

-
作者:Congcong Wen, Yisiyuan Huang, Hao Huang ,Yanjia Huang, Shuaihang Yuan, YuHao, HuiLin and Yi Fang
-
单位:纽约大学阿布扎比分校具身人工智能与机器人实验室,纽约大学阿布扎比分校人工智能与机器人中心,纽约大学坦登工程学院,中国科学技术大学,清华大学软件学院
-
论文标题:Zero-Shot Object Navigation with Vision-Language Models Reasoning
-
论文链接:https://link.springer.com/chapter/10.1007/978-3-031-78456-9_25
-
项目主页:https://vlt-lzson.github.io/
主要贡献
-
提出了 Vision Language 模型与 Tree-of-thought 网络相结合的 VLTNet,用于语言驱动的零样本目标导航(L-ZSON)任务,该模型能够使机器人在没有特定训练数据的情况下与未知物体交互。
-
创新性地将 Tree-of-Thought(ToT)推理框架应用于机器人探索过程中的导航前沿选择,使模型具备多路径推理过程和必要时的回溯能力,从而实现更准确的全局决策。
-
通过在 PASTURE 和 RoboTHOR 两个基准测试中的实验,证明了模型在处理复杂的自然语言指令作为目标指示的 L-ZSON 任务中的出色性能,特别是在涉及复杂自然语言指令的场景中。
研究背景
-
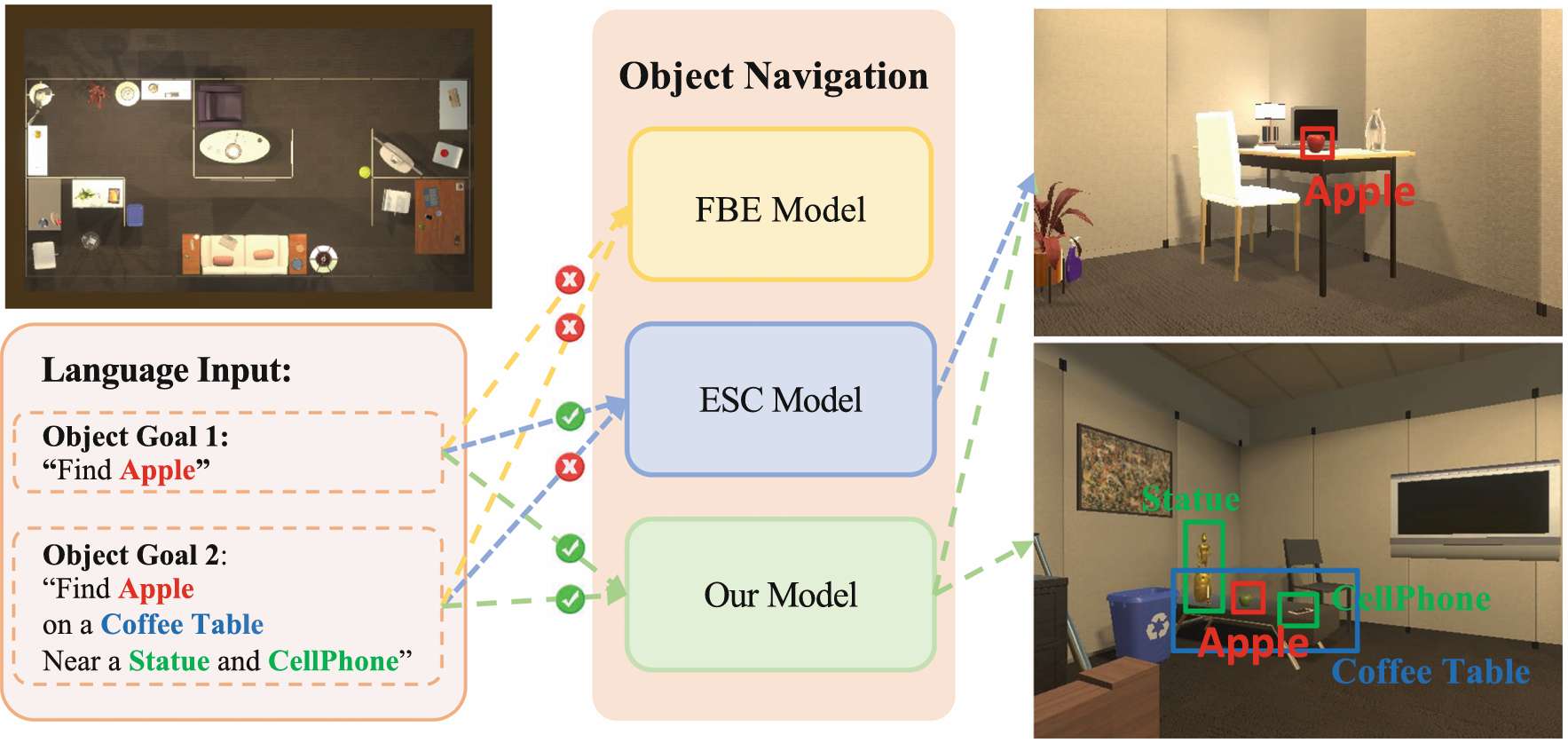
传统的机器人目标导航方法依赖于大量的视觉训练数据,包含环境中的标记物体,这限制了它们在未知和非结构化环境中的泛化能力。
-
零样本目标导航(ZSON)旨在解决这一问题,让机器人能够与未知物体进行导航和交互,但在需要复杂交互和通信的场景中仍存在不足。
-
语言驱动的零样本目标导航(L-ZSON)通过自然语言指令引导智能体,但现有方法只能处理明确包含物体类别的指令,难以处理描述未知物体或具有空间、视觉属性的物体的指令。
研究方法
