FedProx:2020 FedAvg的改进
论文:《Federated Optimization in Heterogeneous Networks》
引用量:4445
源码地址:
官方实现(tensorflow)https://github.com/litian96/FedProx
几个pytorch实现:https://github.com/ki-ljl/FedProx-PyTorch ,https://github.com/rruisong/pytorch_federated_learning
针对的问题:
在FL中,多个client并行训练本地模型,然后server将这些局部模型聚合起来得到全局模型,在这个过程中,有两个困难点:
- 系统异构System Heterogeneity:各client的计算能力、存储能力、通信能力各不相同,等待落后的局部模型会拖慢整个系统的训练速度,但抛弃这些落后的client会影响全局模型的精度;
- 统计异构Statistical Heterogeneity:不同client间的数据是Non-IID的,此外还有数据unbalanced的情况;
FedAvg是FL中最基本的算法,但是针对上述两个难点,仍有一定问题,表现如下:
- 在系统异构方面:FedAvg几乎没有考虑系统异构,在实际中,当部分client在规定时间内没有完成训练时,不管是drop这些模型还是直接聚合未训练完成的模型,都会影响全局模型的acc。
- 在统计异构方面:FedAvg较好得解决了统计异构的难点,也正因此让它成为当时FL中的SOTA,但在算法上仍有改进的空间。
- 其他:FedAvg通过实验证明了其有效性,但缺少理论上对于收敛速度等指标的分析。
论文贡献:
针对FedAvg的不足,作者提出了FedProx算法,该算法能很好地处理异构性,且具有理论保障。在实验中,FedProx能比FedAvg更健壮地收敛,且在高异构地环境下,FedProx比FedAvg有更稳定和准确地收敛,平均提高22%的绝对测试精度。
算法介绍:
FedProx算法在FedAvg算法的基础上进行了两个改动,分别是:
- 针对系统异构性问题,FedProx允许出现训练不充分的局部模型(γ-inexact solution)。
不论一个局部模型是否完成了“本地训练”(固定epoch),FedProx会整合所有参与训练的局部模型,这意味着FedProx不需要所有局部模型训练得很精确。
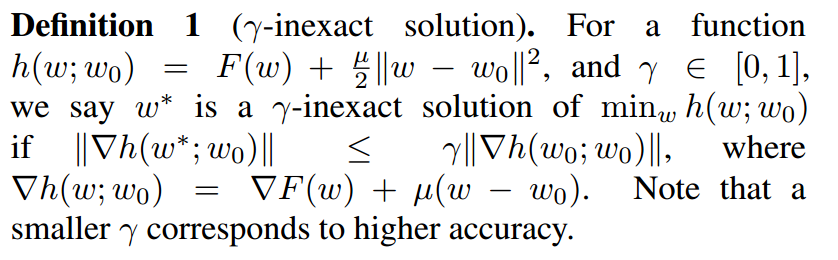
首先,作者给出了定义1,提出了γ-inexact solution,对于一个待优化的目标函数 h ( w ; w 0 ) h(w;w_0) h(w;w0),如果有:
∣ ∣ ∇ h ( w ∗ ; w 0 ) ∣ ∣ ≤ γ ∣ ∣ ∇ h ( w 0 ; w 0 ) ∣ ∣ ||\nabla h(w^*;w_0)||\leq\gamma||\nabla h(w_0;w_0)|| ∣∣∇h(w∗;w0)∣∣≤γ∣∣∇h(w0;w0)∣∣
这里的 γ ∈ [ 0 , 1 ] \gamma\in[0,1] γ∈[0,1],我们就说 w ∗ w^* w∗是 h h h的一个 γ-不精确解。
对这个定义,我们可以这样理解:梯度越小越精确,因为梯度大了,模型就需要更多的时间去收敛。那么在这里的 γ 如果越小,我们的解 w ∗ w^* w∗就越精确。这个 γ 就是用于描述在优化问题中的近似解的准确程度。
