PS:这个SPSS系列不是新坑,我会很快结束的,就是一个新玩具,不用脑子的新玩具上上手。。。
用SPSS处理,可视化傻瓜式的软件处理我个人是不喜欢的,因为太侮辱智商了,这年头真做统计操作了,哪个不是R或者Python起步。
不表,5mins内傻瓜式操作完成:
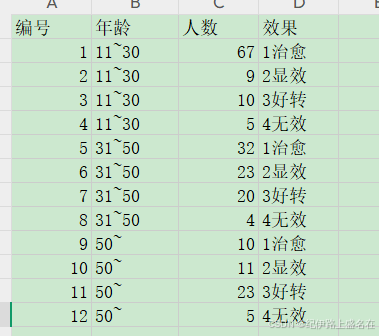
在excel中构建你的长数据,熟悉tidyverse中的long和wide数据格式;
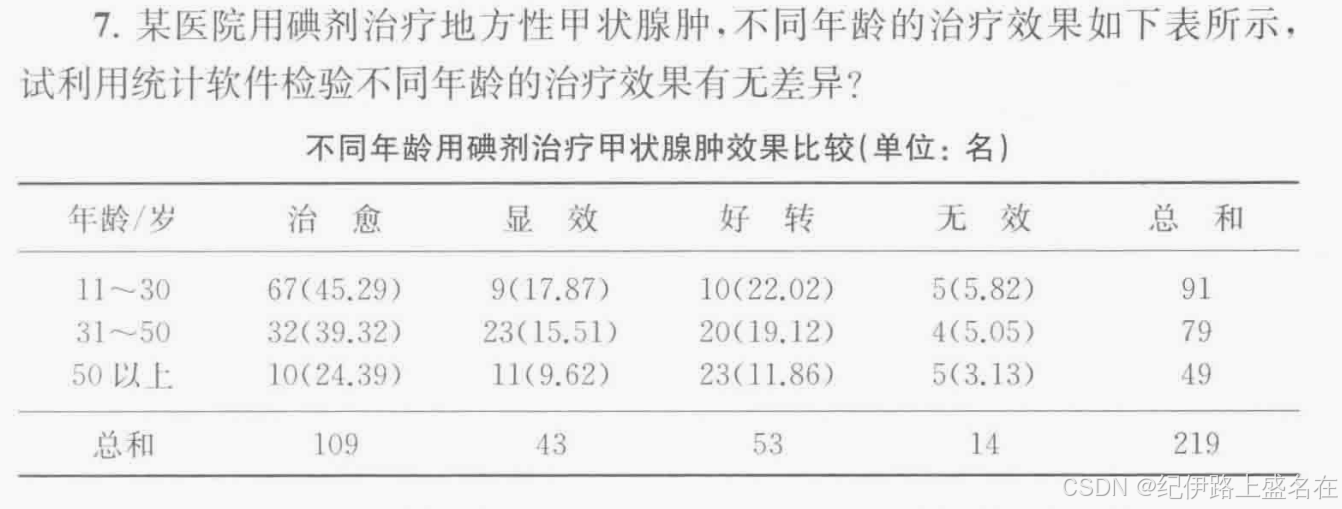
我们真正关心的只有年龄row,以及效果column