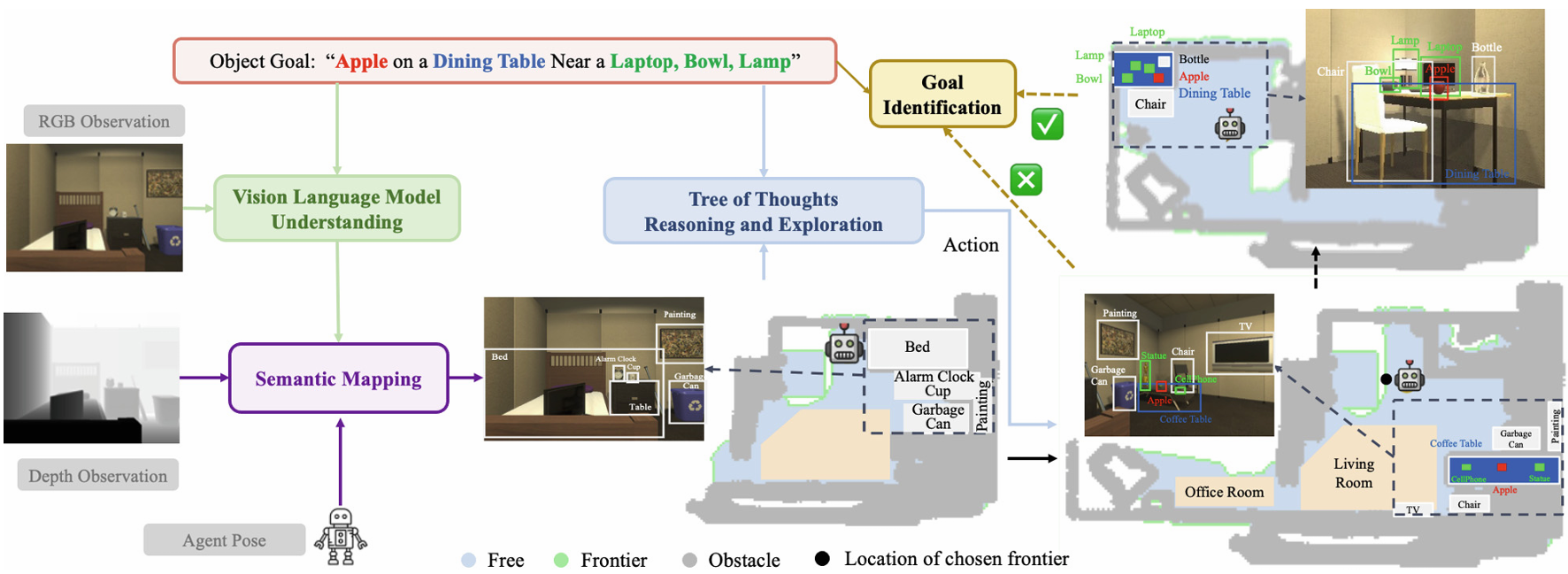
VLTNet 模型由四个核心模块组成,包括视觉语言模型理解模块、语义映射模块、树状思维推理与探索模块以及目标识别模块。
-
视觉语言模型理解模块 :利用预训练的视觉语言模型(如 GLIP)对观测到的 RGB 图像进行语义解析,识别图像中的物体和房间等信息,增强模型对环境语义的理解。
-
语义映射模块 :结合视觉语言模型理解模块生成的语义解析图像、智能体捕获的深度图像以及智能体姿态,构建包含物体、房间和前沿的语义导航地图,为智能体在复杂环境中的导航决策提供支持。
-
树状思维推理与探索模块 :是 VLTNet 的核心组件,创新性地将 ToT 推理框架应用于导航前沿选择。与传统方法不同,ToT 推理框架通过模拟多个专家对问题的讨论,逐步达成共识,使模型能够进行多路径推理和自我评估,从而选择最优的前沿进行探索,提高导航决策的准确性和全局性。
-
目标识别模块 :用于确定智能体当前接近的物体是否与指令中指定的目标物体匹配,不仅考虑物体类别,还结合空间和外观描述等复杂信息,通过视觉语言模型将当前场景转化为语言表达,再利用大型语言模型(如 GPT-3.5)进行分析,实现对场景上下文与目标描述之间一致性的准确评估。
