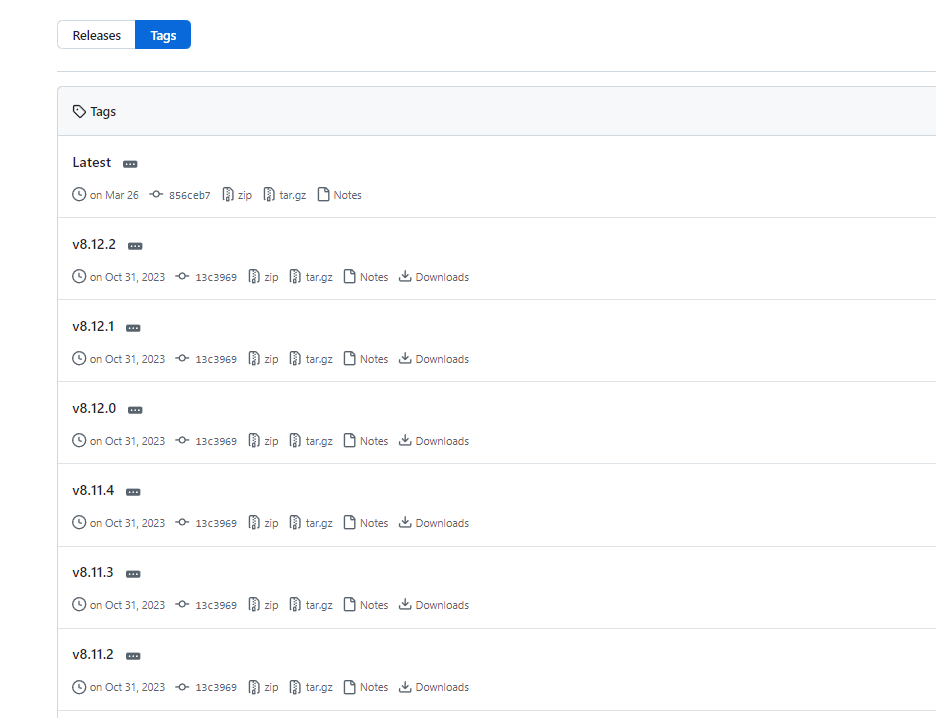
例如我需要下载v7.3.2

下载zip的方式
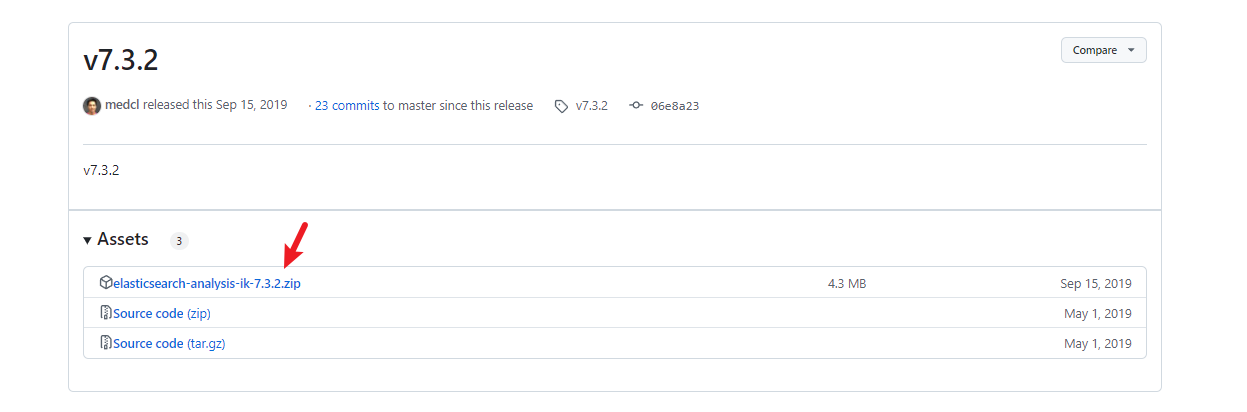
上传,解压
# 切换到es下的plugins 这里根据自己es的安装目录
cd elasticsearch-7.3.2/plugins
# 上传
rz
# 解压
unzip elasticsearch-analysis-ik-7.3.2.zip -d ik
# 删除压缩包,否则启动会报错
rm -rf elasticsearch-analysis-ik-7.3.2.zip
重启es
ps -ef|grep elasticsearch查看es的pid