打开交叉表:
1,先对频数数据加权:
注意,频数数据,我们研究的是两个分类变量关系,两个分类变量目前是没有数据赋值的,咱们需要用这个频数据作为权重赋值给每个组合。因此基于频数数据资料进行统计分析,首先需要加权。
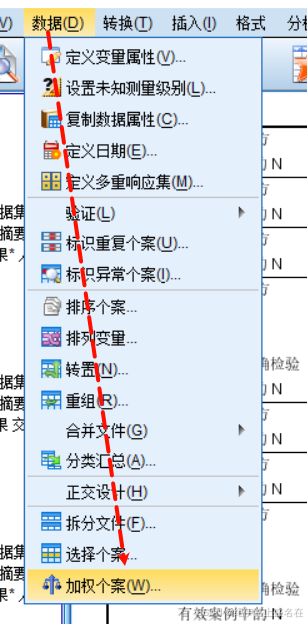
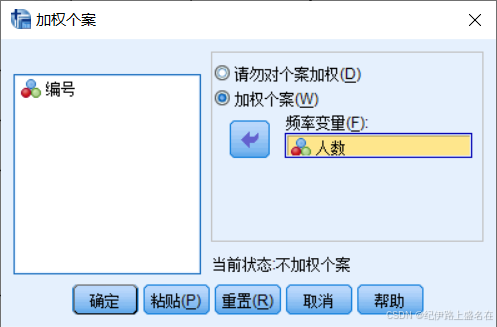
2,加权之后再点击交叉表:
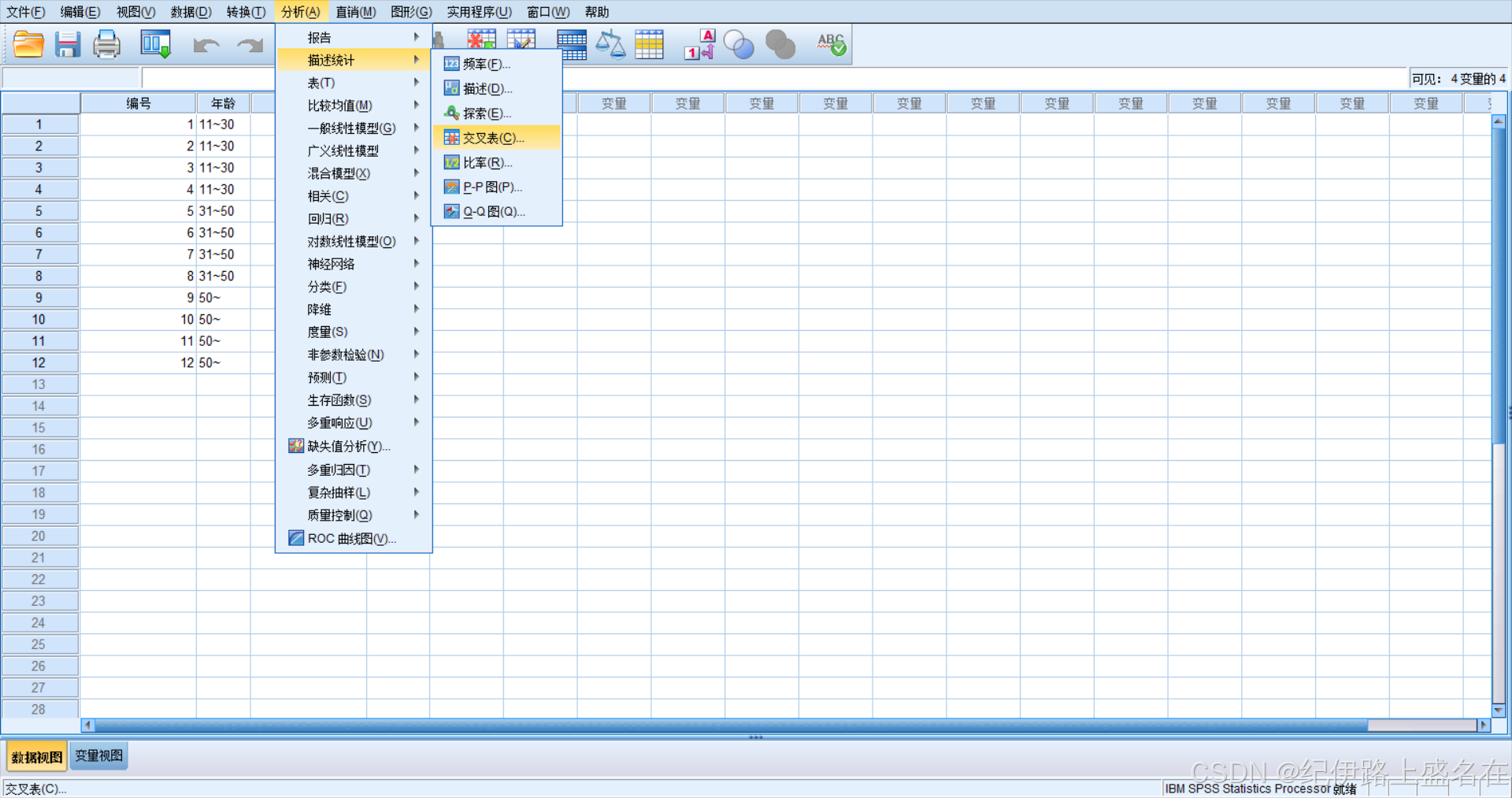
得到的是:
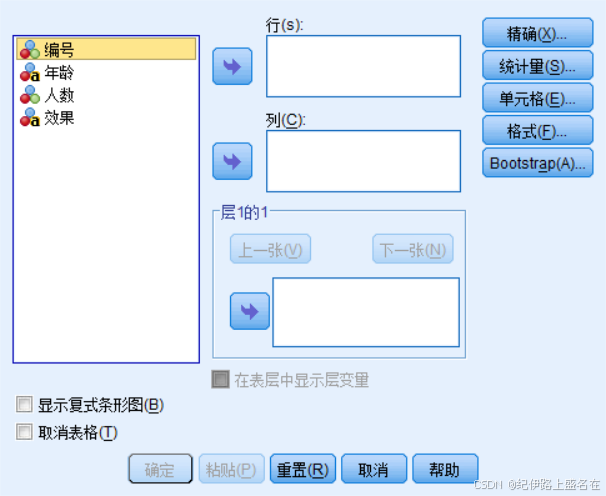
