🧑 博主简介:曾任某智慧城市类企业
算法总监,目前在美国市场的物流公司从事高级算法工程师一职,深耕人工智能领域,精通python数据挖掘、可视化、机器学习等,发表过AI相关的专利并多次在AI类比赛中获奖。CSDN人工智能领域的优质创作者,提供AI相关的技术咨询、项目开发和个性化解决方案等服务,如有需要请站内私信或者联系任意文章底部的的VX名片(ID:xf982831907)
💬 博主粉丝群介绍:① 群内初中生、高中生、本科生、研究生、博士生遍布,可互相学习,交流困惑。② 热榜top10的常客也在群里,也有数不清的万粉大佬,可以交流写作技巧,上榜经验,涨粉秘籍。③ 群内也有职场精英,大厂大佬,可交流技术、面试、找工作的经验。④ 进群免费赠送写作秘籍一份,助你由写作小白晋升为创作大佬。⑤ 进群赠送CSDN评论防封脚本,送真活跃粉丝,助你提升文章热度。有兴趣的加文末联系方式,备注自己的CSDN昵称,拉你进群,互相学习共同进步。

【机器学习案列】基于LightGBM算法的互联网防火墙异常行为检测:数据不平衡的解决方案
- 一、引言
- 二、数据预处理:奠定分析基础
