目录
前言:
数据结构补充
stream
geospaital
Hyperloglog
bitmap
bitfield
渐进式遍历命令等
认识Redis客户端及协议
前言:
在前文,我们总览一下,我们已经介绍了什么是Redis,Redis的应用场景是什么,以及我们是从分布式系统引出了Redis,并且引入了负载均衡的概念,以及微服务的概念,具体是什么,各位同学可以移步到对应的Redis的第一篇文章。
那么从上文,我们知道了Redis可以使用在缓存,也可以使用为数据库,也可以使用为消息队列使用,不过Redis现在似乎不是很适合当作消息队列来用,虽然说list可以吧,一会儿我们介绍的stream也可以,但是还有更可以的,所以消息队列方面的话,Redis可能差了一点点意思。
我们在前面的几篇文章,介绍了常见的,常用的五种数据类型,分别是string,list,hash,set,zset,其中较为复杂的是zset,不过其实也还好。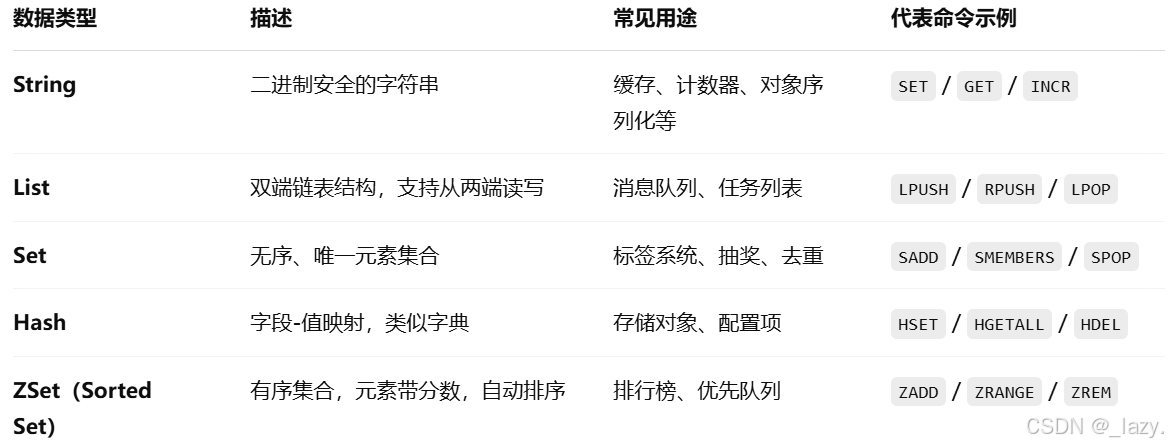

那么,我们现在就来简单介绍一下补充的这几种数据类型,因为不常见,或者说在特定的应用场景才会使用,就简短的过了就行。
进入正题。
数据结构补充
stream
Redis 的 Stream(流)类型是一个 高性能的消息队列结构,用于存储一系列按时间顺序排列的消息项。它结合了传统消息队列(如 Kafka)和 Redis 自身高效的数据结构,既能做数据持久化,又能支持高并发消费。
| 特性 | 描述 |
|---|---|
| 持久化存储 | 不同于 Pub/Sub,消息是可以持久保存的 |
| 消费者组支持 | 多个消费者可协同消费,支持消息确认和追踪 |
| 高吞吐、低延迟 | 写入和读取性能极佳 |
| 轻量级 Kafka 替代 | 对中小项目非常友好 |
可以说stream是一个加强版本的list的blpop和brpop版本。
| 命令 | 说明 |
|---|---|
XADD | 添加一条消息到流中 |
XRANGE / XREVRANGE | 正序/逆序读取消息 |
XREAD | 拉取新消息 |
XGROUP CREATE | 创建消费者组 |
XREADGROUP | 消费者组方式读取消息 |
XACK | 确认消费消息 |
geospaital
我们可以上百度翻译查阅一下对应的意思,它的意思是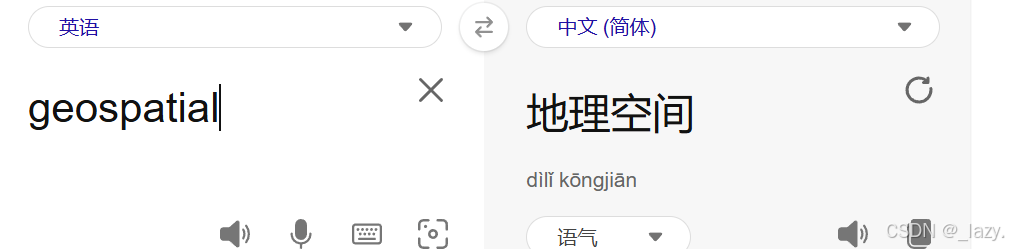
所以它是一个和地理位置有关的类型了,那么对于地理位置来说重要的是经纬度吧?所以它存储的内容是坐标。
Redis 的 Geospatial 类型 是在底层使用 Sorted Set(有序集合zset) 实现的扩展功能,允许你存储地理位置坐标(经纬度)并对其进行 范围查询、距离计算、排序等地理空间操作。
| 命令 | 说明 |
|---|---|
GEOADD | 添加地理位置(经度、纬度、名称) |
GEODIST | 计算两个地点之间的距离 |
GEORADIUS(已弃用,推荐用 GEOSEARCH) | 查询某点周围的位置 |
GEOSEARCH | 更灵活的地理范围搜索(圆形或矩形) |
GEOPOS | 获取一个或多个元素的经纬度 |