右边点开的统计量,选择卡方
格式上选择
大概效果:
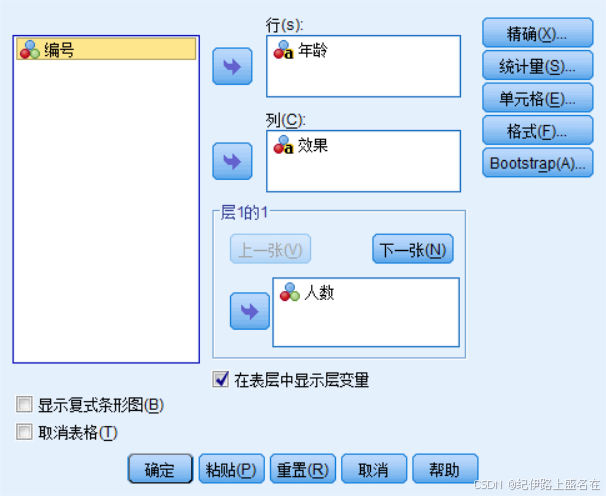
绘制的效果如下:
column变量factor的level有点反了,而且有个变量位置也变了,我们本质上是想探究两个分类变量之间的相关关系;
然后column列level的顺序order乱了,应该和unicode编码相关,索性就直接在first letter上做一个标志,就放个1234,反正column列变量的顺序也就看看:
改动如下:
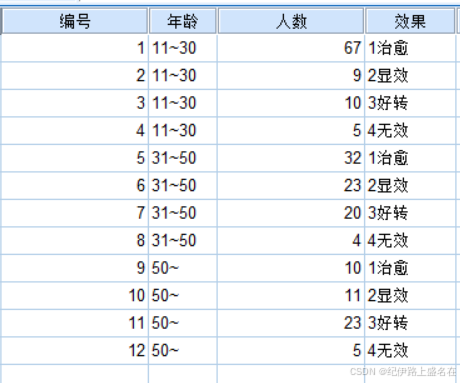