- 2.1 数据读取与初步观察
- 2.2 数据清洗
- 三、数据分布与特征分析:洞察数据本质
- 3.1 观测值分布
- 3.2 相关性分析
- 四、模型构建与训练:LightGBM的高效应用
- 4.1 数据集划分
- 4.2 特征缩放
- 4.3 模型训练与评估
- 五、数据重采样:解决不平衡的有力武器
- 5.1 SMOTETomek算法的应用
- 5.2 重采样后的模型训练与评估
- 六、模型特征重要性:解读关键因素
一、引言
在互联网安全领域,防火墙作为抵御外部威胁的第一道防线,其行为检测的准确性至关重要。然而,在实际的日志数据中,正常行为与异常行为的比例往往失衡,这给模型训练带来了挑战。本文将分享如何利用LightGBM算法,并结合数据重采样技术,有效检测互联网防火墙的异常行为。
二、数据预处理:奠定分析基础
2.1 数据读取与初步观察
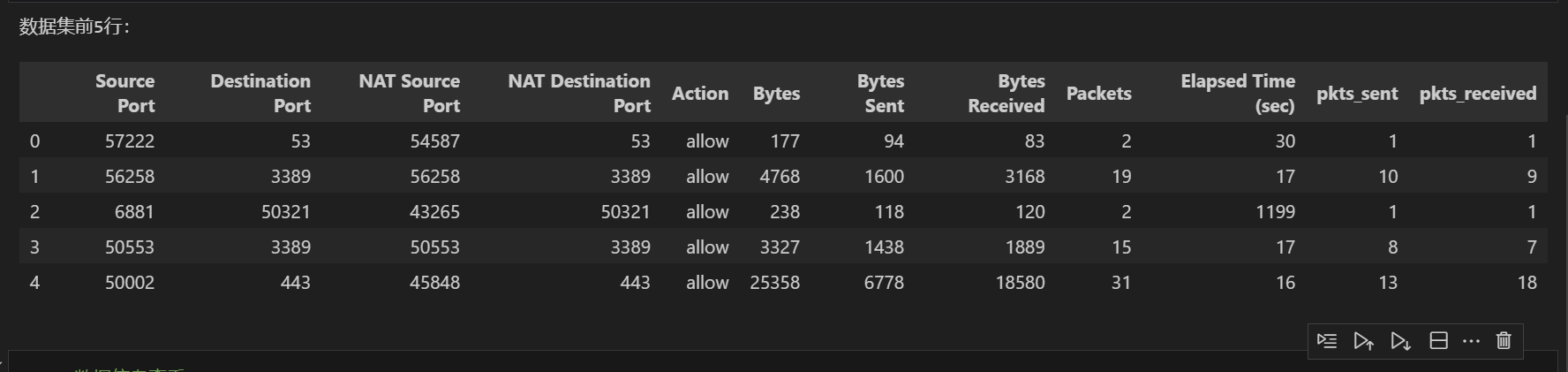
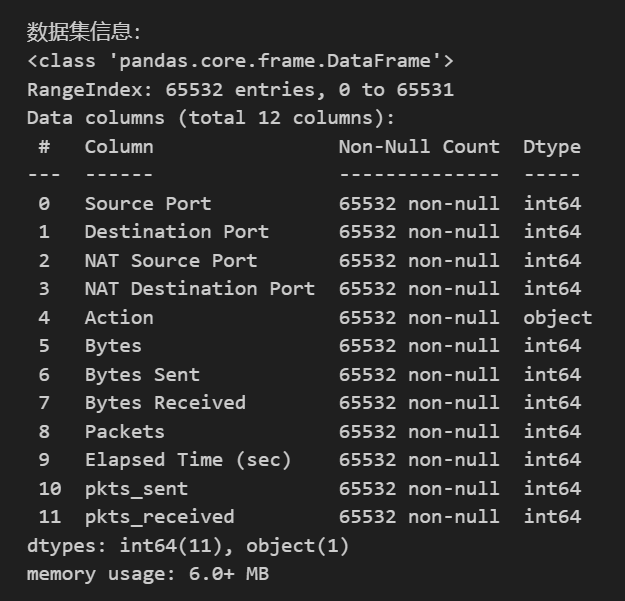
