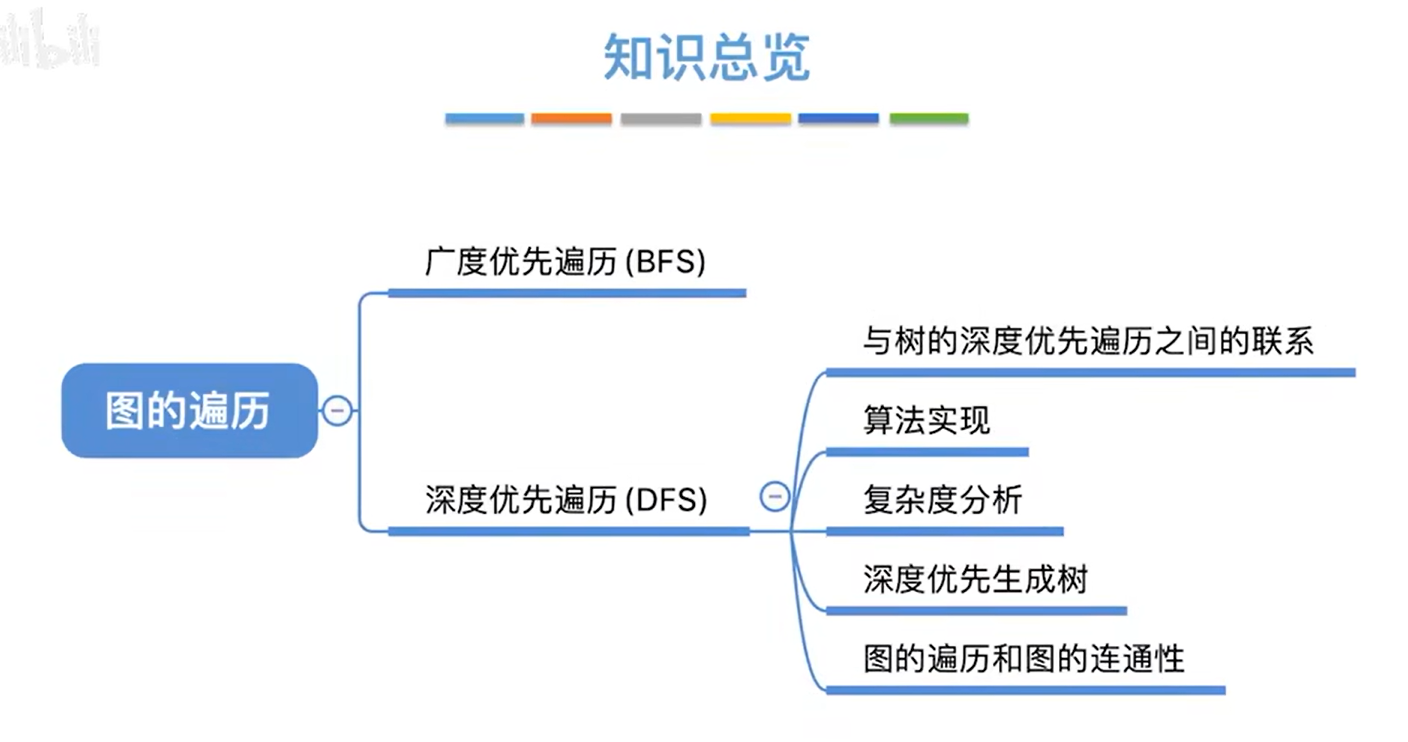
-
树是特殊的图,没有回路的图就是树
-
BFS与DFS的区别在于,BFS使用了队列,DFS使用了栈
一.深度优先遍历:
1.树的深度优先遍历:
树的深度优先遍历分为先根遍历和后根遍历。
以树的先根遍历为例:
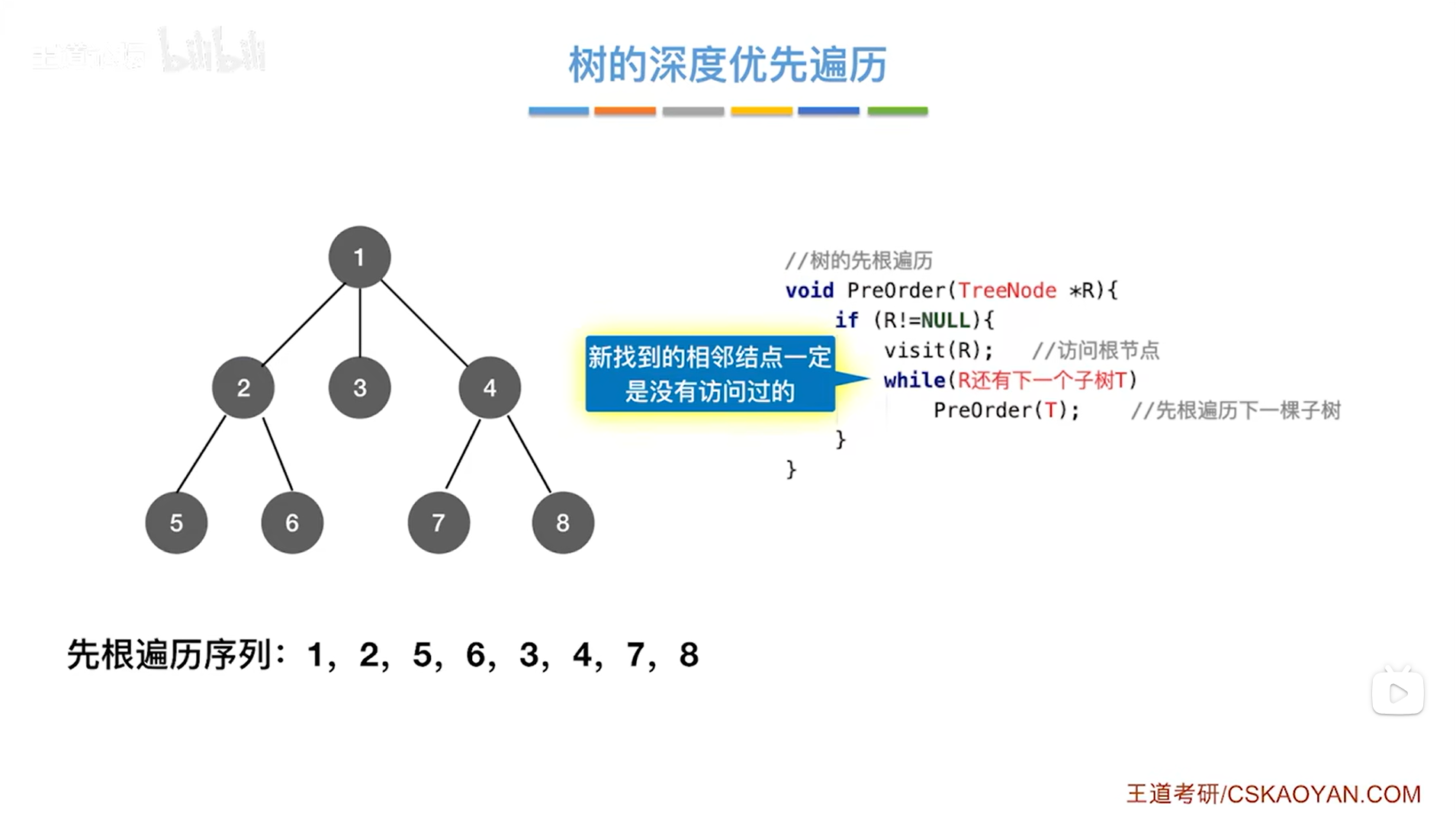
-
上述图片里树的先根遍历序列为1、2、5、6、3、4、7、8
-
树的先根遍历中新找到的相邻结点一定是没有被访问过的
2.图的深度优先遍历:
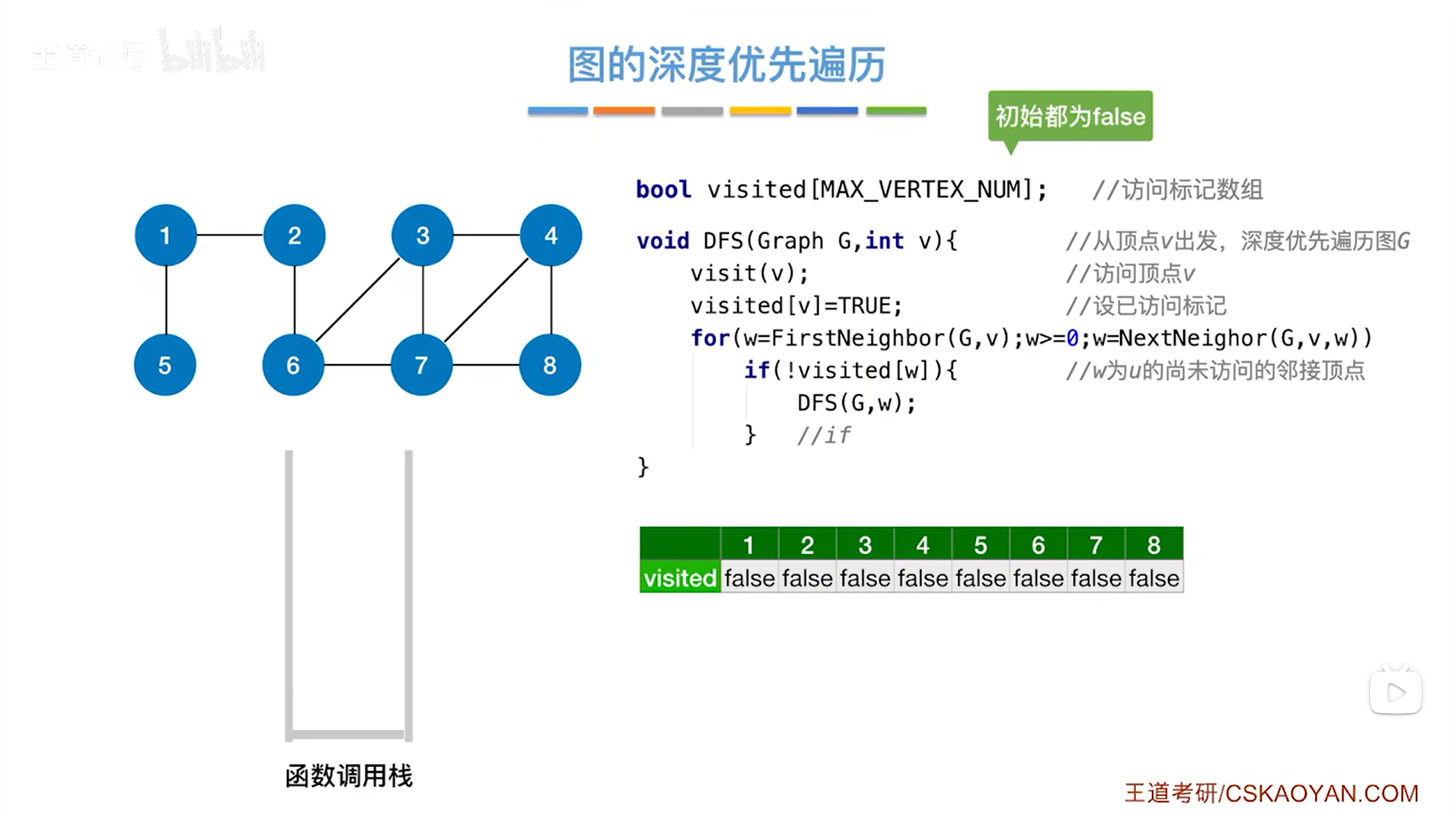
-
visited数组用来记录图中的顶点是否被访问过,MAX_VERTEX_NUM是图中顶点的最大个数,DFS函数的形参Graph G和int v分别表示图和图的顶点编号,visit函数用于访问顶点,visit(v)表示访问第v号顶点,visited[v]=true表示第v号顶点被访问过
-
DFS函数中的for循环,其中FirstNeighbor(G,v)用来找第v号顶点在G中的第一个邻接点,若存在该邻接点,返回该第一个邻接点的编号,赋值给w,如果w非负,执行for循环,首先判断是否执行if语句,若符合条件!visited[w]为true即第w号顶点没有被访问过,那么就执行if语句,调用DFS函数,该层for循环结束,再执行NextNeighbor(G,v,w)函数,第w号顶点是第v号顶点的第一个邻接点,找除了第w号顶点外第v号顶点的的下一个邻接点,找到了返回该邻接点的顶点号,赋值给w,判断是否非负,若非负,继续执行for循环,如不是非负即小于0,跳出for循环
-
图的深度优先遍历类似树的先根遍历,都是先访问完一个结点,然后再用一个循环依次检查和这个结点相邻的其他结点,然后进行更深一层的访问,只不过对于图的深度优先遍历,增加了一个数组用来标记顶点是否被访问过
-
对于图而言,通过某一个顶点找到的与之相邻的其他顶点有可能是已经被访问过的,所以可以设置一个数组,用来标记每一个顶点是否被访问过
3.模拟图的深度优先遍历的执行过程:
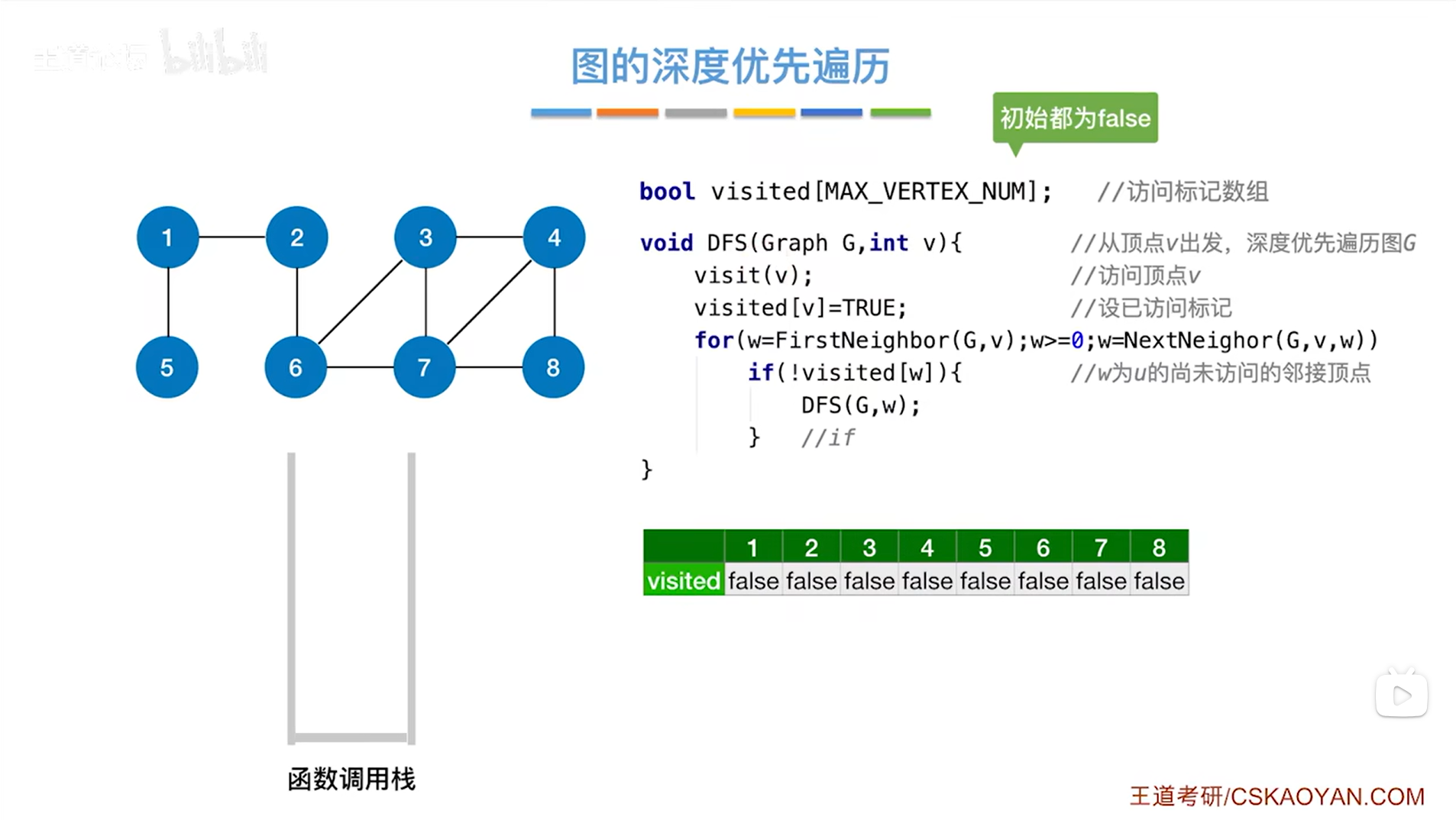
如下图,以上述图片的图为例,假设从2号顶点出发深度优先遍历该图,所以第一次调用DFS函数的时候,传入的v的值为2,然后调用visit函数访问2号顶点,修改2号顶点对应的visited的值为true,表示2号顶点已经被访问过,for循环用来检查和2号顶点相邻的其他顶点,和2号顶点相邻的顶点是1、6号顶点,其中和2号顶点相邻的第一个顶点是1号顶点,此时1号顶点没有被访问过:
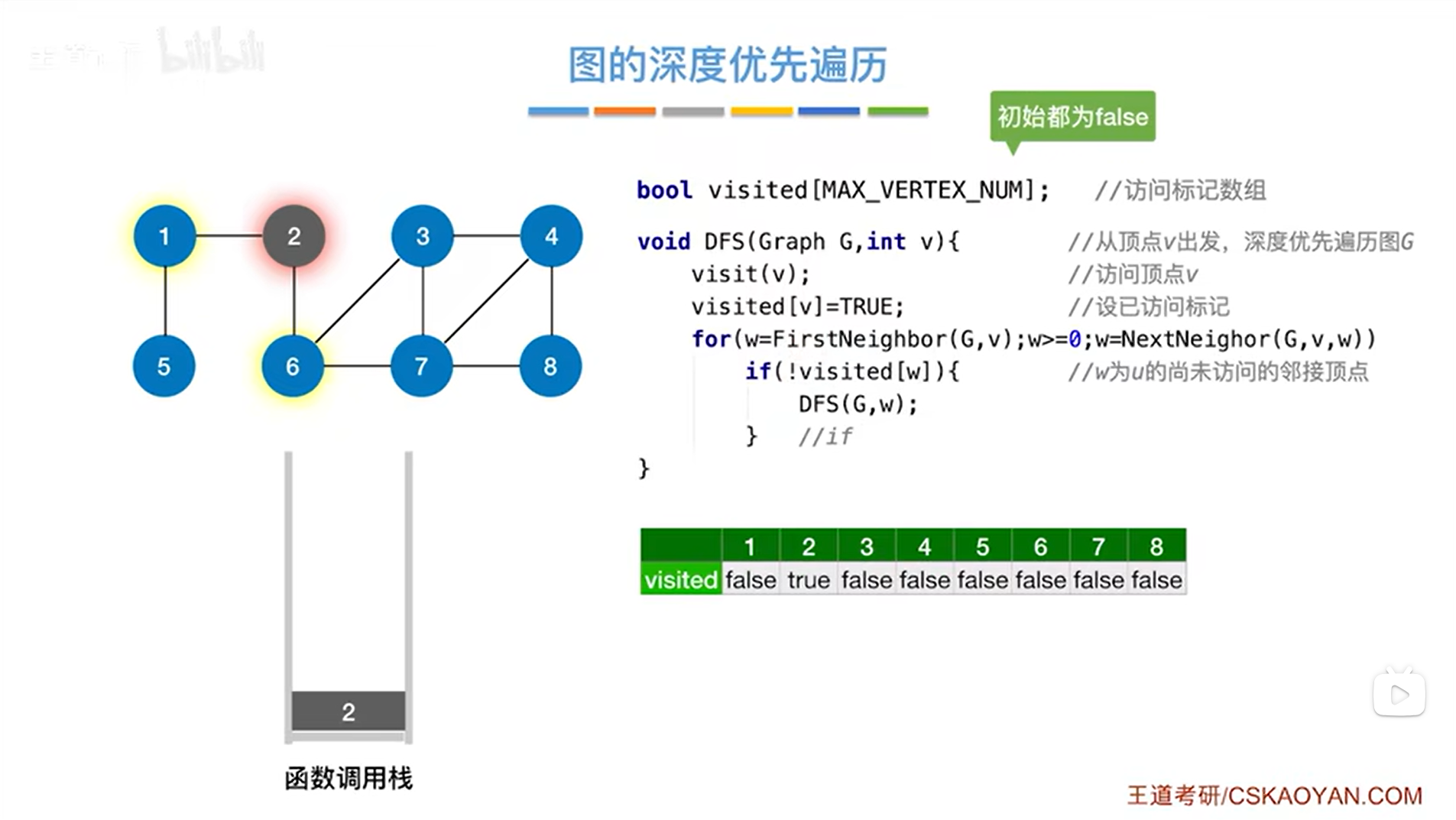
