模型训练
模型训练共分四个步骤:
- 构建数据集
- 定义神经网络模型
- 定义超参、损失函数、优化器
- 训练评估
前面三步在之前的文章都有介绍,这次我们学习模型训练。
构建数据集
载入Mnist数据集并进行数据变换
def datapipe(path, batch_size):image_transforms = [vision.Rescale(1.0 / 255.0, 0),vision.Normalize(mean=(0.1307,), std=(0.3081,)),vision.HWC2CHW()]label_transform = transforms.TypeCast(mindspore.int32)dataset = MnistDataset(path)dataset = dataset.map(image_transforms, 'image')dataset = dataset.map(label_transform, 'label')dataset = dataset.batch(batch_size)return datasettrain_dataset = datapipe('MNIST_Data/train', batch_size=64)
test_dataset = datapipe('MNIST_Data/test', batch_size=64)
定义神经网络
定义一个6层的神经网络,包括1个展平层,三个全连接层, 两个relu激活层。
class Network(nn.Cell):def __init__(self):super().__init__()self.flatten = nn.Flatten()self.dense_relu_sequential = nn.SequentialCell(nn.Dense(28*28, 512),nn.ReLU(),nn.Dense(512, 512),nn.ReLU(),nn.Dense(512, 10))def construct(self, x):x = self.flatten(x)logits = self.dense_relu_sequential(x)return logitsmodel = Network()
定义超参、损失函数、优化器
超参
在模型训练中可以自己设置的控制模型训练中的参数。模型参数是在训练过程中通过优化算法自己学习到的,而超参数是手动或通过一些方式在训练前设定的,在训练过程中保持不变。
深度学习中大多拆用批量随机梯度下降算法进行优化。
w t + 1 = w t − η 1 n ∑ x ∈ B ∇ l ( x , w t ) w_{t+1}=w_{t}-\eta \frac{1}{n} \sum_{x \in \mathcal{B}} \nabla l\left(x, w_{t}\right) wt+1=wt−ηn1x∈B∑∇l(x,wt)
其中, n n n 为批量大小batch size, η η η是学习率learning rate。 w t w_{t} wt为训练轮次 t t t中的权重参数, ∇ l \nabla l ∇l为损失函数的导数。
超参数包括
- 训练轮次 epoch:遍历数据集的次数
- 批次大小 batch size: 数据集会被分成批被读取。size过小则花费时间长,参数更新频繁,噪声大。size过大则需要更多内存,容易陷入局部最优但过程更加稳定。
- 学习率 learning rate:学习率定义了每次更新模型参数时的步长大小。学习率较小会导致收敛速度变慢。较大可能不收敛。
损失函数
损失函数loss function用于评估模型的预测值logits和目标值targets之间的误差。模型的训练目标实际上是让误差降低。
常见的损失函数有均方误差MSE loss(求预测值和实际值差值的平方和的平均值),交叉熵损失Cross-Entropy Loss(用于衡量分类模型输出的概率分布与真实分布之间的差异,用于分类任务)
优化器
模型优化是在训练步骤中调整模型参数以减少模型误差的过程。优化器定义了优化模型参数的方式。SGD是常用的优化器。我们向优化器中传入模型的可训练参数并传入学习率来初始化优化器。
optimizer = nn.SGD(model.trainable_params(), learning_rate=learning_rate)
训练和评估
数据集的完整迭代称为一次epoch。每次都会包含训练和验证。验证是为了检查模型性能是否有提升。
这里需要定义两个循环,一个训练用和验证用。
# 前向传播函数,定义loss计算
def forward_fn(data, label):logits = model(data)loss = loss_fn(logits, label)return loss, logits# 微分函数
grad_fn = mindspore.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=True)# 把梯度计算函数传入优化器
def train_step(data, label):(loss, _), grads = grad_fn(data, label)optimizer(grads)return loss# 定义训练的循环
def train_loop(model, dataset):size = dataset.get_dataset_size()model.set_train()for batch, (data, label) in enumerate(dataset.create_tuple_iterator()):loss = train_step(data, label)# 每一百个batch打印一次lossif batch % 100 == 0:loss, current = loss.asnumpy(), batchprint(f"loss: {loss:>7f} [{current:>3d}/{size:>3d}]")# 定义test的循环
def test_loop(model, dataset, loss_fn):num_batches = dataset.get_dataset_size()model.set_train(False)total, test_loss, correct = 0, 0, 0for data, label in dataset.create_tuple_iterator():pred = model(data)total += len(data)# 计算losstest_loss += loss_fn(pred, label).asnumpy()correct += (pred.argmax(1) == label).asnumpy().sum()test_loss /= num_batchescorrect /= totalprint(f"Test: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
开始进行模型训练并测试模型效果
# 定义loss函数
loss_fn = nn.CrossEntropyLoss()
# 定义优化器
optimizer = nn.SGD(model.trainable_params(), learning_rate=learning_rate)for t in range(epochs):print(f"Epoch {t+1}\n-------------------------------")train_loop(model, train_dataset)test_loop(model, test_dataset, loss_fn)
print("Done!")