GEOHASH | 获取元素的 Geohash 编码值(用于地图服务) |
其实从定义也可以看到,它本质上还是zset,不过是多封装了一层而已。实际应用场景我们一打开地图,里面提供的地理信息就可以使用geospatial来完成。
Hyperloglog
我们前文提到了可以使用set来完成对某种数据的统计,比如某个游戏的用户的数据,我们需要用一个大榜来显示,那么我们假设这个数据是由一个longlong和int构成的,假设用户由一亿,那么就是12亿字节,对于12亿字节来说,也就1.2G左右的内存,这个内存看起来即便是对于我们日常的家用电脑也是完成能够承受的,但是实际上可能不止这么多数据。
而且,如果告诉你有一个数据结构可以用最多12KB的空间存放你想要的信息,你会如何选择呢?相信大多数同学选择的都是这个12KB的数据结构,这个数据结构就是Hyperloglog,但是它也有一定的缺点,比如它能够给你存放,但是怎么存放的你别管了。
HyperLogLog 是 Redis 中用于 基数(不重复元素数量)估算 的特殊数据结构,它可以在 极小的内存占用下(约12 KB),快速统计 大量数据中的唯一元素数量。
其核心价值是:“以极低成本估算去重后的数量”,而不是保存或返回这些唯一元素本身。
所以更多的是计数,并且没有办法通过特征值返回原来的元素。
不过根据官方文档的介绍,这个误差值也只有0.81,也是完全可以接受的了。

当然你要是问怎么操作的,那就涉及到了对应的源码了,咱们后面再看咯。
bitmap
首先看到这名字咱们也应该知道怎么回事了,位图嘛,我们在C++阶段学习过位图,对于位图来说,它的优势就是可以用位来表示数据是否存在,这样就比单独用一个变量表示标志位强多了,这是非常节省空间的。
Bitmap 并不是 Redis 独立的数据类型,而是 Redis 基于 String 类型的位操作能力 实现的功能。它可以通过操作字符串的二进制位,实现 高效的布尔状态记录和统计。
每个位(bit)可以表示一个对象的某种状态(如是否登录、是否签到),非常适合进行空间优化和大规模状态存储。
| 特性 | 描述 |
|---|---|
| 空间高效 | 每个状态只占用 1 位,1 字节可记录 8 个状态 |
| 支持位操作 | AND / OR / XOR / NOT 等逻辑运算 |
| 适用于布尔标记场景 | 例如签到、活跃、已读等状态记录 |
| 命令 | 说明 |
|---|---|
SETBIT key offset value | 设置指定偏移位(bit)的值(0/1) |
GETBIT key offset | 获取指定偏移位的值 |
BITCOUNT key | 统计所有为 1 的位数量 |
BITOP operation destkey key1 [key2 ...] | 对多个 bitmap 进行位运算 |
当然了,具体怎么实现的还是根据源码了,我们后面再学习咯~
bitfield
这个东西大家可能看起来是非常陌生的,对于bitfield来说,咱们翻译一下,bitfield的意思就是位域,欸是不是有点熟悉了?换个名字:位段
是不是换成位段就非常熟悉了?这不就是我们在C语言阶段通过结构体学习的位段吗?