如下图,因此第二次调用DFS函数时传入的参数为1,然后调用visit函数访问1号顶点,修改1号顶点对应的visited的值为true,表示1号顶点已经被访问过,for循环用来检查和1号顶点相邻的其他顶点,和1号顶点相邻的顶点是2、5号顶点,其中和1号顶点相邻的第一个顶点是2号顶点,由于2号顶点对应的visited的值为true即已经被访问过,因此2号顶点会被跳过,通过for循环找到下一个和1号顶点相邻接的顶点是5号顶点:
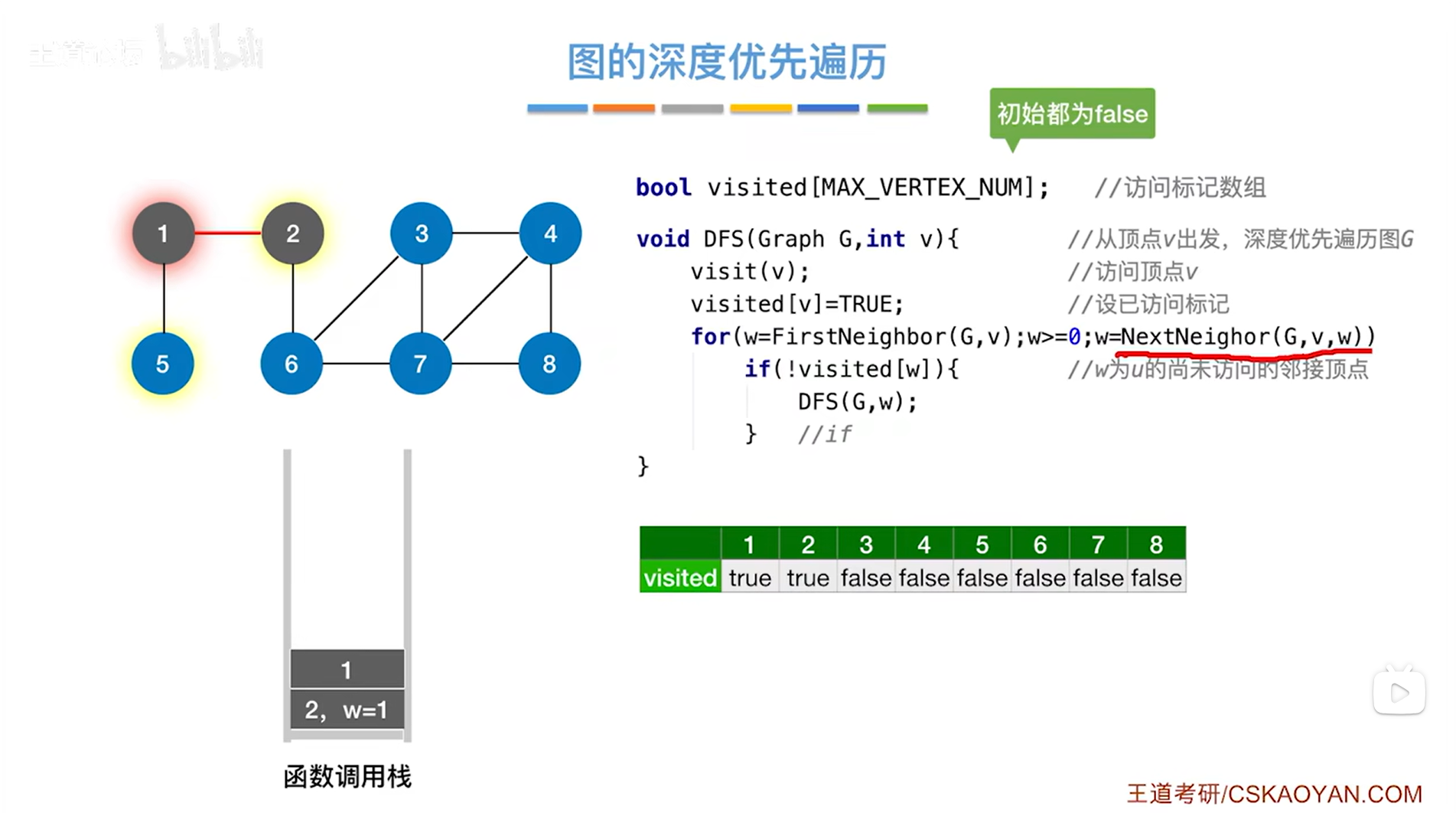
如下图,因此第三次调用DFS函数时传入的参数为5,然后调用visit函数访问5号顶点,修改5号顶点对应的visited的值为true,表示5号顶点已经被访问过,for循环用来检查和5号顶点相邻的其他顶点,和5号顶点相邻的顶点是1号顶点,由于1号顶点对应的visited的值为true即已经被访问过,因此1号顶点会被跳过,此时和5号顶点相邻的所有顶点全部访问完毕,意味着5号顶点对应的for循环什么都不会做:
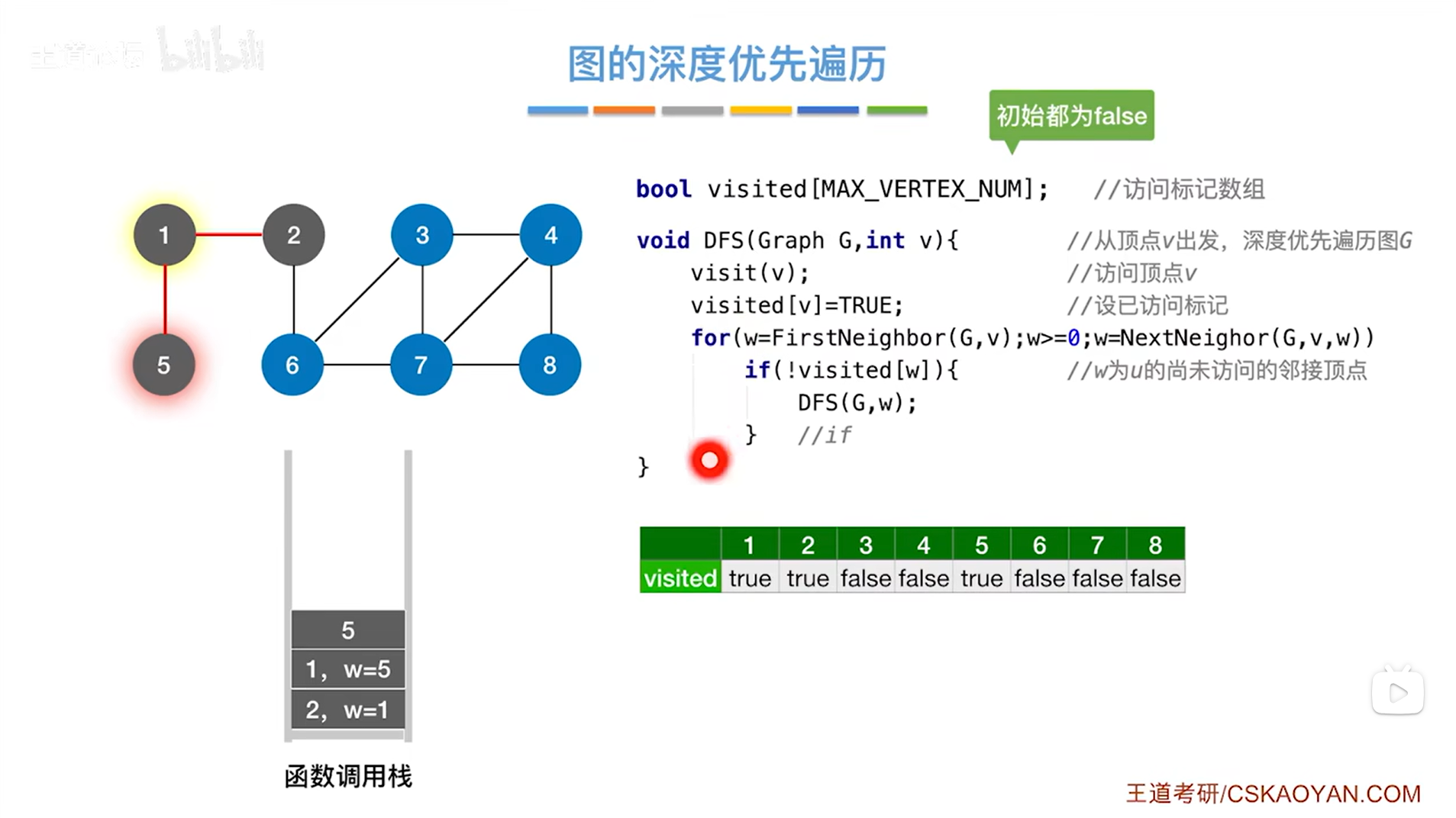
如下图,所以5号顶点对应的DFS函数执行完毕,之后就会返回上一层的递归调用,即1号顶点这一层:
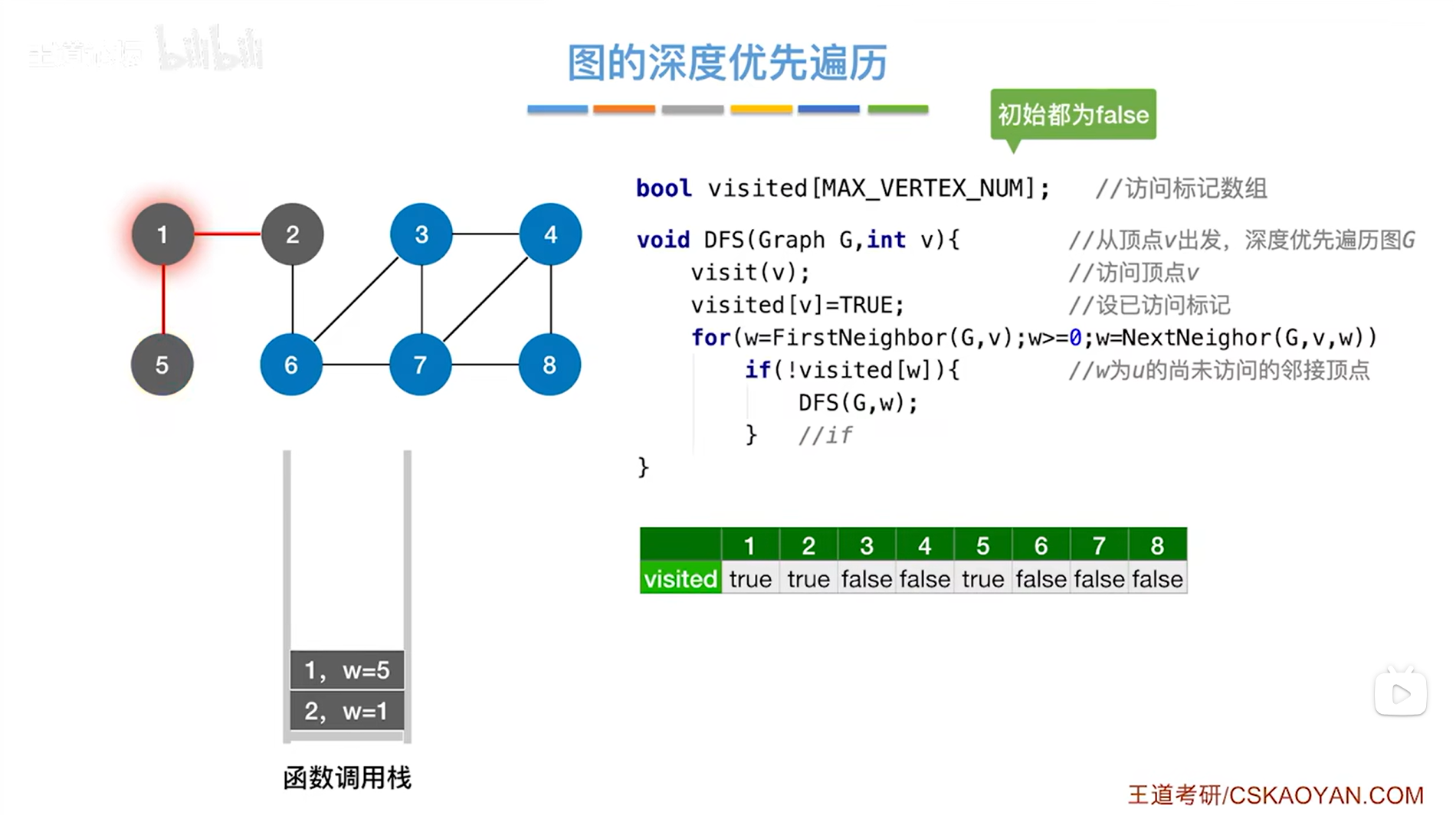
如下图,由于之前处理的5号顶点已经是1号顶点的最后一个邻接点,所以1号顶点的for循环执行完毕,因此1号顶点对应的DFS函数执行结束,最终返回上一层的递归调用,即2号顶点这一层:
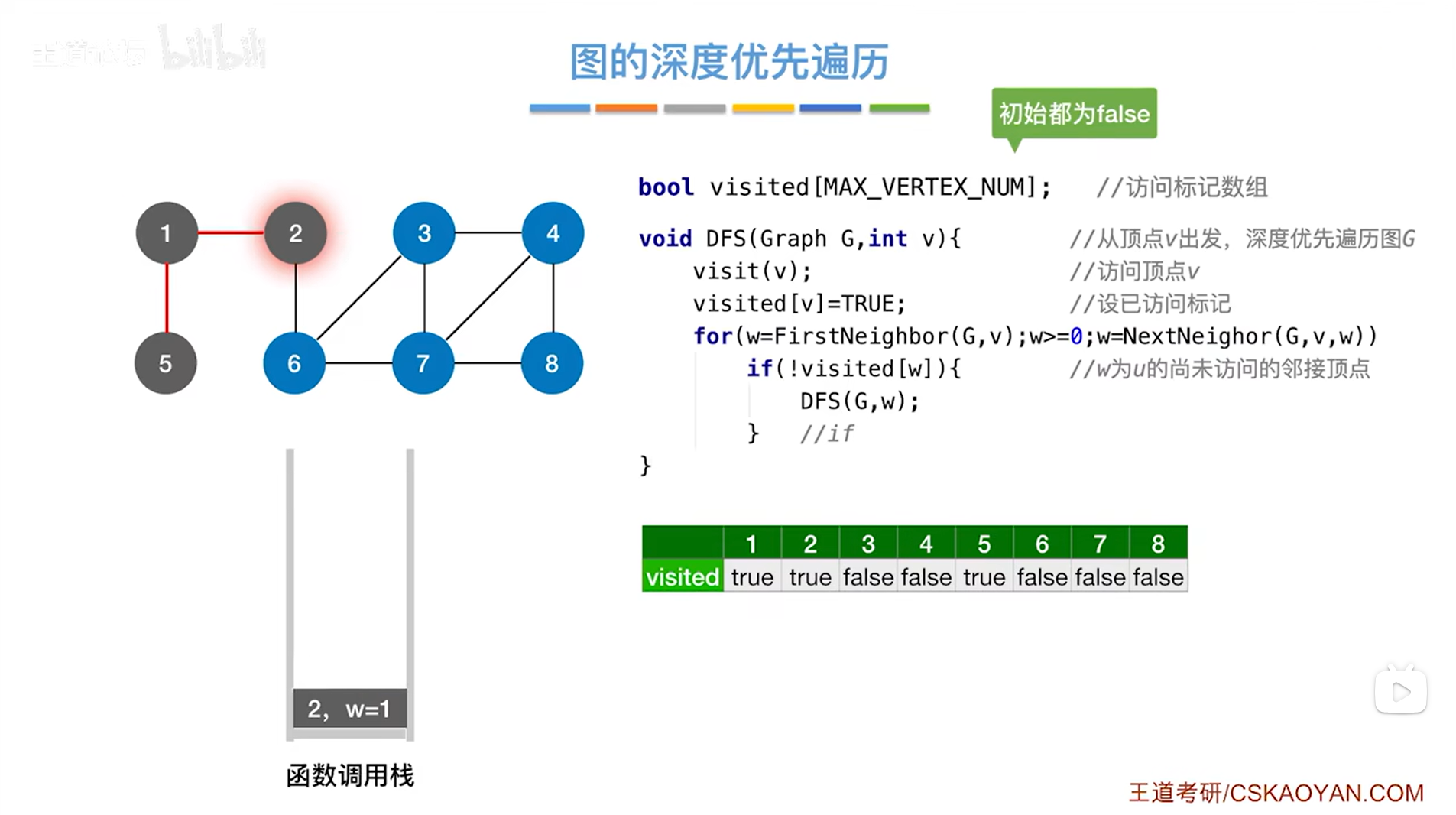
如下图,此时2号顶点的第一个邻接点即1号顶点已经被处理完,通过NextNeighor(G,v,w)函数找到除了1号顶点之外后一个和2号顶点相邻接的顶点即6号顶点,6号顶点此时还没有被访问过:
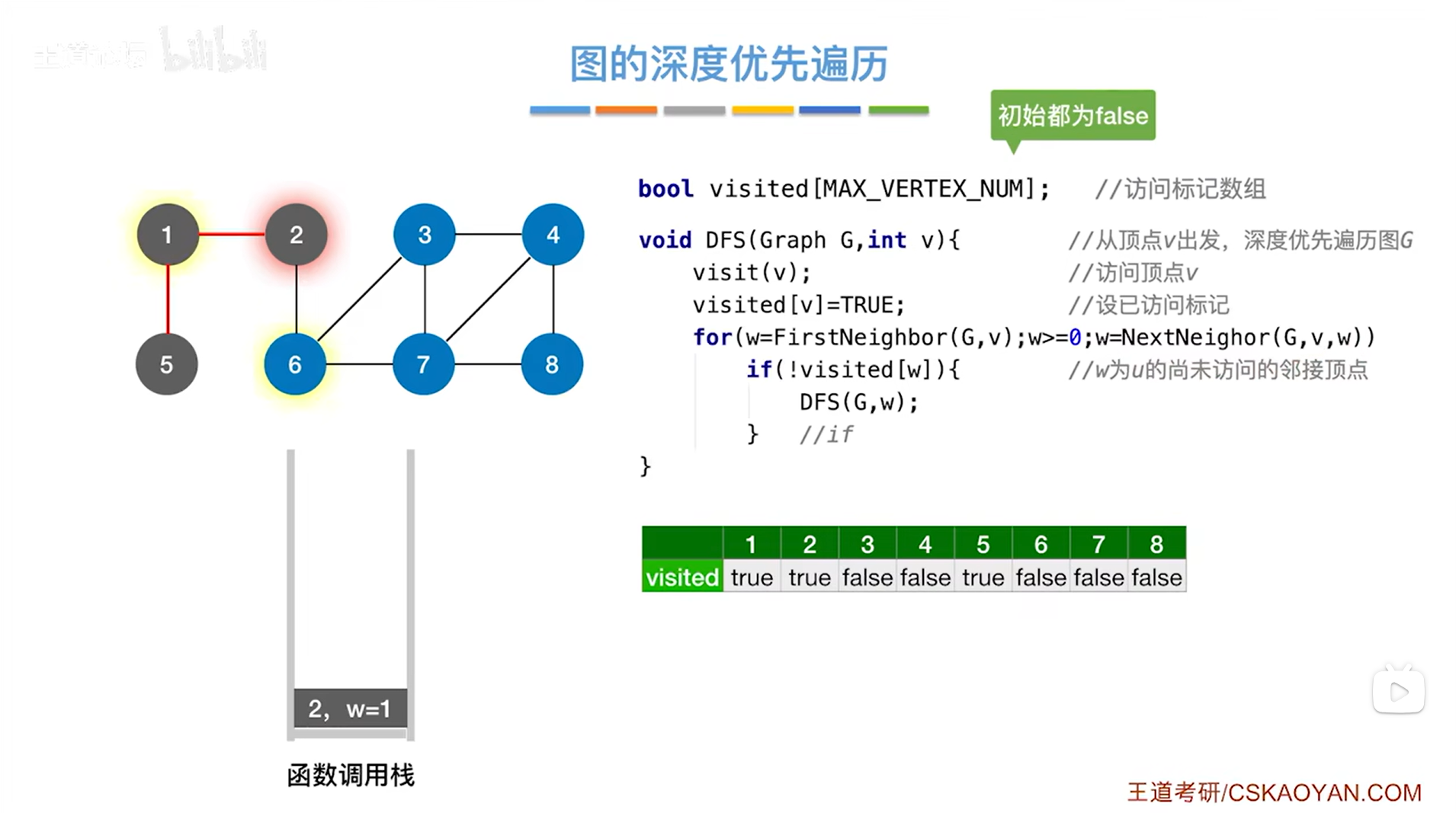
如下图,因此接下来调用DFS函数时传入的参数为6,然后调用visit函数访问6号顶点,修改6号顶点对应的visited的值为true,表示6号顶点已经被访问过,for循环用来检查和6号顶点相邻的其他顶点,和6号顶点相邻的顶点是2、3、7号顶点,由visited数组可知2号顶点已经被访问过,因此会跳过2号顶点,开始访问3号顶点:
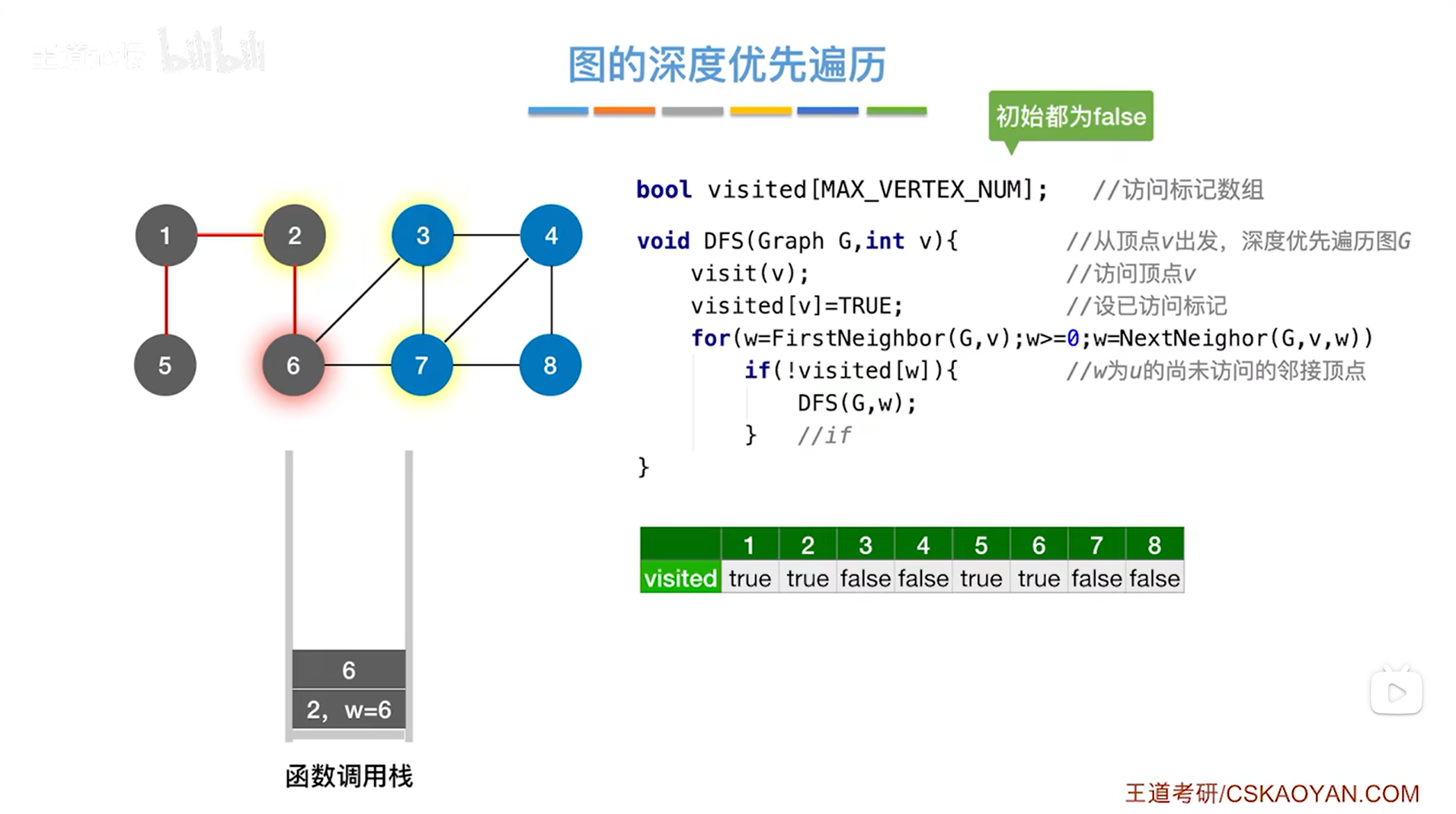
如下图,因此接下来调用DFS函数时传入的参数为3,然后调用visit函数访问3号顶点,修改3号顶点对应的visited的值为true,表示3号顶点已经被访问过,for循环用来检查和3号顶点相邻的其他顶点,和3号顶点相邻的顶点是4、6、7号顶点,第一个被访问的顶点是4号顶点,由visited数组可知4号顶点还没有被访问过:
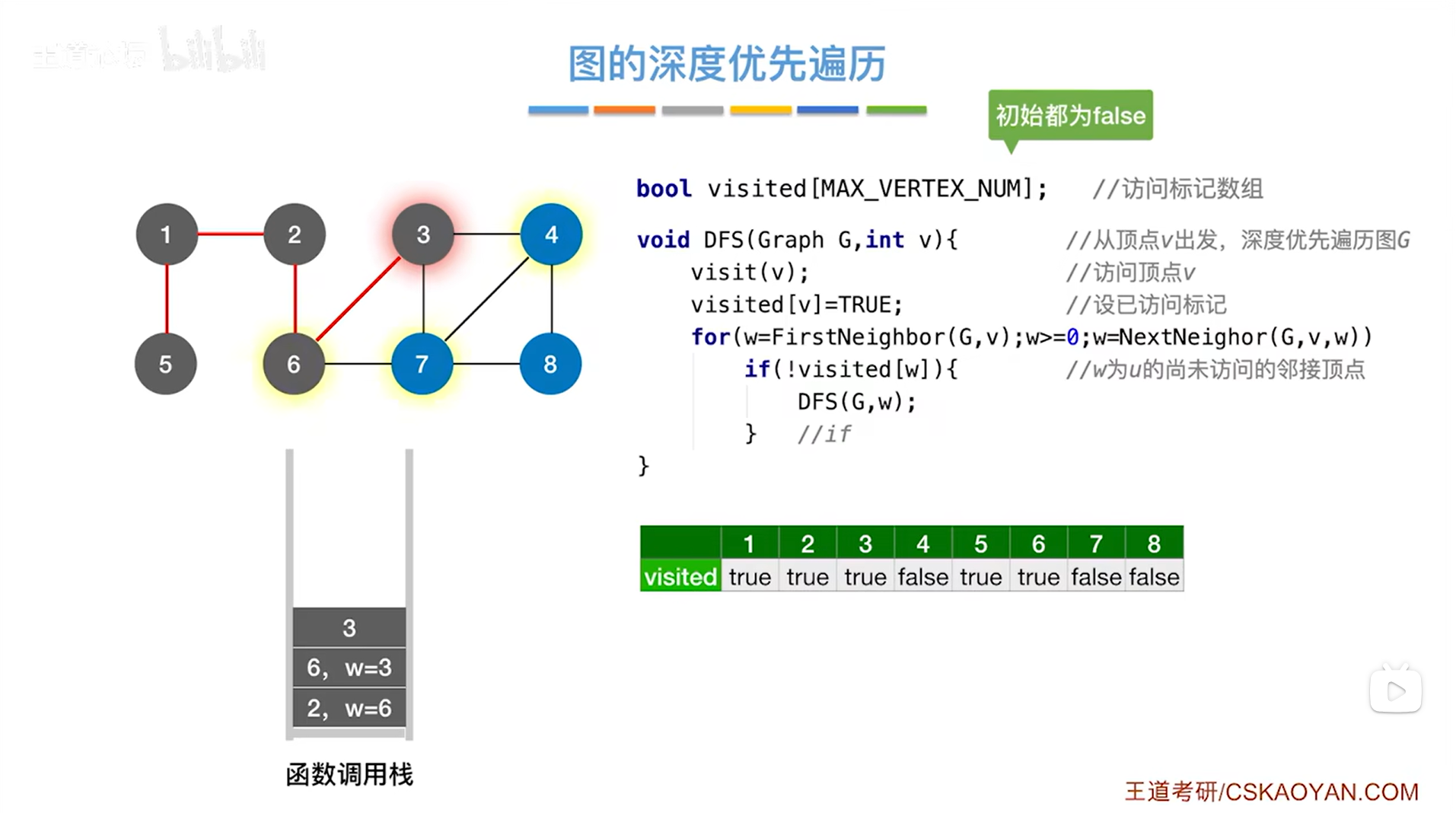
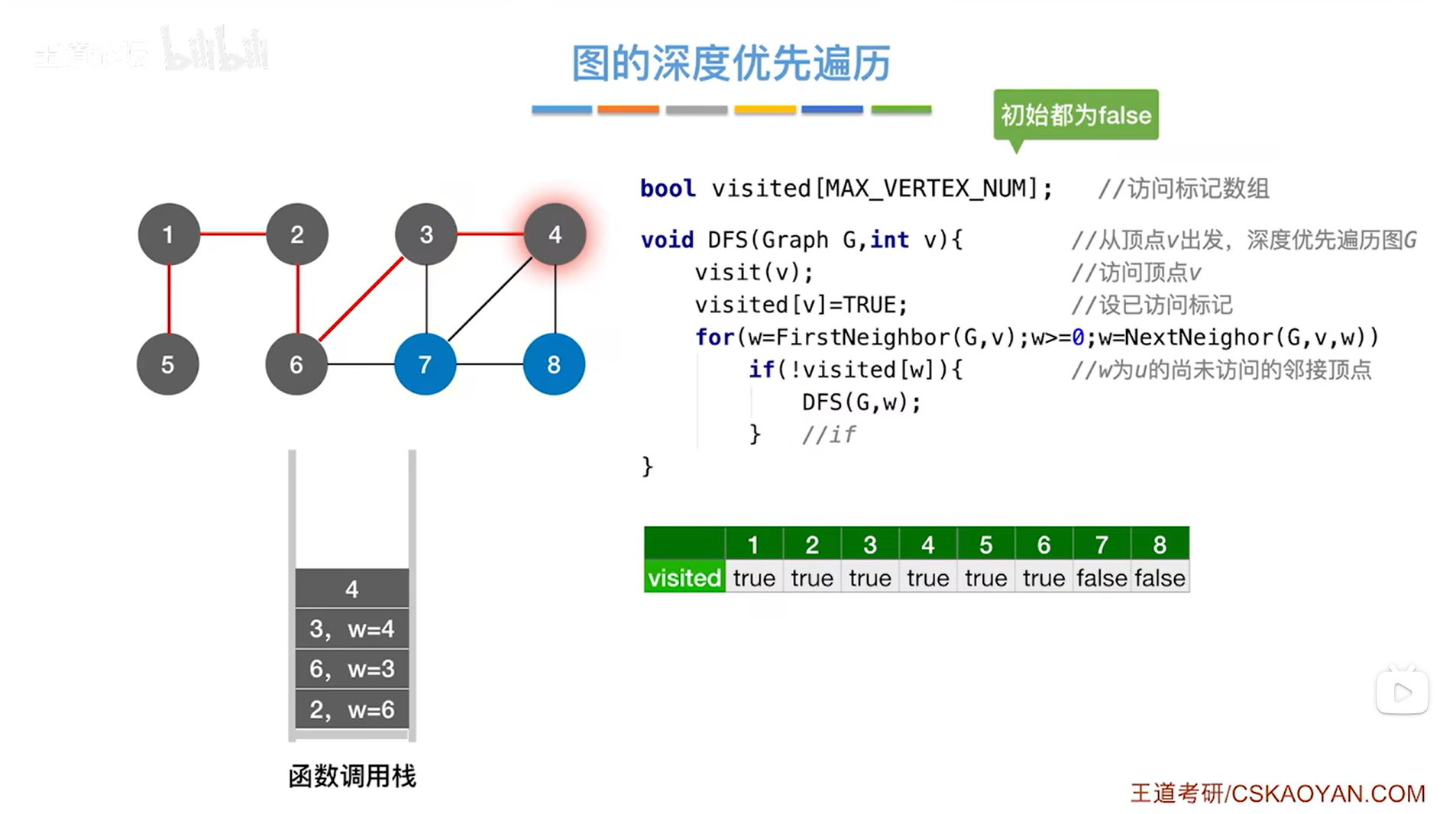