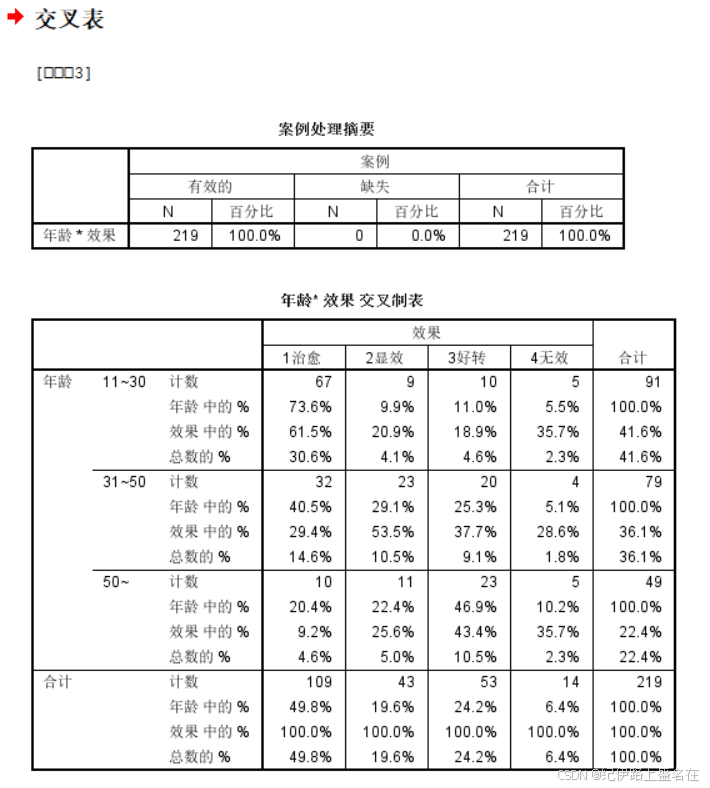
然后我们的这个数据实际上是不需要矫正的,虽然列联表用卡方检验需要矫正离散数据与连续多项式分布之间的显著性error,而且不同教材上的矫正条件也不同,但此处不需要矫正;
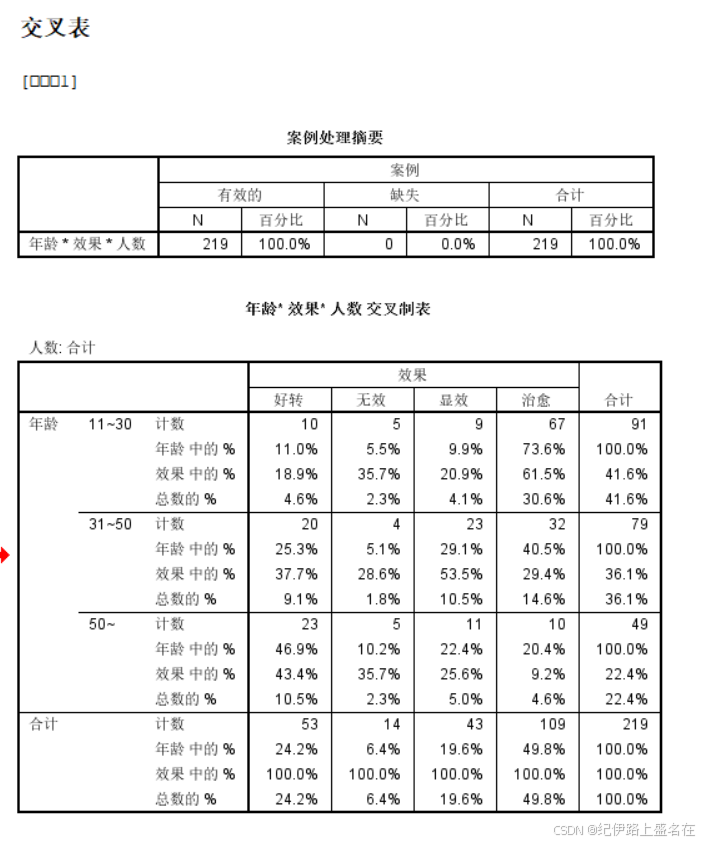
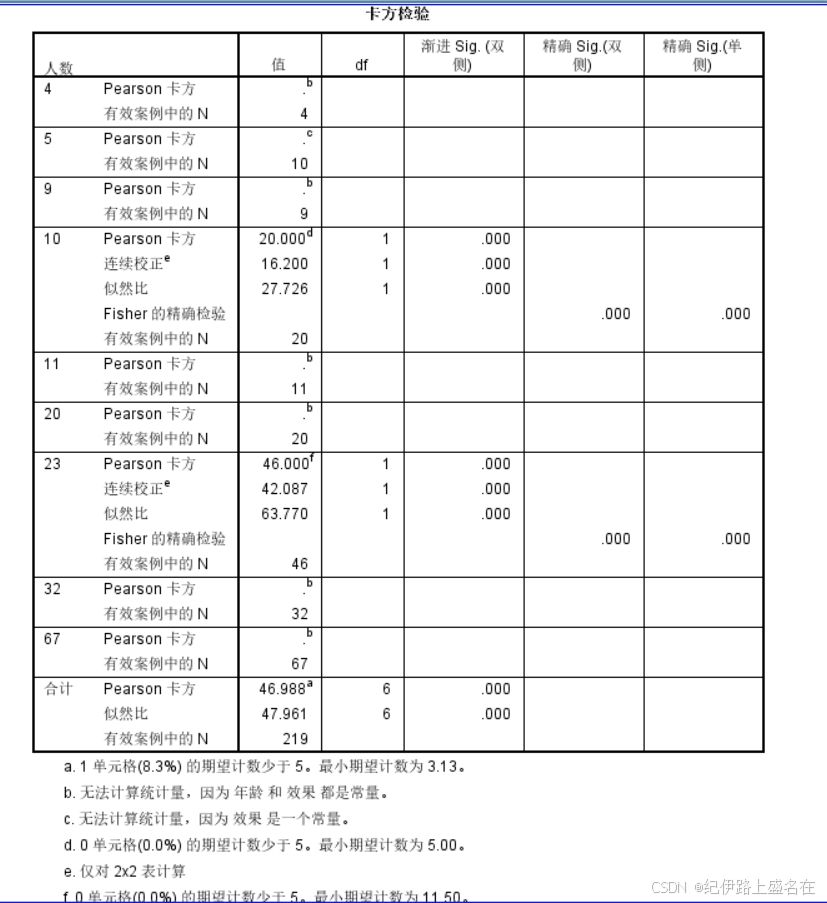
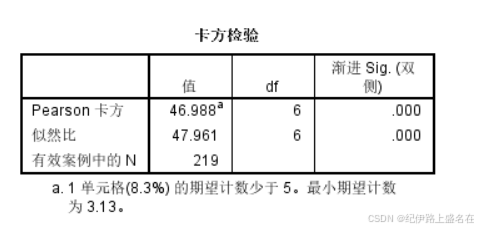
根据列联表卡方检验的使用条件,读取Pearson Chi-Square 统计检验结果。
说白了就是卡方统计量46.988,自由度为6,然后P value可能下溢了,导致显示的效果看不见,总之就是有统计学显著性差异;
我们的H0是行列向量也就是变量不相关,然后这里显然是拒绝H0,所以我们的数据是认为行变量与列变量存在相关关系,
其实从原始数据上直观看,就是年龄越大,越难治,效果越不好。
当然,以上正规内容其实可以到IBM中阅读帮助文档进行分析:
总之,SPSS这种玩意,就是个统计学软件玩具,和coding八竿子打不着,没必要花费力气去学;
参考:SPSS案例:RxC列联表卡方检验

)
` 不生效的问题)
的远程操作练习)

)
)