Redis 的 BITFIELD 命令是对 Bitmap 类型的一个高级扩展,它不仅可以对指定的位进行读写,还允许进行 整数类型的批量操作。通过 BITFIELD,用户可以高效地执行多位数据操作(如整数计数器、嵌入式计数器等),适合一些需要操作大规模二进制数据的应用场景。
BITFIELD 主要用于位图的分段操作,可以进行整数值的增减、查询和位操作,甚至支持直接对多个不同类型的字段进行批量操作。
| 特性 | 描述 |
|---|---|
| 位操作扩展 | 不仅限于布尔值,还可以操作各种整数类型(8 位、16 位、32 位等) |
| 高效批量操作 | 一次命令内支持多个字段操作,减少了多个命令的传输开销 |
| 对 Bitmap 扩展 | 允许更复杂的运算,如按位增减、批量读取等 |
| 命令 | 说明 |
|---|---|
BITFIELD key GET type offset | 获取指定位置的整数值(支持类型如 i8, i16, u32 等) |
BITFIELD key SET type offset value | 设置指定位置的整数值 |
BITFIELD key INCRBY type offset increment | 增加指定位置的整数值 |
BITFIELD key AND type offset value | 按位与操作 |
BITFIELD key OR type offset value | 按位或操作 |
它的主要操作就是位操作了,具体怎么操作的我们还是看源码去咯~
注意了,以上的数据结构咱们了解一下就可以了,你要说真正用到的时候呢,咱们再去查官方文档也行~~~
渐进式遍历命令等
我们通过名字就可以知道,渐进式遍历的核心就是渐进式,即一部分一部分的遍历呗,那么为什么要渐进式遍历呢?
因为如果Redis中的数据库的键值对太多了的话,直接遍历完大概率是会阻塞住其他的命令的,这个时候的后果就不用我多说了吧。所以我们需要一个命令单独来慢慢的遍历数据库中的键值对。
| 命令 | 作用 | 可遍历的数据结构 |
|---|---|---|
SCAN | 遍历数据库中的键 | 所有 key |
SSCAN | 遍历集合中的元素 | Set |
HSCAN | 遍历哈希表中的字段和值 | Hash |
ZSCAN | 遍历有序集合中的成员及分值 | Sorted Set |
XREAD / XREADGROUP | 渐进式读取 Stream 消息 | Stream(使用游标 ID) |