如下图,因此接下来调用DFS函数时传入的参数为4,然后调用visit函数访问4号顶点,修改4号顶点对应的visited的值为true,表示4号顶点已经被访问过,for循环用来检查和4号顶点相邻的其他顶点,和4号顶点相邻的顶点是3、7、8号顶点,第一个被访问的顶点是3号顶点,由visited数组可知3号顶点已经被访问过,因此会跳过3号顶点,开始访问7号顶点:
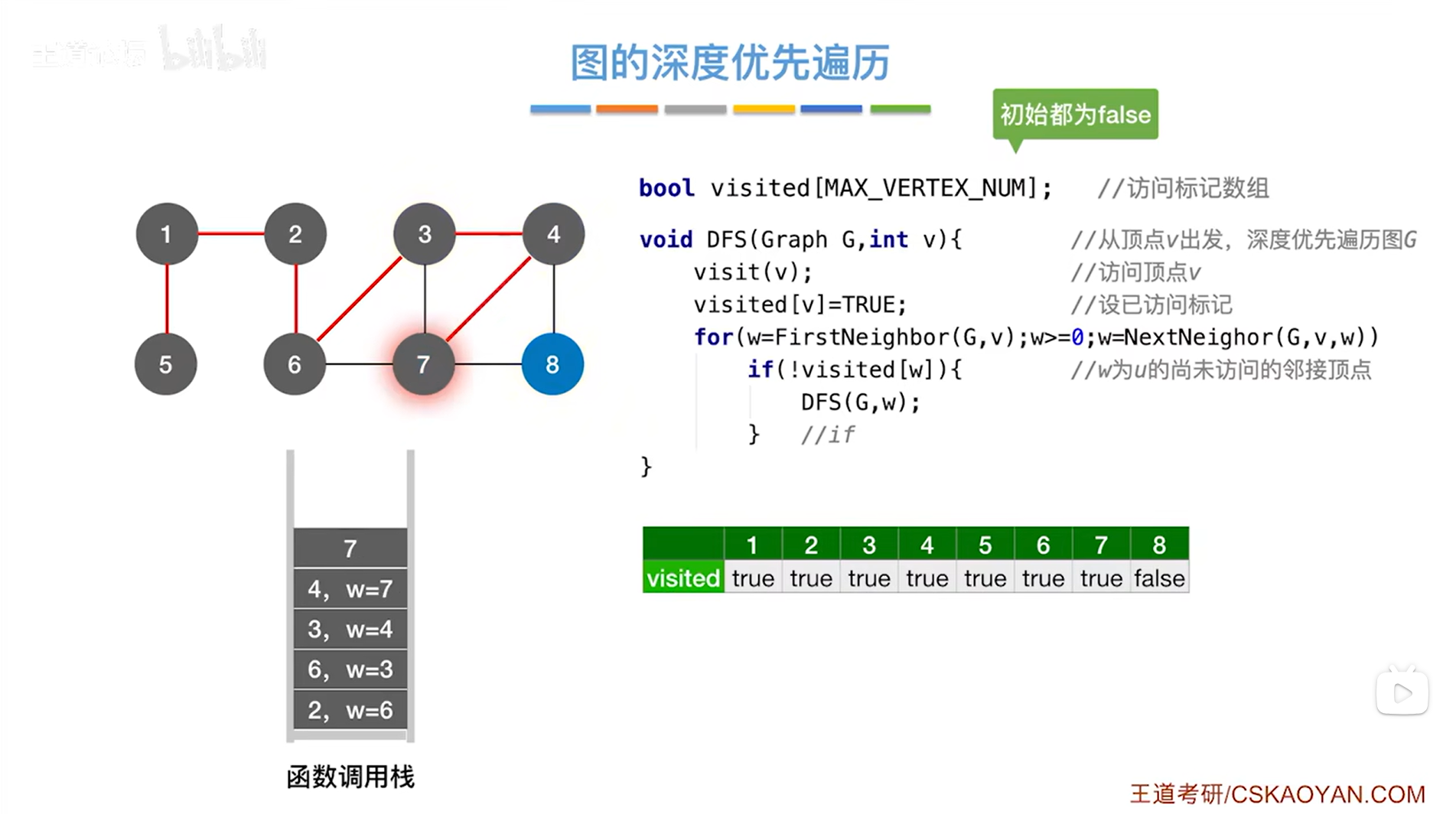
如下图,因此接下来调用DFS函数时传入的参数为7,然后调用visit函数访问7号顶点,修改7号顶点对应的visited的值为true,表示7号顶点已经被访问过,for循环用来检查和7号顶点相邻的其他顶点,和7号顶点相邻的顶点是3、4、6、8号顶点,由visited数组可知,和7号顶点相邻接的顶点中,只有8号顶点还没有被访问过,因此开始访问8号顶点:
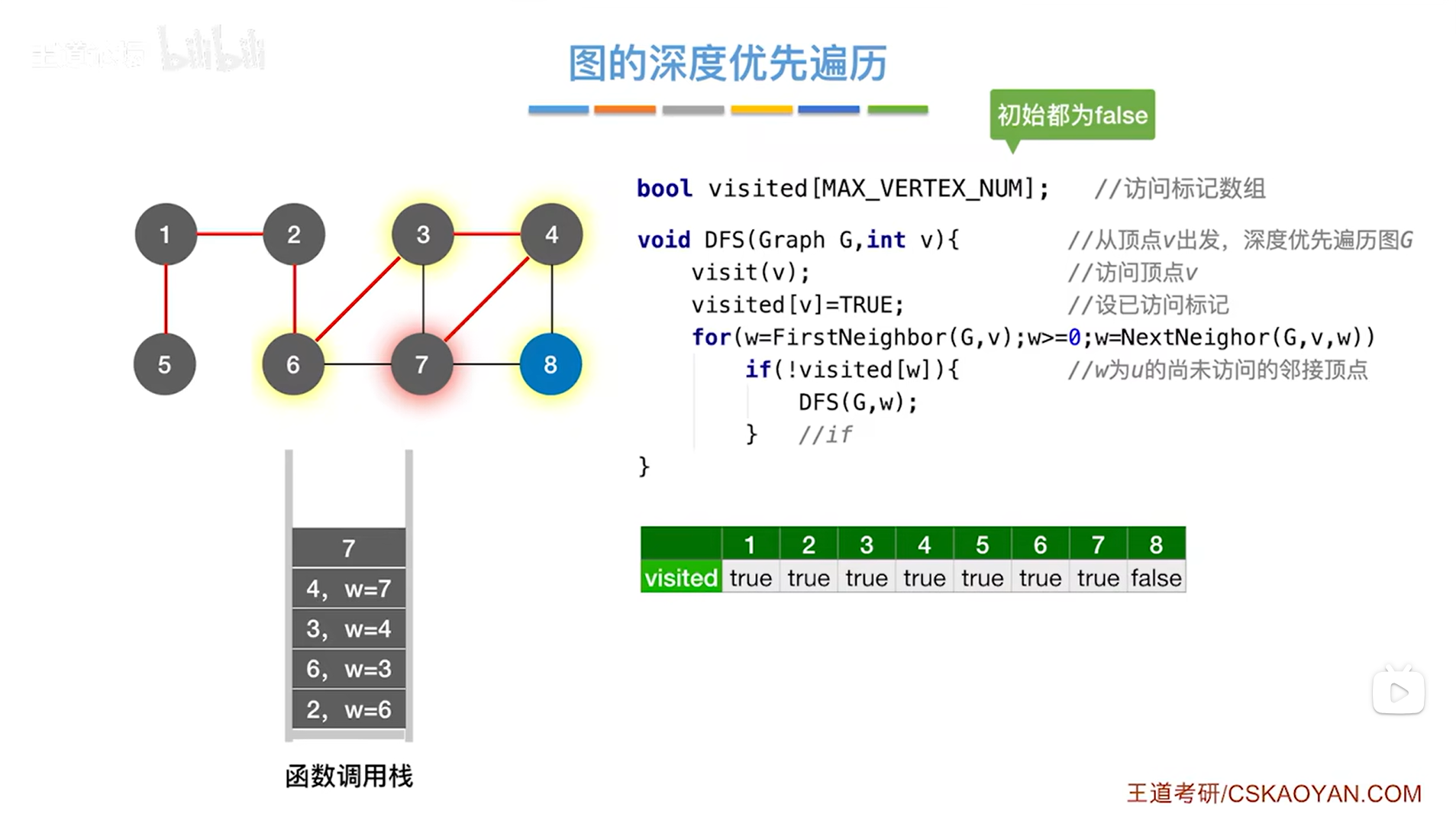
如下图,因此接下来调用DFS函数时传入的参数为8,然后调用visit函数访问8号顶点,修改8号顶点对应的visited的值为true,表示8号顶点已经被访问过,for循环用来检查和8号顶点相邻的其他顶点,和8号顶点相邻的顶点是4、7号顶点,由visited数组可知,4、7号顶点都已经被访问过,所以8号顶点的DFS函数执行完毕:
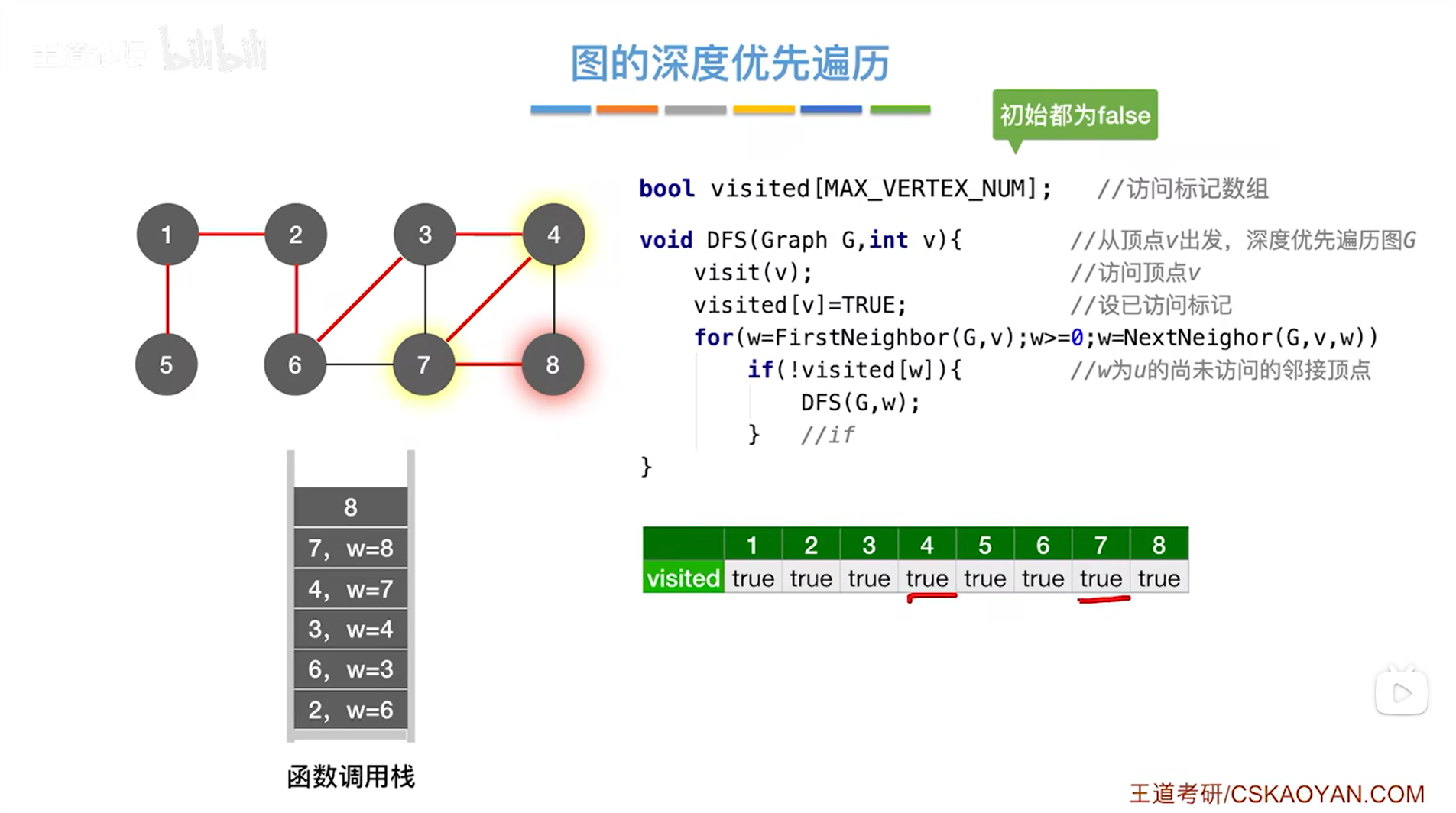
如下图,返回上一层即7号顶点这一层,此时和7号顶点相邻的所有顶点都已经全部被访问完毕,所以继续返回上一层:
如下图,返回到4号顶点这一层,此时和4号顶点相邻的所有顶点都已经全部被访问完毕,所以继续返回上一层:
如下图,其他的类似,最终函数调用栈清空,上述图片的图遍历完毕:
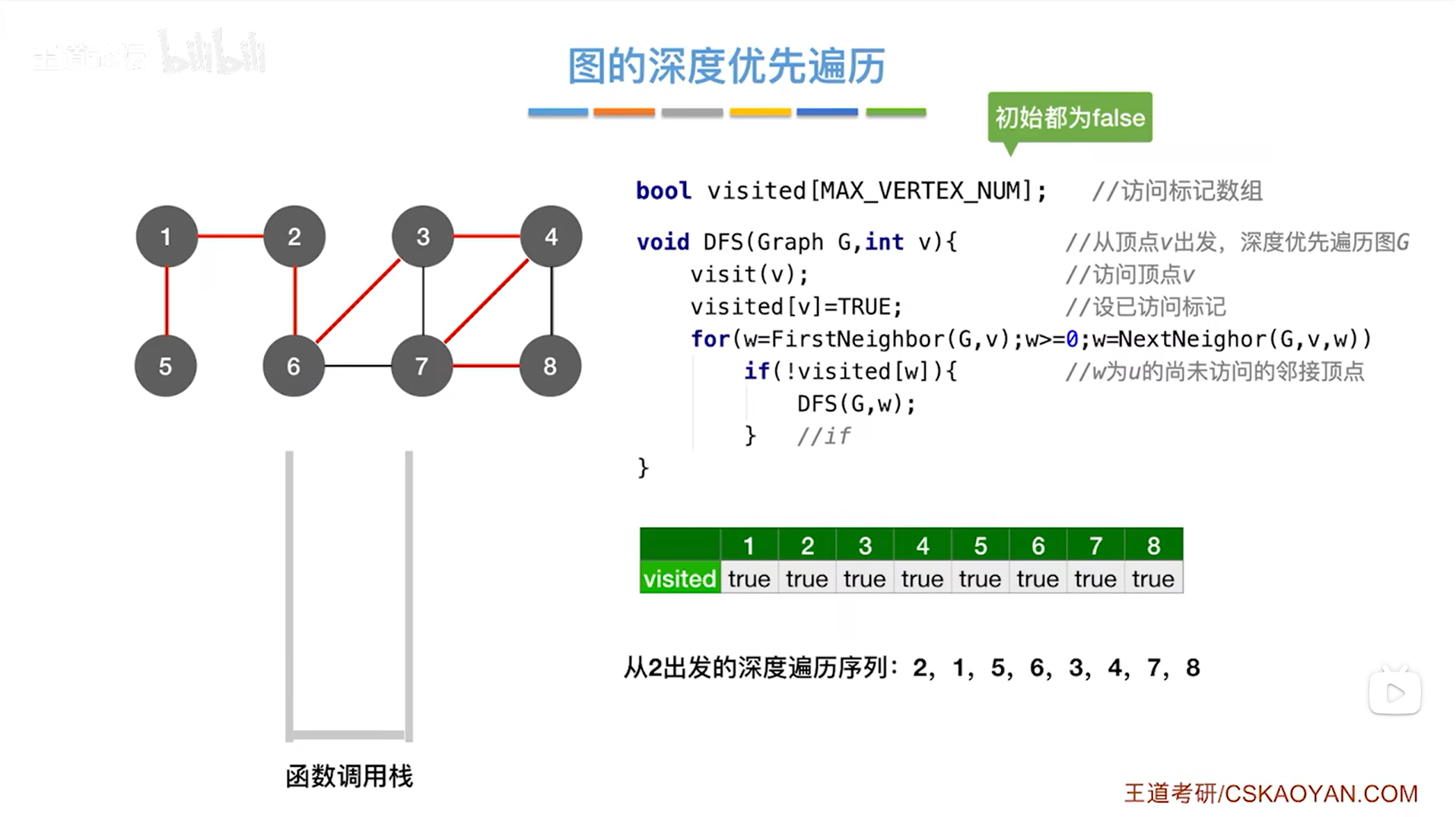
如上图,最终得出从2号顶点出发,进行上述图的深度优先遍历,得到的深度遍历序列为2,1,5,6,3,4,7,8。
4.图的深度优先遍历算法存在的问题与优化:
上述图片的代码存在一个问题,就是如果遍历的图是非连通图,则无法遍历完所有顶点,如下图所示:
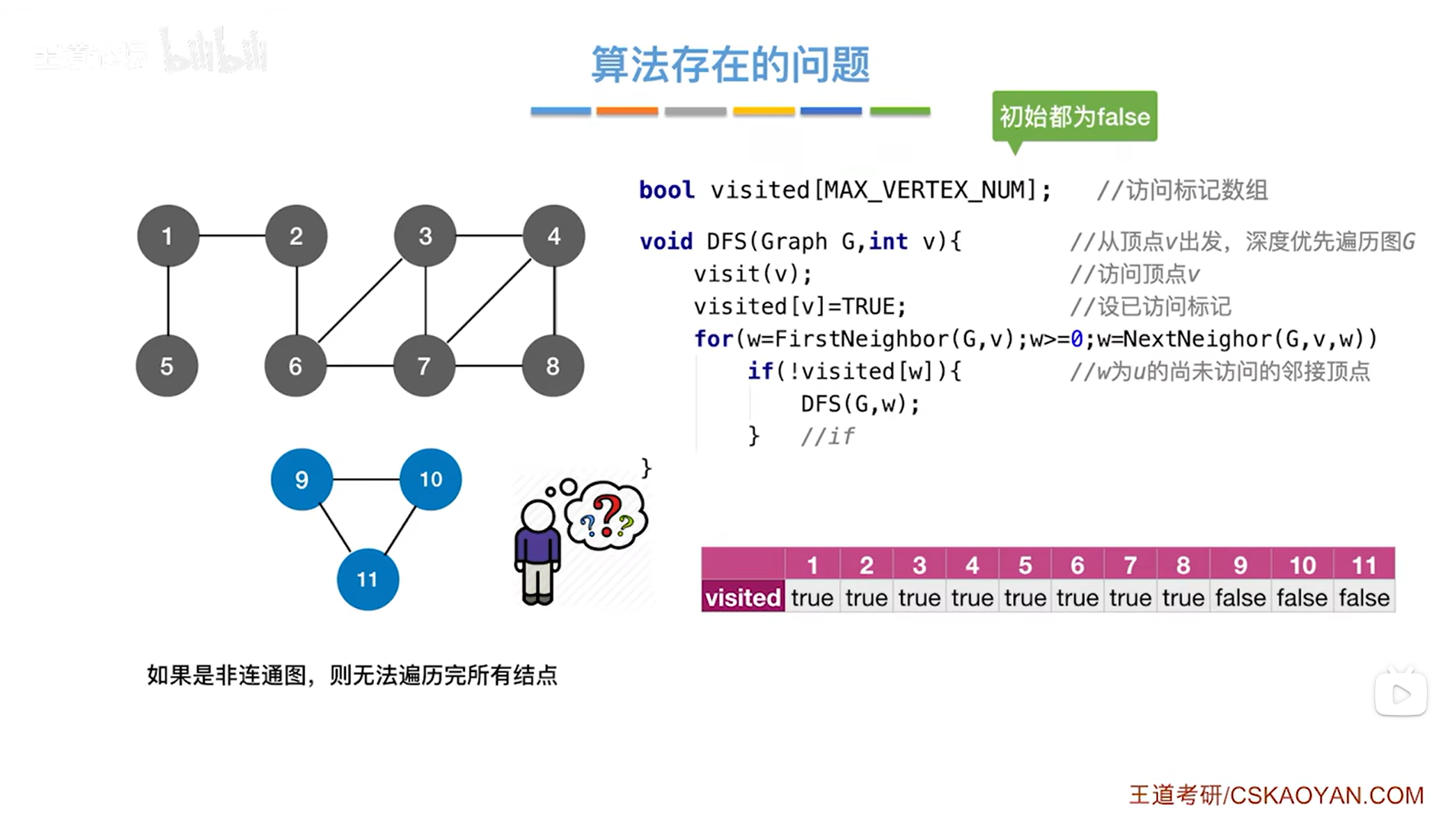
例如从2号顶点出发进行深度优先遍历上述图片里的图,调用DFS函数,可以遍历完1、2、3、4、5、6、7、8号顶点,但9、10、11号顶点无法遍历到,解决方案如下:

-
DFSTraverse函数的形参Graph G表示图;vexnum表示图中顶点的个数,G.vexnum表示图中顶点的个数,v是顶点编号
-
DFSTraverse函数的第一个for循环用来把visited数组全部赋值为false,表示图中所有顶点都没有被访问过
-
