scrapy框架2
一、中间件 (下载中间件)
利用中间件加cookie
案例:登录以后下载豆瓣的电影信息
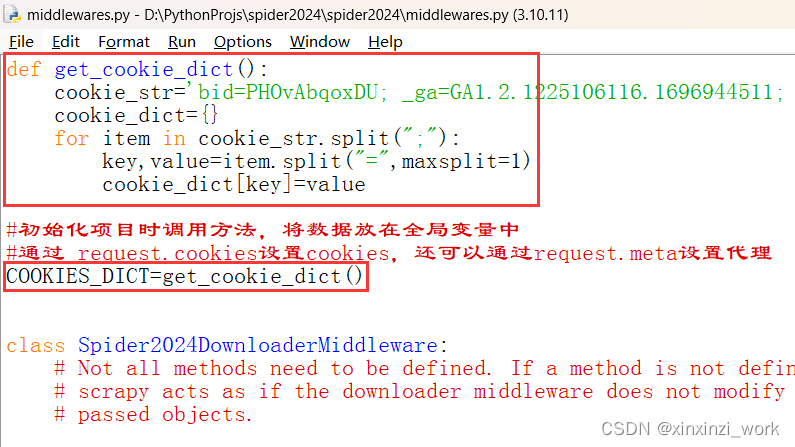
def get_cookie_dict():cookie_str='登陆后的cookie'cookie_dict={}for item in cookie_str.split(";"):key,value=item.split("=",maxsplit=1)cookie_dict[key]=value#初始化项目时调用方法,将数据放在全局变量中
#通过 request.cookies设置cookies,还可以通过request.meta设置代理
COOKIES_DICT=get_cookie_dict()
在process_request函数,拦截请求,属于钩子函数,这样scrapy框架才能调用他
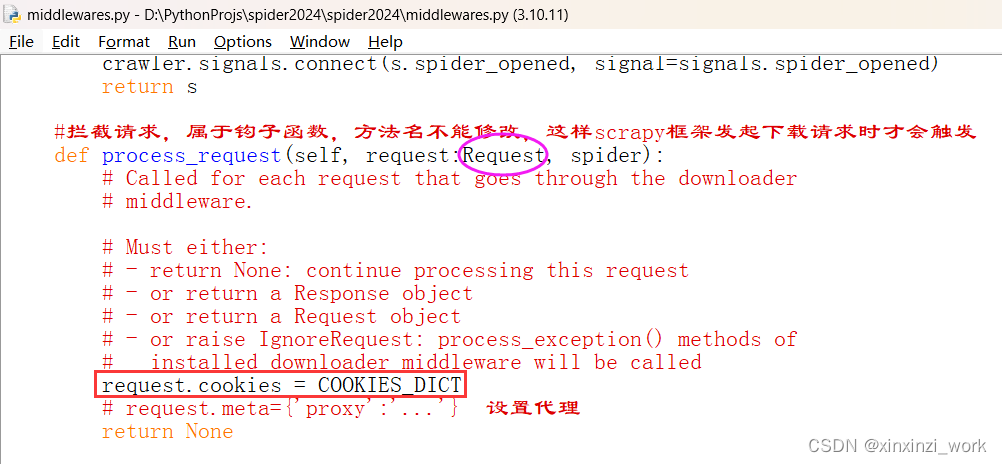
对应代码:
#通过 request.cookies设置cookies,还可以通过request.meta设置代理
request.cookies=COOKIES_DICT
# request.meta={'proxy':'...'} 设置代理
在settings中开启中间件:
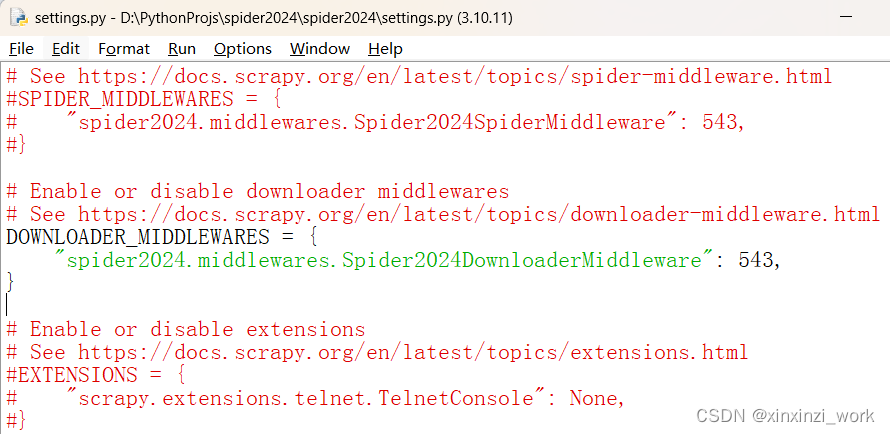
在终端运行命令:scrapy crawl douban
运行结果:
案例:下载豆瓣评分列表页信息和详情页信息
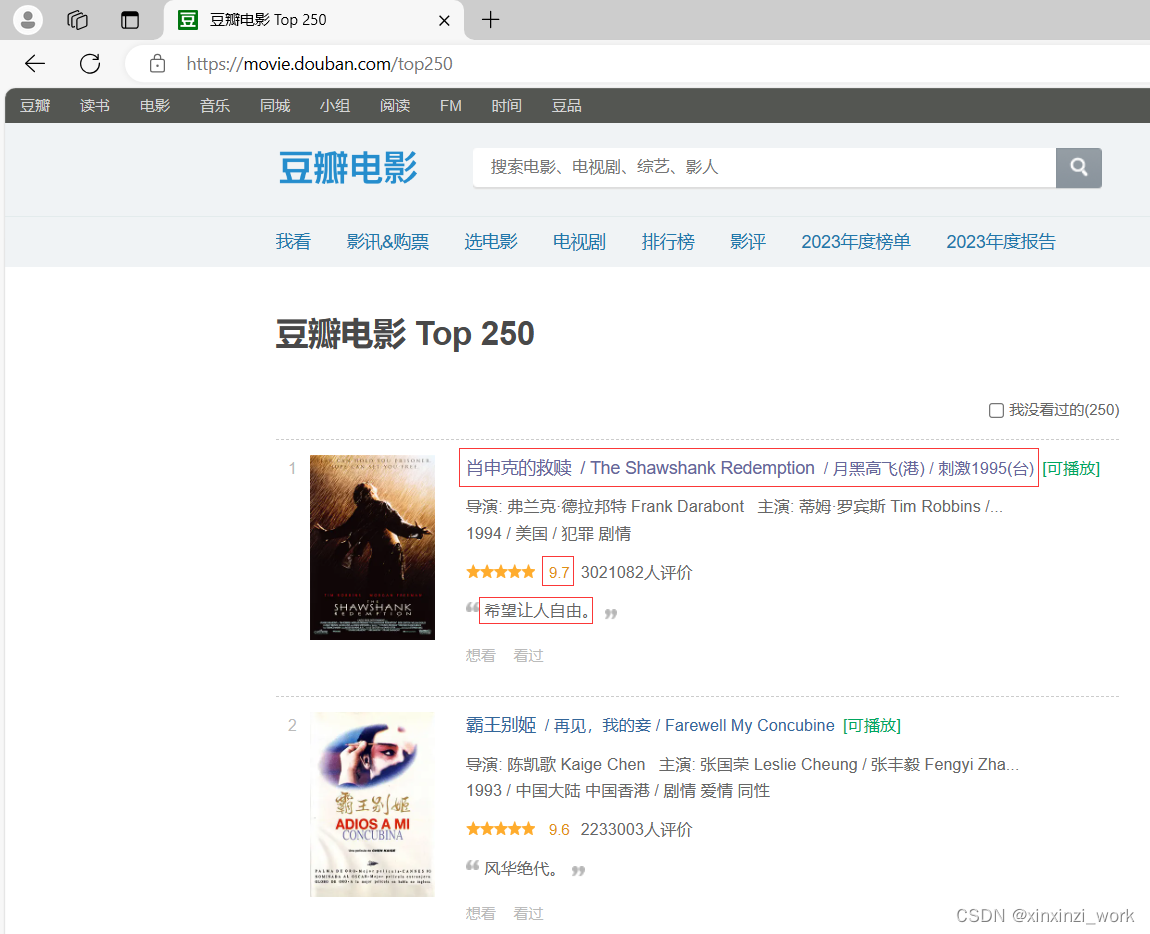

实现如下:
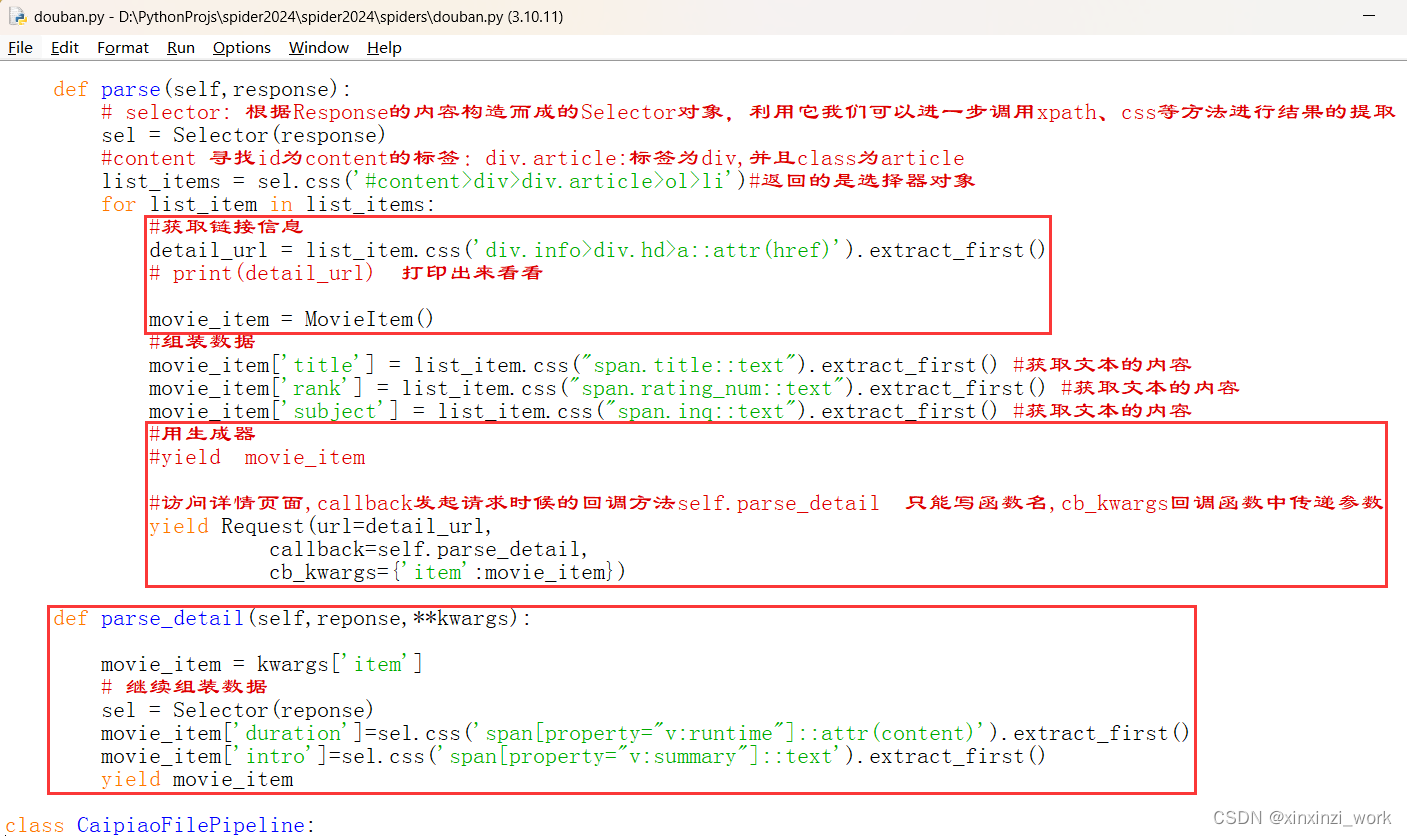
def parse(self,response):# selector: 根据Response的内容构造而成的Selector对象,利用它我们可以进一步调用xpath、css等方法进行结果的提取sel = Selector(response)#content 