简单来说就是,这里的 γ 对应着局部模型的训练完成度,γ 越小,局部模型训练完成度就越高。

在FedProx中,允许随着 k 和 t 的不同,有不同的精确解,所以作者提出了定义2。 γ k t \gamma_k^t γkt衡量了第 k 个client在全局第 t 次迭代(或者说通信)中本地计算量。总之,定义2中的 γ 和定义1中的含义仍是一致的,只不过相比于定义1,定义2中将目标函数和梯度的计算方法引入到分布式场景上,这样定义的 γ k t \gamma_k^t γkt近似解适用于衡量每个client的解在近似程度上的准确度。也就是说在不同轮的FL中,每个client不用都完成相同的epoch次本地训练,而是可以根据自己的算力等情况去决定自己在当前通信轮要完成几个epoch次本地训练。
注意:作者在实验中并没有真正自适应地去设置 γ 的大小,而是让不同的client去完成不同epoch次本地训练来模拟不同client算力不同的场景。(所以这个 γ 只是作者用来说明问题而提出的一个概念而已)
- 针对统计异构,局部模型的目标函数在原损失函数基础上加上了近端项(proximal term)。
这里的近端项Proximal term正是算法名FedProx的由来。
我们知道,在FedAvg中,k号client在本地训练时,需要最小化的目标函数为:
F k ( w ) = 1 n k ∑ i ∈ P k f i ( w ) F_k(w)=\frac{1}{n_k}\sum_{i\in P_k}f_i(w) Fk(w)=nk1∑i∈Pkfi(w)
简单来说就是,每个client都是优化自己的所有样本的损失和,这是个正常的思路,目的是让全局模型在自己本地数据集上表现更好。
但是,当client之间各自的数据是Non-IID时,每个client优化之后的局部模型就会跟全局模型相去甚远了,局部模型会偏离全局模型,这会减缓全局模型的收敛。
为了限制这种偏差,作者提出了新的方案,修改了k号client在本地训练时需要最小化的目标函数为:
h k ( w ; w t ) = F k ( w ) + μ 2 ∣ ∣ w − w t ∣ ∣ 2 h_k(w;w^t)=F_k(w)+\frac{\mu}{2}||w-w^t||^2 hk(w;wt)=Fk(w)+2μ∣∣w−wt∣∣2
加号的左边就是原来FedAvg的损失函数,作者在其基础上,加上了一个近端项proximal term。引入近端项之后,client在本地训练后得到的模型参数 w w w将不会与初始时server下发的参数 w t w^t wt偏离太多。
作者指出引入近端项的两个优点:
- 通过限制局部更新,让其更接近全局模型的方式,而不需要手动设置局部epoch,解决了统计异构性的问题;
- 允许安全合并由系统异构产生的可变数量的局部工作。
观察上式,当 μ =0 时,FedProx的优化目标就和FedAvg一致了。
这种思路还是很常见的,在机器学习中,为了防止过调节,亦或者为了限制参数变化,会在损失函数里加上一个类型的项,用于惩罚那些偏离过大的情况。

输入:client总数 K、通信轮数 T、μ 和 γ、server初始化参数 w 0 w^0 w0,被选中的client个数 N、第 k 个client被选中的概率 p k p_k pk。(注意:相比于FedAvg那篇论文是随机选client,本文是有概率的选择,作者说这样对两种算法更稳定,但这会不会造成不公平呢?)
