Teapot 开源小型语言模型概览
1. 模型简介
定位:专为资源受限设备(如智能手机、CPU)优化的轻量级语言模型(约 8 亿参数)。
特点:在合成数据上微调,依赖文档上下文回答问题,减少幻觉。支持抗幻觉问答(QnA)、检索增强生成(RAG)和结构化信息提取(如 JSON)。由社区驱动,开源且免费。
2. 核心功能

3. 使用方法
安装
推荐:使用 TeapotAI 库(集成模型配置、嵌入处理等)。
替代:通过 Hugging Face transformers 直接调用模型。
示例场景
问答:
输入:上下文="巴黎是法国首都",问题="埃菲尔铁塔多高?"
输出:"上下文未提供该信息。"
RAG:
输入:多篇地标文档,问题="哪个地标建于19世纪?"
输出:"埃菲尔铁塔(1889年建成)。"
信息提取:
输入:公寓描述文本,Pydantic 模型定义
输出:{"租金": 2000, "卧室": 2, "电话": "123-456-7890"}
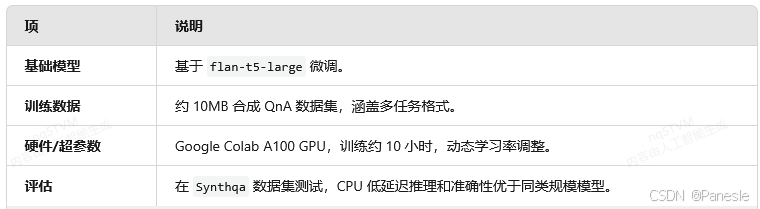
4. 技术细节
5. 局限性
适用场景:仅限问答/RAG/信息提取,不适用于代码生成、创意写作等。
语言支持:主要针对英语,未测试其他语言性能。
6. 总结
Teapot 是一款高效、轻量的任务专用模型,适合本地部署和精准信息处理,但在通用性上存在限制。
)




