目录
系列文章
1. 引言
2. pandas数据分析实战
2.1新建数据库,完善dbname.py
2.2完善数据分析逻辑部分
2.3完整代码
4. 随想
系列文章
虫洞数观系列总览 | 技术全景:豆瓣电影TOP250数据采集→分析→可视化完整指南
虫洞数观系列一 | 豆瓣电影TOP250数据采集与MySQL存储实战
虫洞数观系列二 | Python+MySQL高效封装:为pandas数据分析铺路
1. 引言
提到数据可视化,大多数人首先想到的可能是微软Power BI、帆软BI或是炫酷的前端数据大屏。然而,Navicat 同样提供了便捷高效的数据展示方式,能够轻松实现数据的可视化呈现。
在上一篇文章《虫洞数观系列二 | Python+MySQL 高效封装:为 Pandas 数据分析铺路》中,我们探讨了如何利用 Python 和 MySQL 进行数据预处理。本文将继续深入数据分析,并借助 Navicat 实现数据可视化,最终打造一个直观的数据大屏。

2. pandas数据分析实战
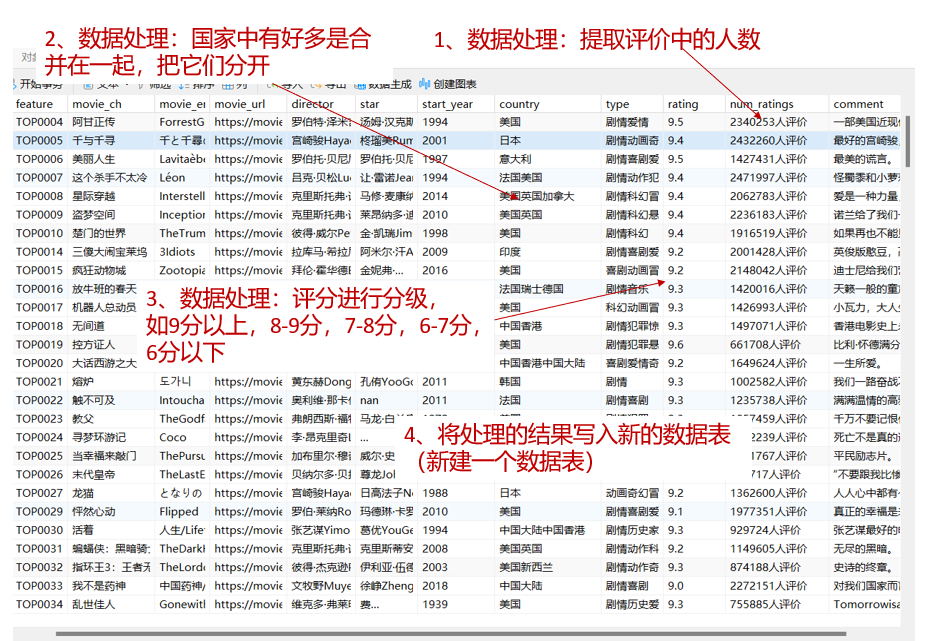
在对top250movie数据表进行初步检查时,我们发现了三个主要的数据质量问题:①国家字段存在多个国家合并存储的情况,②评价人数字段包含冗余的"人评价"文本,③评分数据需要进一步分级处理。针对这些问题,我们需要执行数据清洗、格式标准化和特征工程等预处理步骤。
本阶段数据处理工作流程如下:
-
步骤一:源数据获取(读取top250movie表)
-
步骤二:数据转换分析(基于pandas实现)
-
步骤三:结果数据存储(生成表A并写入MySQL)
在后续开发中,我们将基于《虫洞数观系列二 | Python+MySQL 高效封装:为 Pandas 数据分析铺路》一文中已实现的db模块进行扩展。该模块已完成了数据库连接池的封装及核心读写接口的开发,本次将在此基础上进一步完善数据访问层的功能架构
2.1新建数据库,完善dbname.py
利用navicat新建一个数据表
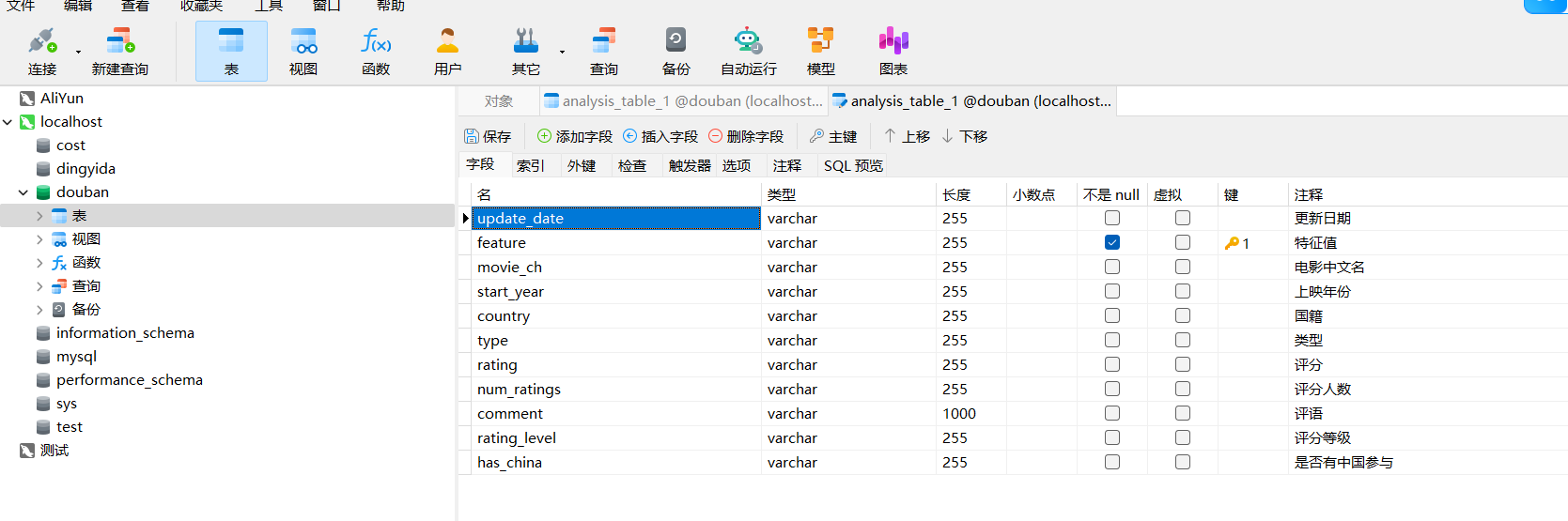
SQL语句