DFSTraverse函数的第二个for循环用来检查是否有顶点还没有被访问过,如果有,visited[v]的值为false,!visited[v]的值为true,就会执行if语句再次调用DFS函数把未访完的顶点访问完毕
-
注:DFSTraverse函数的第二个for循环必须从第一个顶点出发开始遍历,如果从中间的顶点出发开始遍历,就会使得前面的顶点无法遍历到->如上图,必须从1号顶点出发,由于是非连通图,只能把1、2、3、4、5、6、7、8号顶点访问完,此时发现第9号顶点对应visited的值为false,意味着9号顶点还没有被访问,因此从9号顶点出发,再次调用DFS函数访问剩下的顶点,通过9号顶点就可以把9、10、11号顶点全部访问完,最终上述图片的图深度优先遍历完毕
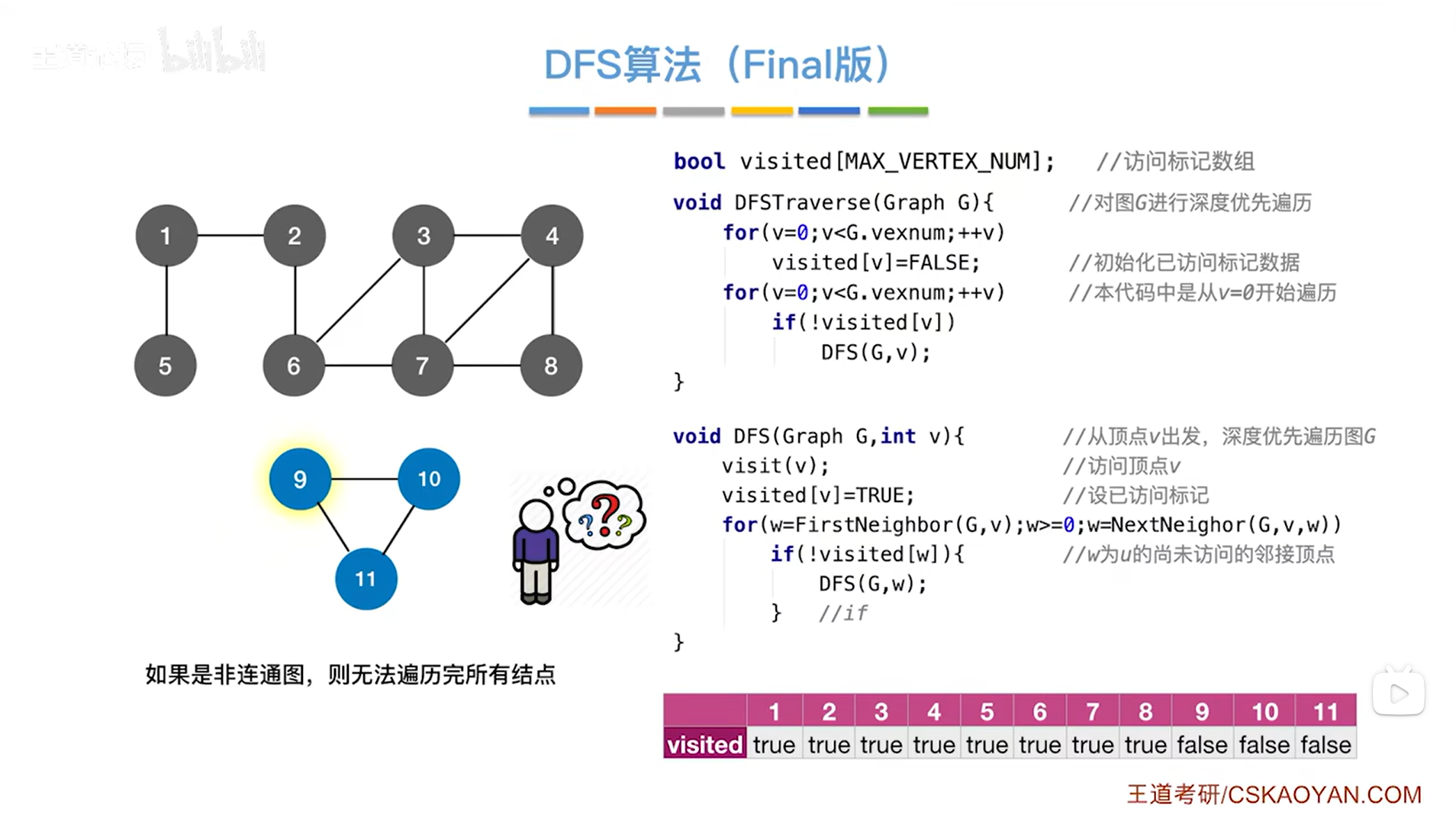
二.图的深度优先遍历算法的空间复杂度:
如上图,图的深度优先遍历算法的空间复杂度主要取决于DFS函数的递归调用。
1.最坏的情况:

如上图,比如从1号顶点出发开始深度优先遍历图,那么DFS函数递归调用栈的深度就会与图中的顶点个数相等(因为1号顶点与2、3、4、5、6、7、8号顶点都邻接,意味着函数递归调用栈会把图中8个顶点即所有顶点都入栈),假设图中有V个顶点,因此最坏的情况为O( |V| )->之所以这个是最坏情况,是因为递归深度达到了最大值。
2.最好的情况:
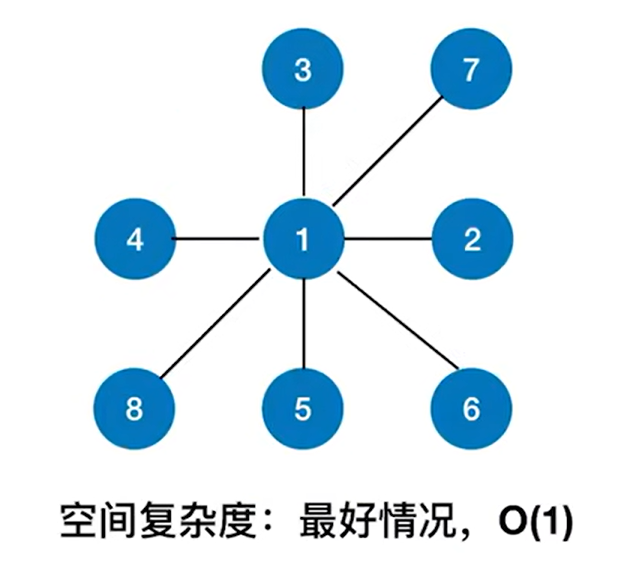
如上图,比如从1号顶点出发开始深度优先遍历图,显然在这种情况下DFS函数递归调用栈最多只会有两层(一层是当前访问的顶点,一层是与该顶点相邻接的顶点,不存在第二个与该顶点相邻接的顶点),也就是说只需要常数级即O(1)的空间复杂度。(注:访问顶点时函数递归调用栈最少会有一层,这一层是当前访问的顶点,该顶点不存在邻接点,顶点全部访问完毕时或者不访问顶点时函数递归调用栈为0层)
3.注意:做题时,题目问图的深度优先遍历算法的空间复杂度,没有特别说明的情况下,要答O( |V| )即最坏的情况。
三.图的深度优先遍历算法的时间复杂度:
核心:无论是BFS还是DFS,计算时间复杂度都可以简化为计算访问各个顶点所需要的时间加探索各条边/弧所需要的时间
1.如果图采用邻接矩阵存储:
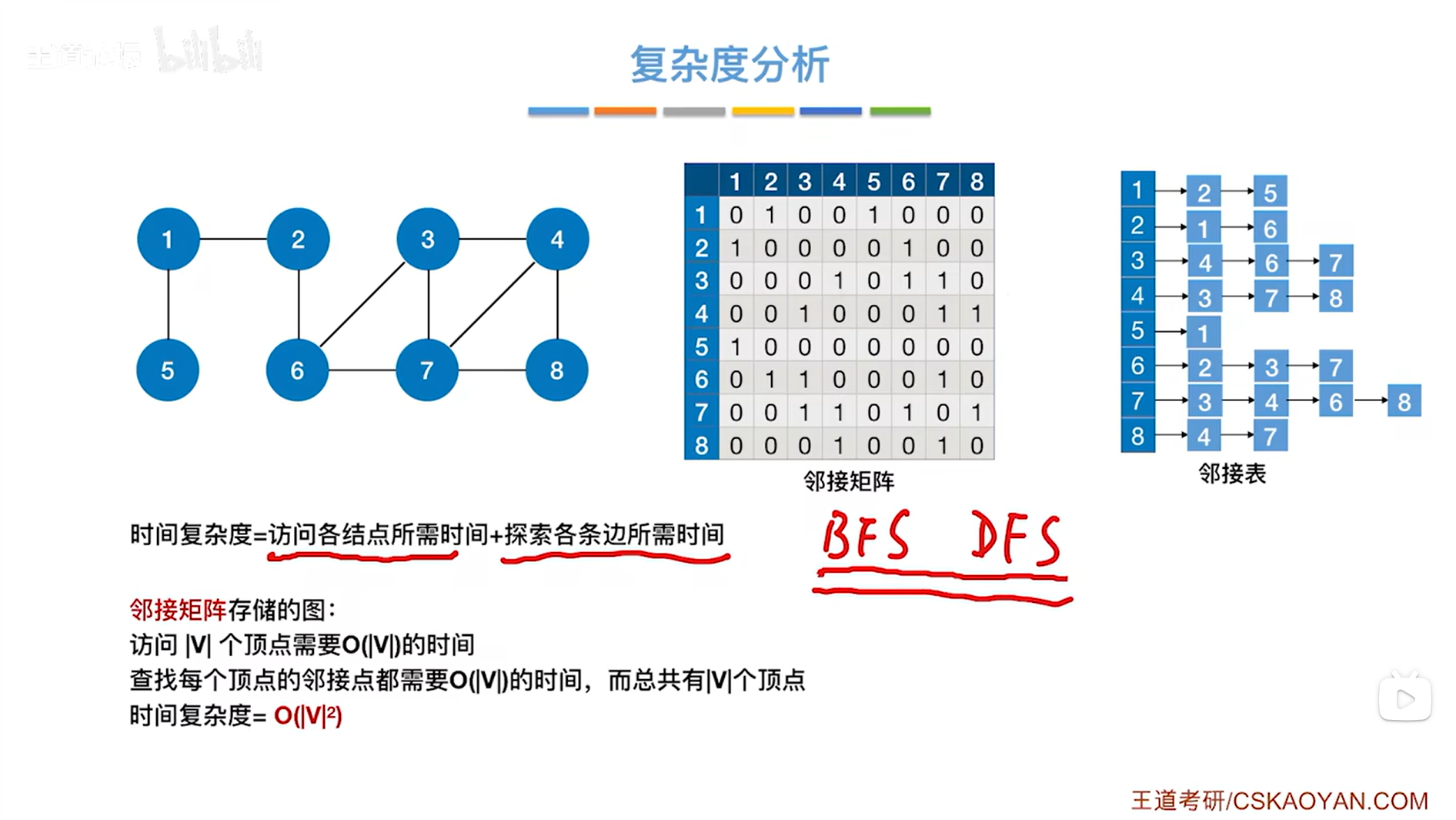
假设图中有V个顶点,访问|V|个顶点就需要O( |V| )的时间,因为需要遍历,
探索和某一个顶点相邻的边只需要遍历该顶点对应的一整行(或一整列,因为此时是无向图,无向图的邻接矩阵是对称的)的数据即可,所以查找每个顶点的邻接点即邻接的边需要O( |V| )的时间,
由于总共有|V|个顶点,所以整体来看时间复杂度就是O( |V| * |V| )。
2.如果图采用邻接表存储:
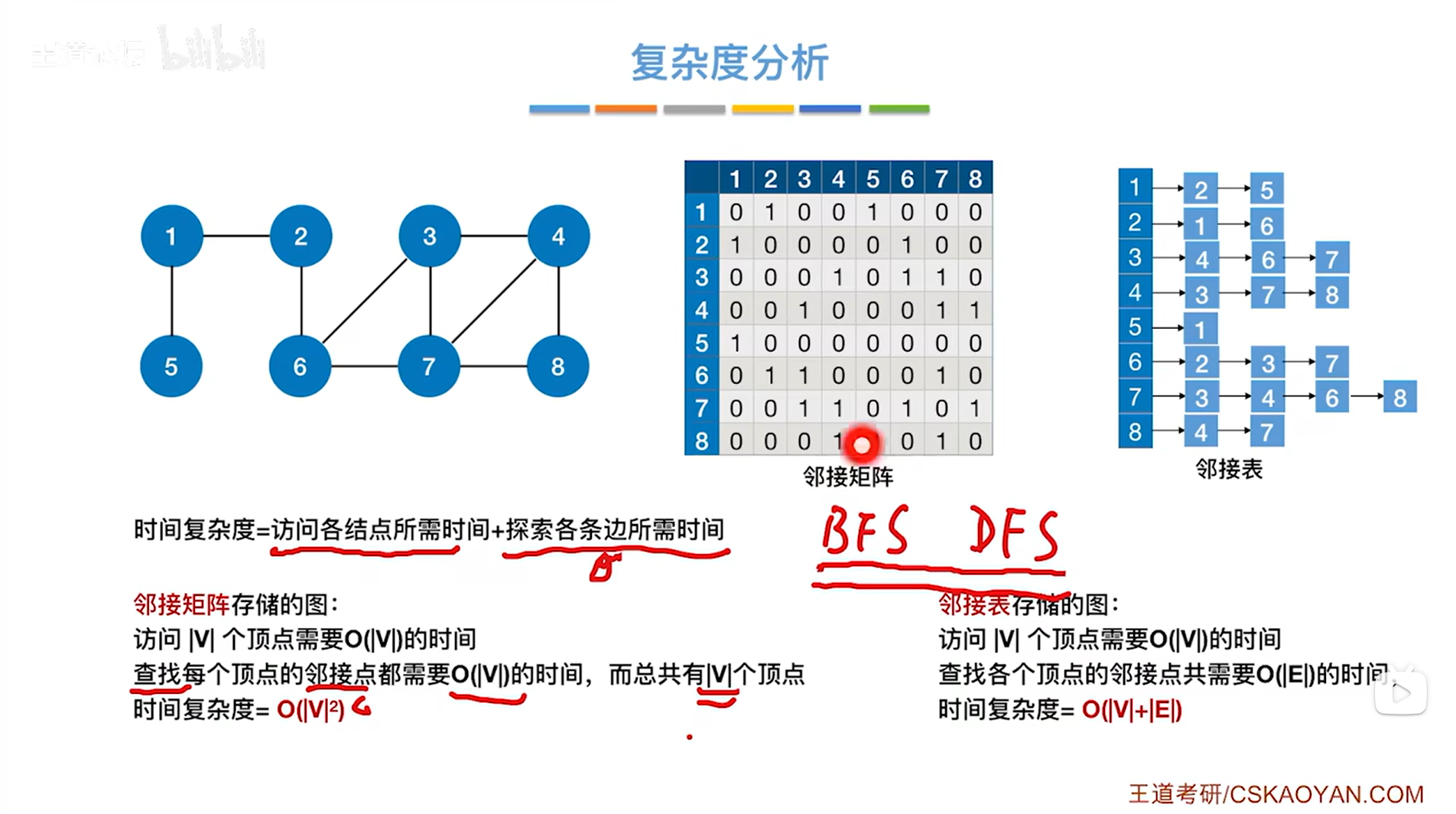