寻找id为content的标签:div.article:标签为div,并且class为articlelist_items = sel.css('#content>div>div.article>ol>li')#返回的是选择器对象for list_item in list_items:#获取链接信息detail_url = list_item.css('div.info>div.hd>a::attr(href)').extract_first()# print(detail_url) 打印出来看看movie_item = MovieItem()#组装数据movie_item['title'] = list_item.css("span.title::text").extract_first() #获取文本的内容movie_item['rank'] = list_item.css("span.rating_num::text").extract_first() #获取文本的内容movie_item['subject'] = list_item.css("span.inq::text").extract_first() #获取文本的内容#用生成器#yield movie_item#访问详情页面,callback发起请求时候的回调方法self.parse_detail 只能写函数名,cb_kwargs回调函数中传递参数yield Request(url=detail_url,callback=self.parse_detail,cb_kwargs={'item':movie_item})def parse_detail(self,reponse,**kwargs):movie_item = kwargs['item']# 继续组装数据sel = Selector(reponse)movie_item['duration']=sel.css('span[property="v:runtime"]::attr(content)').extract_first()movie_item['intro']=sel.css('span[property="v:summary"]::text').extract_first()yield movie_item
在item中加新的属性:
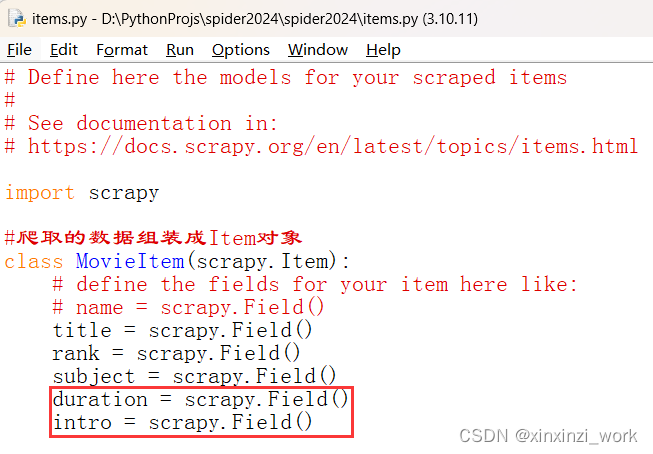
class MovieItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()title = scrapy.Field()rank = scrapy.Field()subject = scrapy.Field()duration = scrapy.Field()intro = scrapy.Field()
管道中设置新增属性:
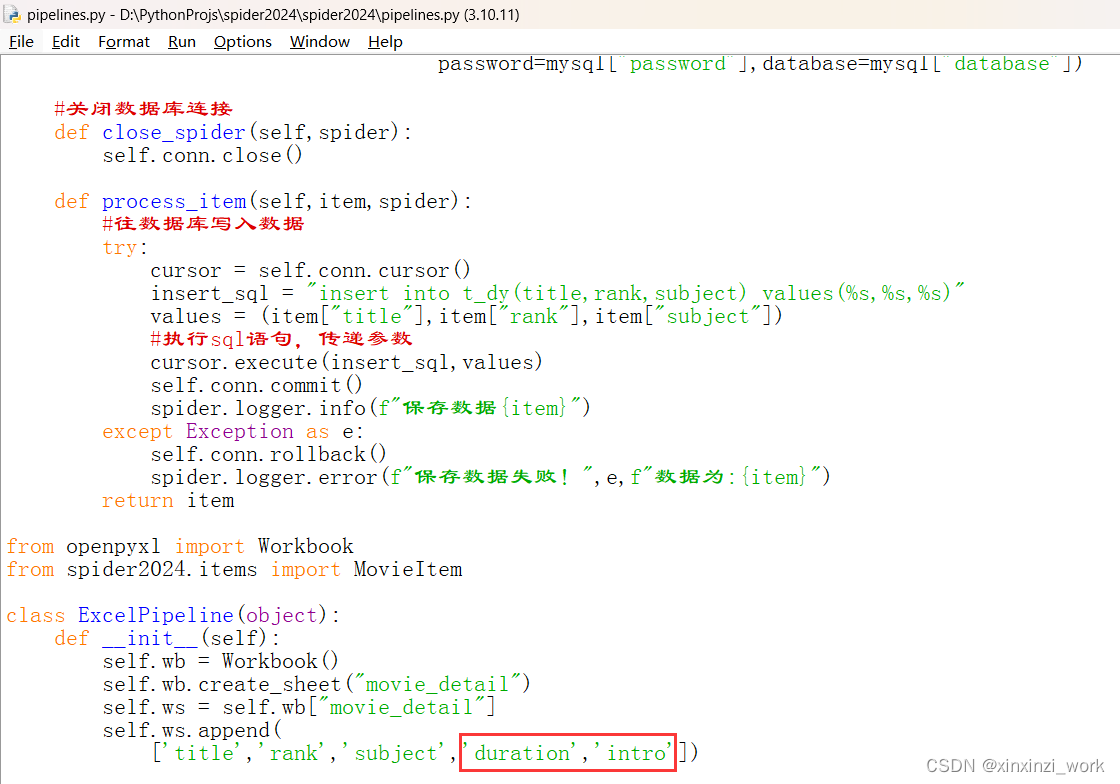
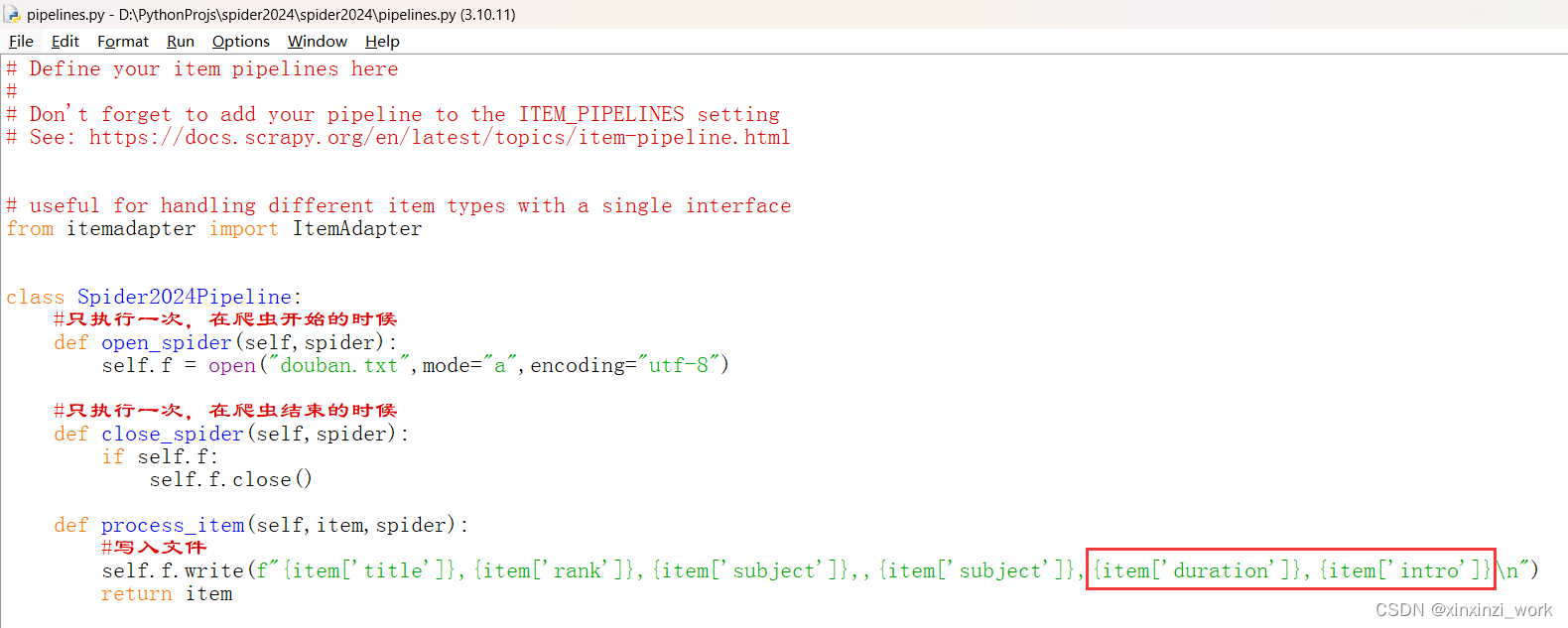
在终端运行命令:scrapy crawl douban
运行结果:


)