CREATE TABLE `analysis_table_1` (`update_date` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '更新日期',`feature` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '特征值',`movie_ch` varchar(255) DEFAULT NULL COMMENT '电影中文名',`start_year` varchar(255) DEFAULT NULL COMMENT '上映年份',`country` varchar(255) DEFAULT NULL COMMENT '国籍',`type` varchar(255) DEFAULT NULL COMMENT '类型',`rating` varchar(255) DEFAULT NULL COMMENT '评分',`num_ratings` varchar(255) DEFAULT NULL COMMENT '评分人数',`comment` varchar(1000) DEFAULT NULL COMMENT '评语',`rating_level` varchar(255) DEFAULT NULL COMMENT '评分等级',`has_china` varchar(255) DEFAULT NULL COMMENT '是否有中国参与',PRIMARY KEY (`feature`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;同时完善dbname.py文件,代码如下,增加了def analysis_table_1()
from typing import Dictclass TableDefinition:"""表定义基类"""@staticmethoddef _create_table_dict(table_name: str, columns: Dict[str, str]) -> Dict[str, Dict[str, str]]:"""创建表字典结构"""return {table_name: columns}class DouBan(TableDefinition):"""分析表定义"""@staticmethoddef top250movie():"""top250电影"""columns = {'update_date': '更新日期','feature': '特征值','movie_ch': '电影中文名','movie_en': '电影英文名','movie_url': '电影详情页链接','director': '导演','star': '主演','start_year': '上映年份','country': '国籍','type': '类型','rating': '评分','num_ratings': '评分人数','comment': '评语',}return DouBan._create_table_dict('top250movie', columns)# 其他表定义类...@staticmethoddef analysis_table_1():columns = {'update_date': '更新日期','feature': '特征值','movie_ch': '电影中文名','start_year': '上映年份','country': '国籍','type': '类型','rating': '评分','num_ratings': '评分人数','comment': '评语','rating_level': '评分等级','has_china': '是否有中国参与',}return DouBan._create_table_dict('analysis_table_1', columns)def get_dbname_dict():"""获取所有表定义的字典"""db_dict = {}# 合并所有表定义db_dict.update(DouBan.top250movie())# 添加其他表...db_dict.update(DouBan.analysis_table_1())return db_dict# 全局表定义字典
dbname_dic = get_dbname_dict()
for dbname in dbname_dic:print('>>>>>>>>>>>>>>>>>')print(dbname)print(dbname_dic[dbname])