假设图中有V个顶点,访问|V|个顶点就需要O( |V| )的时间,因为需要遍历,
假设图中有E条边,查找某个顶点的邻接点即邻接的边共需要O( |E| )的时间,因为查找某个顶点的邻接点即邻接的边只需要遍历该顶点对应的链表即可,链表可能包含所有的边,所以共需要O( |E| )的时间,
由于需要先查找所要操作的顶点,再找邻接的边,所以时间复杂度为O( |V|+|E| )。
四.深度优先遍历序列:从哪一个顶点开始遍历(入栈),遍历结束时就是哪个顶点最后一个出栈(先进后出)
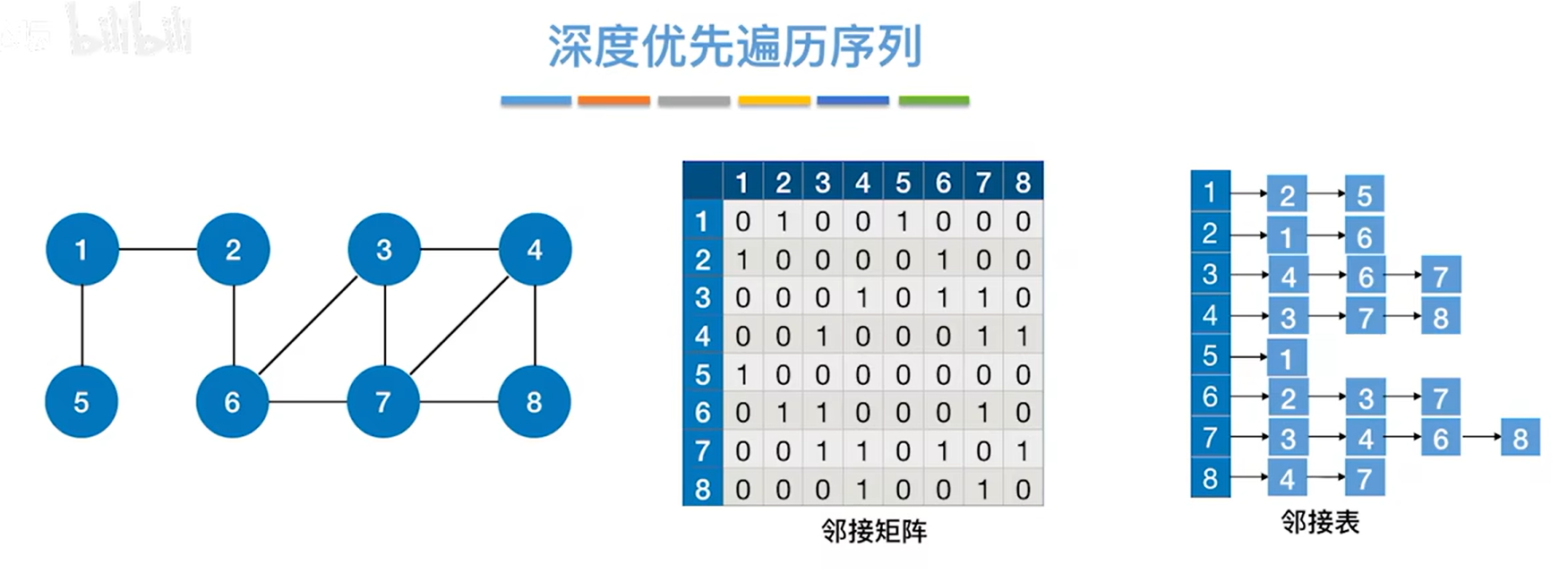
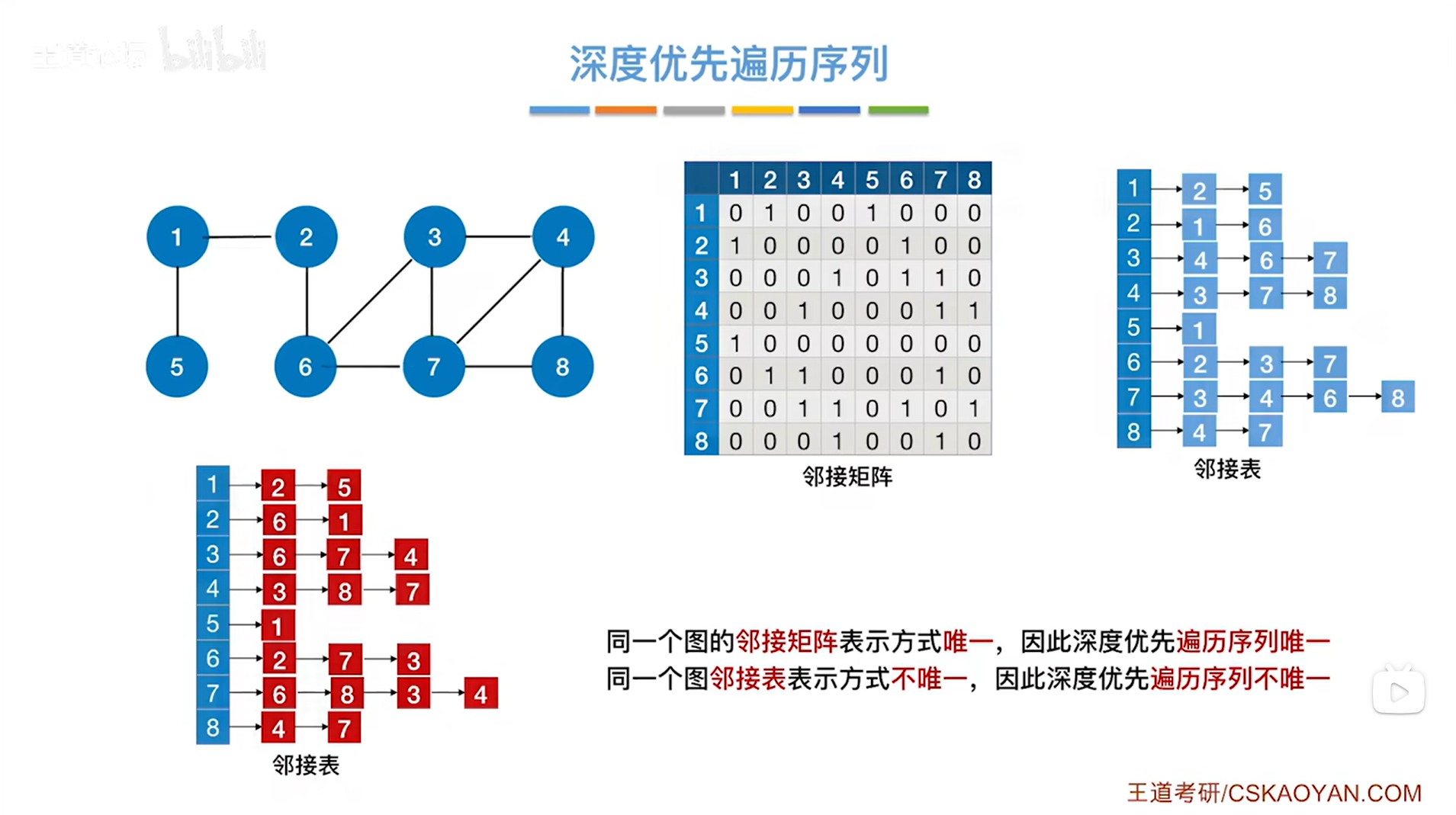
假设图使用了邻接矩阵或者邻接表存储,
如上图,邻接表中各个链表中顶点号都是从左向右递增的,因此,对于某一个顶点,要找到与该顶点相邻的其他顶点,在该邻接表中找到的顺序与左边的邻接矩阵找到的顺序是一致的,因为邻接矩阵的顶点号也是从左向右递增的。
1.从2号顶点出发进行深度优先遍历整个图:
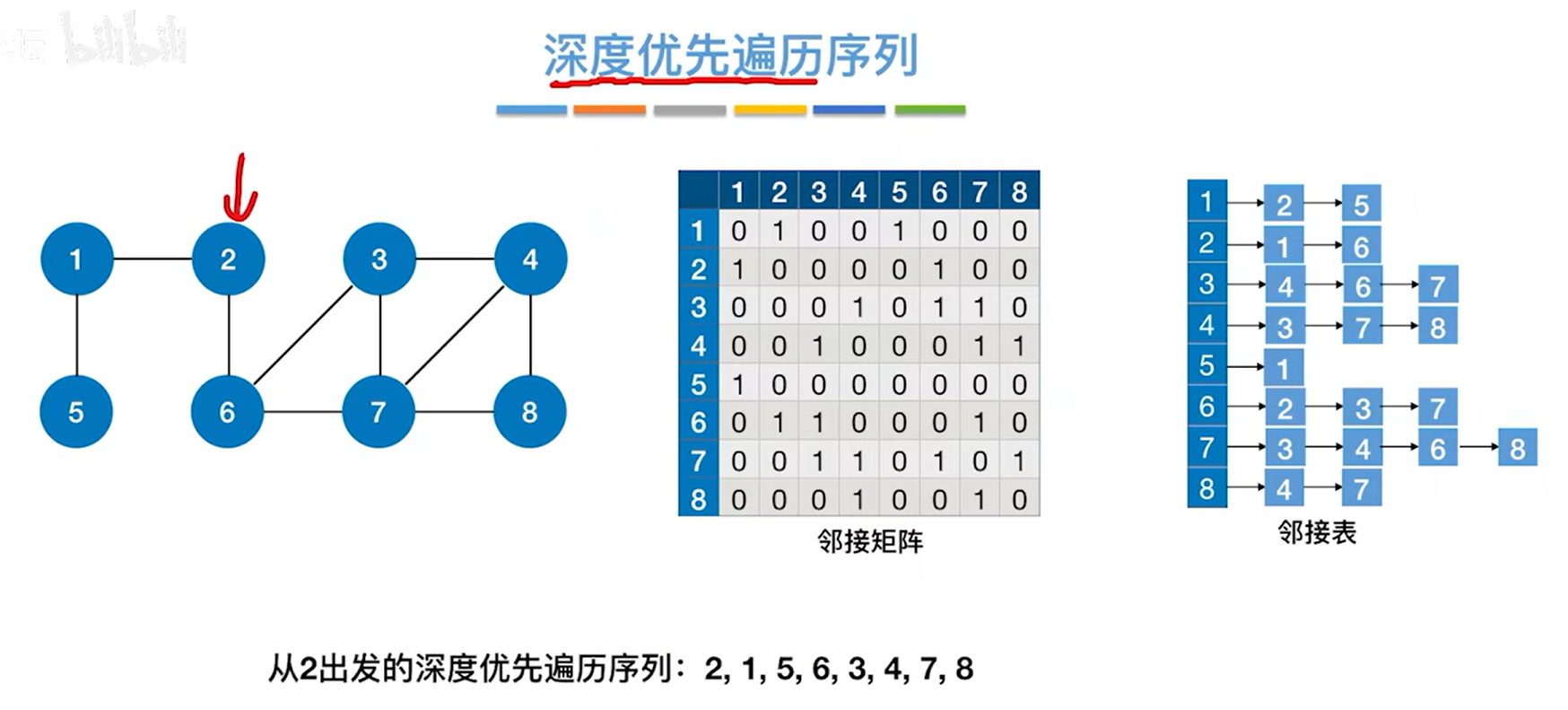
在邻接矩阵和邻接表这两种情况下,如果从2号顶点出发进行深度优先遍历整个图,得到的遍历序列都是2,1,5,6,3,4,7,8(因为此时邻接矩阵和邻接表存储顶点的编号都是递增的)。
2.从3号顶点出发进行深度优先遍历整个图:(详细遍历过程)
如下图,假设图使用邻接表存储:
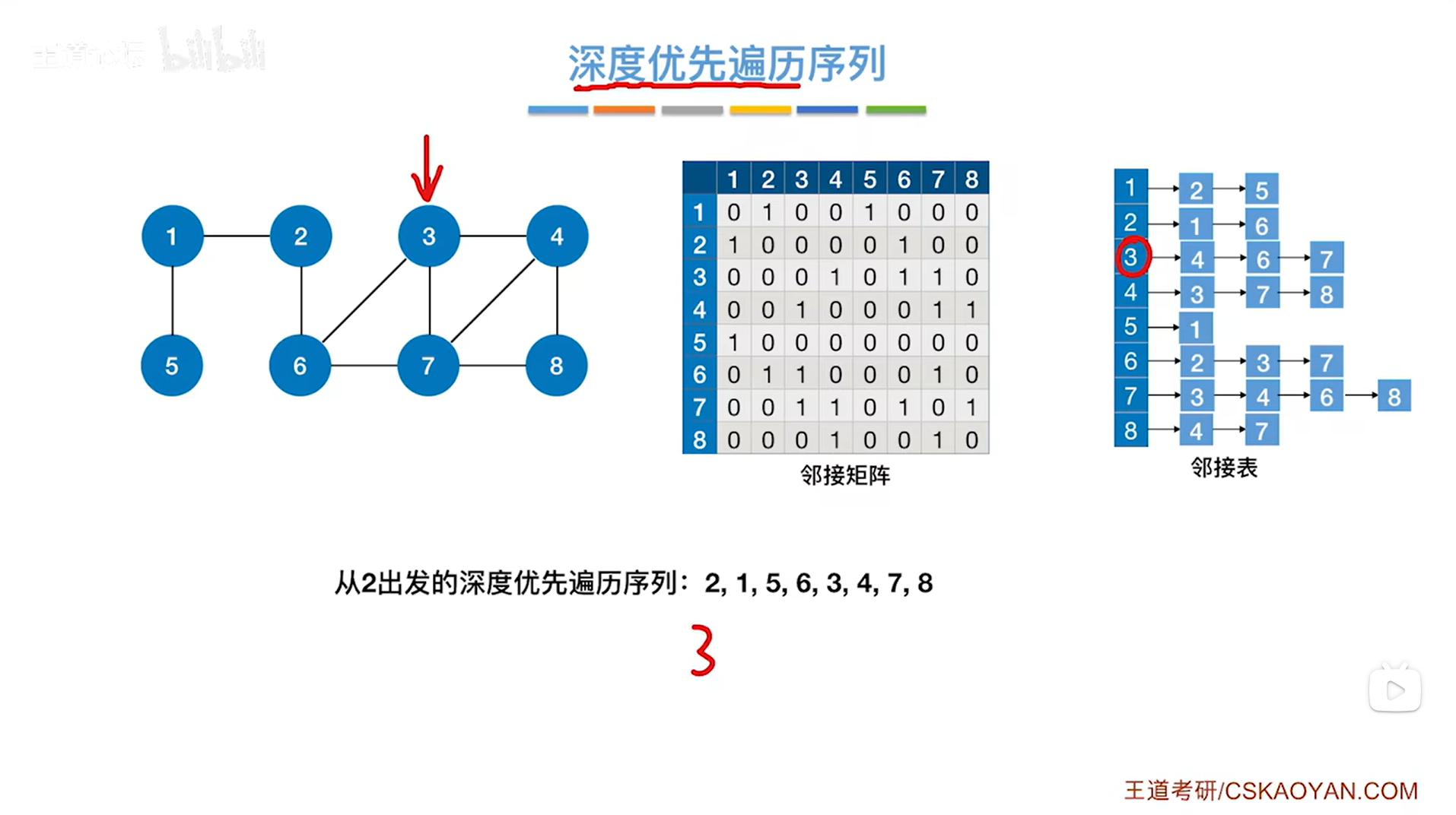
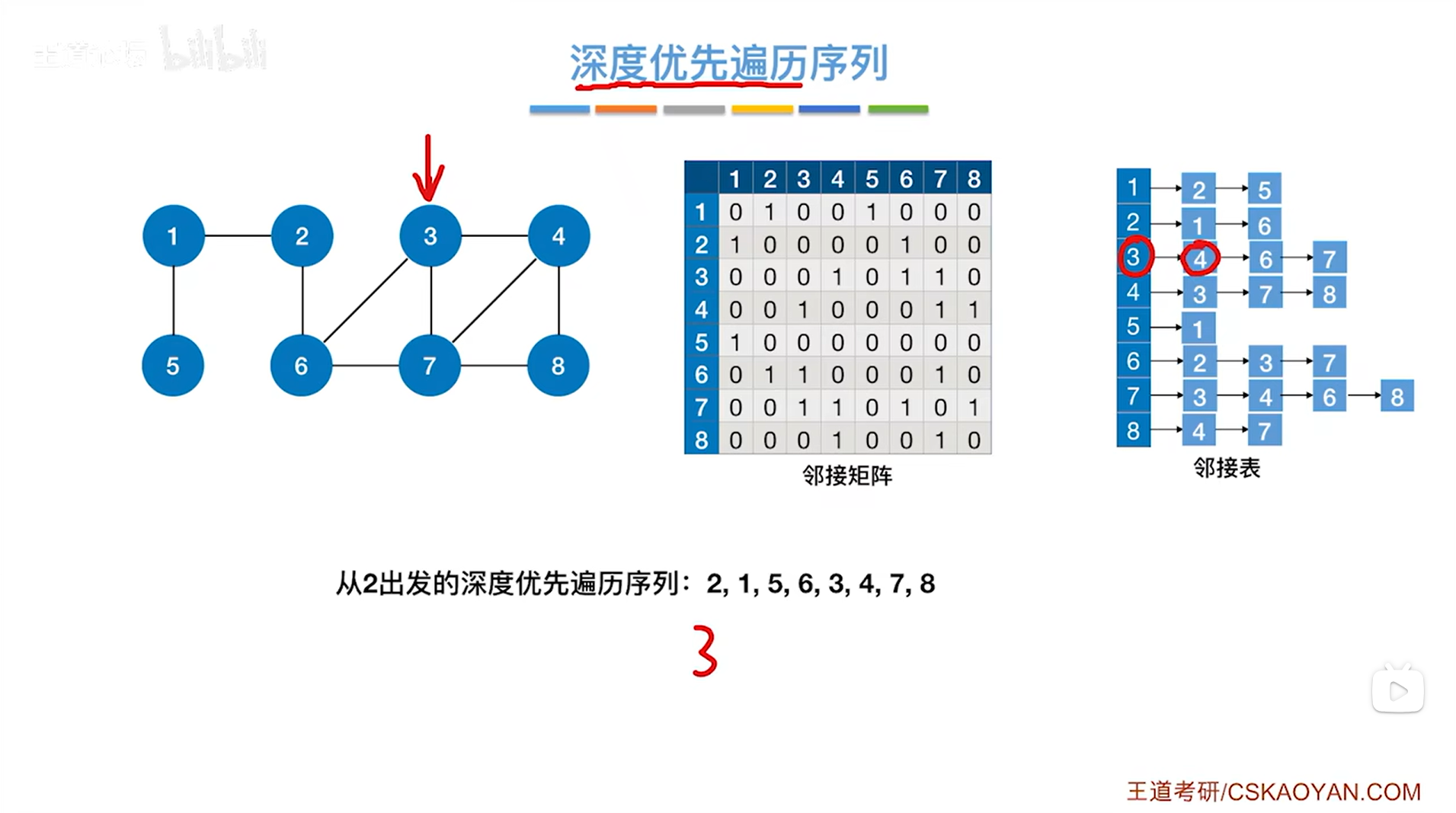
如上图,第一个访问3号顶点,和3号顶点相邻的第一个顶点是4号顶点(这个直接看3号顶点对应的链表即可知道3号顶点与哪些顶点邻接,其他同理),因此
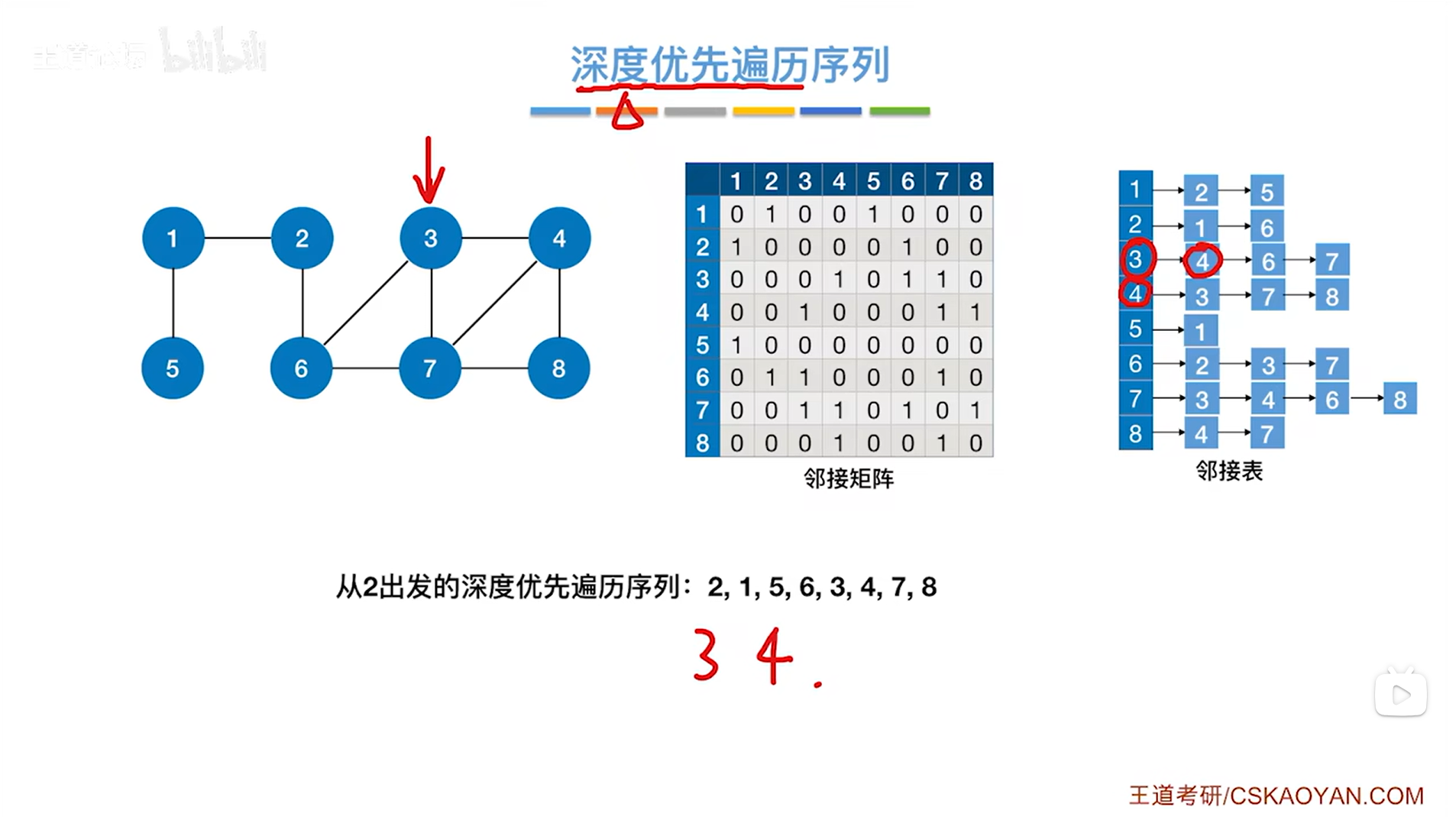
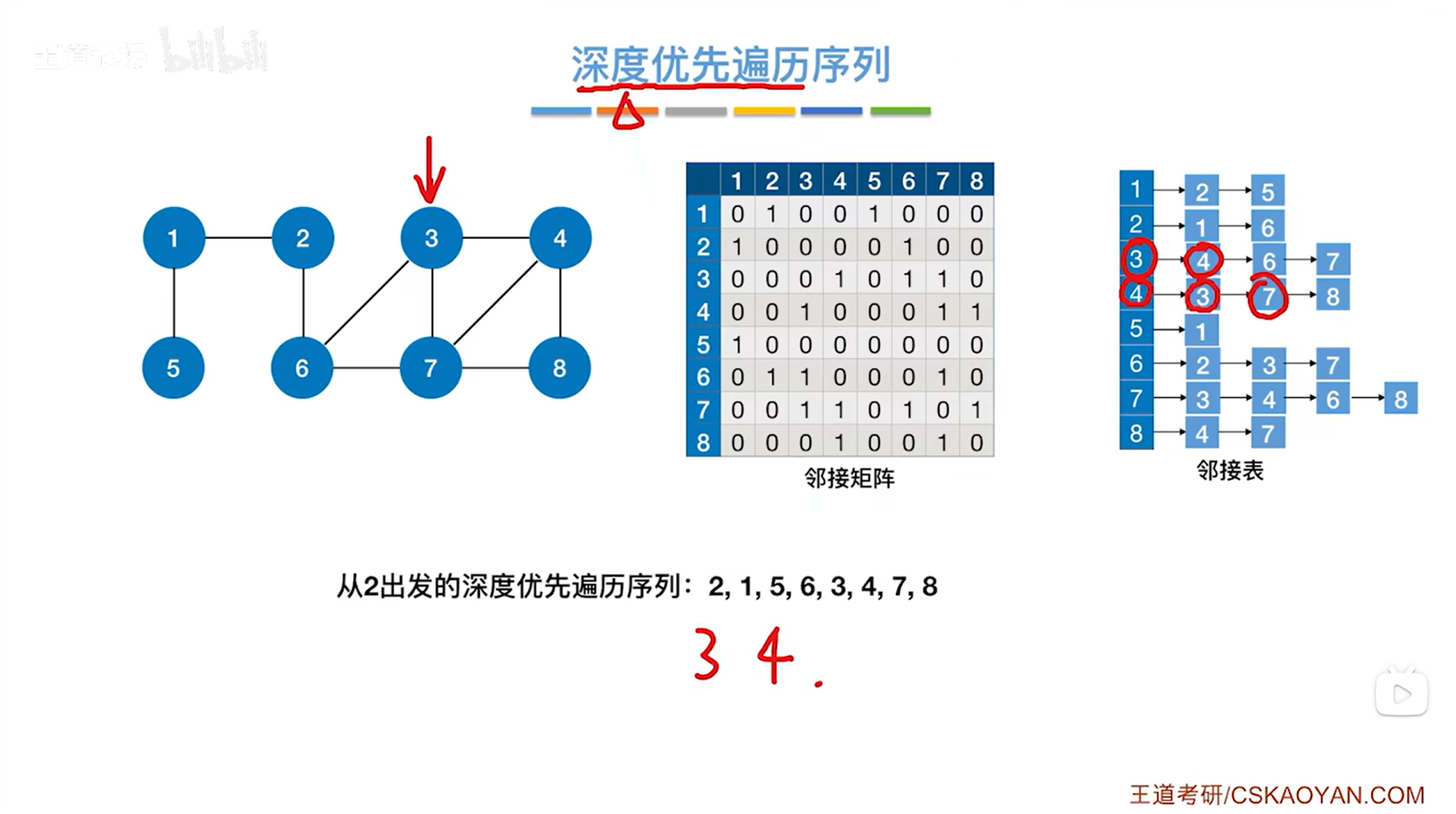
如上图,第二个访问4号顶点,根据DFS的规则,此时要从4号顶点出发找其他和4号顶点相邻且没有被访问的顶点,与4号顶点相邻的第一个顶点即3号顶点已经被访问过了,因此跳过3号顶点,与4号顶点相邻的第二个顶点即7号顶点没有被访问过,因此
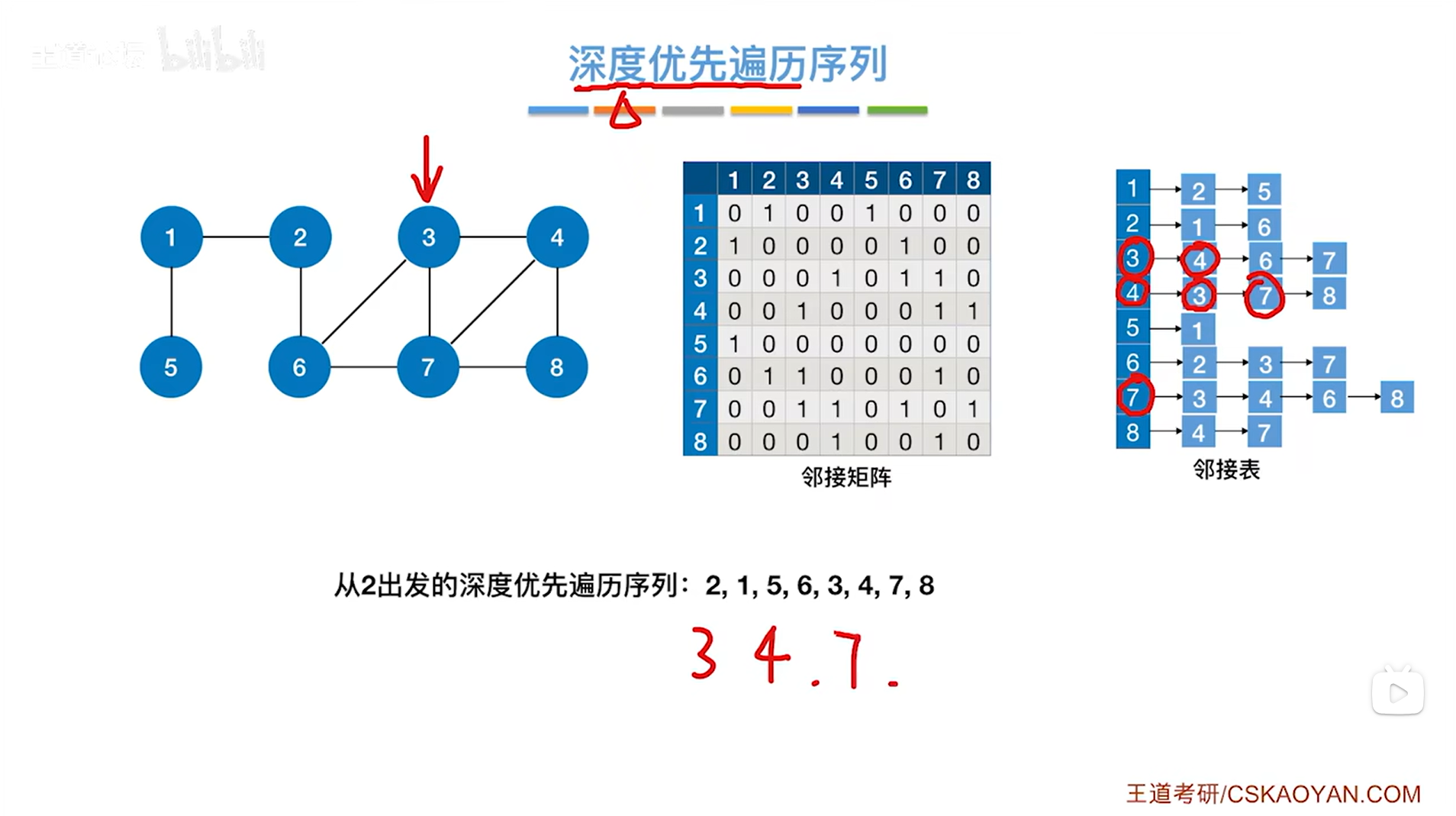
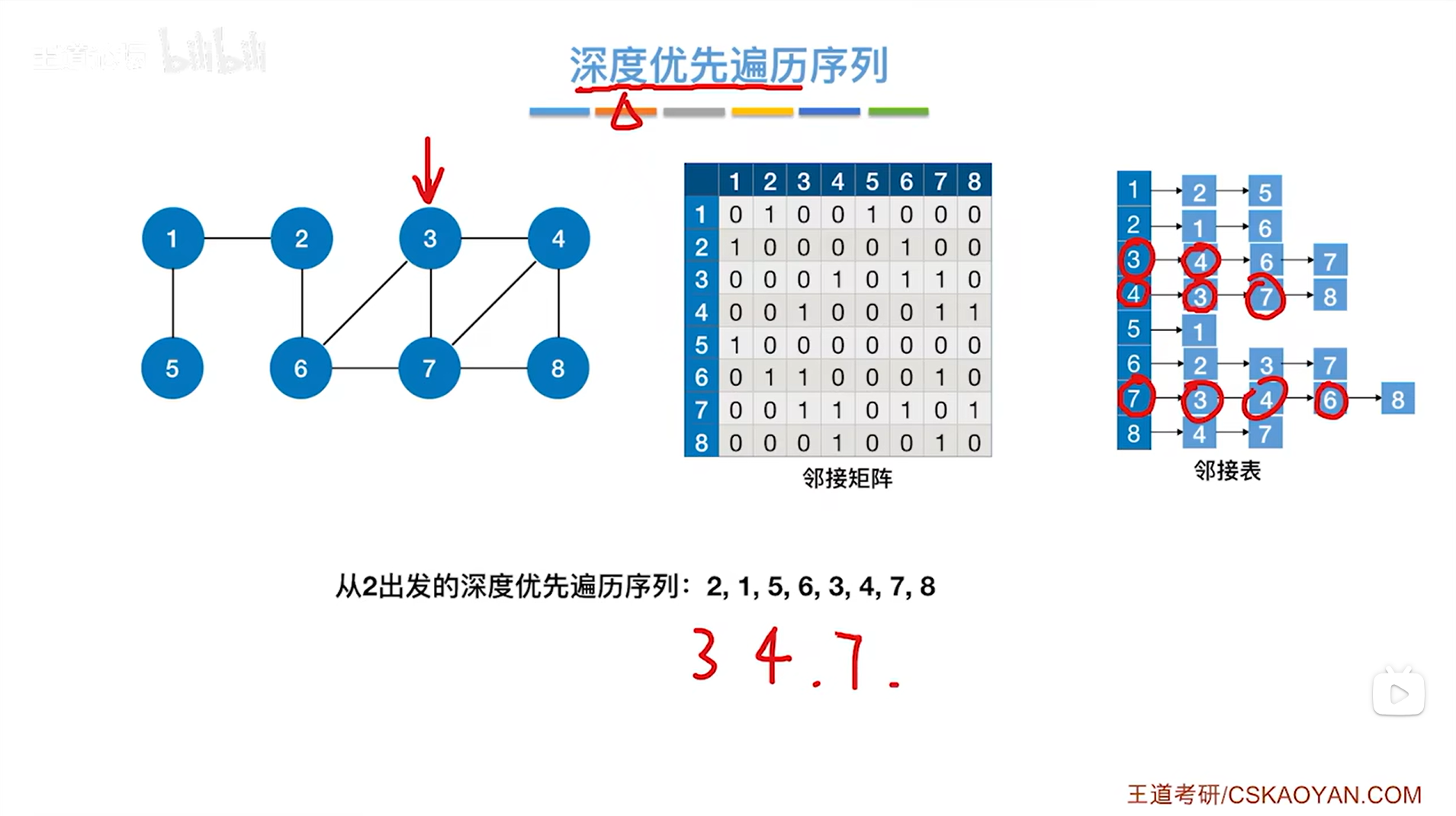
如上图,第三个访问7号顶点,与7号顶点相邻的第一个顶点即3号顶点已经被访问过了,因此跳过3号顶点,与7号顶点相邻的第二个顶点即4号顶点也已经被访问过了,因此跳过4号顶点,与7号顶点相邻的第三个顶点即6号顶点没有被访问过,因此
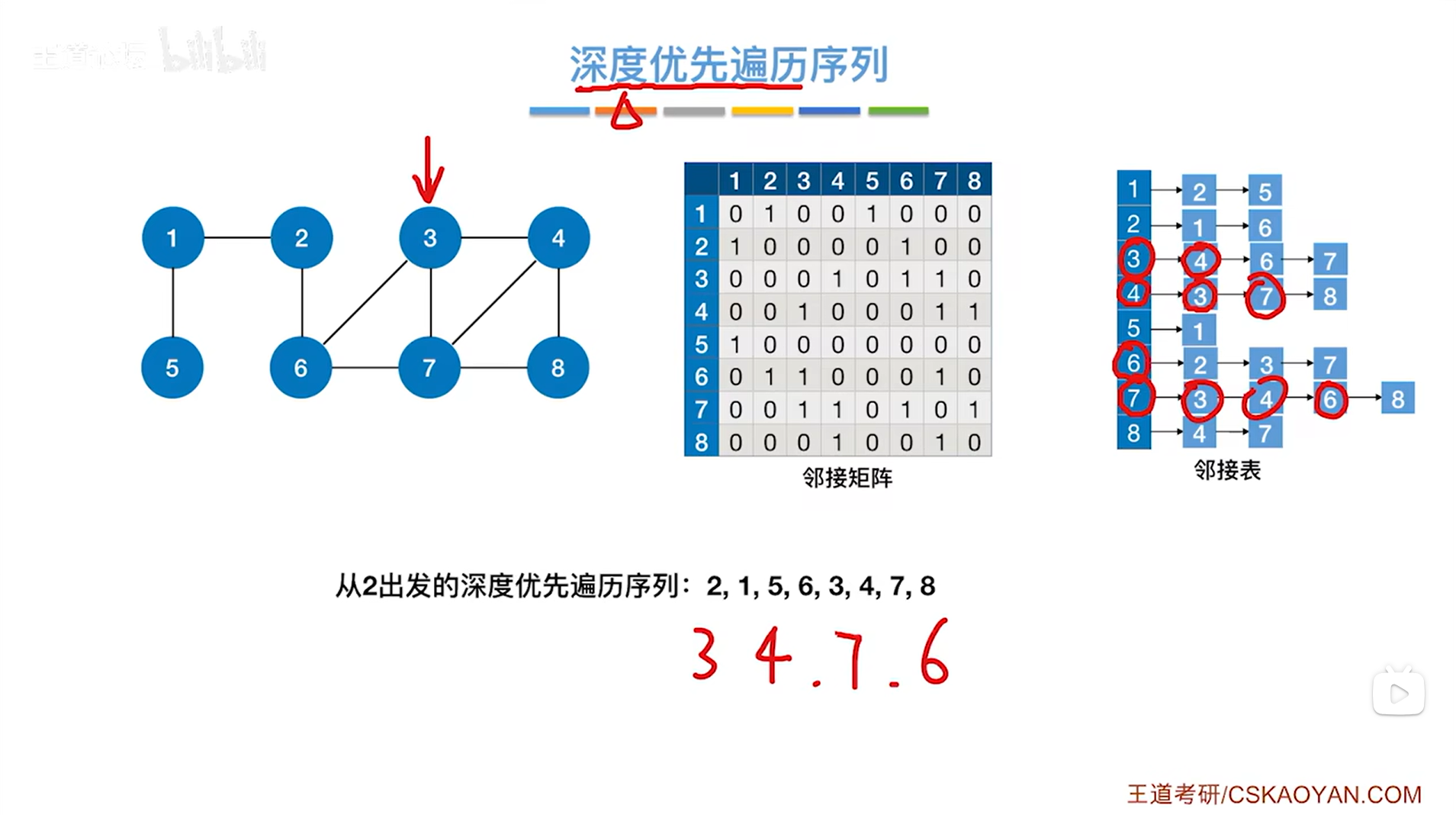
如上图,第四个访问6号顶点,与6号顶点相邻的第一个顶点即2号顶点没有被访问过,因此