使用pandas库读取防火墙日志数据,初步查看数据的前几行,了解特征和目标变量的基本情况。通过df.head()可以快速获取数据的直观印象,而df.info()则提供了数据类型、非空值数量等重要信息,为后续处理提供依据。
# 数据读取与初步观察
df = pd.read_csv("log2.csv")
print("数据集前5行:")
df.head()
# 数据信息查看
print("\n数据集信息:")
df.info()
2.2 数据清洗
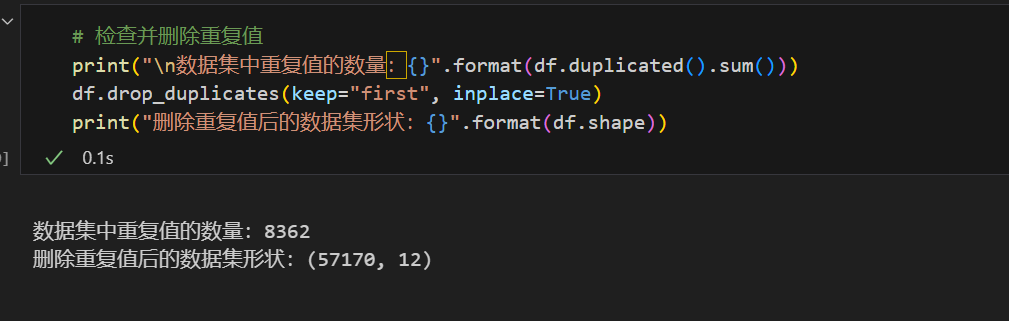
检查数据中的重复值,使用df.duplicated().sum()统计重复值数量,并通过df.drop_duplicates()删除重复记录,保留首次出现的行,确保数据的纯净性,避免重复信息对模型训练的干扰。
三、数据分布与特征分析:洞察数据本质
3.1 观测值分布
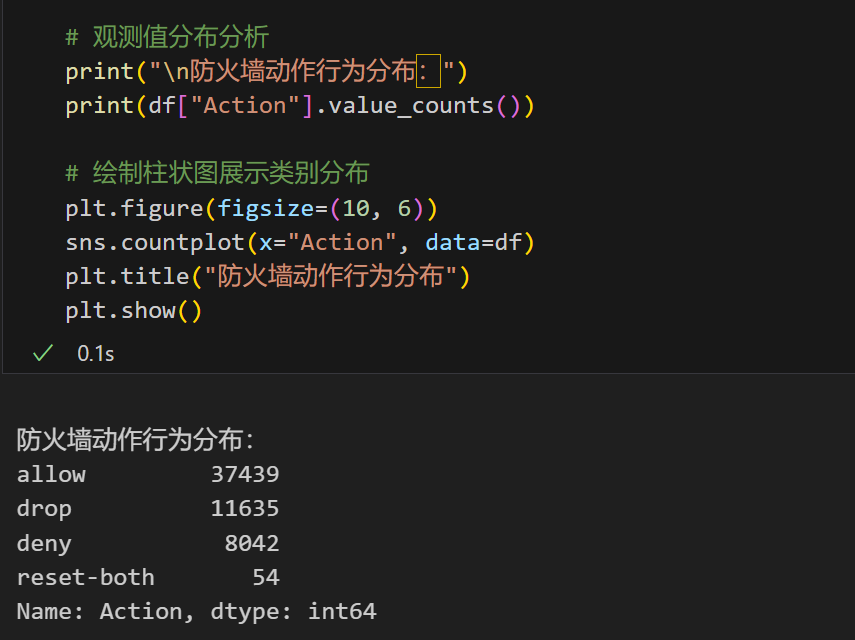
绘制柱状图展示防火墙动作行为的类别分布,发现数据集中存在严重的类别不平衡问题。其中,某一类(如allow类)出现频率极高,而其他类别(如reset-both类等)相对较少。这种不平衡可能导致模型在训练过程中过于偏向多数类,而忽视少数类的特征,从而影响整体预测性能。
