文章目录
- Gaze-Directed Vision GNN for Mitigating Shortcut Learning in Medical Image
- 摘要
- 方法
- 实验结果
Gaze-Directed Vision GNN for Mitigating Shortcut Learning in Medical Image
摘要
背景: 深度神经网络在医学图像分析中表现出卓越的性能。然而,由于捷径学习,它容易受到伪相关性的影响,这引发了人们对网络可解释性和可靠性的担忧。此外,在疾病指标通常微妙和稀疏的医学环境中,捷径学习会加剧。
目的: 提出了一种新的凝视导向视觉 GNN(称为 GDViG),以利用放射科医生从凝视中获得的视觉模式作为专业知识,将网络引导到疾病相关区域,从而减少捷径学习。
方法: GD-ViG 由一个凝视映射生成器 (GMG) 和一个凝视定向分类器 (GDC) 组成。将 GNN 的全局建模能力与 CNN 的位置相结合,GMG 根据放射科医生的视觉模式生成凝视图。值得注意的是,它在推理过程中消除了对真实眼动数据的需求,增强了网络的实际适用性。GDC 以凝视为专业知识,通过结合特征距离和凝视距离来指导图形结构的构建,使网络能够专注于与疾病相关的前景。从而避免了捷径学习并提高网络的可解释性。