2.2完善数据分析逻辑部分
代码如下:
# 导入必要的库
import datetime # 用于处理日期和时间
import pandas as pd # 用于数据处理和分析
from db.mysql_dao import CommonSQL # 自定义的MySQL数据库操作类def main():############################### 第一步:获取数据 ################################ 从数据库中获取top250电影数据# 使用CommonSQL类的execute_sql_return_value方法执行SQL查询并返回结果df = CommonSQL().execute_sql_return_value('top250movie')print(df) # 打印原始数据用于检查############################### 第二步:数据分析处理 ###############################data_list = [] # 初始化一个空列表,用于存储处理后的数据# 遍历DataFrame中的每一行数据for i in range(df.shape[0]):# 创建一个字典来存储当前电影的所有信息data_dic = {}# 添加基本字段信息data_dic['更新日期'] = str(datetime.datetime.now()) # 记录当前处理时间data_dic['特征值'] = df.loc[i, '特征值'] # 电影特征值data_dic['电影中文名'] = df.loc[i, '电影中文名'] # 电影中文名称data_dic['上映年份'] = df.loc[i, '上映年份'] # 电影上映年份data_dic['国籍'] = df.loc[i, '国籍'] # 电影制作国家data_dic['类型'] = df.loc[i, '类型'] # 电影类型data_dic['评分'] = df.loc[i, '评分'] # 电影评分data_dic['评分人数'] = df.loc[i, '评分人数'] # 参与评分的人数data_dic['评语'] = df.loc[i, '评语'] # 