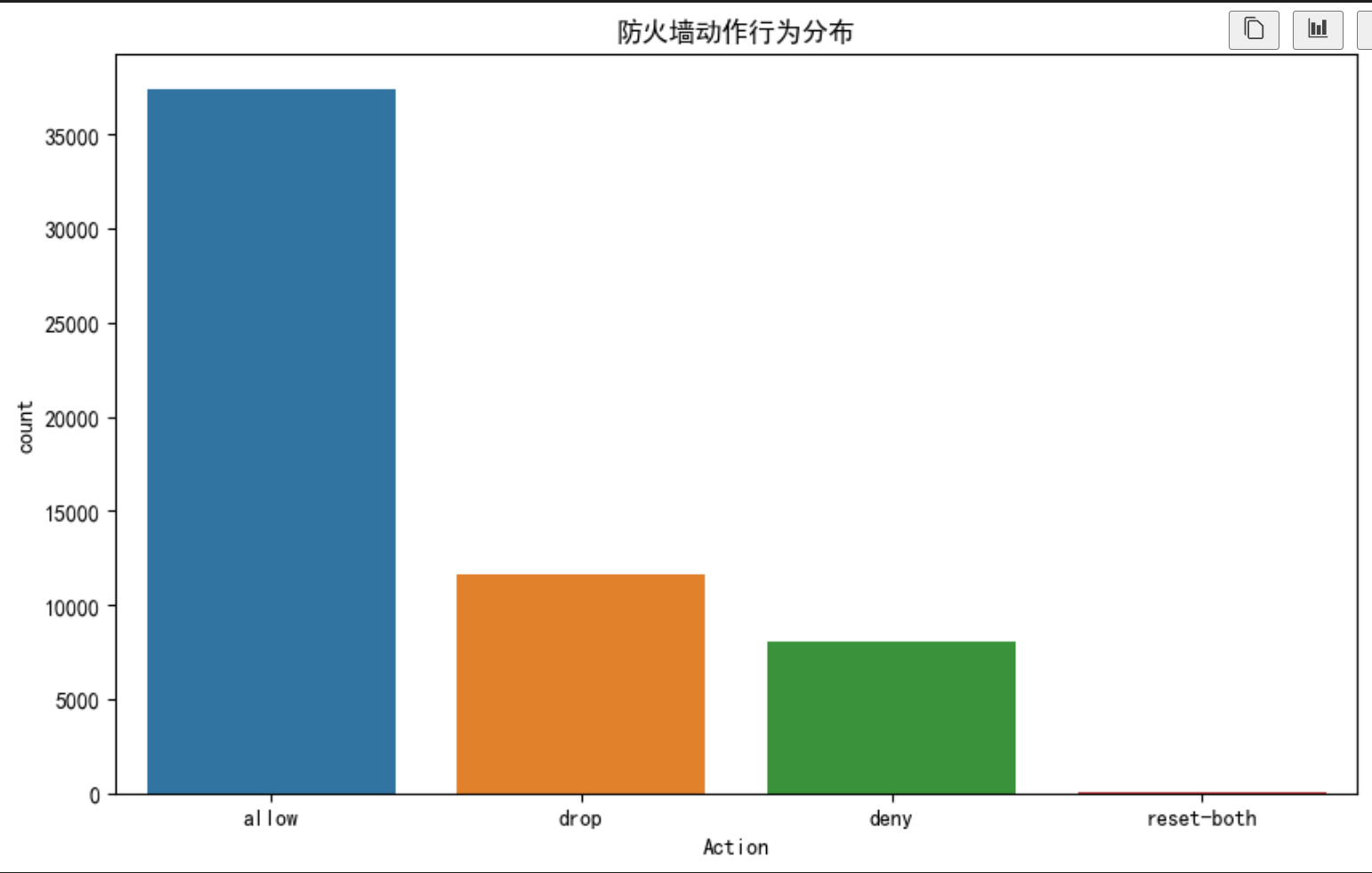
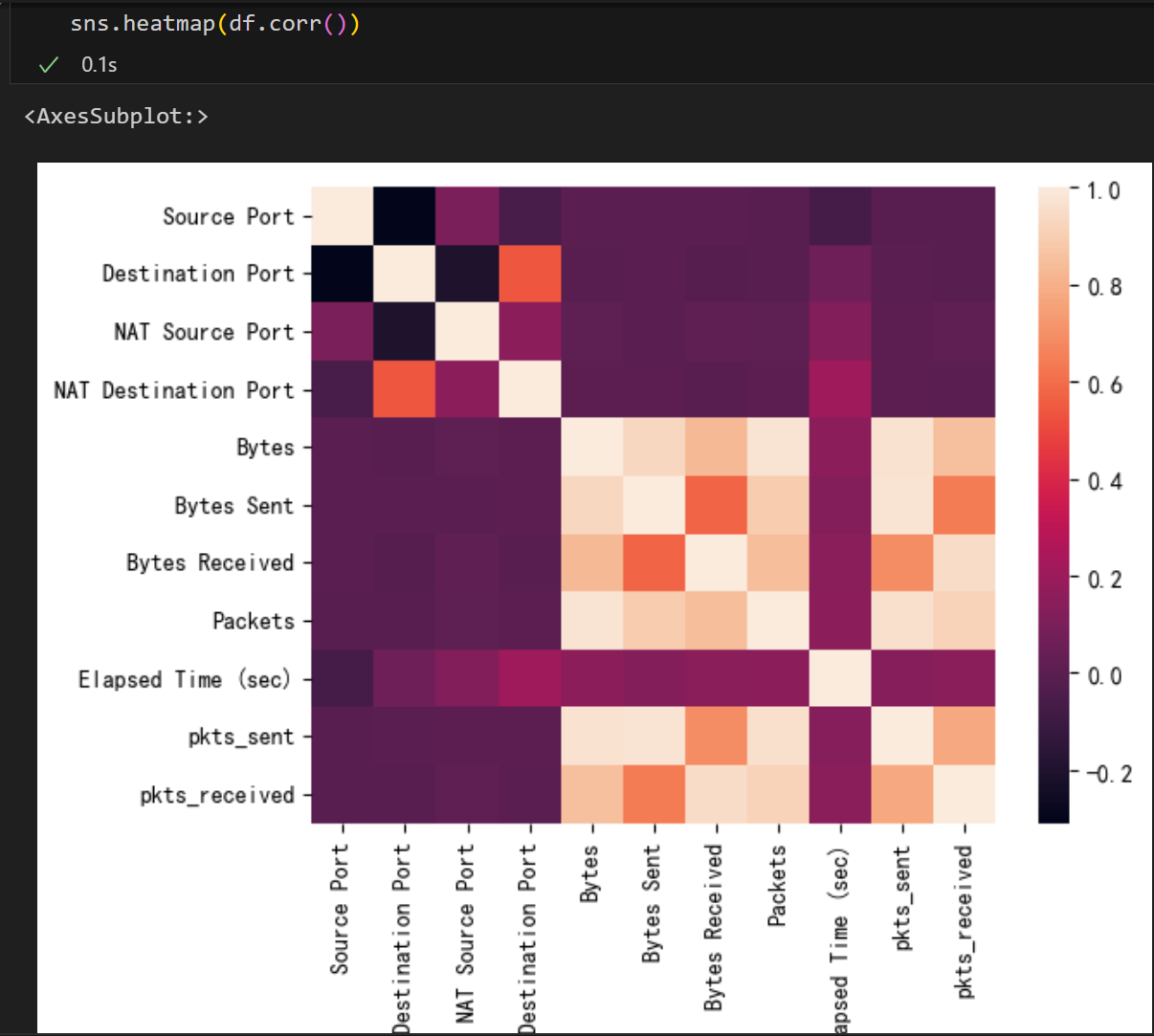
3.2 相关性分析
通过绘制相关性热力图,分析各特征值与观测值之间的相关性。结果表明,大部分特征与观测值的相关性不明显,甚至存在负相关情况。
四、模型构建与训练:LightGBM的高效应用
4.1 数据集划分
将数据集划分为训练集和测试集,采用常见的8:2比例,确保模型在足够的数据上进行学习,同时保留一部分数据用于评估模型的泛化能力。
# 数据集划分
X = df.drop("Action", axis=1)
y = df["Action"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
4.2 特征缩放
使用MinMaxScaler对特征数据进行标准化处理,将特征值缩放到0-1的范围内。这有助于加速模型的收敛速度,并提高模型的稳定性。