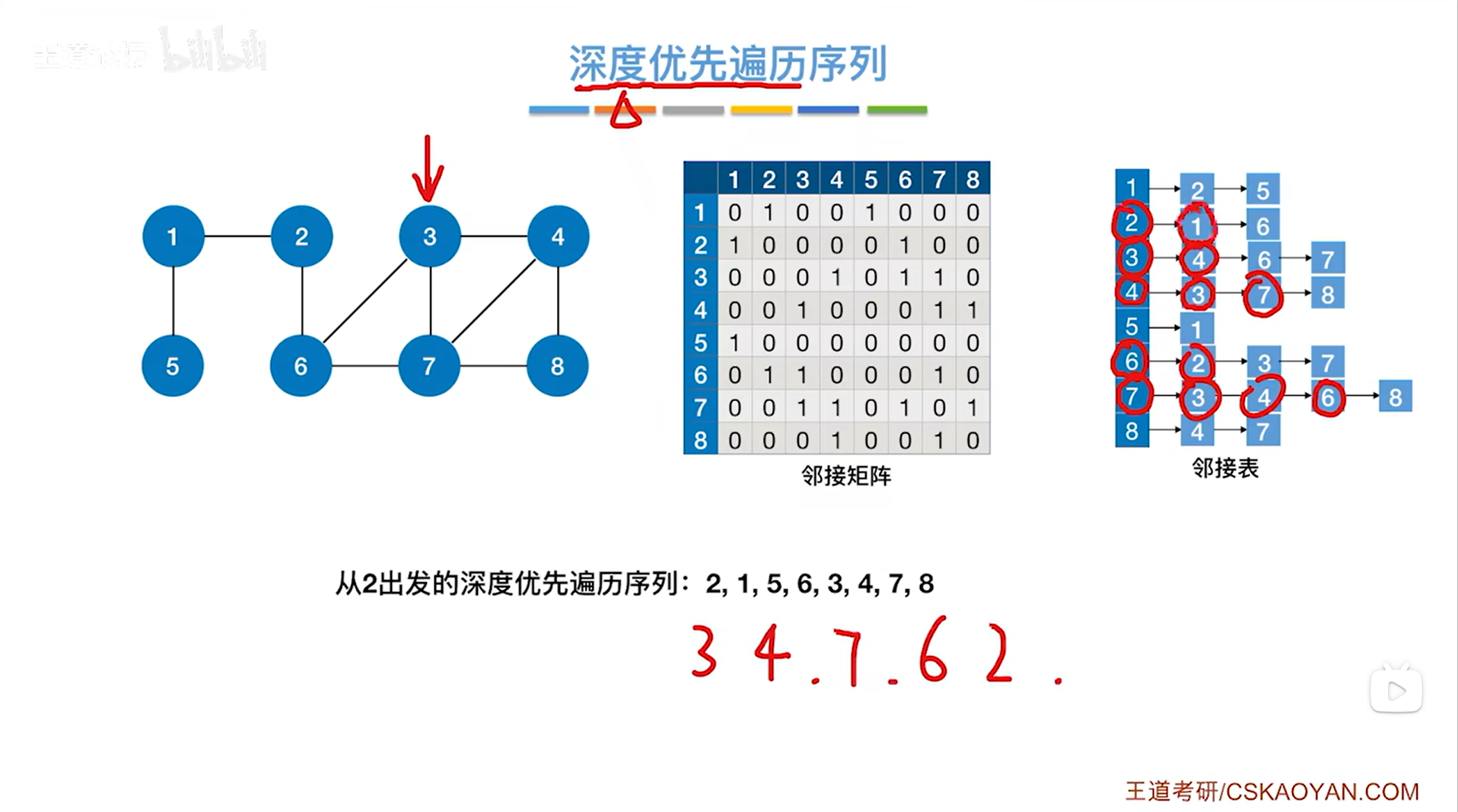
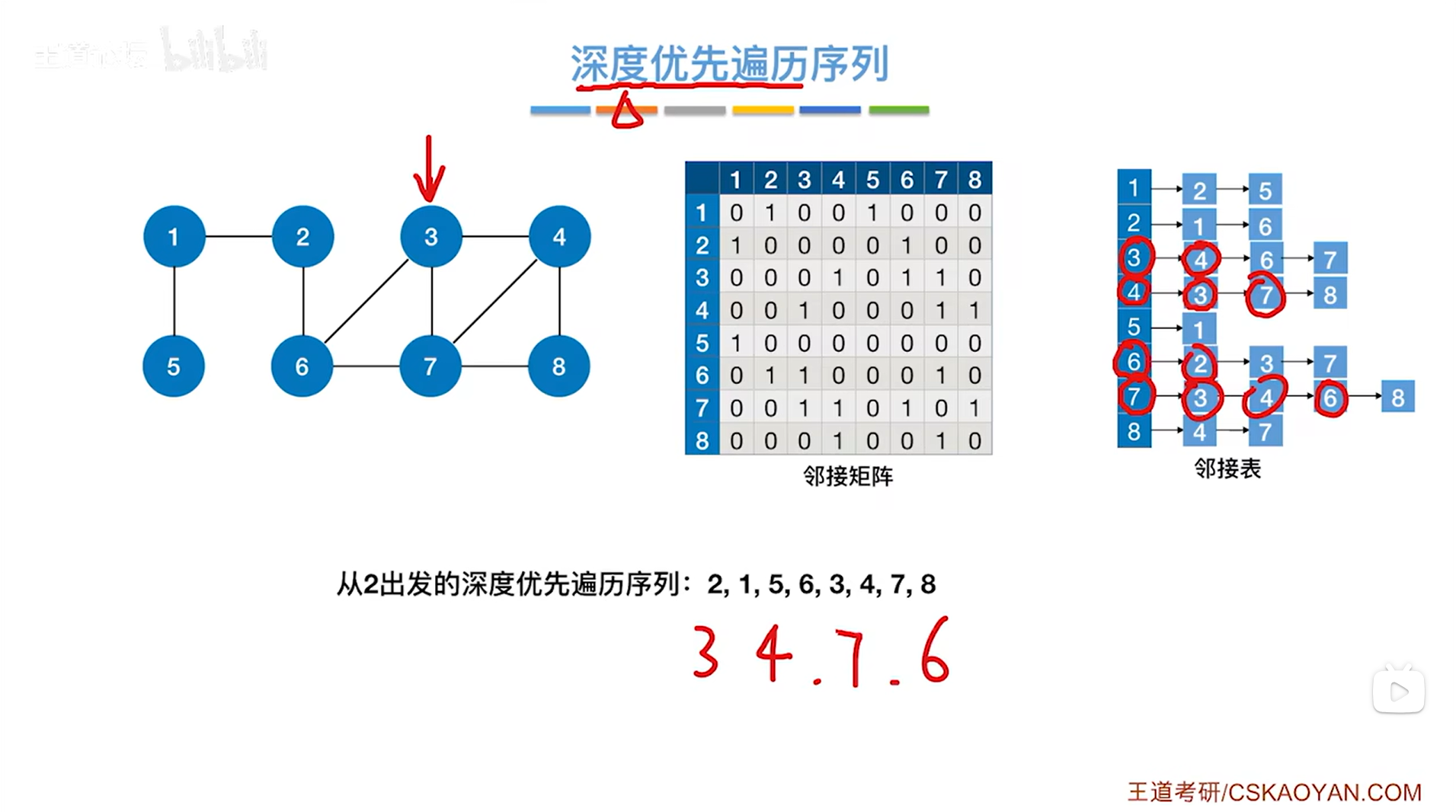
如上图,第五个访问2号顶点,与2号顶点相邻的第一个顶点即1号顶点没有被访问过,因此
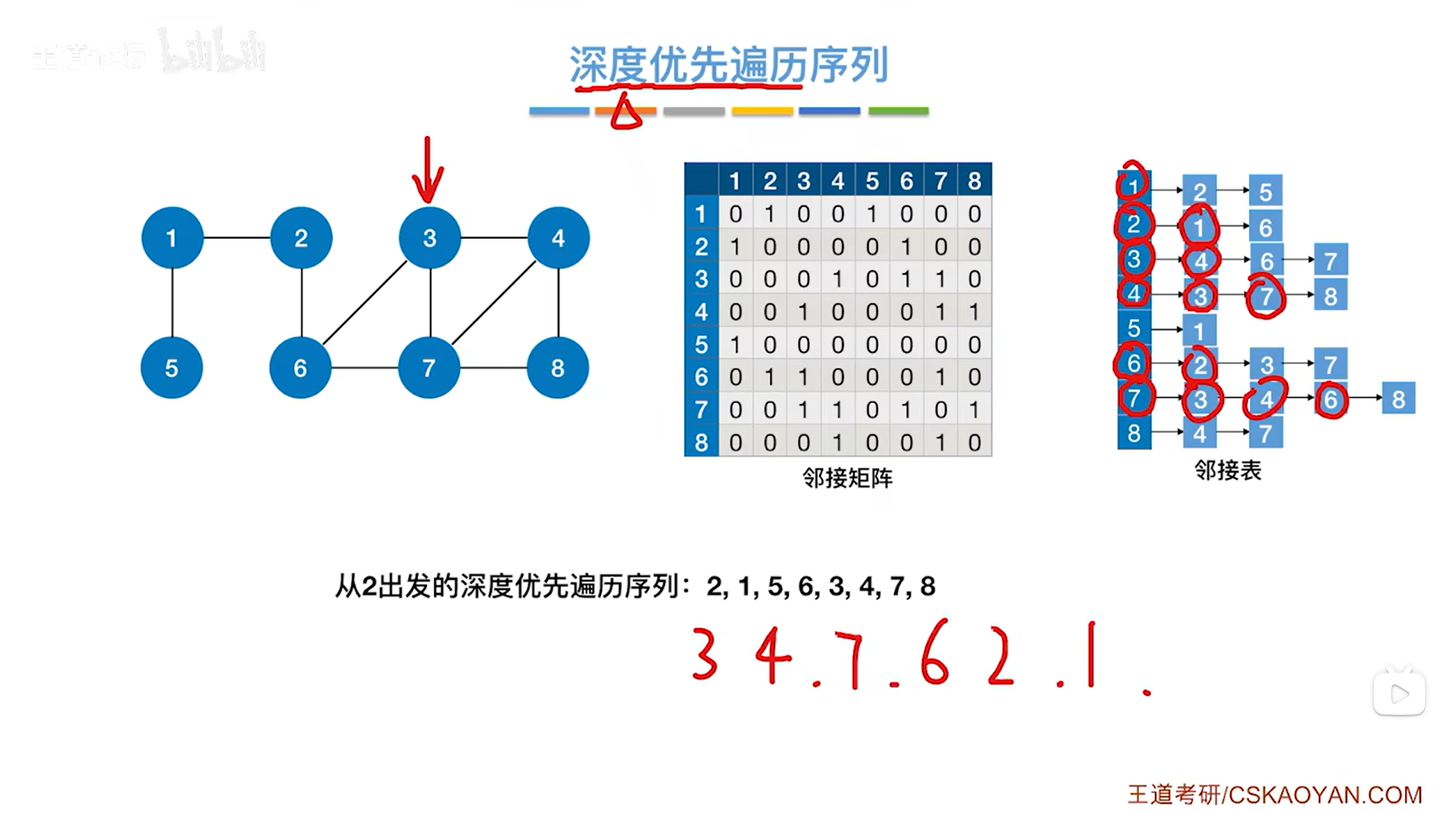
如上图,第六个访问1号顶点,与1号顶点相邻的第一个顶点即2号顶点已经被访问过了,因此跳过2号顶点,与1号顶点相邻的第二个顶点即5号顶点没有被访问过,因此
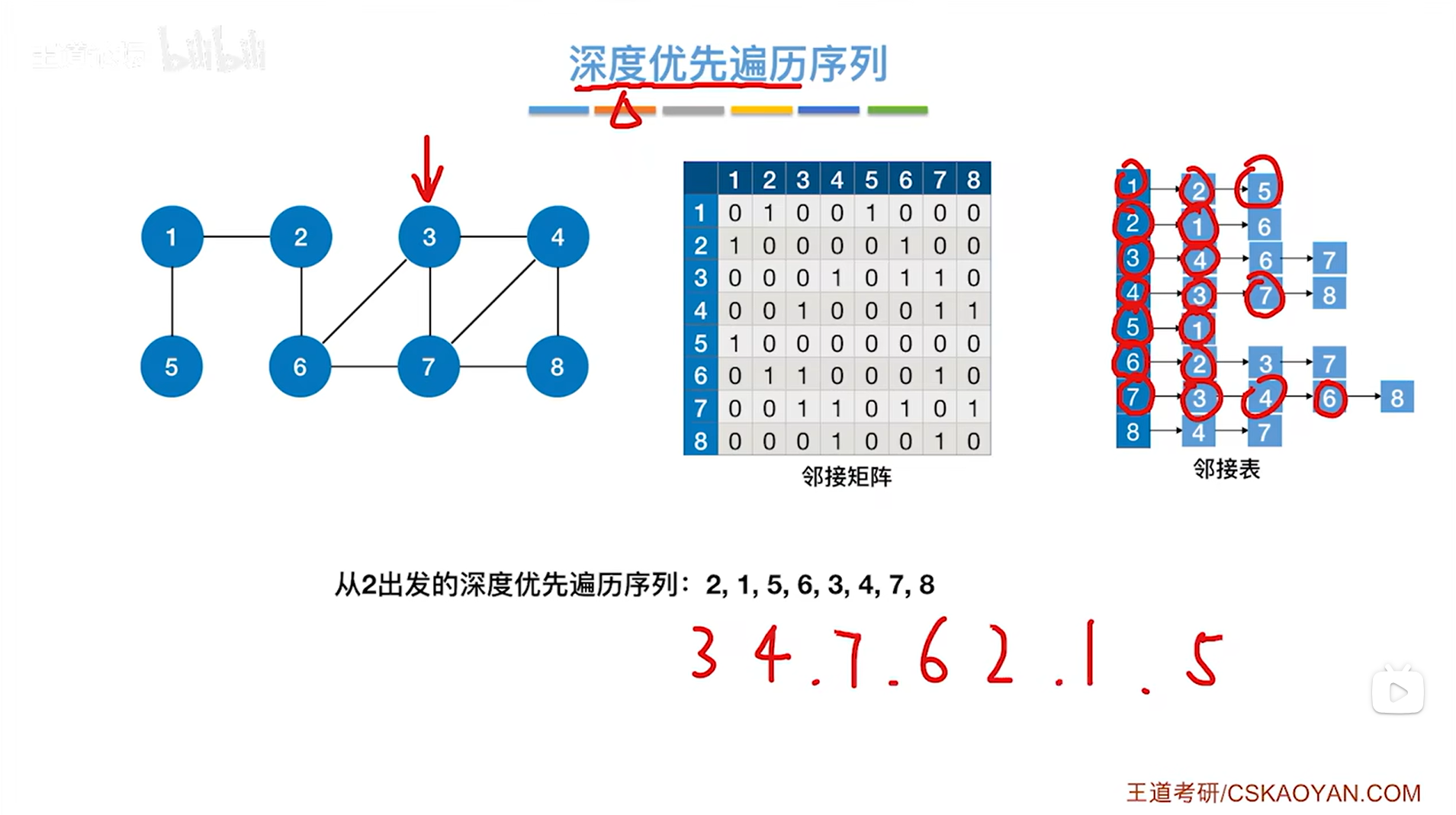
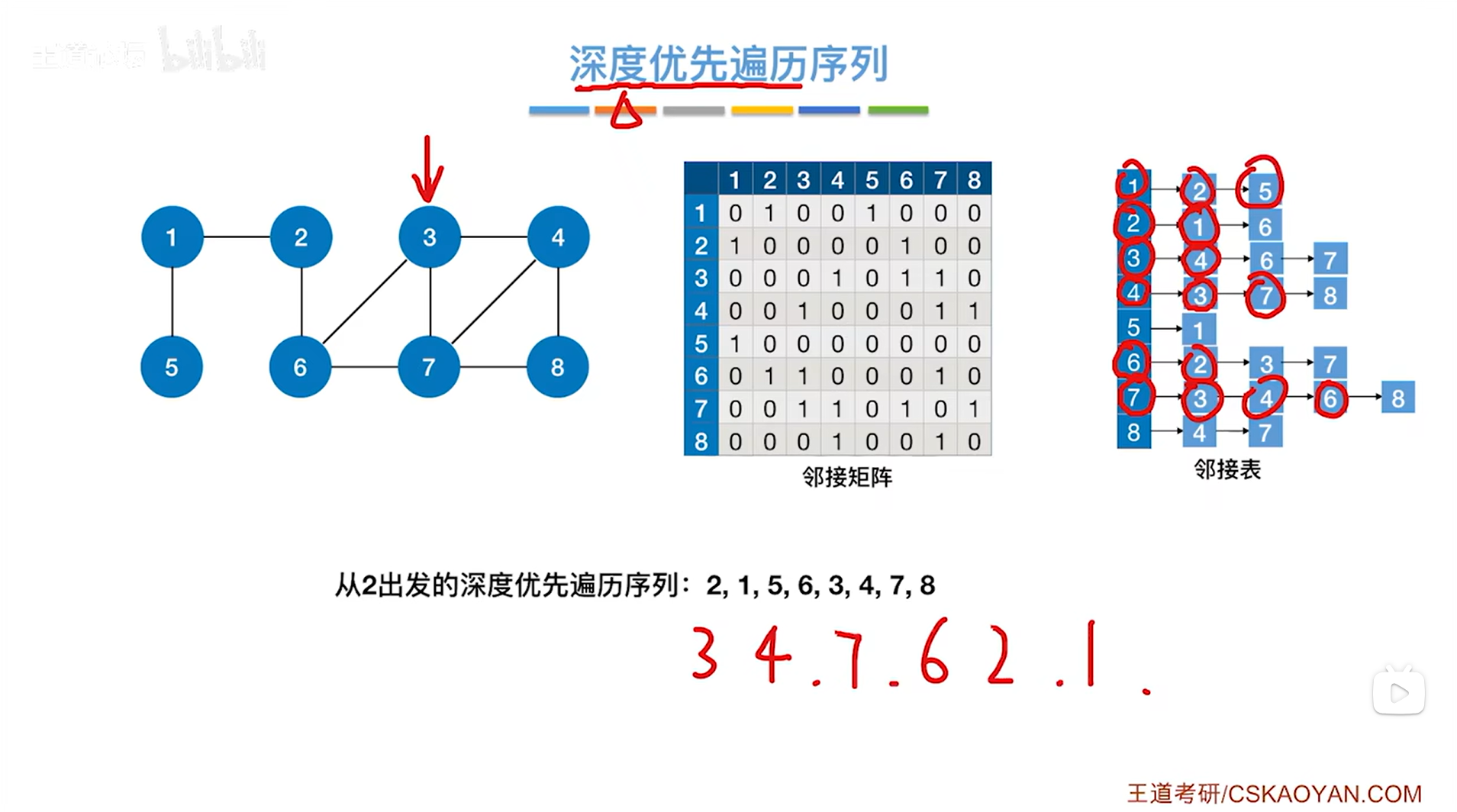
如上图,第七个访问5号顶点,与5号顶点相邻的第一个顶点即1号顶点已经被访问过了,因此跳过1号顶点->此时5号顶点对应的这一层DFS结束,退回到上一层即1号顶点对应的这一层DFS:
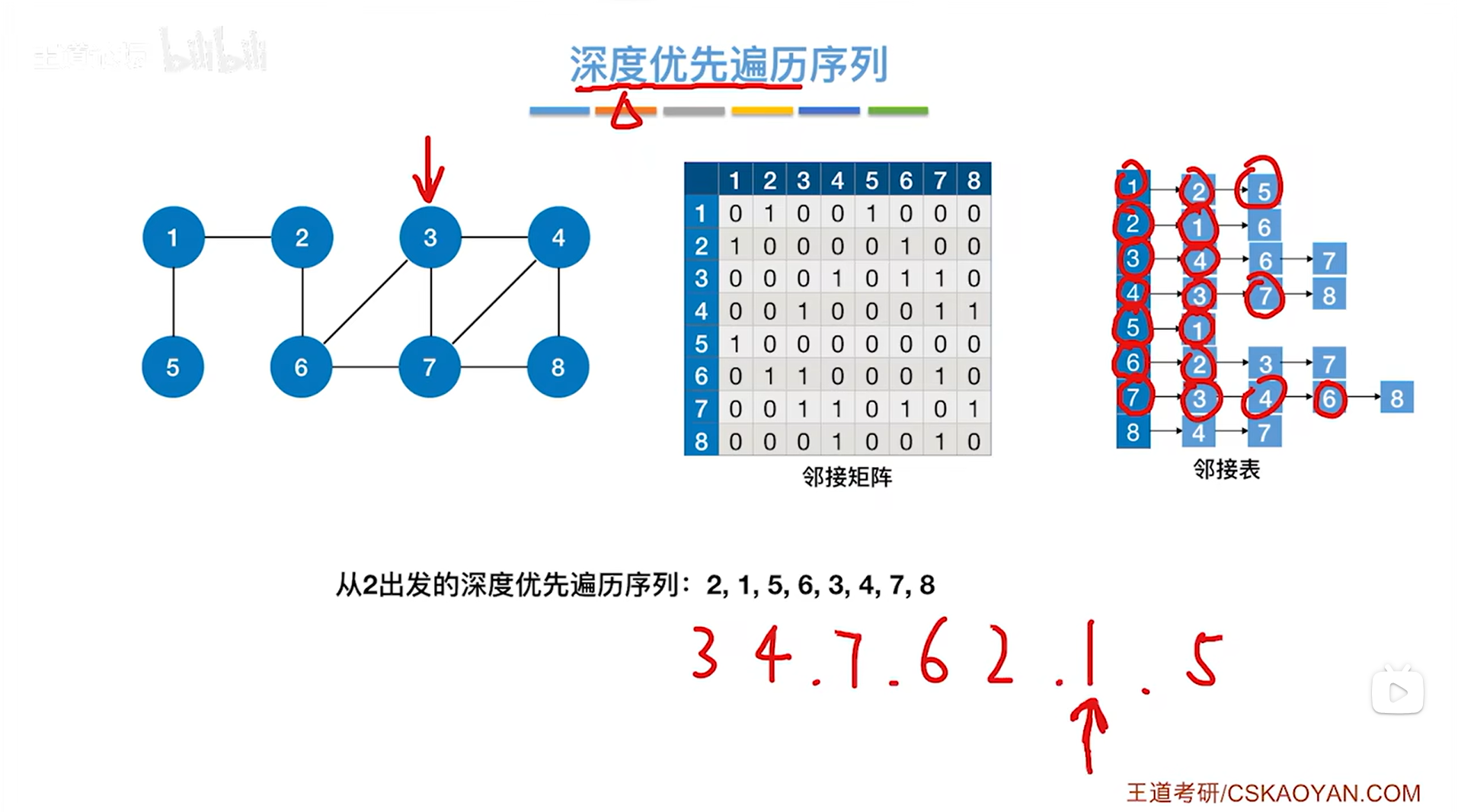
如上图,此时与1号顶点相邻的2、5号顶点全部被访问过,因此1号顶点对应的这一层DFS结束,退回到上一层即2号顶点对应的这一层DFS:
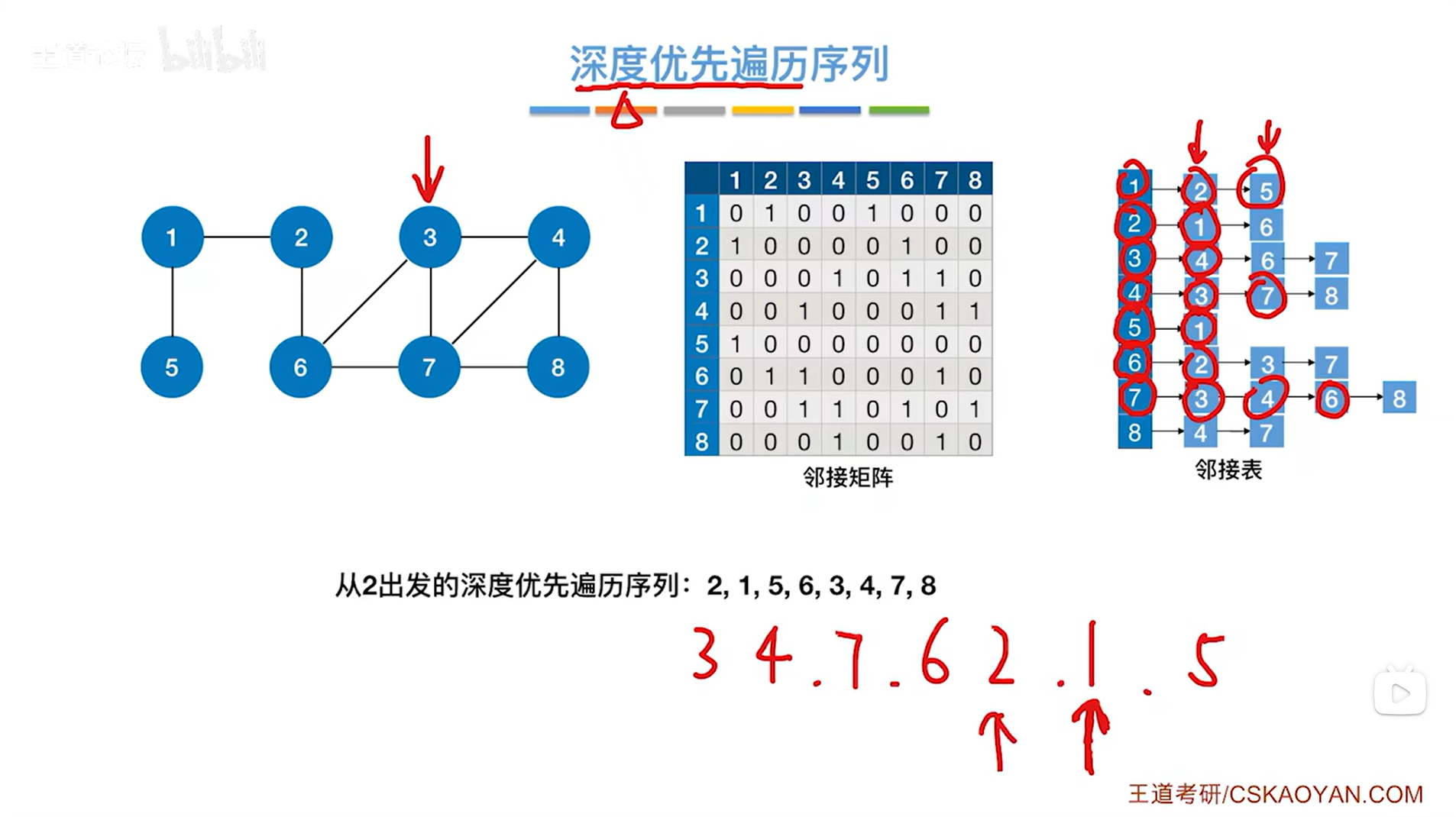
如上图,2号顶点对应的这一层DFS还有6号顶点没有检查过,但6号顶点已经访问过了,所以退回到上一层即6号顶点对应的这一层DFS:
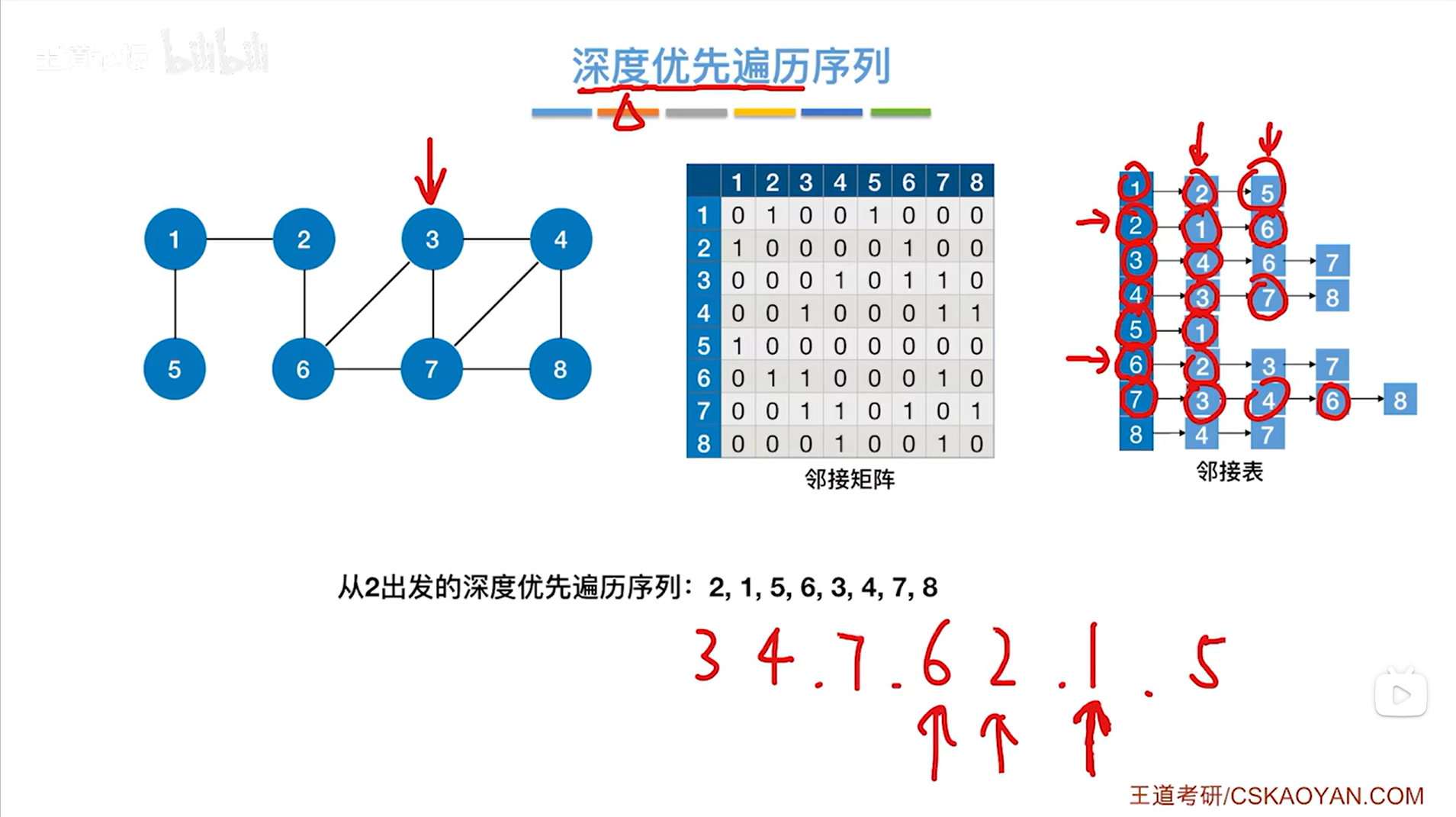
如上图,和6号顶点相邻的顶点中还剩3、7号顶点没有检查,但3、7号顶点已经被访问过了,因此退回到上一层即7号顶点对应的这一层DFS:
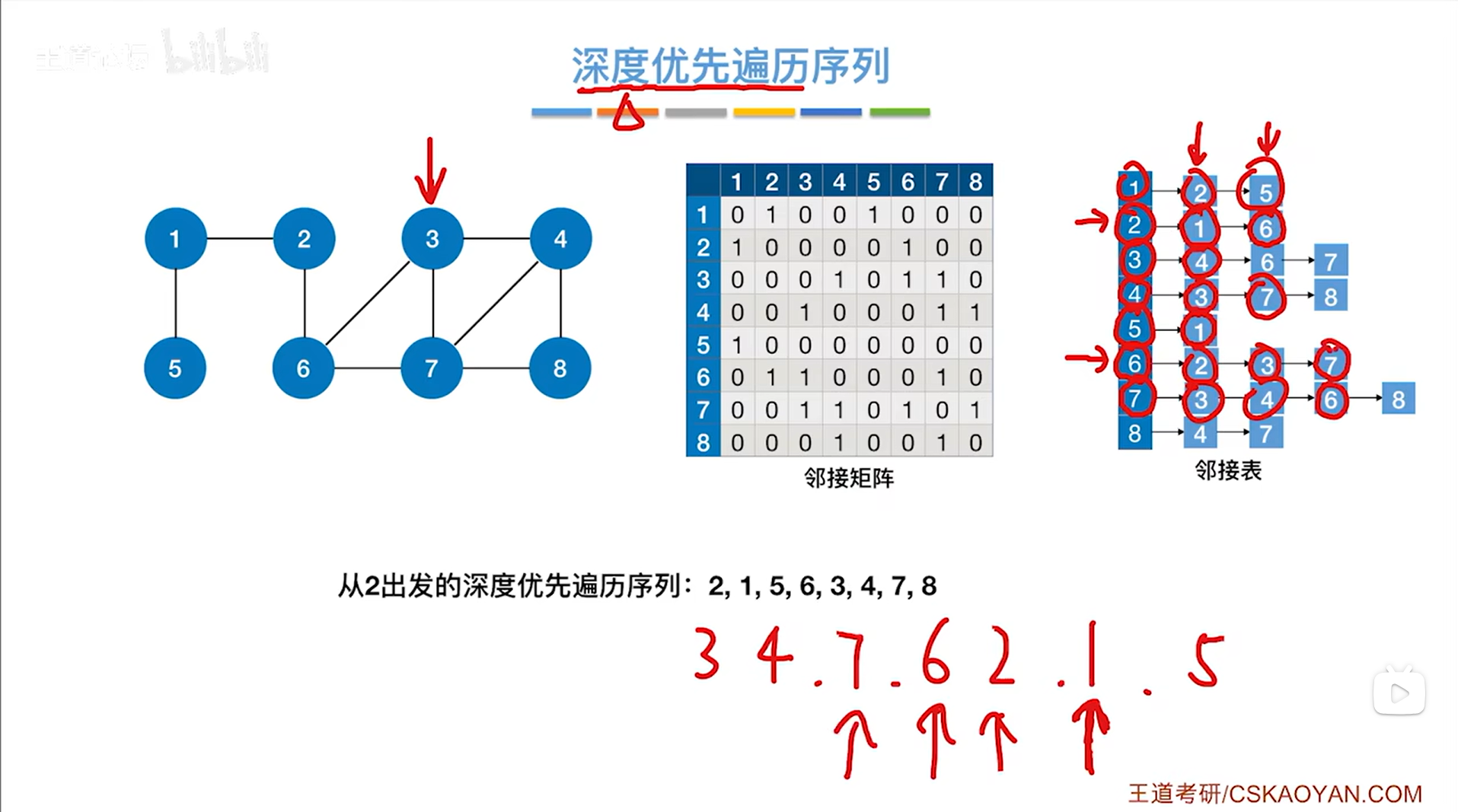
如上图,和7号顶点相邻的顶点中还剩下8号顶点没有被访问过:
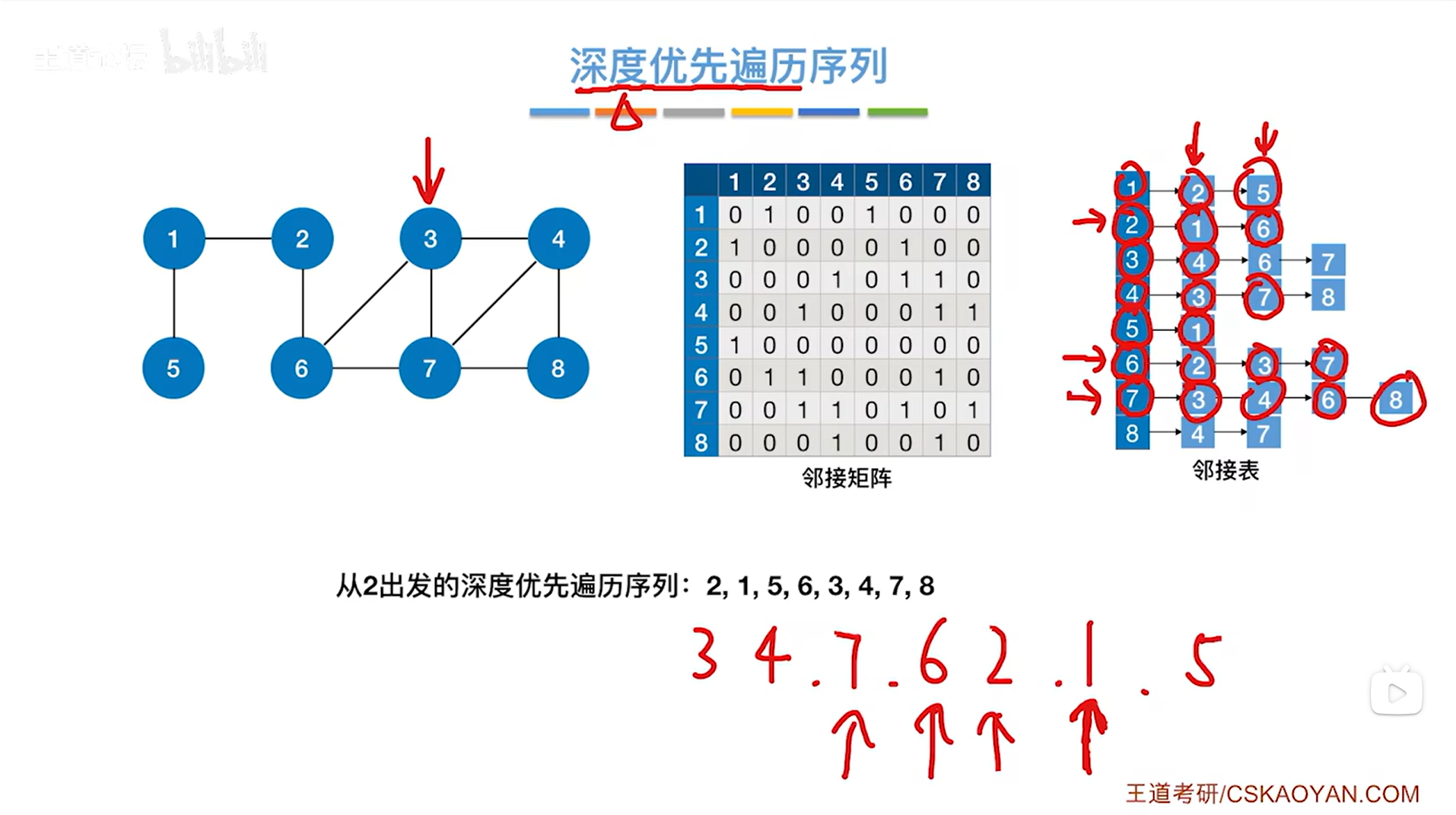
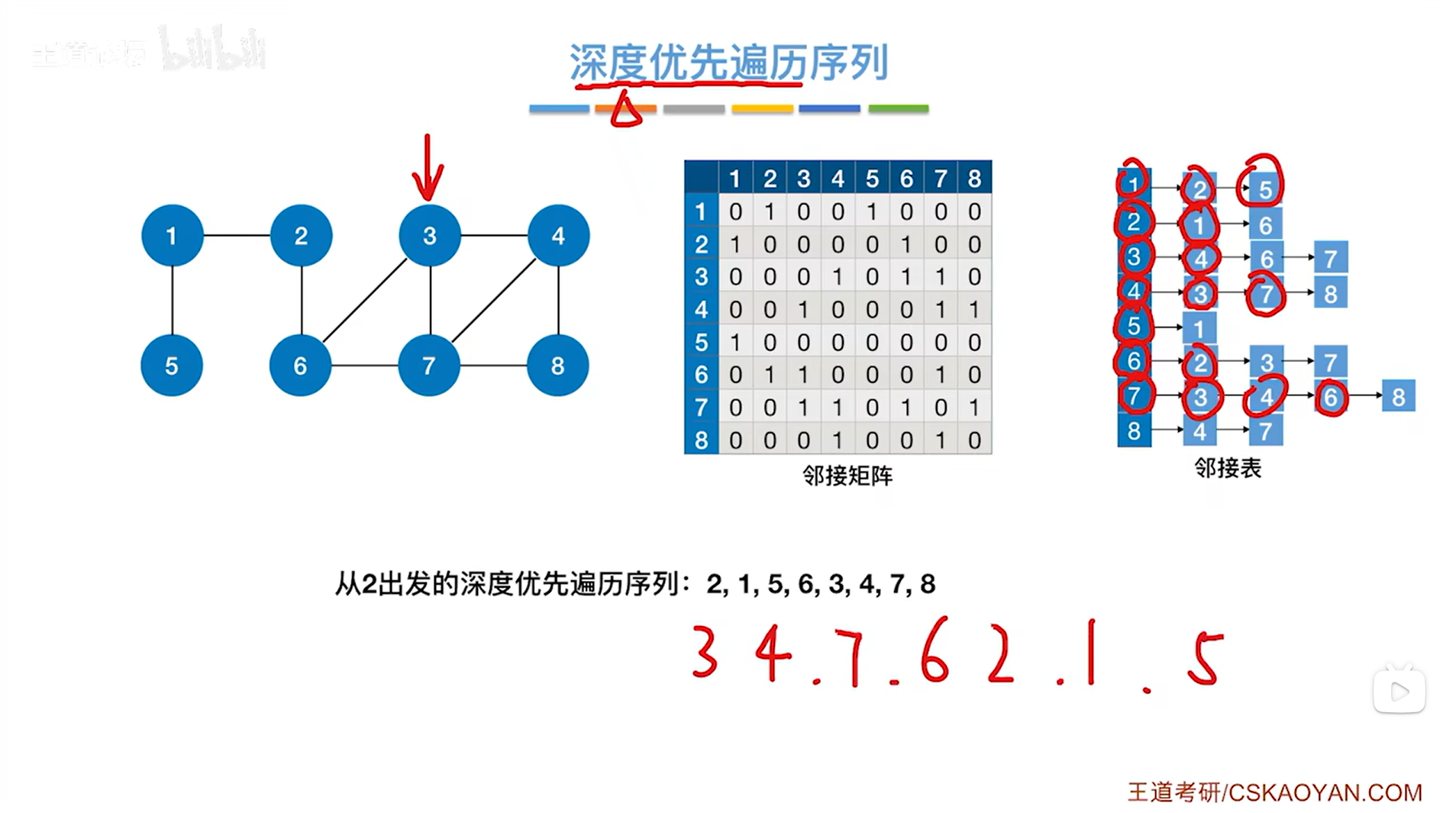
如下图,所以第八个访问8号顶点,
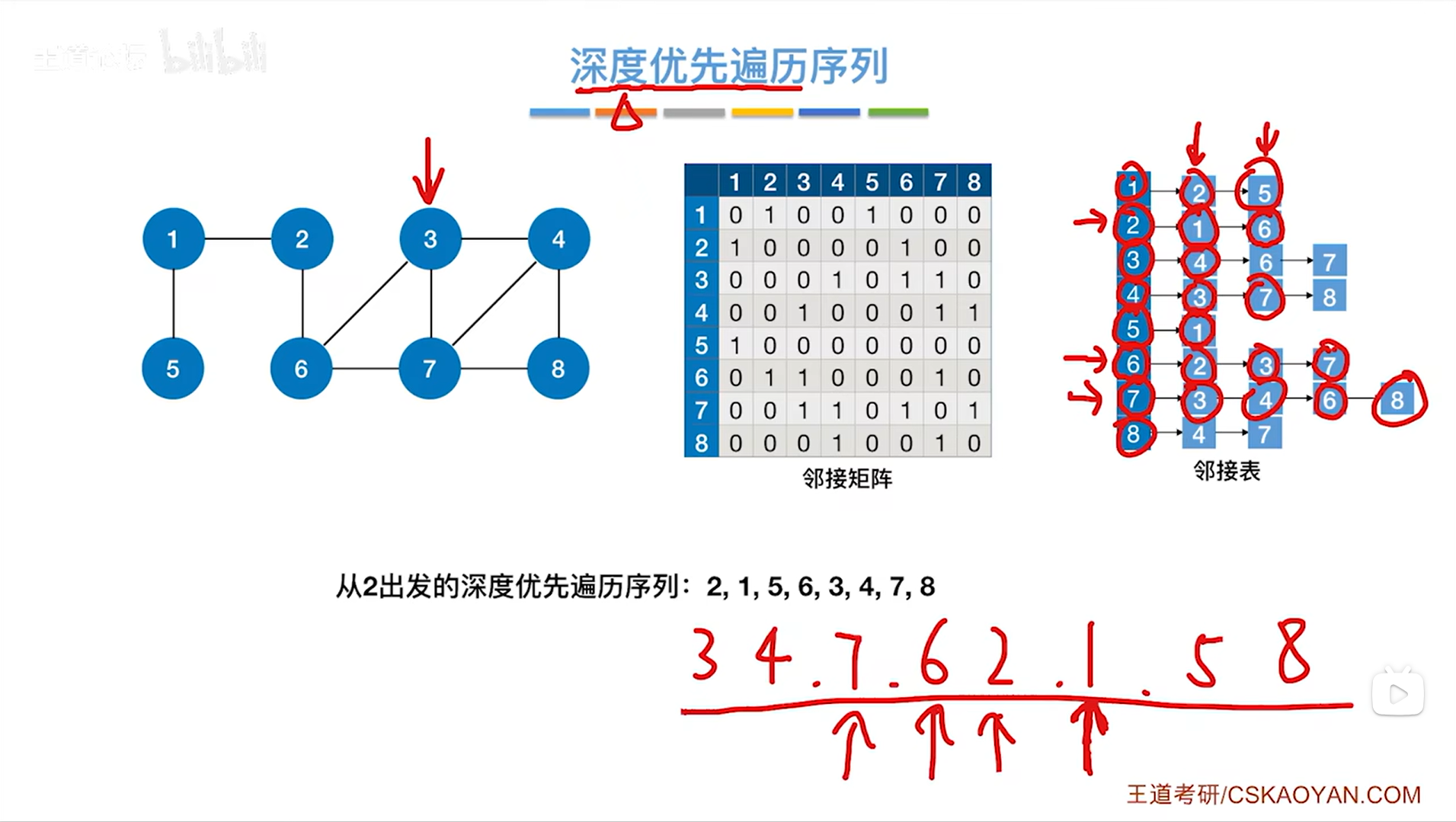
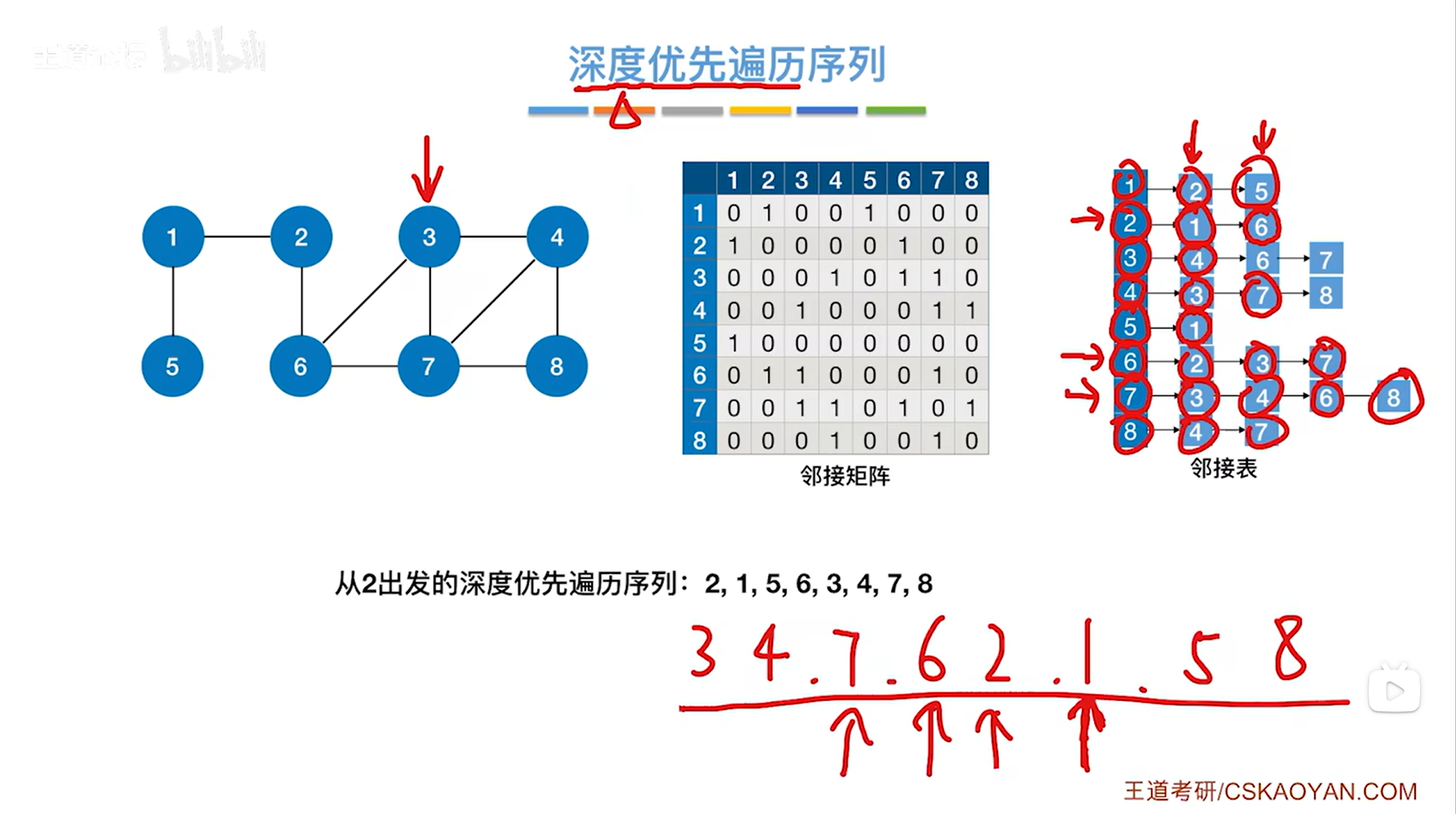
如上图,与8号顶点相邻的顶点中4、7号顶点全部被访问过,所以退回到上一层即7号顶点对应的这一层DFS,
此时7号顶点对应的这一层DFS结束,退回到上一层即4号顶点对应的这一层DFS,
和4号顶点相邻的顶点中还剩8号顶点没有检查,但8号顶点已经被访问过了,因此退回到上一层即3号顶点对应的这一层DFS,
此时还剩下6、7号顶点没有检查,但6、7号顶点已经被访问了,因此退出3号顶点对应的这一层DFS,
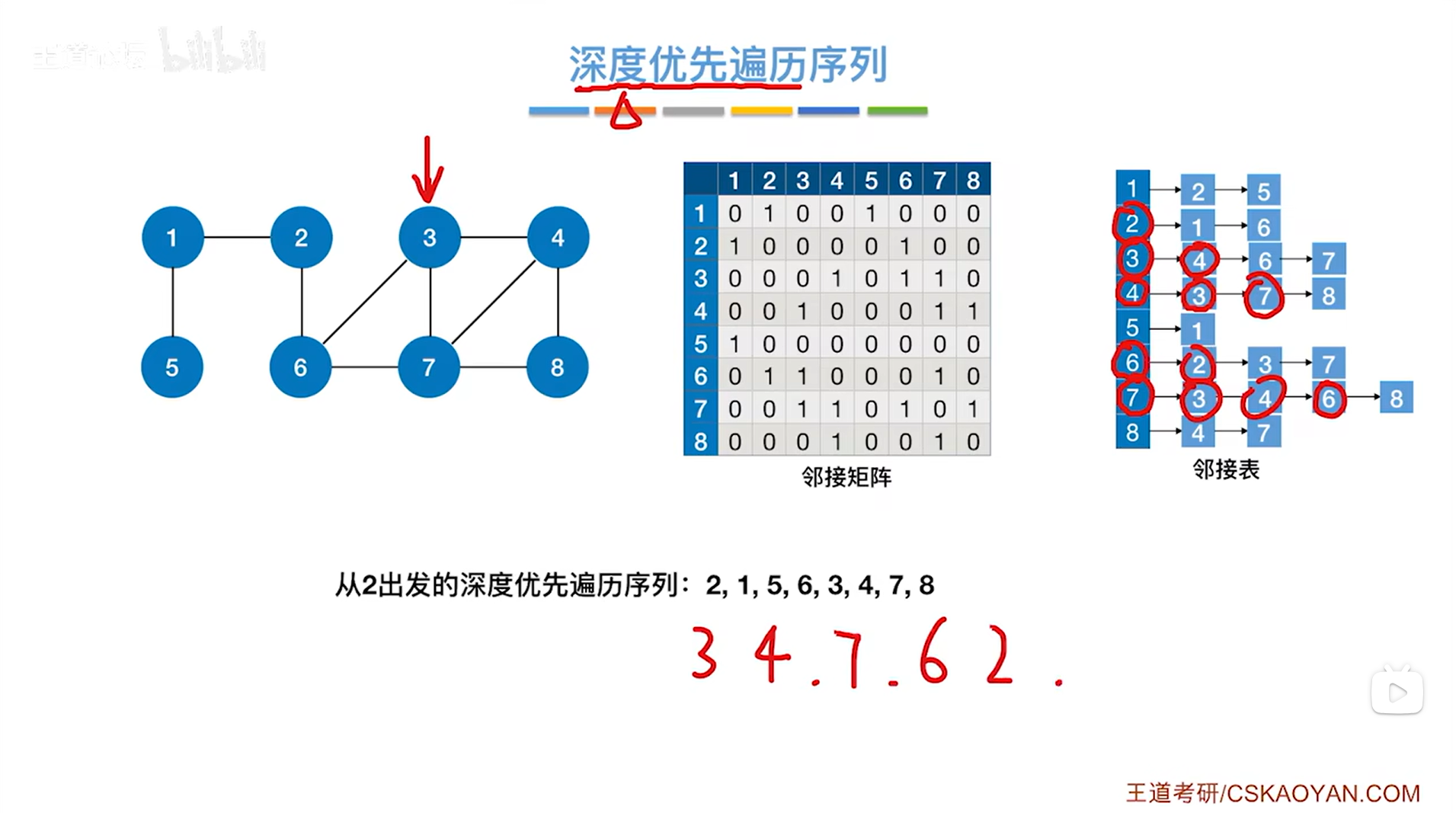