- 杀死程序 kill -9 pid
- 进入es的bin目录,执行
./elasticsearch -d
分词测试
使用kibana进行查看
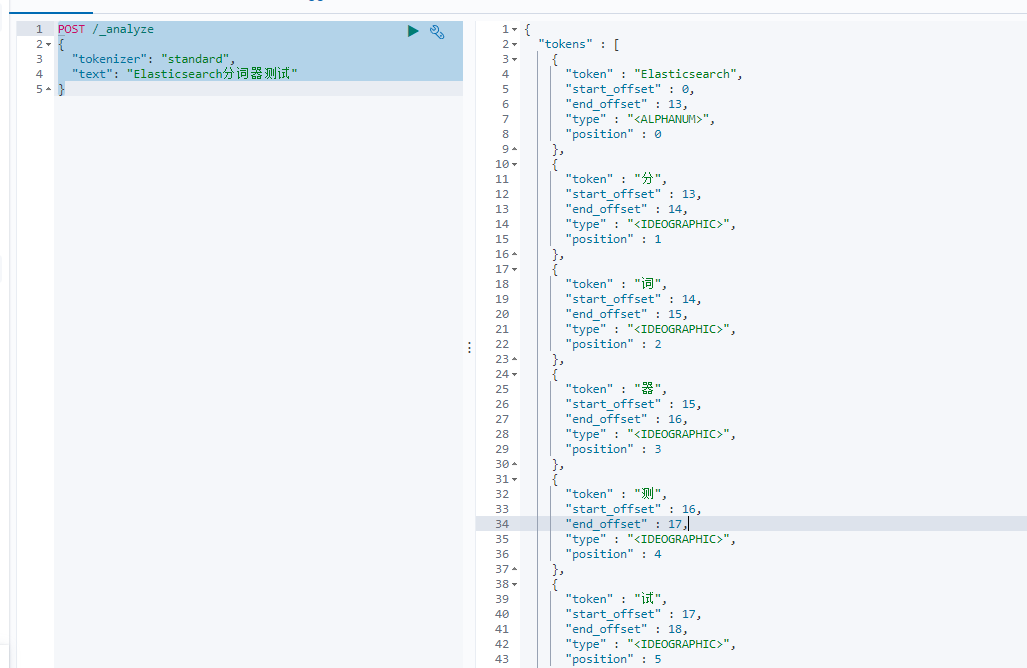
- 标准分词器测试
POST /_analyze
{"tokenizer": "standard", "text": "Elasticsearch分词器测试"
}
- ik分词器测试
POST /_analyze
{"tokenizer": "ik_max_word","text": "Elasticsearch分词器测试"
}
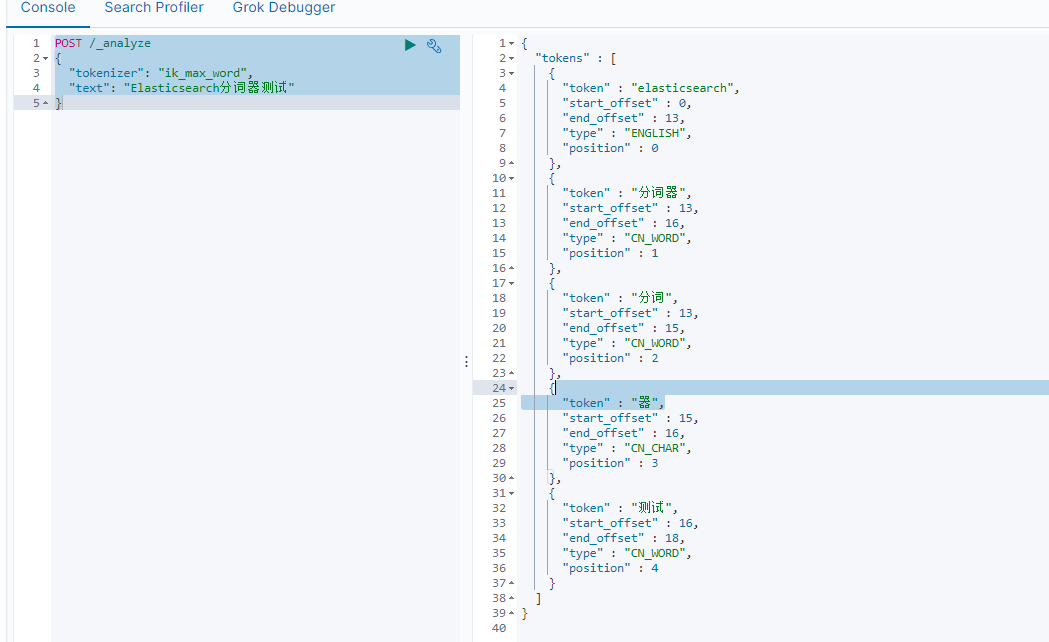
可以看出二者的区别