训练结果,可以看到loss逐渐降低了。
Epoch 1
loss: 0.379628 [ 0/938]
loss: 0.364262 [100/938]
loss: 0.200386 [200/938]
loss: 0.384155 [300/938]
loss: 0.357219 [400/938]
loss: 0.241734 [500/938]
loss: 0.189096 [600/938]
loss: 0.174289 [700/938]
loss: 0.444105 [800/938]
loss: 0.354697 [900/938]
Test:
Accuracy: 92.8%, Avg loss: 0.252959
Epoch 2
loss: 0.329644 [ 0/938]
loss: 0.228527 [100/938]
loss: 0.196500 [200/938]
loss: 0.213885 [300/938]
loss: 0.271757 [400/938]
loss: 0.194773 [500/938]
loss: 0.251400 [600/938]
loss: 0.198860 [700/938]
loss: 0.245383 [800/938]
loss: 0.274584 [900/938]
Test:
Accuracy: 93.7%, Avg loss: 0.210091
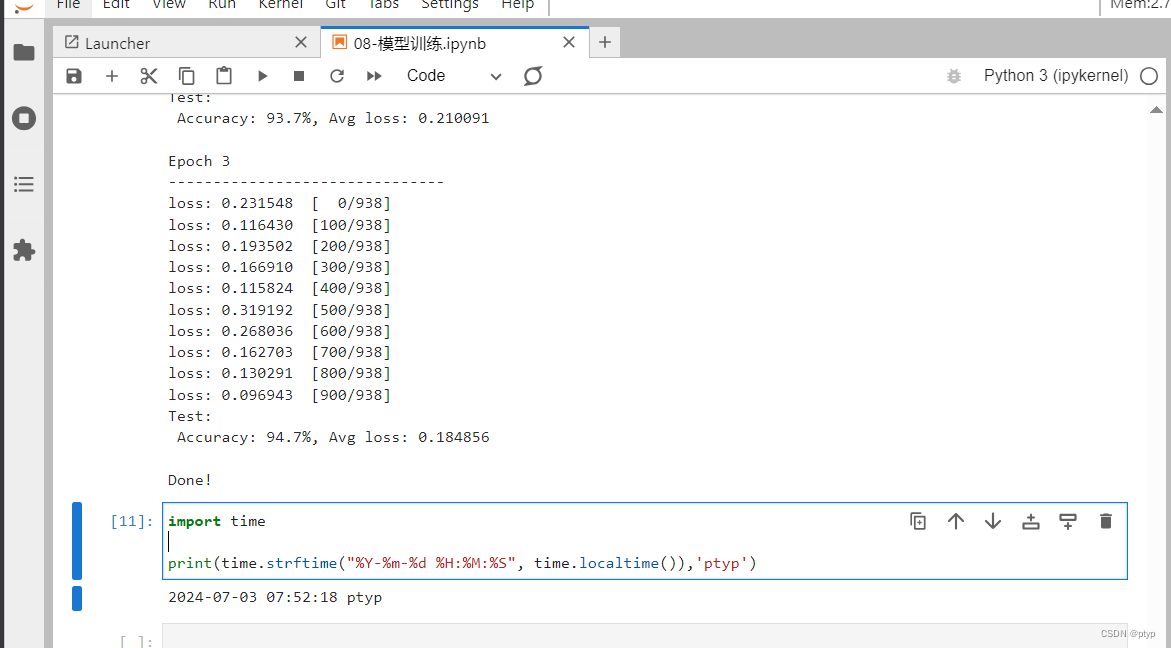
Epoch 3
loss: 0.231548 [ 0/938]
loss: 0.116430 [100/938]
loss: 0.193502 [200/938]
loss: 0.166910 [300/938]
loss: 0.115824 [400/938]
loss: 0.319192 [500/938]
loss: 0.268036 [600/938]
loss: 0.162703 [700/938]
loss: 0.130291 [800/938]
loss: 0.096943 [900/938]
Test:
Accuracy: 94.7%, Avg loss: 0.184856
总结
本节梳通了从数据集加载、数据处理、模型定义、超参优化器及损失函数定义、到后续的模型训练和评估整个流程。
打卡凭证

CUDA 图像去噪函数fastNlMeansDenoising())