电影评语# 初始化两个新字段data_dic['评分等级'] = '' # 用于存储评分等级分类data_dic['是否有中国参与'] = '' # 用于标记是否有中国参与制作# 定义世界上所有国家的列表(用于后续国家处理)countries = ["阿富汗", "阿尔巴尼亚", "阿尔及利亚", "安道尔", "安哥拉","安提瓜和巴布达", "阿根廷", "亚美尼亚", "澳大利亚", "奥地利","阿塞拜疆", "巴哈马", "巴林", "孟加拉国", "巴巴多斯","白俄罗斯", "比利时", "伯利兹", "贝宁", "不丹","玻利维亚", "波斯尼亚和黑塞哥维那", "博茨瓦纳", "巴西", "文莱","保加利亚", "布基纳法索", "布隆迪", "柬埔寨", "喀麦隆","加拿大", "佛得角", "中非共和国", "乍得", "智利","中国", "哥伦比亚", "科摩罗", "刚果(布)", "刚果(金)","哥斯达黎加", "克罗地亚", "古巴", "塞浦路斯", "捷克","丹麦", "吉布提", "多米尼克", "多米尼加", "东帝汶","厄瓜多尔", "埃及", "萨尔瓦多", "赤道几内亚", "厄立特里亚","爱沙尼亚", "斯威士兰", "埃塞俄比亚", "斐济", "芬兰","法国", "加蓬", "冈比亚", "格鲁吉亚", "德国","加纳", "希腊", "格林纳达", "危地马拉", "几内亚","几内亚比绍", "圭亚那", "海地", "洪都拉斯", "匈牙利","冰岛", "印度", "印度尼西亚", "伊朗", "伊拉克","爱尔兰", "以色列", "意大利", "牙买加", "日本","约旦", "哈萨克斯坦", "肯尼亚", "基里巴斯", "朝鲜","韩国", "科威特", "吉尔吉斯斯坦", "老挝", "拉脱维亚","黎巴嫩", "莱索托", "利比里亚", "利比亚", "列支敦士登","立陶宛", "卢森堡", "马达加斯加", "马拉维", "马来西亚","马尔代夫", "马里", "马耳他", "马绍尔群岛", "毛里塔尼亚","毛里求斯", "墨西哥", "密克罗尼西亚", "摩尔多瓦", "摩纳哥","蒙