对每一轮通信:
- server首先根据概率 p k p_k pk随机选出一批client,它们的集合为 S t S_t St。
- server将当前全局模型的参数 w t w^t wt发送给被选中的clients。
- 每一个被选中的client需要寻找到一个 w k t + 1 w_k^{t+1} wkt+1,这里的 w k t + 1 w_k^{t+1} wkt+1不再是FedAvg中根据本地SGD优化得到的,而是优化 h k ( w ; w t ) = F k ( w ) + μ 2 ∣ ∣ w − w t ∣ ∣ 2 h_k(w;w^t)=F_k(w)+\frac{\mu}{2}||w-w^t||^2 hk(w;wt)=Fk(w)+2μ∣∣w−wt∣∣2后得到的 γ-不精确解。
- 每个client将得到的不精确解传递回server,server聚合这些参数得到下一轮的初始参数。
综上,总结一下来说就是,FedProx在FedAvg上做了两点改进:
- 引入近端项,限制了因为统计异构性导致的模型偏离;
- 引入了不精确解,各个client不再需要训练相同的轮数,只需要得到一个不精确解,这有效缓解了某些设备的计算压力;
实验:
数据集方面,本文实验使用了5个数据集,包含1个合成数据集和4个经典数据集。合成数据集Synthetic data(α;β),其中 α 控制局部模型之间的差异,β 控制每个client的本地数据之间的差异。经典数据集为:MNIST、FEMNIST(Non-IID版的MNIST,由不同作者手写的0-9、A-Z、a-z的数据集)、Shakespeare(莎士比亚作品数据集,同FedAvg)、Sent140(Non-IID,一个文本数据集,内容为一条条推文,标签为positive/negative二分类)。
关于系统异构的实验:
Baseline:FedProx会为0%、50%、90%的被选定的client分别设定 x 个epoch( x 是在 [1, E]之间均匀随机选择)。而FedAvg会简单放弃这些0%、50%、90%的clients。这模拟的是不同client之间的算力不同。