# 标签编码
le = LabelEncoder()
df["Action"] = le.fit_transform(df["Action"])# 特征缩放
ss = MinMaxScaler()
# 对训练集进行特征缩放
X_scaler_train = ss.fit_transform(X_train)
X_scaler_test = ss.transform(X_test)
4.3 模型训练与评估
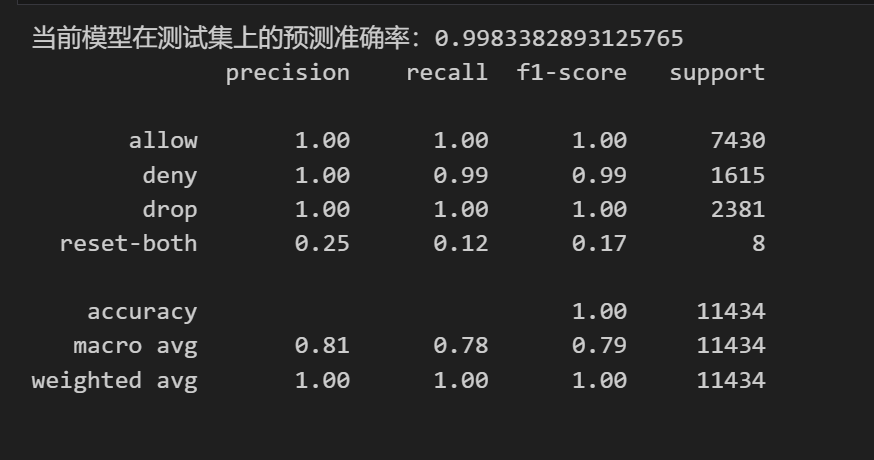
选择LightGBM算法作为分类模型,其在处理大规模数据和高维特征时具有高效性和鲁棒性。通过训练模型并使用测试集进行预测,计算预测准确率和分类报告。
# 创建LightGBM模型
model = lgb.LGBMClassifier(verbose=-1)# 模型训练
model.fit(X_scaler_train, y_train)# 使用模型预测测试集
y_pred = model.predict(X_scaler_test)# 使用预测准确率评估模型