实验
-
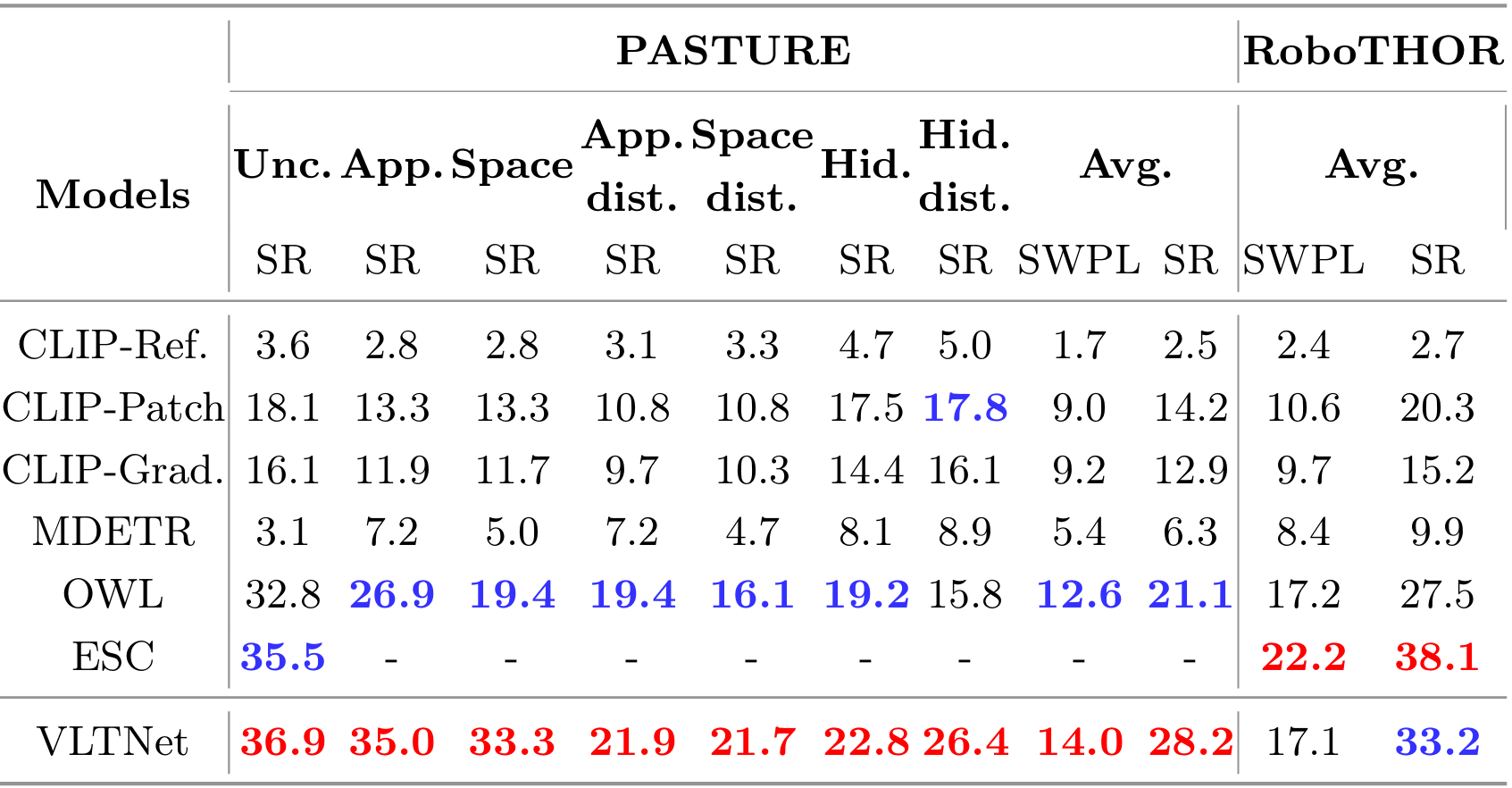
实验环境与数据集 :在 PASTURE 和 RoboTHOR 两个基准测试上评估 VLTNet 的性能。PASTURE 数据集包含多种独特的导航挑战,如不常见物体、外观复杂的物体等;RoboTHOR 则基于真实世界室内环境,提供精确的 3D 环境表示。
-
评估指标 :采用成功率(SR)和路径长度加权成功率(SWPL)作为评估指标,SR 衡量智能体在最大步数内成功导航到目标物体的比例,SWPL 则同时考虑导航的成功性和路径的最优性。
-
基线模型 :与多个最先进的模型进行对比,包括 CoW 及其变体(如 CLIPRef、CLIP-Patch 等)、ESC 等。
-
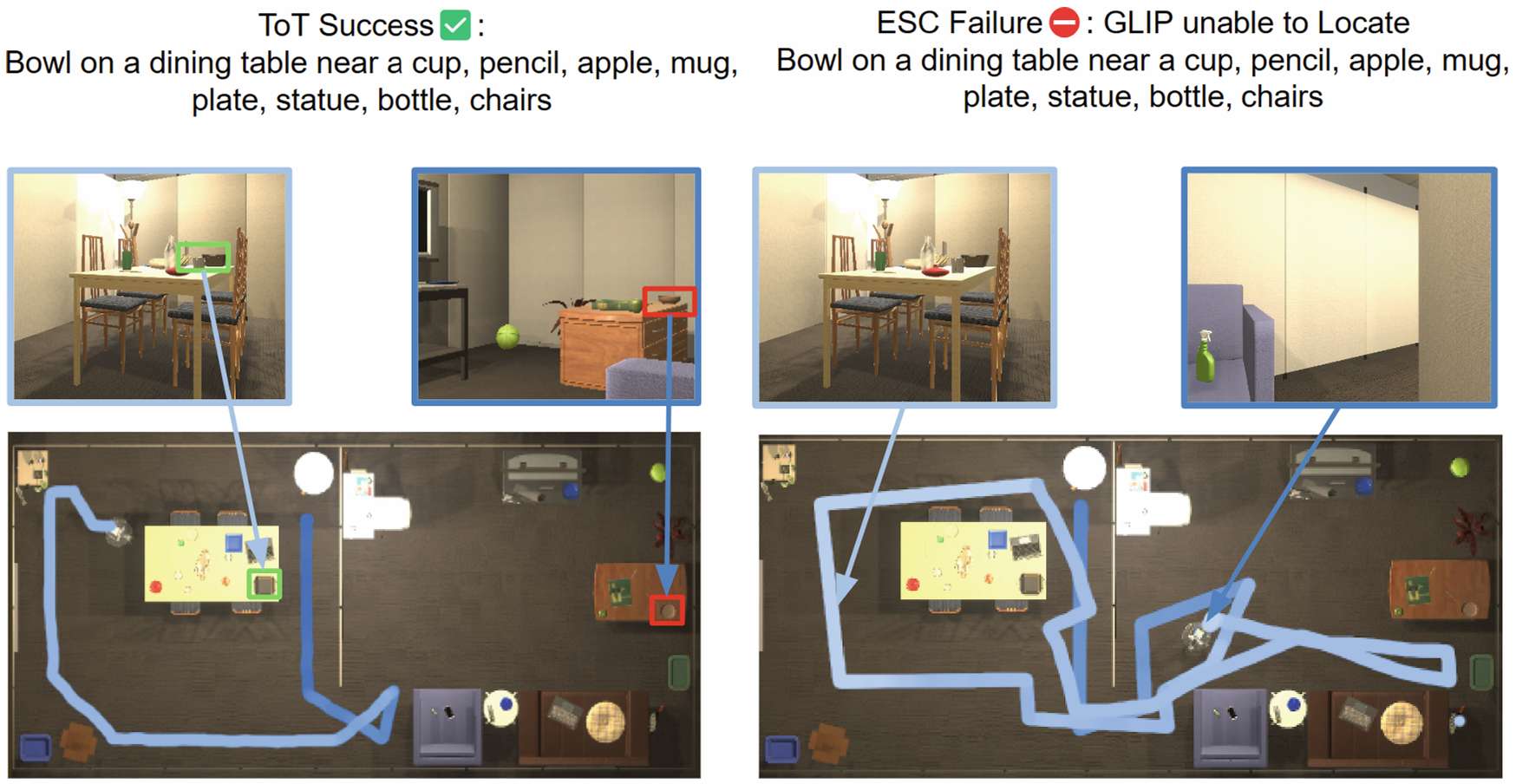
实验结果 :在 PASTURE 数据集上,VLTNet 模型在所有指标上均优于其他模型,在外观类别中的成功率达到 35.0%,在空间类别中的成功率为 33.3%;在 RoboTHOR 数据集上,VLTNet 的成功率为 33.2%,SWPL 为 17.1%,优于 CoW 等模型。此外,消融实验表明,使用 ToT 提示的模型在前沿选择上优于没有 ToT 提示的模型,证明了 ToT 推理的有效性;在目标识别模块中,使用 GPT-3.5 的模型在验证目标对象与空间提示的一致性方面表现最佳。
讨论与未来工作
-
论文指出,尽管 VLTNet 在 L-ZSON 任务中取得了显著的性能提升,但仍存在一些局限性,例如在处理某些复杂的自然语言指令时可能还需要进一步优化模型的推理过程和语义理解能力。
-
未来的工作可以探索如何进一步改进 ToT 推理框架,以更好地处理复杂的导航场景和更丰富的语言指令。
-
此外,还可以研究如何将 VLTNet 与其他技术(如强化学习、模拟真实世界环境的高保真仿真等)相结合,以进一步提高机器人的导航性能和泛化能力,使其能够在更接近真实世界的环境中更有效地执行任务。




)