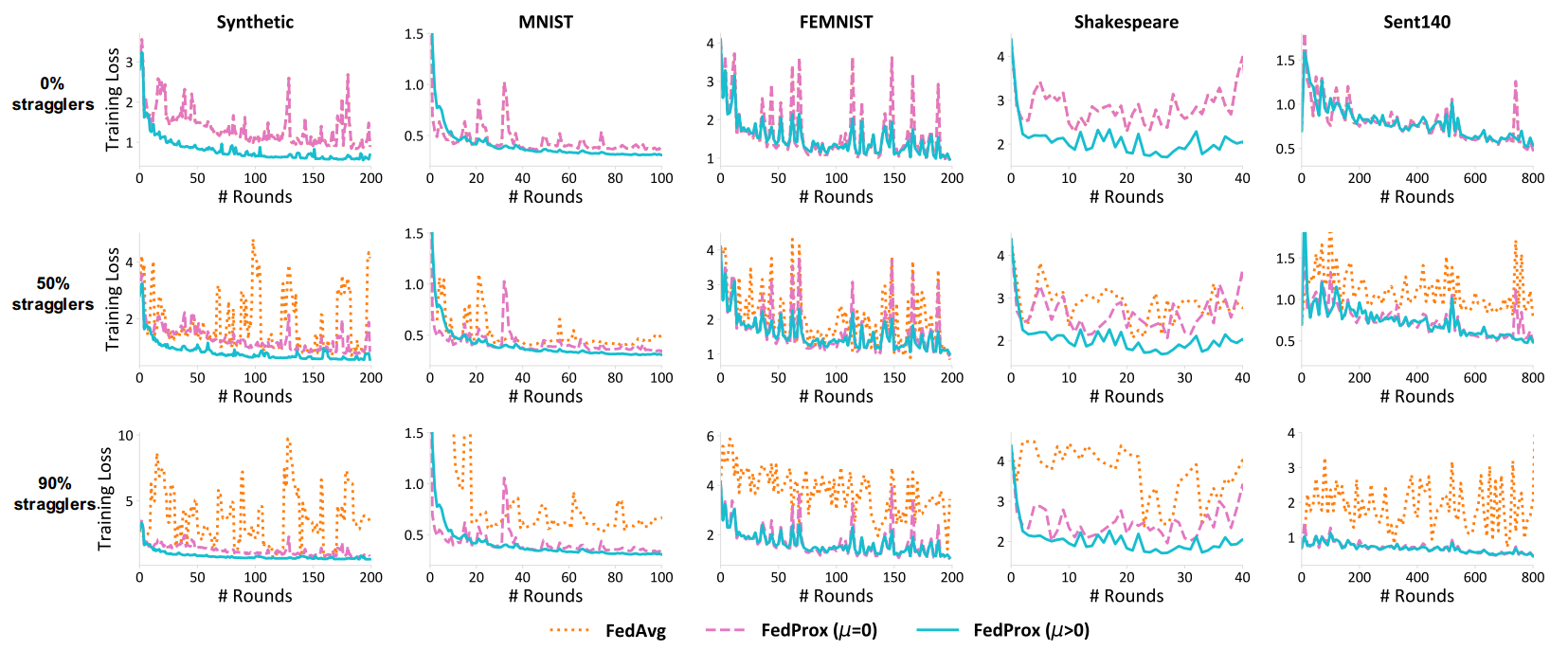
橙线为标准的FedAvg、粉线为近端项为0的FedProx(相当于有系统异构但没有近端项的FedAvg)、蓝线为FedProx。
第一行相当于消融实验,证明了近端项Proximal term对FedProx具有优化作用。
第二、三行,证明了FedProx收敛效果基本比FedAvg要好。
关于统计异构的实验:
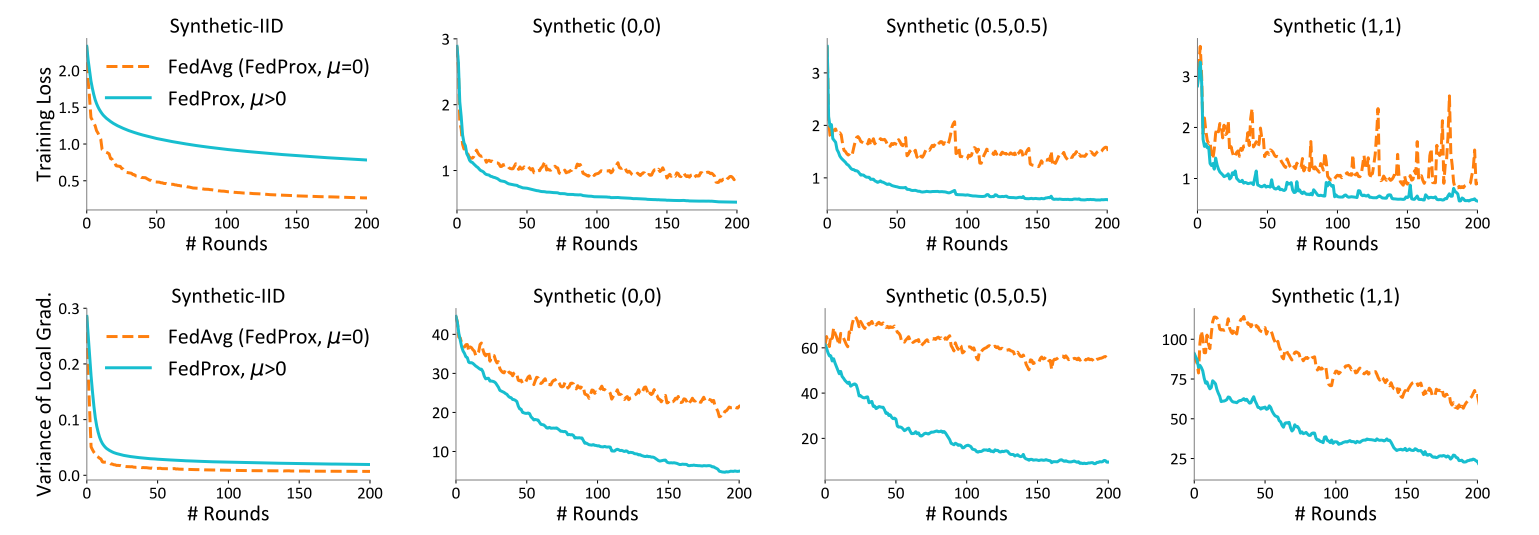
合成数据集的两个参数越大,表明client数据分布越Non-IID。
第一列,说明当数据分布IID时,FedProx收敛速度和最终结果是不如FedAvg的,作者解释说是在IID情况下,FedProx包含的近端项没有带来改善。
第二、三、四列,可见在数据分布Non-IID时,FedProx比FedAvg更有优势。
注意:上面只是论文正文中的实验结果,附录中也有不少实验结果图,大致看了一下发现,在某些数据集的Non-IID条件下,FedProx也没有特别明显的优势。
此外,作者还给出了一个trick:μ 可以根据模型当前的情况自适应去选择,一种简单的做法是当loss增加时增加 μ,当loss减少时减少 μ。这种动态变化的 μ 会使FedProx的收敛效果更好。
总结展望:
系统异构和统计异构对FedAvg提出了挑战,作者在FedAvg的基础上提出了FedProx,主要有两点改进:
- 系统异构方面,考虑到不同client间的算力差异,引入了不精确解,不同的client不需要训练相同的epoch,只需要得到一个不精确解即可。
- 统计异构方面,引入了近端项,限制了局部模型训练时对全局模型的偏离。
本文在系统异构方面主要关注的是算力的差异,如果是其他资源比如网络,有没有处理方法?


(17/ 30))