古", "黑山", "摩洛哥", "莫桑比克", "缅甸","纳米比亚", "瑙鲁", "尼泊尔", "荷兰", "新西兰","尼加拉瓜", "尼日尔", "尼日利亚", "北马其顿", "挪威","阿曼", "巴基斯坦", "帕劳", "巴勒斯坦", "巴拿马","巴布亚新几内亚", "巴拉圭", "秘鲁", "菲律宾", "波兰","葡萄牙", "卡塔尔", "罗马尼亚", "俄罗斯", "卢旺达","圣基茨和尼维斯", "圣卢西亚", "圣文森特和格林纳丁斯", "萨摩亚", "圣马力诺","圣多美和普林西比", "沙特阿拉伯", "塞内加尔", "塞尔维亚", "塞舌尔","塞拉利昂", "新加坡", "斯洛伐克", "斯洛文尼亚", "所罗门群岛","索马里", "南非", "南苏丹", "西班牙", "斯里兰卡","苏丹", "苏里南", "瑞典", "瑞士", "叙利亚","塔吉克斯坦", "坦桑尼亚", "泰国", "多哥", "汤加","特立尼达和多巴哥", "突尼斯", "土耳其", "土库曼斯坦", "图瓦卢","乌干达", "乌克兰", "阿联酋", "英国", "美国","乌拉圭", "乌兹别克斯坦", "瓦努阿图", "梵蒂冈", "委内瑞拉","越南", "也门", "赞比亚", "津巴布韦"]##### 国家信息处理 #####country_list = [] # 初始化一个空列表来存储匹配到的国家# 遍历国家列表,检查原始国籍字段中是否包含这些国家for each_country in countries:if data_dic['国籍'].find(each_country) > -1: # 如果找到匹配的国家country_list.append(each_country) # 将国家添加到列表中# 用竖线(|)连接所有匹配到的国家,更新国籍字段data_dic['国籍'] = '|'.join(country_list)##### 评分人数处理 ###### 去除"评分人数"字段中的"人评价"文字,只保留数字data_dic['评分人数'] = data_dic['评分人数'].replace('人评价', '')##### 评分等级分类 ###### 