结果: 在两个公共医学图像数据集上的实验表明,GD-ViG 优于最先进的方法,并有效地减轻了捷径学习。
代码地址
方法
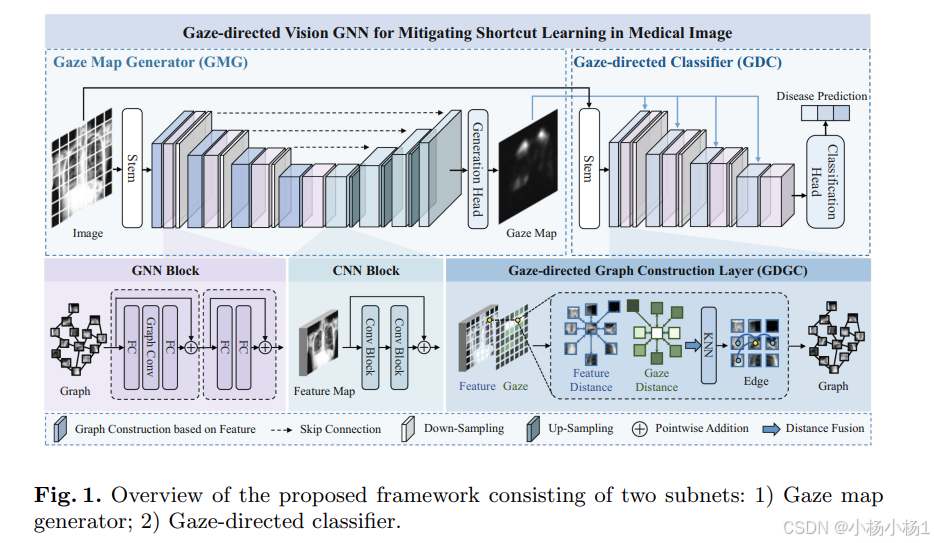
- 凝视图生成器(GMG):
- GMG 包括一个编码器和一个解码器。
- 编码器由基于特征距离的图构造层和 GNN 块组成,这些块提取图像的全局特征。图构造层将每个位置的特征转换为一个节点,对于每个节点,KNN 算法根据特征距离搜索其邻居,并用边将它们连接起来。
- 解码器由四个 CNN 块组成,用于提取局部特征。
- 凝视定向分类器(GDC):
- GDC 由凝视定向图构造层 (GDGC) 和 GNN 块组成。
- GDGC 融合特征距离和凝视距离来构建图形结构并消除与疾病无关节点的联系
实验结果
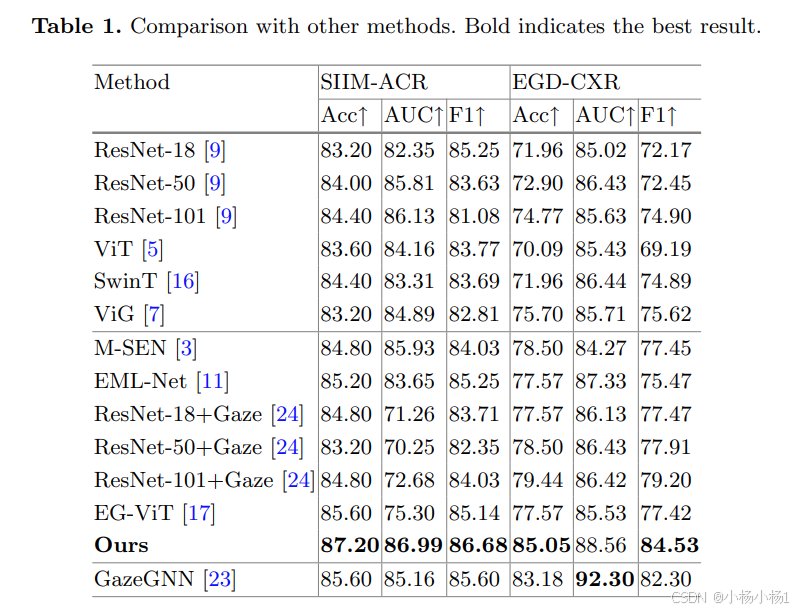
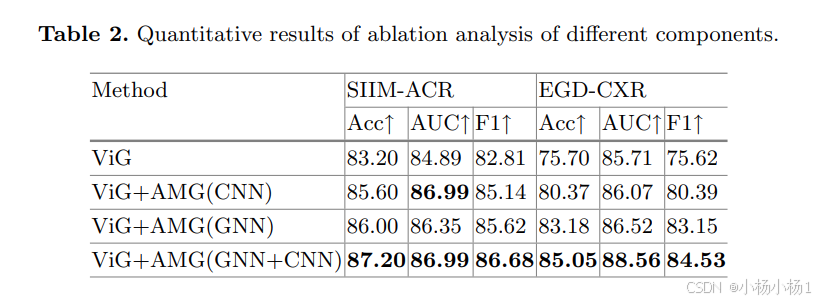
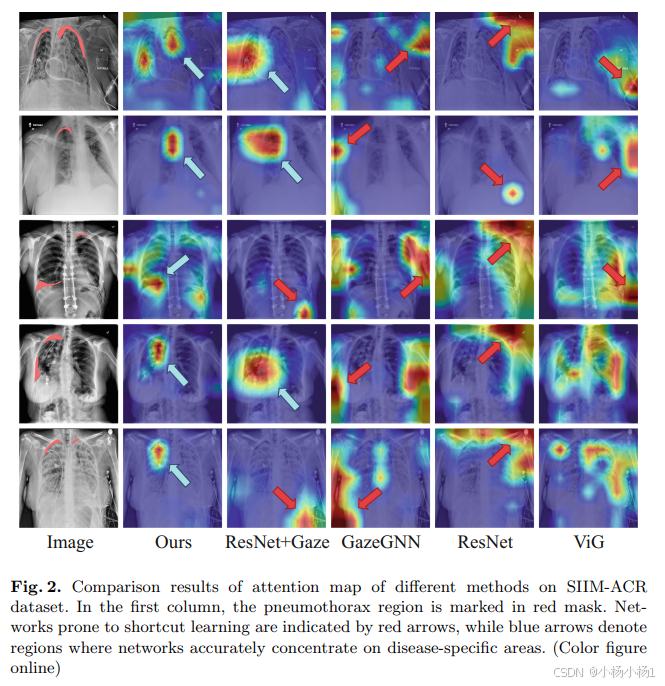






)