print("当前模型在测试集上的预测准确率:{}".format(accuracy_score(y_test, y_pred)))# 查看分类报告结果
print(classification_report(y_test, y_pred))
五、数据重采样:解决不平衡的有力武器
5.1 SMOTETomek算法的应用
为了解决数据不平衡问题,采用SMOTETomek算法对训练数据进行重采样。该算法结合了过采样和欠采样的优点,对多数类进行欠采样,同时对少数类进行过采样,使得各类别的数据量更加均衡。经过重采样后的训练数据,各类别的比例接近1:1:1:1,为模型训练提供了更公平的数据基础。
# 使用SMOTETomek进行过采样和欠采样
smote_tomek = SMOTETomek(random_state=42)
X_resampled, y_resampled = smote_tomek.fit_resample(X_train, y_train)# 对重采样后的数据进行特征缩放
X_scaler_train_resampled = ss.fit_transform(X_resampled)
X_scaler_test_resampled = ss.transform(X_test)df_label = pd.DataFrame(y_resampled)# 绘制柱状图展示类别分布
plt.figure(figsize=(10, 6))
sns.countplot(x="Action", data=df_label)
plt.title("防火墙动作行为分布")
plt.show()
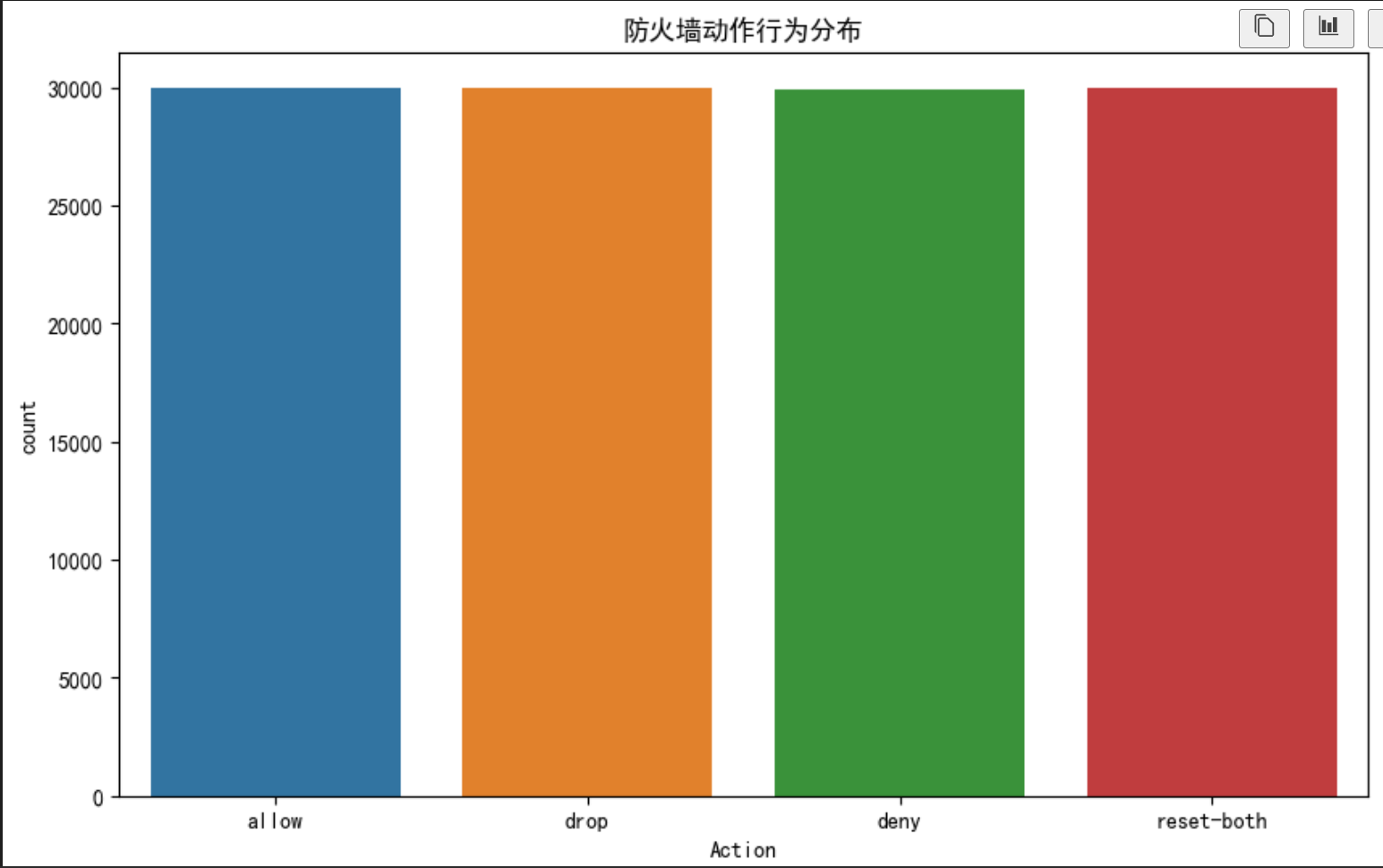
5.2 重采样后的模型训练与评估
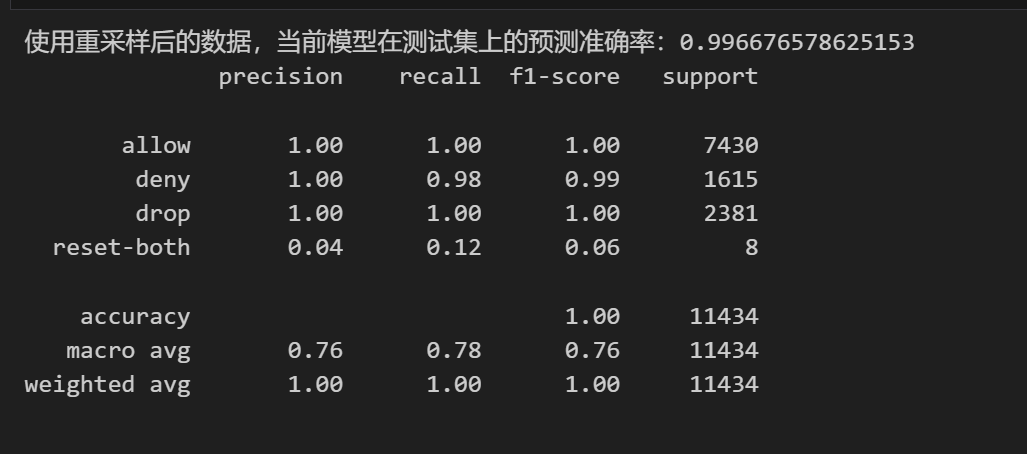
使用重采样后的数据重新训练LightGBM模型,并在原始测试集上进行评估。结果如下:
# 模型训练
model.fit(X_scaler_train_resampled, y_resampled)# 使用模型预测测试集
y_pred_resampled = model.predict(X_scaler_test_resampled)# 使用预测准确率评估模型