根据评分值设置评分等级score = float(data_dic['评分']) # 将评分转换为浮点数if score >= 9:data_dic['评分等级'] = '9分以上'elif score >= 8:data_dic['评分等级'] = '8-9分'elif score >= 7:data_dic['评分等级'] = '7-8分'elif score >= 6:data_dic['评分等级'] = '6-7分'else:data_dic['评分等级'] = '6分以下'##### 中国参与标记 ###### 检查国籍中是否包含"中国"if '中国' in data_dic['国籍']:data_dic['是否有中国参与'] = '是'else:data_dic['是否有中国参与'] = '否'# 将处理完的电影数据添加到列表中data_list.append(data_dic)############################### 第三步:数据存储 ################################ 清空目标数据库表,为插入新数据做准备CommonSQL().clear_db_table('analysis_table_1')# 将处理后的数据列表转换为Pandas DataFramedf = pd.DataFrame(data_list)# 定义数据库列名与DataFrame列名的映射关系insert_cols = {'update_date': '更新日期','feature': '特征值','movie_ch': '电影中文名','start_year': '上映年份','country': '国籍','type': '类型','rating': '评分','num_ratings': '评分人数','comment': '评语','rating_level': '评分等级','has_china': '是否有中国参与',}# 打印处理后的数据用于检查print(df)# 使用批量替换方法将数据写入数据库CommonSQL().bulk_replace_infor_in_db(df, # 要插入的数据insert_cols=insert_cols, # 列名映射dbname='analysis_table_1' # 目标表名)# Python脚本的标准入口