最终该图的深度优先遍历结束,得到的遍历序列为3、4、7、6、2、1、5、8:
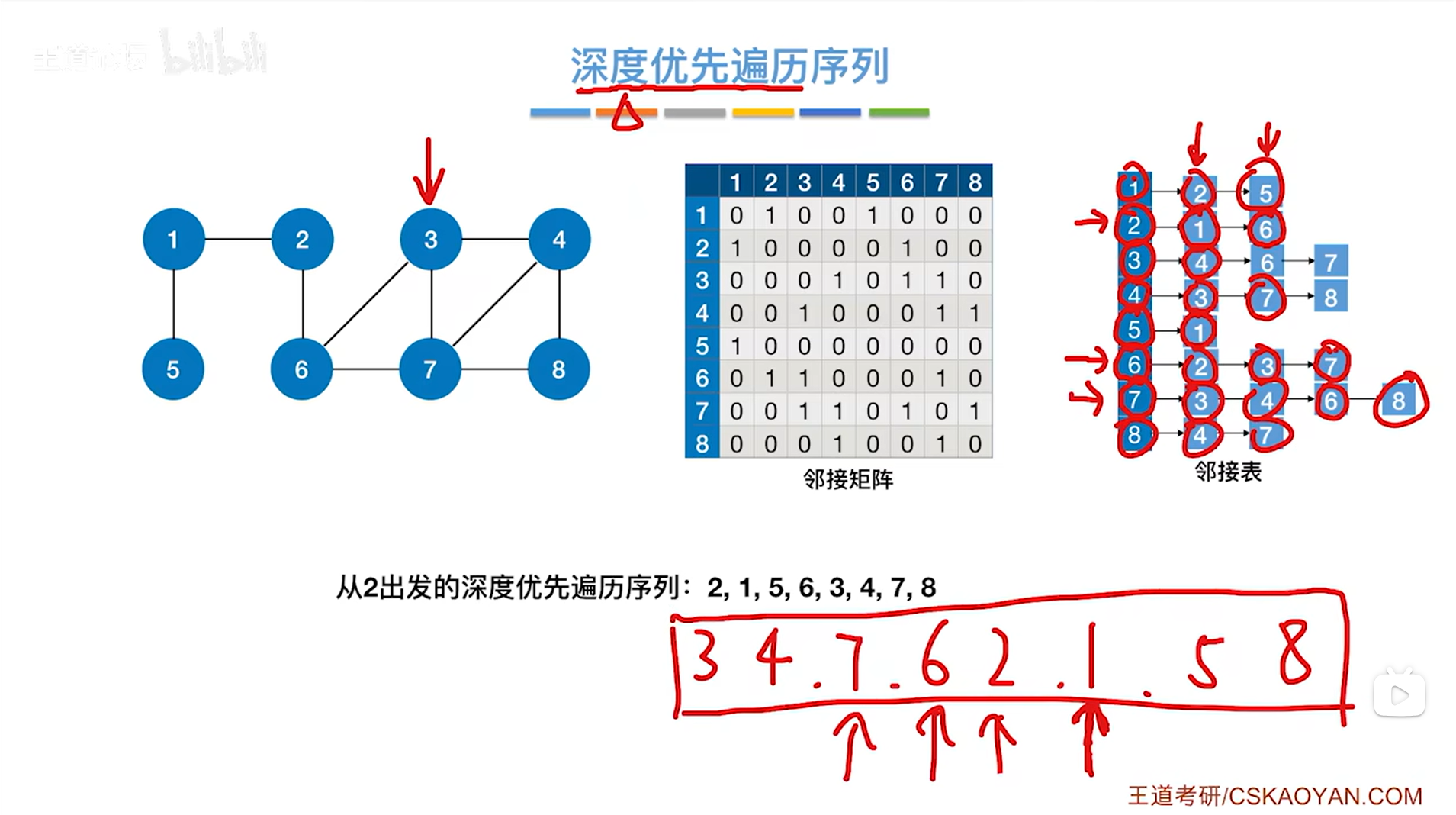
3.从1号顶点出发进行深度优先遍历整个图:
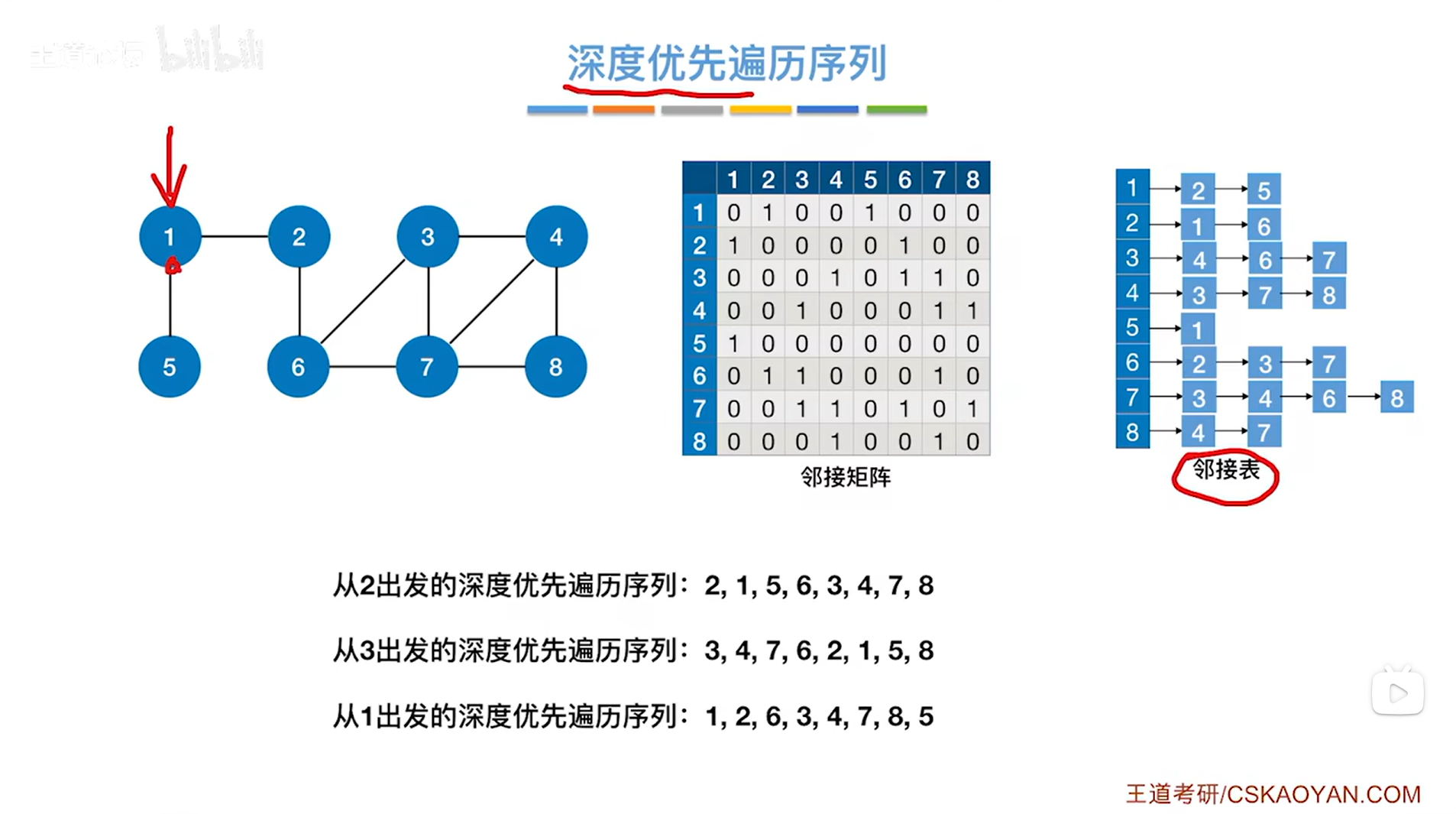
4.细节:当图使用邻接表存储的话,由于邻接表的表现方式不唯一即顶点对应的链表中顶点号顺序不固定,因此如果从某一个顶点出发深度优先遍历得到的图的序列也可能不一样
对于图而言,它的邻接矩阵存储的表示方式是唯一的,但邻接表的表示方式不唯一,
所以如果图使用邻接表存储的话,从某一顶点出发深度优先遍历图,最终得到的遍历序列也可能不同,这个与BFS一样。
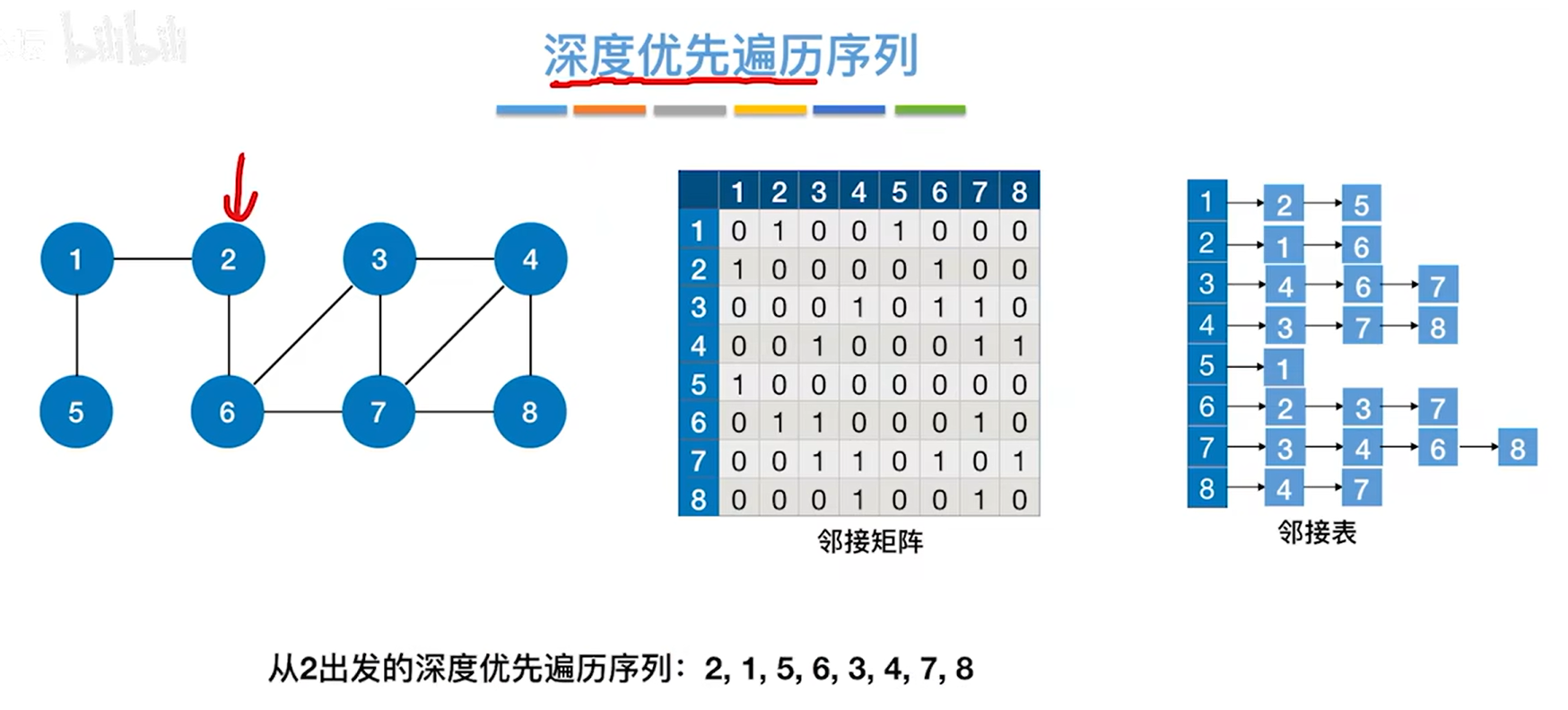
如上图,图使用上述图片呈现的邻接表存储,从2号顶点出发,得到的深度优先遍历序列为2、1、5、6、3、4、7、8,
如下图,此时把邻接表的内容稍作修改即把顶点对应的链表中的顶点号换一下顺序:
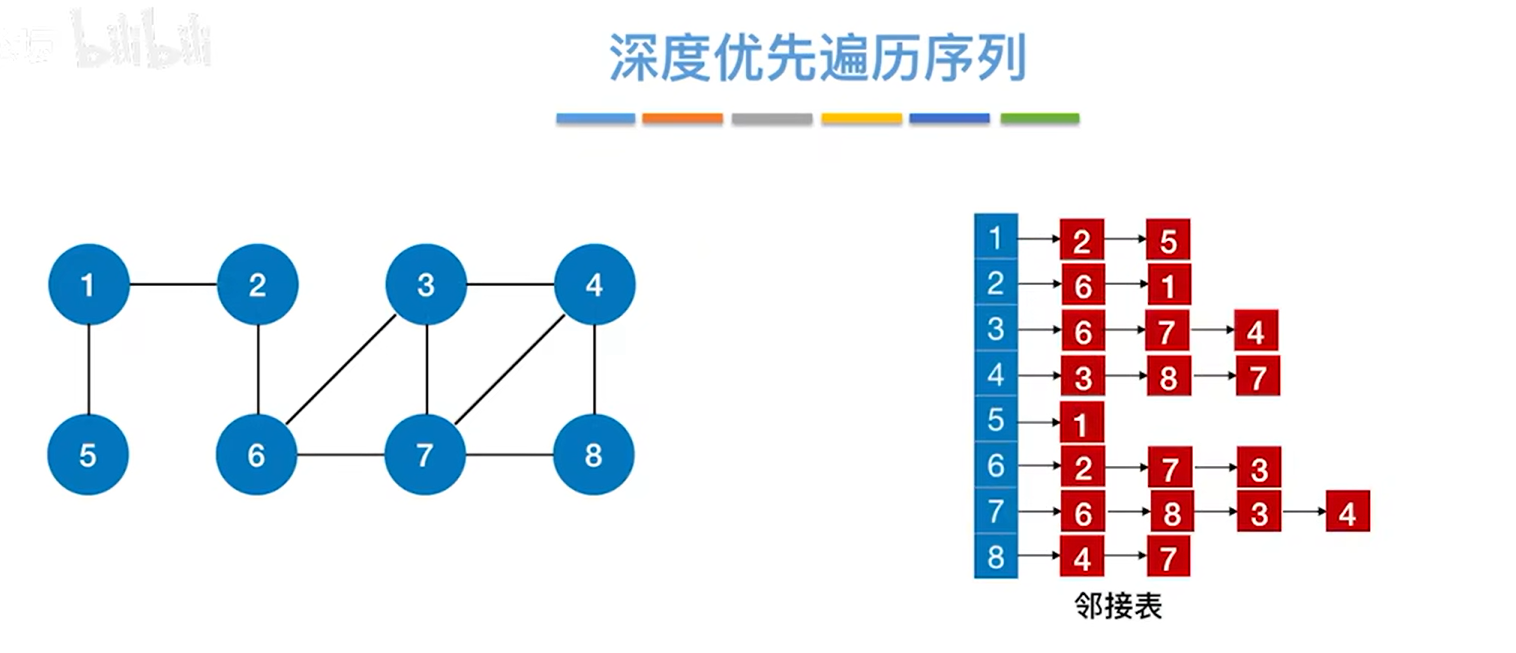
从2号顶点出发开始深度优先遍历图,
第一个访问2号顶点,与2号顶点相邻的第一个顶点即6号顶点没有被访问过(这个直接看顶点对应的链表即可)
第二个访问6号顶点,与6号顶点相邻的第一个顶点即2号顶点已经被访问过,因此跳过2号顶点,与6号顶点相邻的第二个顶点即7号顶点还没有被访问过,
第三个访问7号顶点,与7号顶点相邻的第一个顶点即6号顶点已经被访问过,因此跳过6号顶点,与7号顶点相邻的第二个顶点即8号顶点还没有被访问过,
第四个访问8号顶点,与8号顶点相邻的第一个顶点即4号顶点还没有被访问过,
第五个访问4号顶点,与4号顶点相邻的第一个顶点即3号顶点还没有被访问过,
第六个访问3号顶点,与3号顶点相邻的顶点有6、7、4号顶点,这些顶点都被访问过,

因此3号顶点对应的DFS递归调用结束,
返回到4号顶点对应的DFS,与4号顶点相邻的只剩下8、7号顶点没有检查过,但8、7号顶点都被访问过,
所以继续返回到8号顶点对应的DFS,与8号顶点相邻的7号顶点也已经被访问过,
所以继续返回到7号顶点对应的DFS,与7号顶点相邻的3、4号顶点也已经被访问过,
所以继续返回到6号顶点对应的DFS,与6号顶点相邻的3号顶点也已经被访问过,
所以继续返回到2号顶点对应的DFS,与2号顶点相邻的还剩一个1号顶点,1号顶点还没有被访问过,
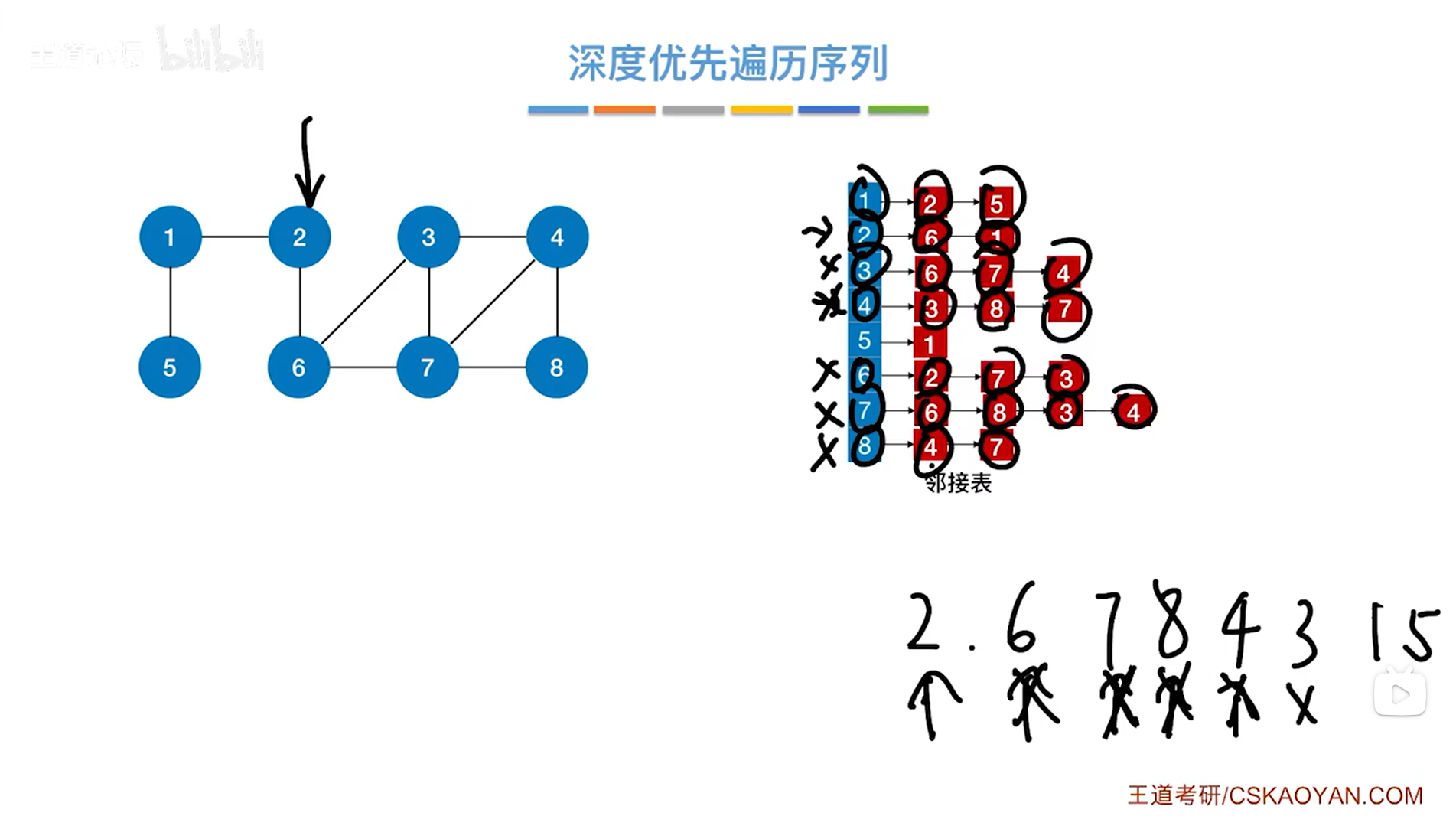
第七个访问1号顶点,与1号顶点相邻的第一个顶点即2号顶点已经被访问过,因此跳过2号顶点,与1号顶点相邻的第二个顶点即5号顶点还没有被访问过,
第八个访问5号顶点,与5号顶点相邻的第一个顶点即1号顶点已经被访问过,此时5号顶点访问结束,
返回到1号顶点对应的DFS,与1号顶点相邻的所有顶点全部访问完毕,