print("使用重采样后的数据,当前模型在测试集上的预测准确率:{}".format(accuracy_score(y_test, y_pred_resampled)))# 查看分类报告结果
print(classification_report(y_test, y_pred_resampled))
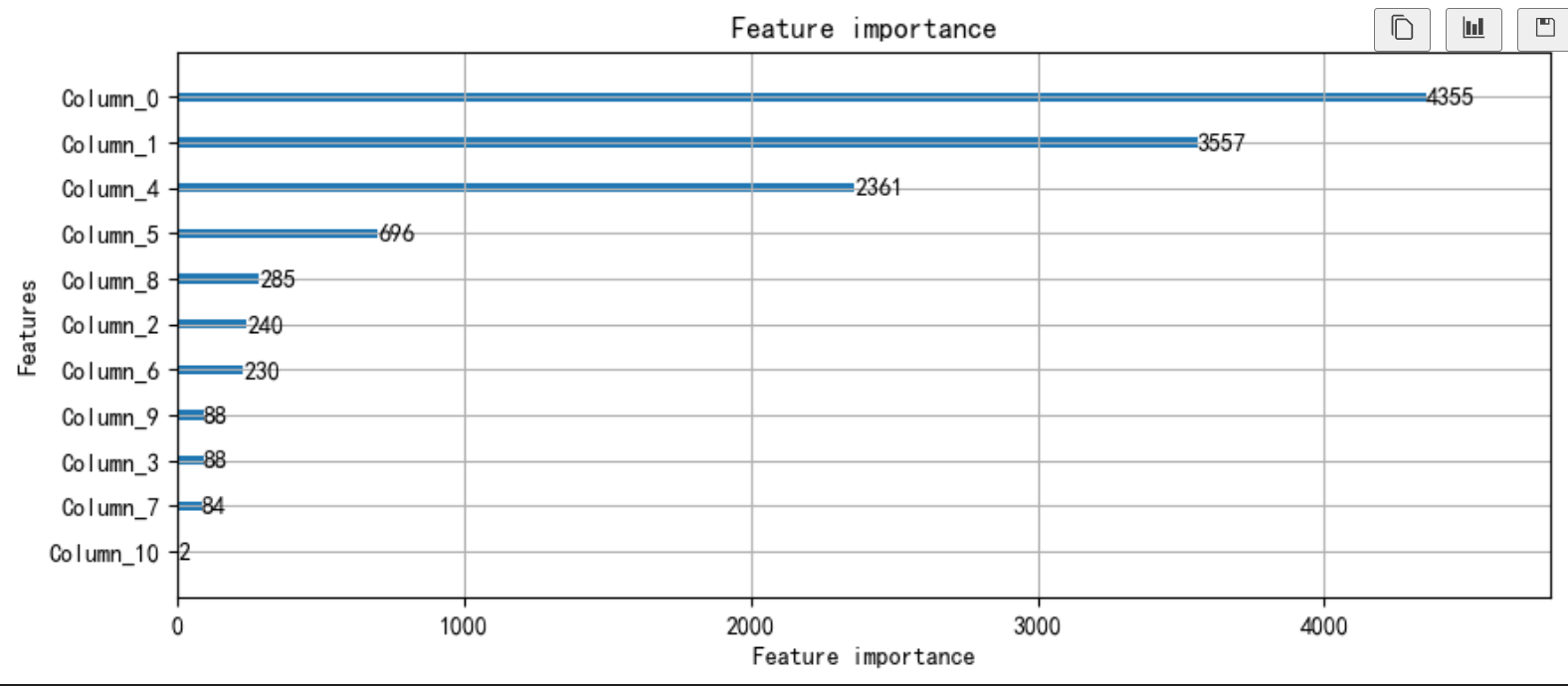
六、模型特征重要性:解读关键因素
通过打印模型的特征重要性,可以了解哪些特征对防火墙异常行为的预测具有关键影响。有助于我们理解模型的决策过程,能为后续的数据收集和特征工程提供指导,优化模型的输入特征,进一步提升模型性能。
# 绘制特征重要性
fig, ax = plt.subplots(figsize=(10, 8))
lgb.plot_importance(model, max_num_features=20, ax=ax)
plt.show()
在互联网防火墙异常行为检测中,合理处理数据不平衡问题对于提高模型的准确性和可靠性至关重要。


)

——处理数据流的中位数)