if __name__ == '__main__':main() # 调用主函数
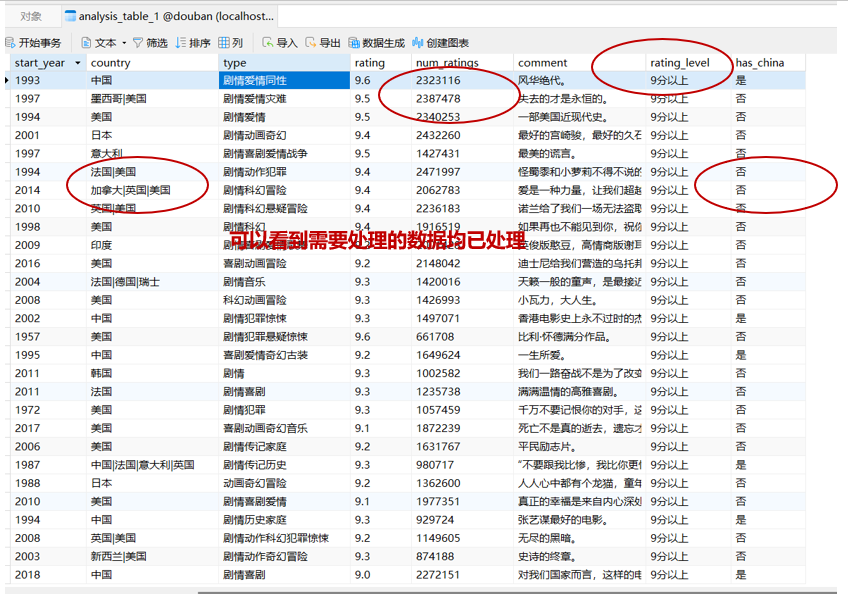
运行结果如下:
2.3完整代码
通过网盘分享的文件:项目工坊_数据分析全链路实践:Pandas清洗统计 + Navicat可视化呈现-代码
链接: https://pan.baidu.com/s/1WpoHYxJKzAcMhl-ngHREKg?pwd=ctib 提取码: ctib
3. navicat使用
这个操作相对简单,尤其对于熟悉微软Power BI或帆软BI的用户来说,基本可以快速上手。即使没有相关经验,只需按照以下步骤操作即可。
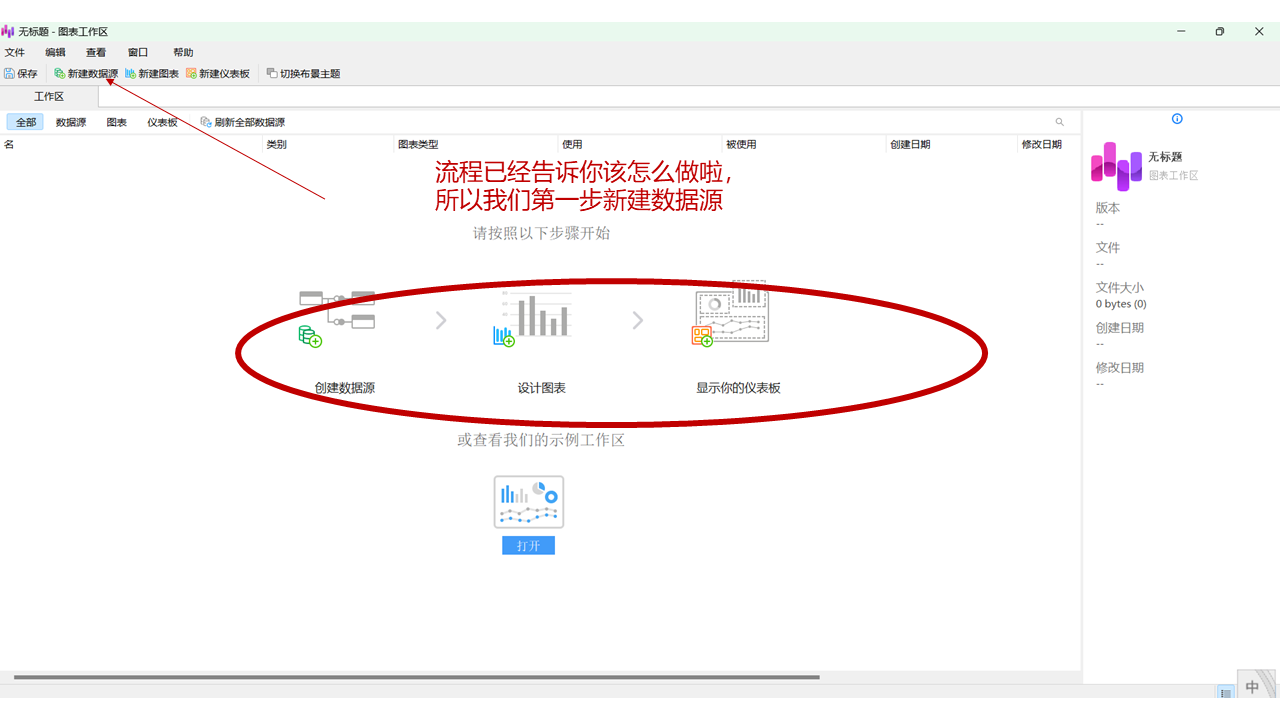


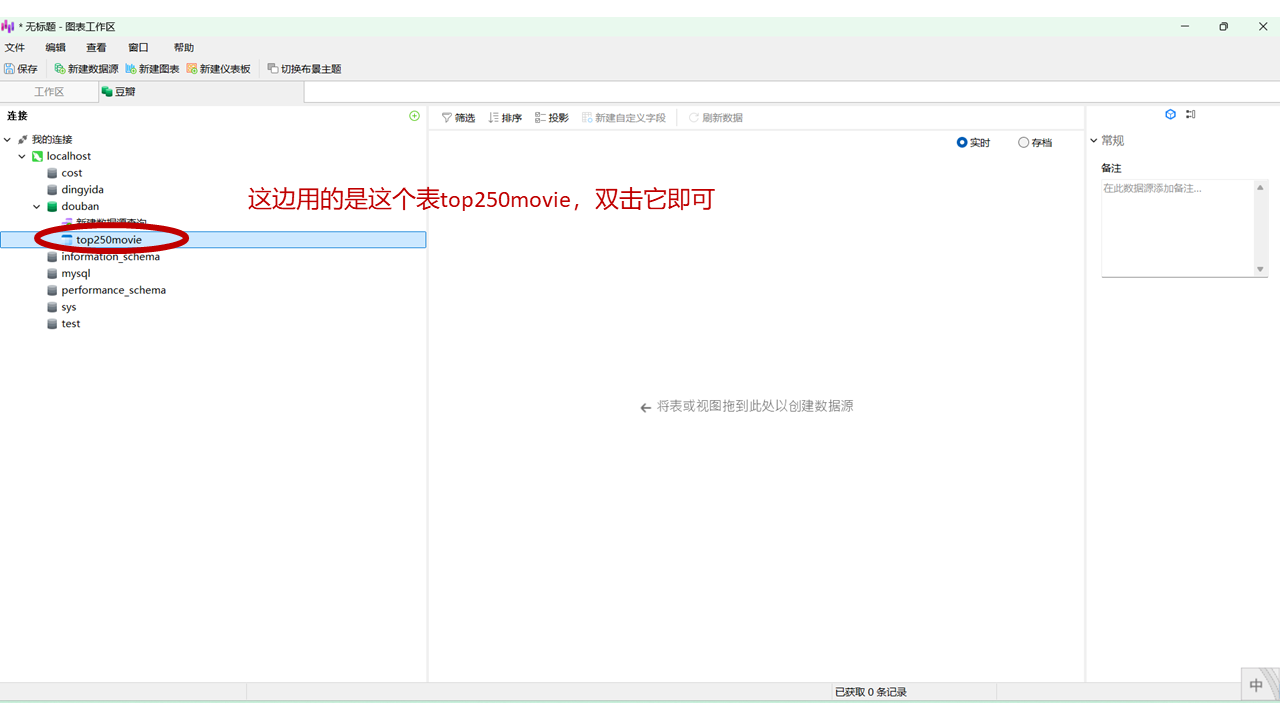
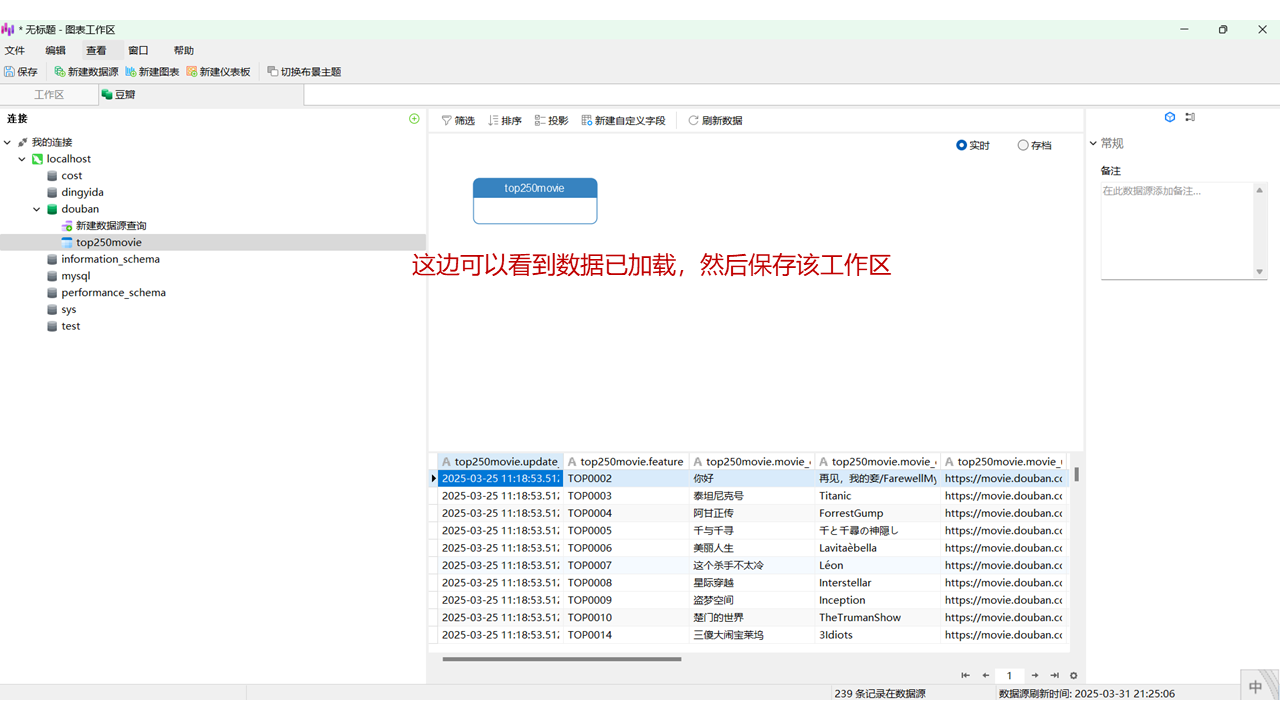
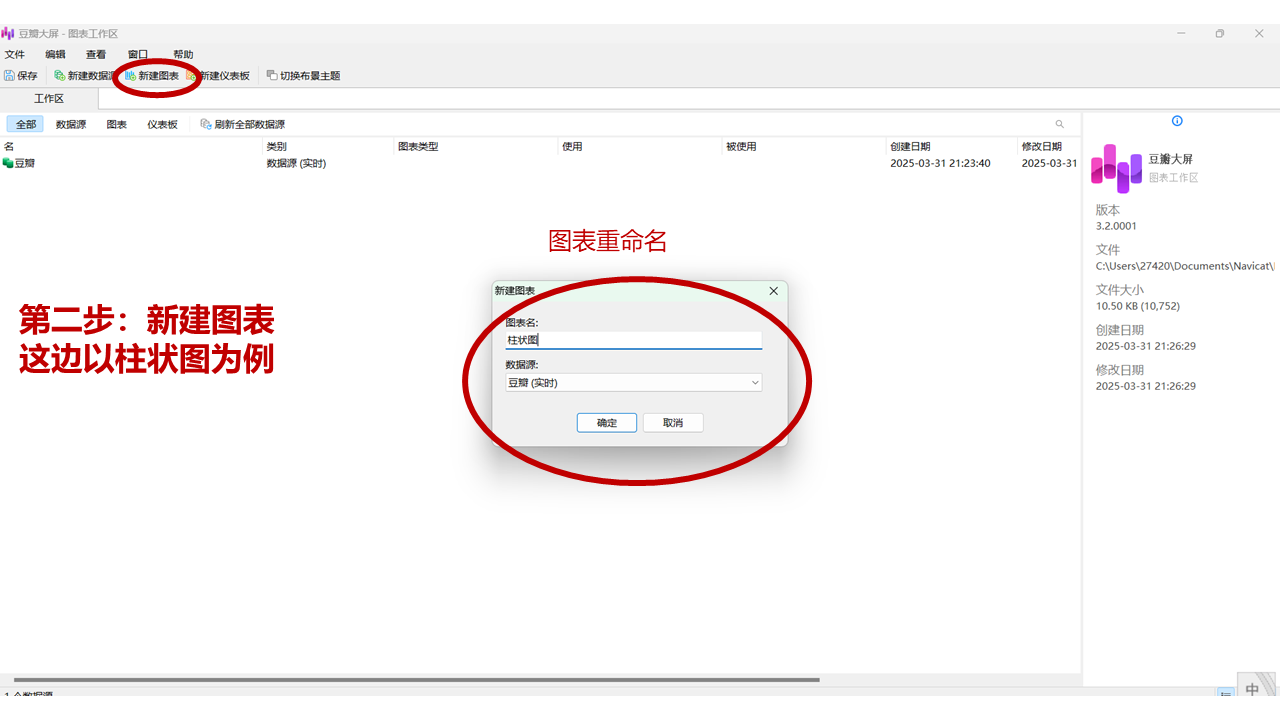
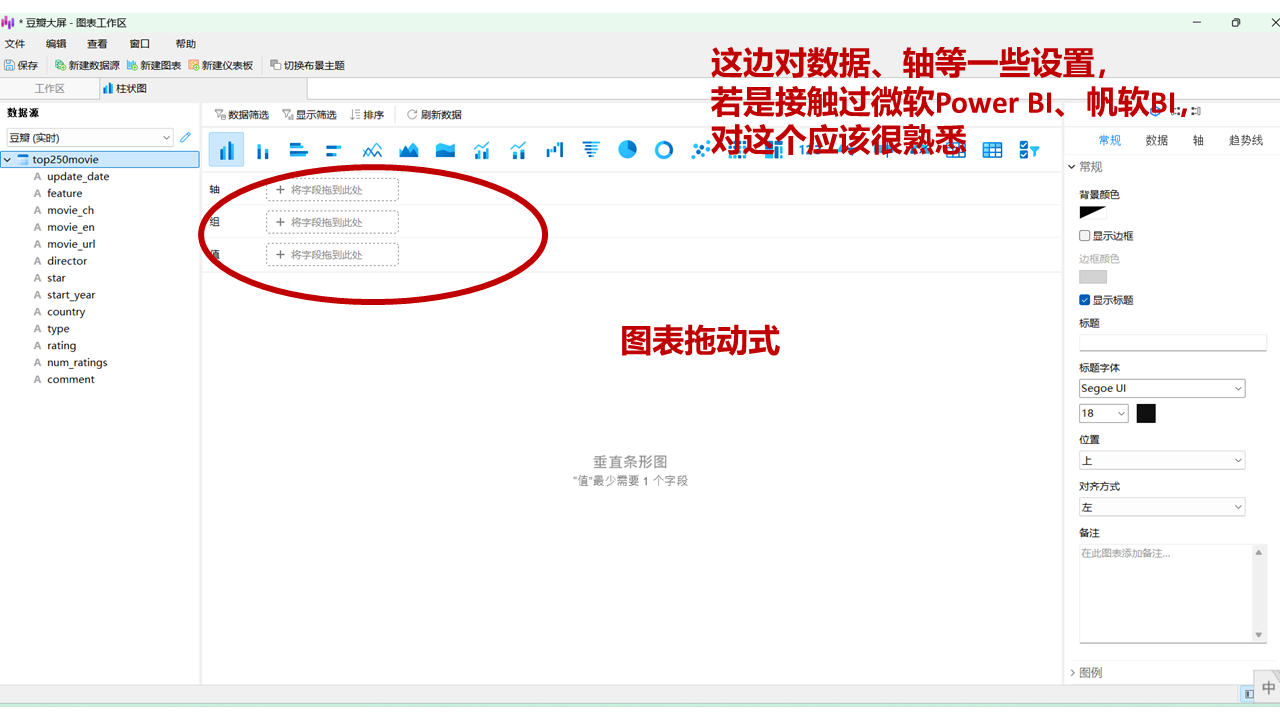

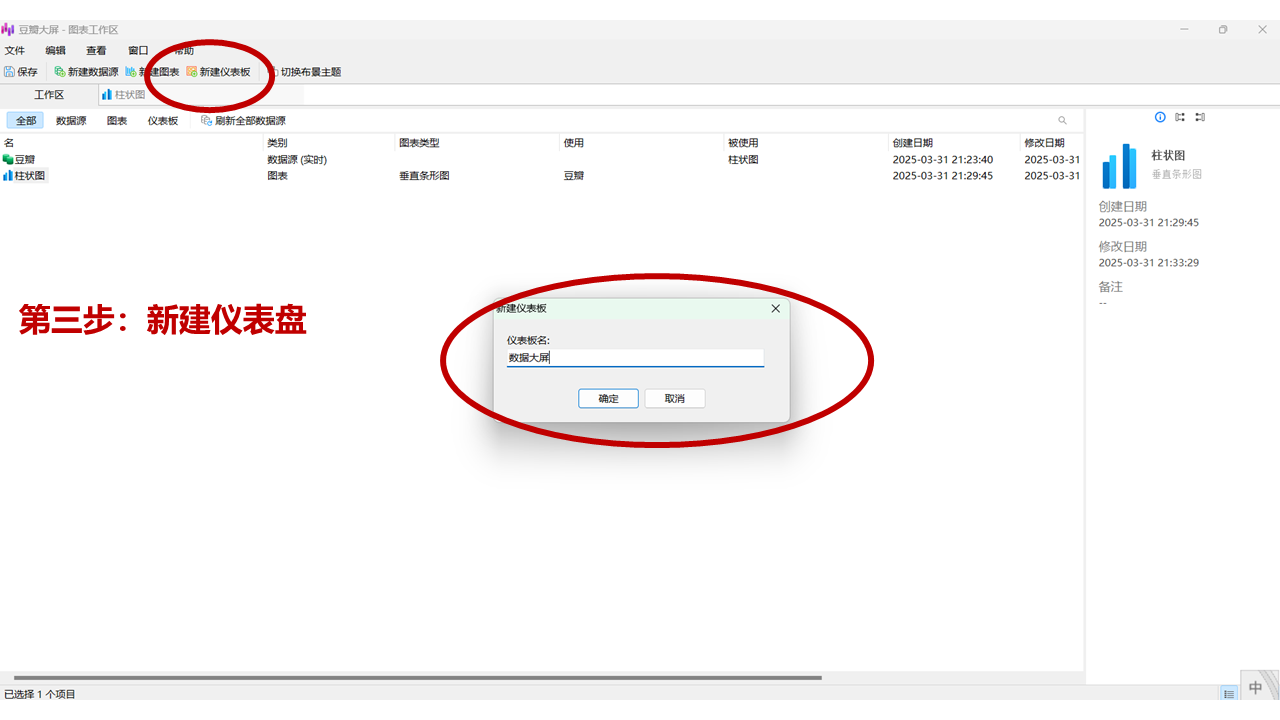
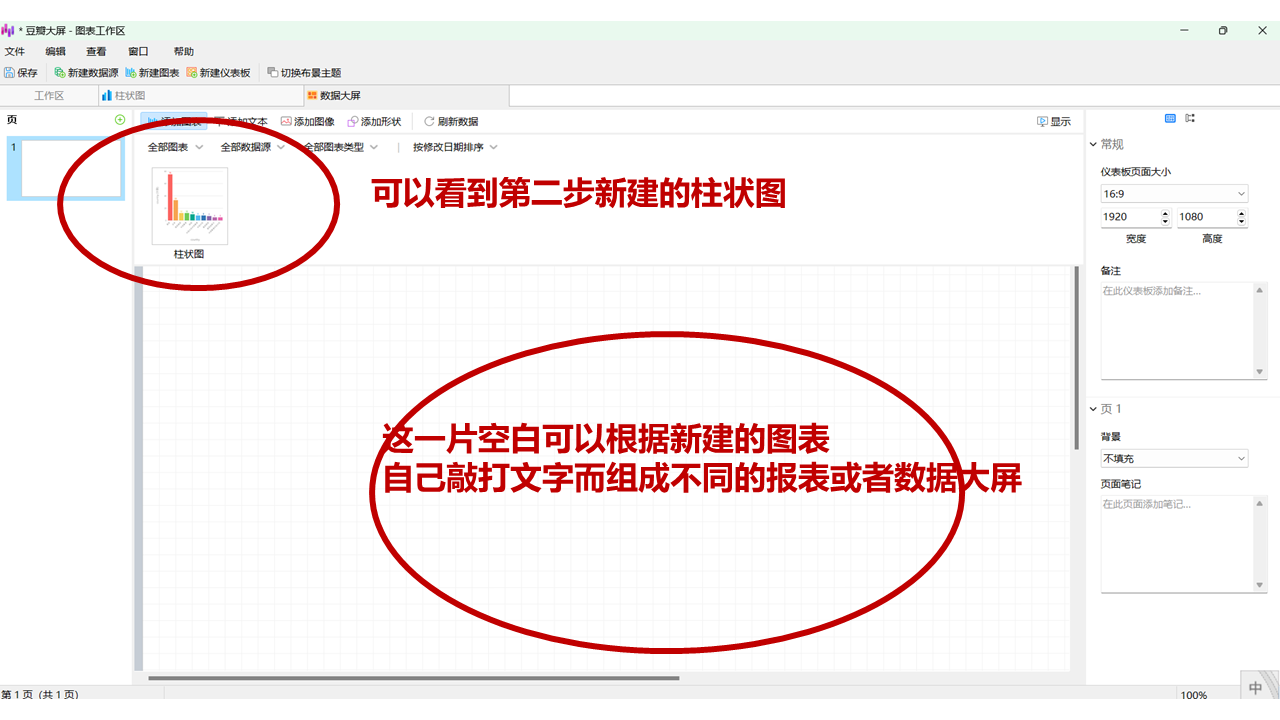
Navicat的核心优势在于其拖拽操作方式,让用户可以零代码实现数据库数据的实时可视化呈现。
这是一个基础实现方案,要打造专业级数据大屏,还需要在交互体验、视觉呈现等细节上持续优化。随着对Navicat的熟练使用,将能掌握更多高级技巧。以下展示我的优化成果供参考:

4. 总结
本方案构建了一套高效的数据分析及可视化工作流:基于Pandas实现核心数据处理与分析,通过Navicat进行可视化呈现。Navicat支持将动态仪表板直接导出为PDF报告,实现了企业数据报表的自动化生成与更新。该方案有效解决了传统PPT汇报中数据维护成本高、时效性差的痛点,能够确保管理层始终获取最新业务洞察,显著提升决策效率。

、索引的使用及设计原则)