所以继续返回到2号顶点对应的DFS,此时与2号顶点相邻的顶点全部访问完毕,
最终该图的深度优先遍历结束,得到的遍历序列为2、6、7、8、4、3、1、5:

5.总结:关于图采用邻接表存储
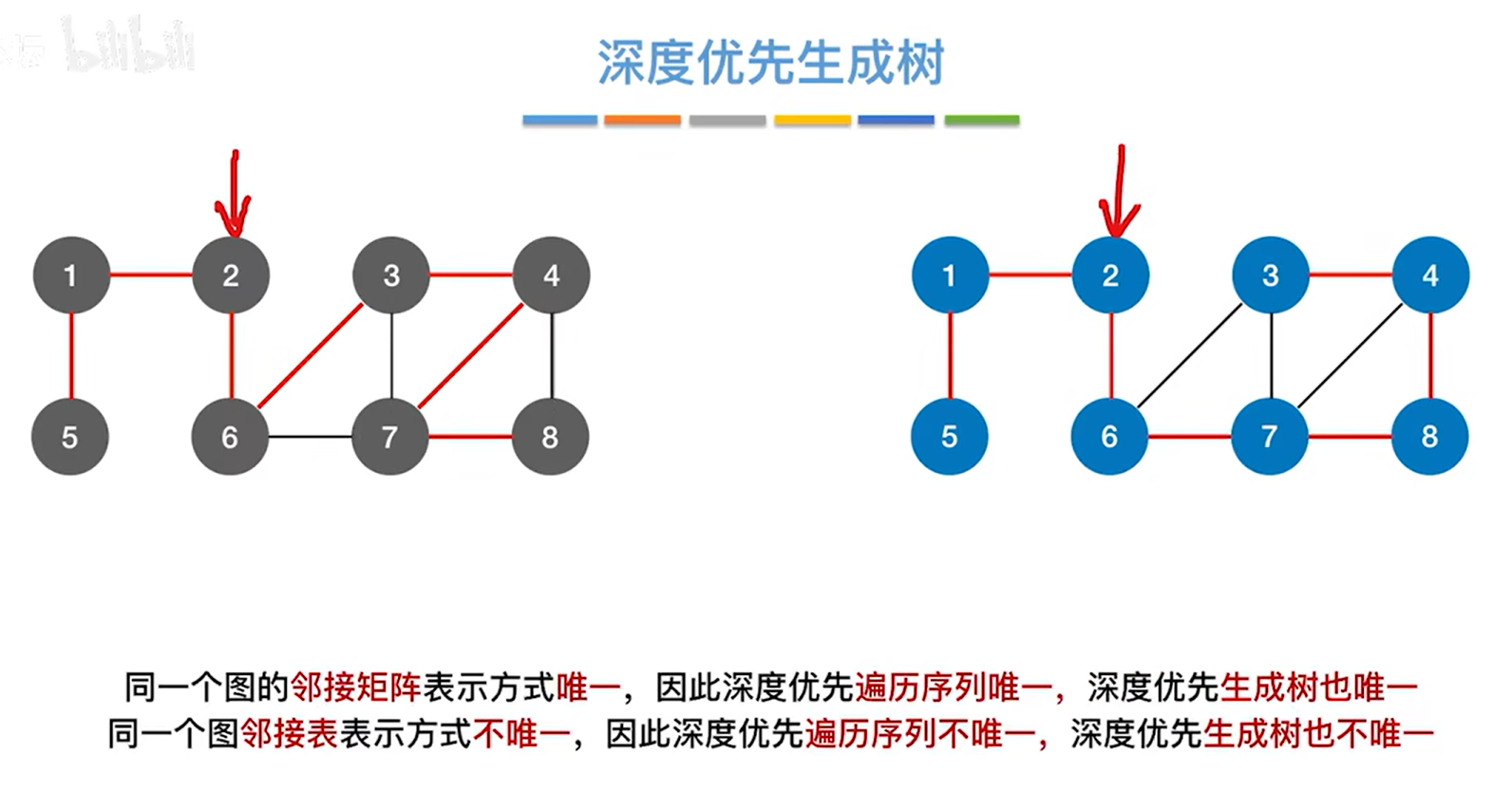
五.深度优先生成树:
下图的两个例子都是从2号顶点开始深度优先遍历图,左边的例子基于之前第一个邻接表,右边的例子基于之前第二个邻接表,由于邻接表的不同,即使从同一个顶点开始深度优先遍历,得到的遍历序列也可能不同,:
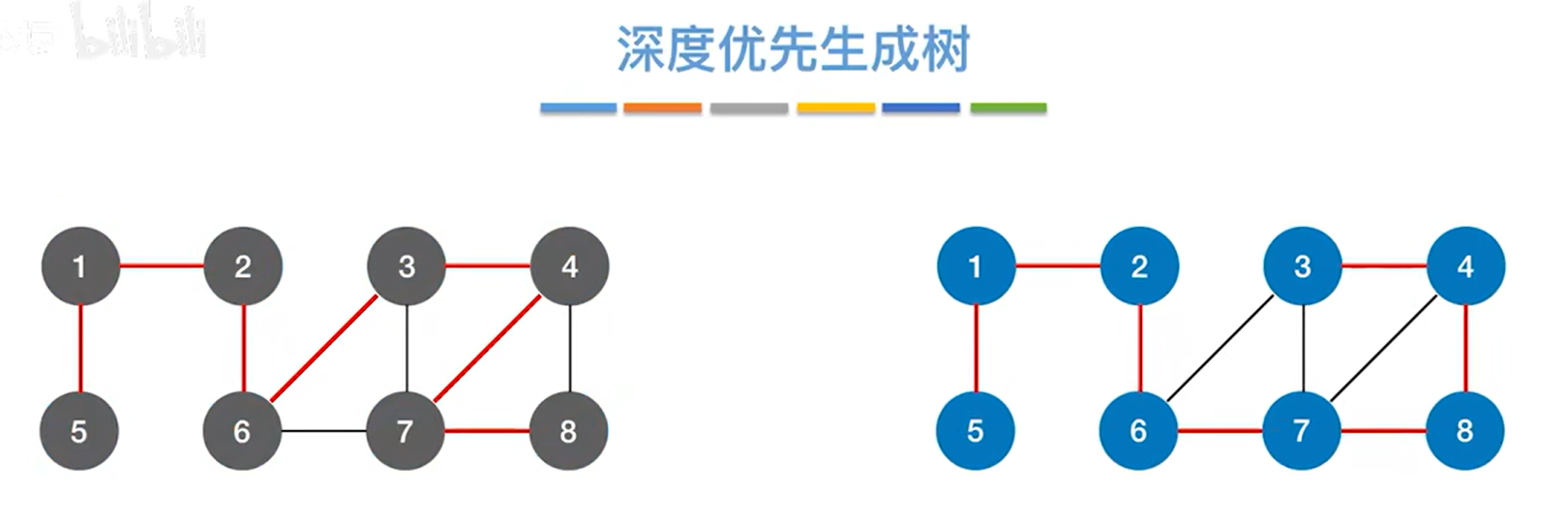
深度优先遍历的过程中也是在探索各条边所连接的顶点的过程,
如果通过某一条边找到某个顶点且该顶点还没有被访问过,此时就把这条边标红,通过某一条边找到某个顶点且该顶点被访问过则边标黑,
如果只保留红色的边,把黑色的边去掉,最终的图就变成了一个没有环的树,
如果采用邻接表存储的图,即便从同一个顶点出发进行深度优先遍历,也有可能得到不一样的深度优先遍历序列,因此也会对应不一样的深度优先生成树:
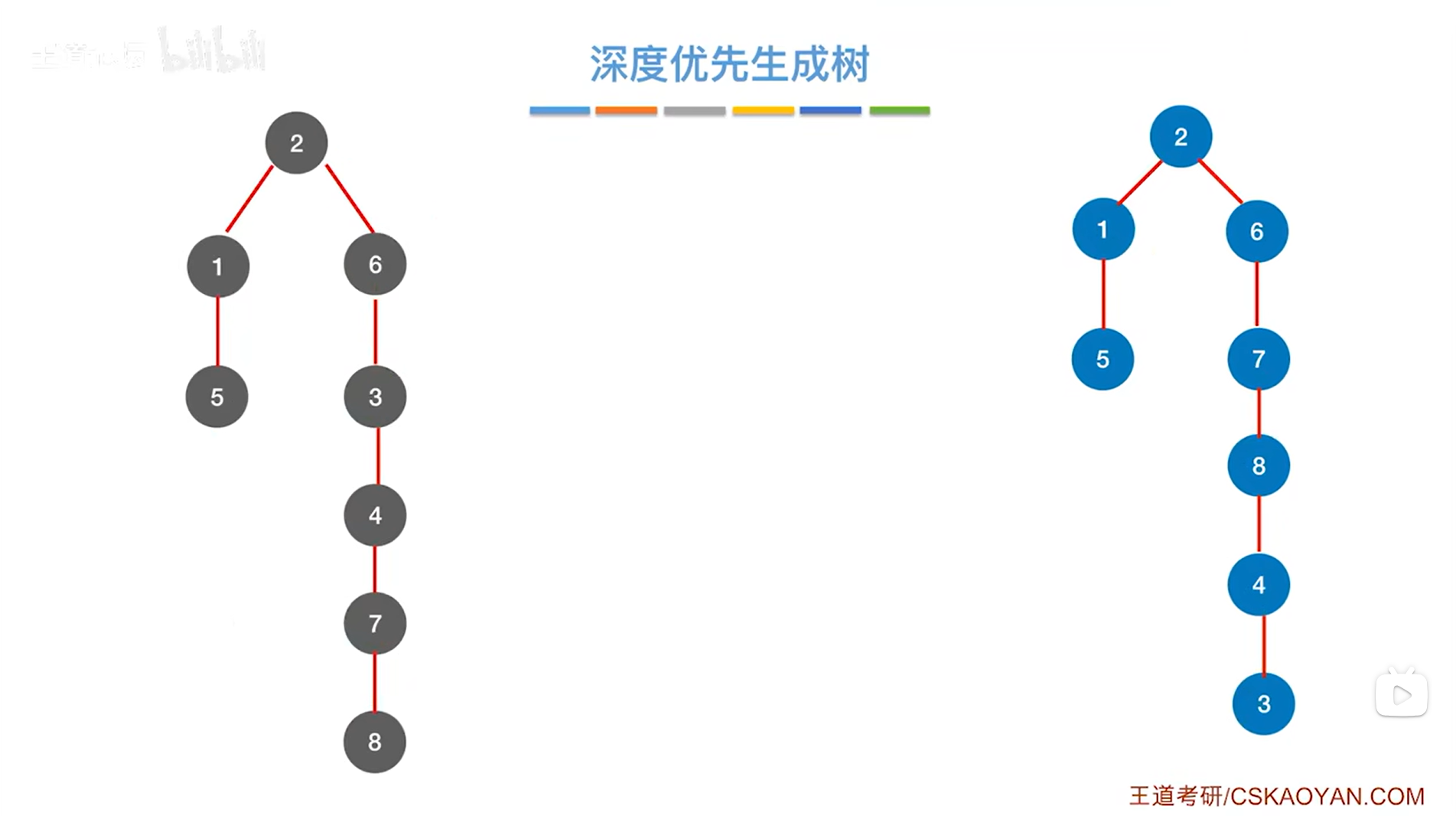
六.深度优先生成森林:
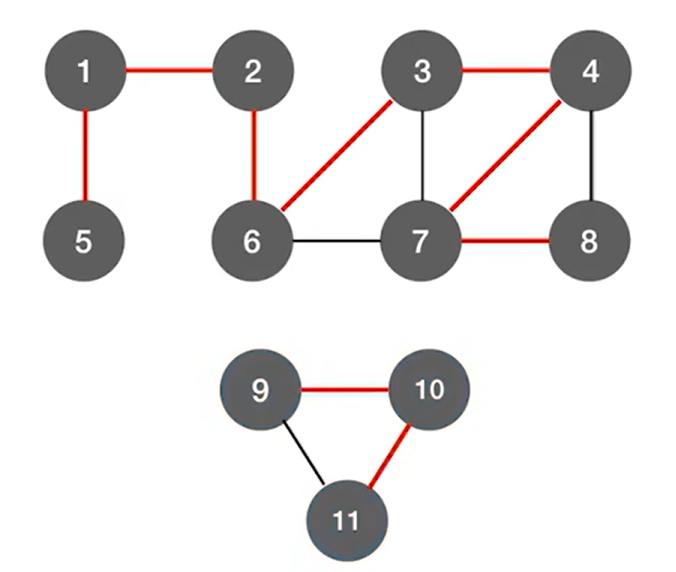
如上图,如果图是非连通的,也就是说要调用多次DFS函数才能把图深度优先遍历完,每调用一次DFS函数,就会生成一棵深度优先生成树,由于上述图片的无向图有两个连通分量,所以需要调用两次DFS函数,因此也会对应的生成两棵深度优先生成树:
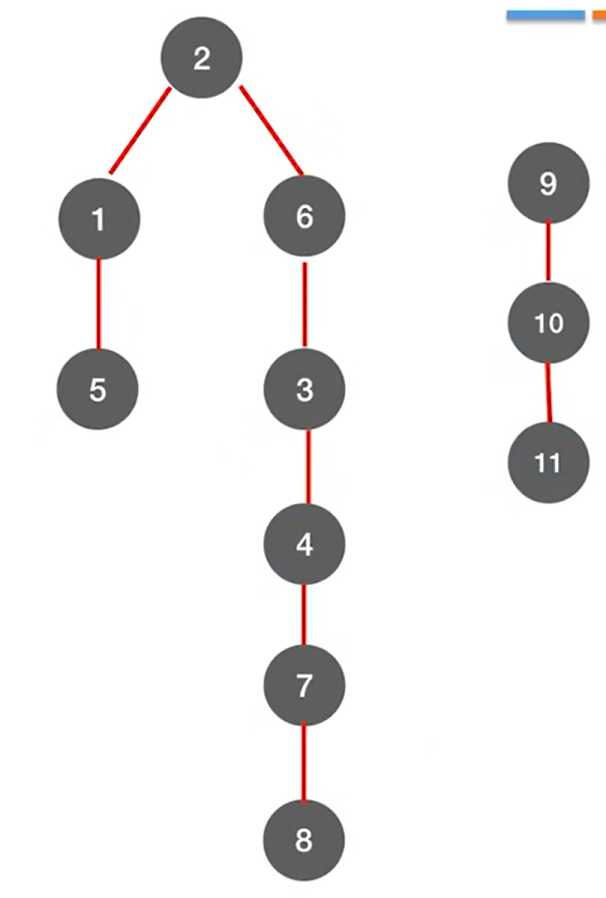
上述图片的两棵深度优先生成树就组成了深度优先生成森林。
七.图的遍历与图的连通性:
1.无向图:

对于无向图而言,进行BFS或者DFS时,遍历图中调用BFS函数或者DFS函数的次数等于连通分量数。
如上图,把上述图片的图进行BFS或者DFS时,由于该图有3个连通分量数,因此需要调用3次BFS或者DFS才能遍历完图。
如果无向图是连通图即只有1个连通分量,所以只需要调用1次BFS或者DFS函数即可遍历完图。
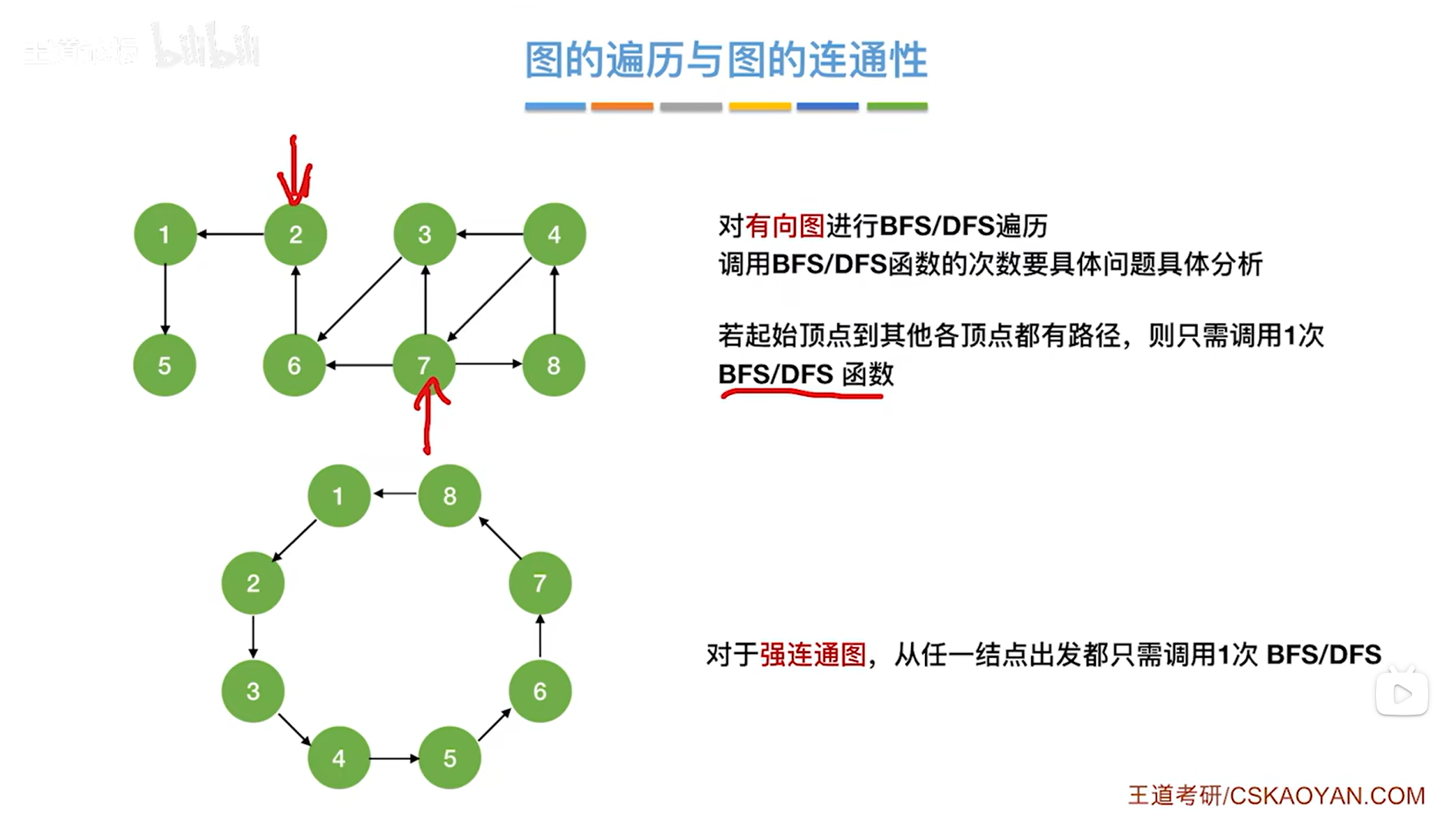
2.有向图:
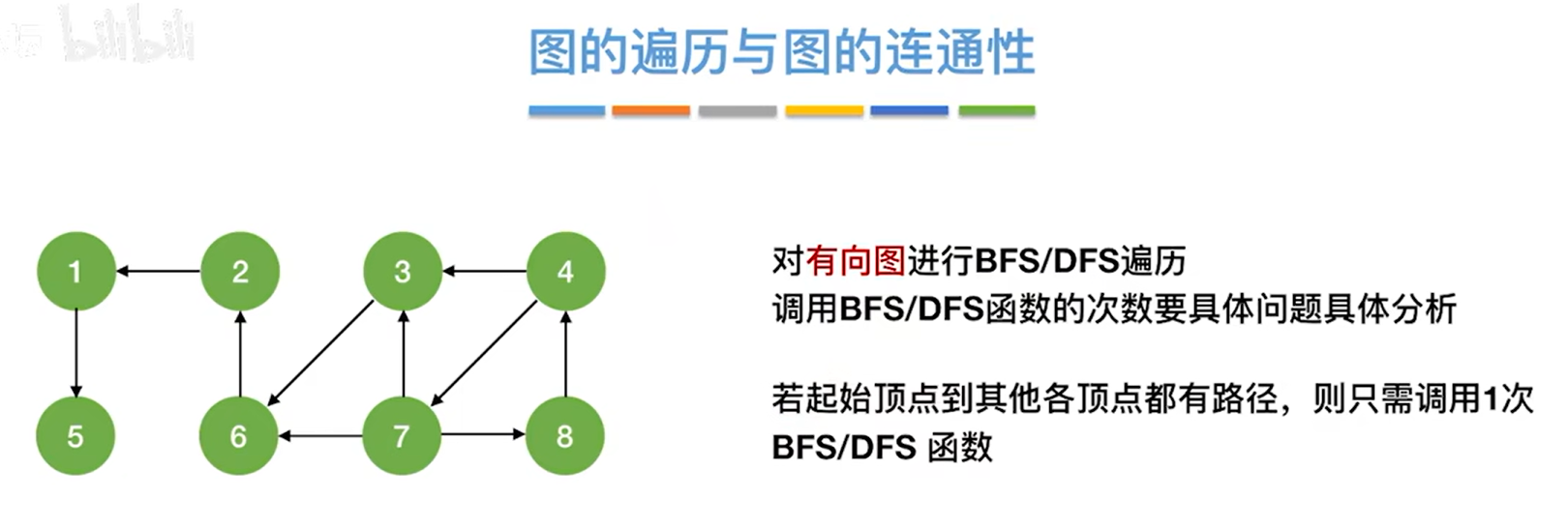
比如从7号顶点出发进行BFS或者DFS,只需要调用一次BFS函数或者DFS函数即可遍历完图,其中一条遍历序列为7、8、4、3、6、2、1、5;
比如从2号顶点出发进行BFS或者DFS,此时只能找到1、5号顶点(因为方向),所以无法调用一次BFS函数或者DFS函数就遍历完图。
特殊情况:有向图是强连通图(也就是从任何一个顶点开始都能找到到达其他所有顶点的路径)
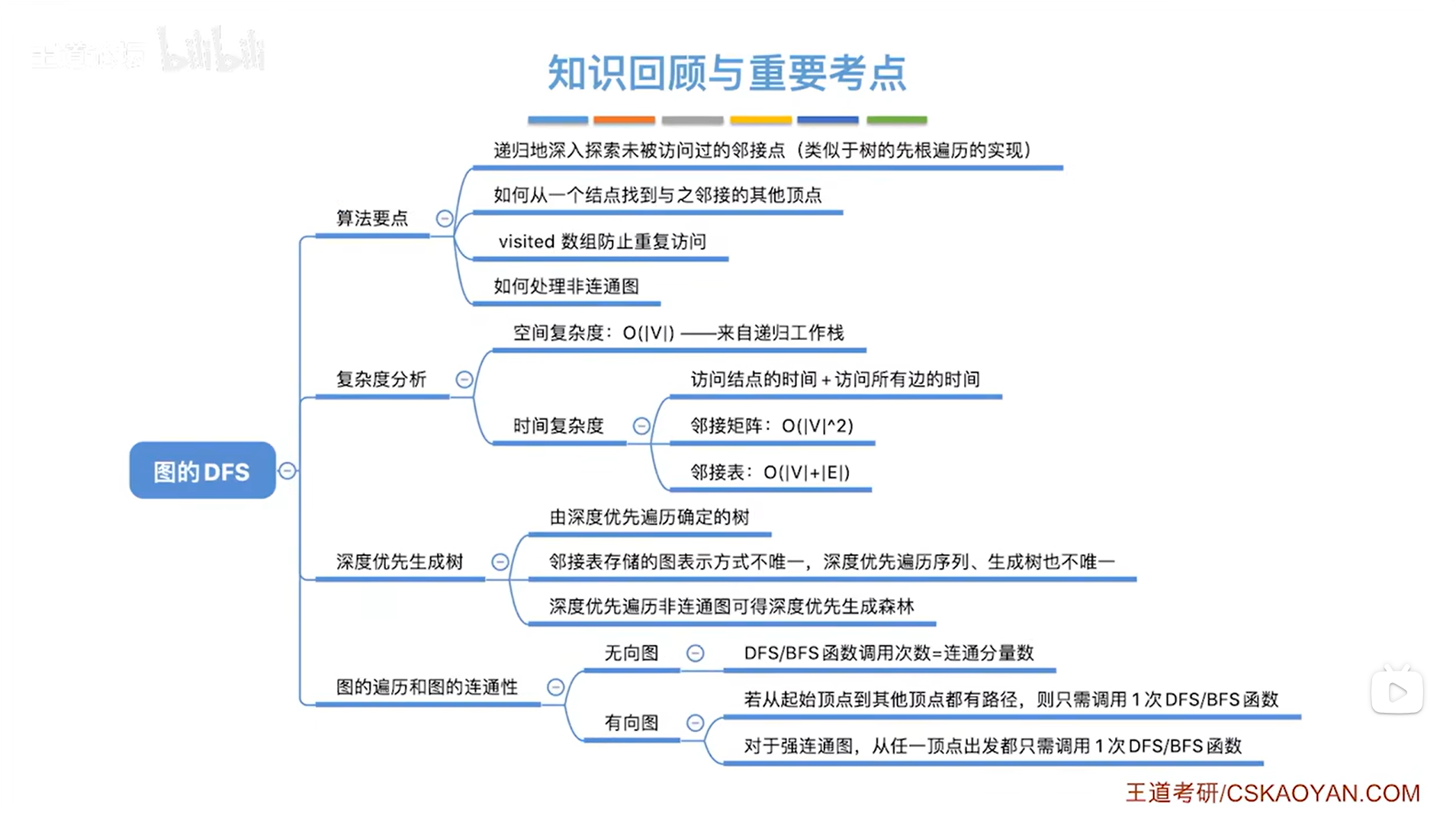
八.总结:
)


)