渐进式遍历的命令有这么多,但是我们拿一个出来介绍就可以了,即scan命令,对于其他命令来说我们看看文档也是能够理解,更重要的是scan是能够遍历所有的数据结构的。
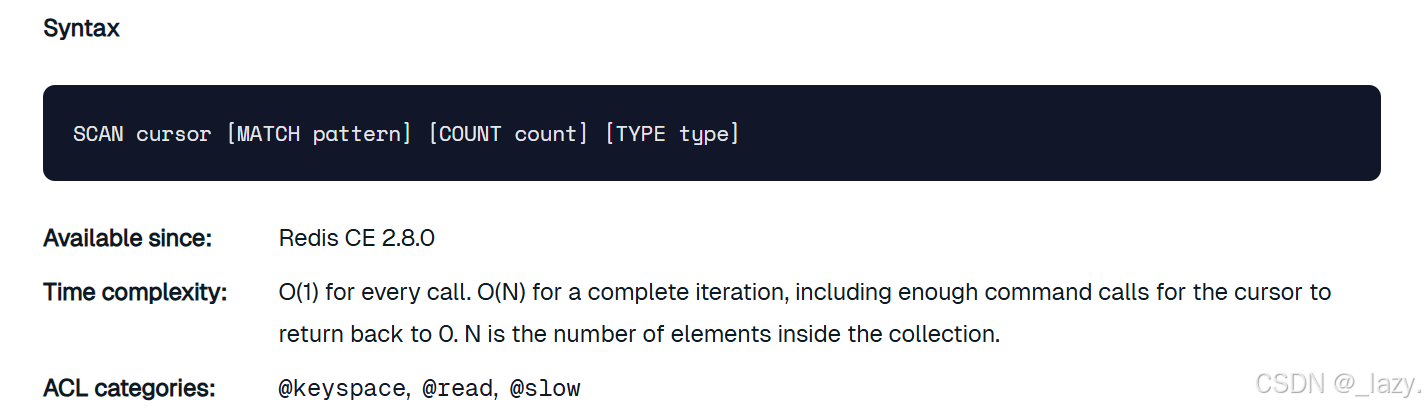
这是scan在官方文档中的介绍,第一个是游标位置,咱们可不要轻易的把这个位置认定为是下标位置,因为它根本就不是,咱们一会儿看就知道了。然后是匹配规则,对于匹配规则来说分为:
| 模式 | 说明 |
|---|---|
* | 任意多个字符 |
? | 单个字符 |
[abc] | 匹配 abc 中的任意一个字符 |
[a-z] | 匹配范围内字符 |
[^e] | 匹配非 e 的单个字符 ✅ |
\* | 匹配字面上的 * |
这个点我们其实在keys *那里是学习过了的,这里的scan是一样的。
然后是Count count,这里的意思是代表你要遍历多少个元素,但是你以为你给多少它就会给你多少个吗?并不是,这里的count只是一个建议,至于这个建议它是否接受呢,只能说接受一半,即它遍历的数据个数是在count左右的,但是会不会是count,那就不好说了。
这里的type是指定遍历哪种类型的元素,因为一个数据库里面有很多个元素,多种类型的,那么有的时候我们想要特定的元素,我们就可以通过这个选项来指定。
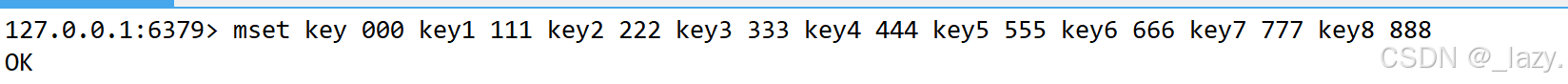

第一个返回的值代表的是下一次遍历开始位置,这里的位置不是下标哦,然后count我们指定一下遍历多少个元素即可。
如果scan返回的是0,那么才代表遍历结束了。不过我们在使用scan的时候要注意了,scan虽然解决了阻塞一类的问题,但是是非常不推荐在遍历的时候修改键值对的,即便它的遍历是可中断的,不对服务器保留状态产生影响的。
然后刚才我们提到了,Redis的数据库中的key有多种类型的,那么,这个数据库,是否有多个呢?是否能够像MySQL中一样,创建数据库,删除数据库呢?
不幸的是,Redis中没有这么丝滑的操作,它里面的数据库是固定了的,一共就只有16个,我们可以通过命令进行切换:
| 命令 | 说明 | 示例 |
|---|---|---|
SELECT index | 切换当前连接到指定数据库(0 ~ 15) | SELECT 1 |
FLUSHDB | 清空当前数据库中的所有键 | FLUSHDB |
FLUSHALL | 清空所有数据库(慎用) | FLUSHALL |
DBSIZE | 获取当前数据库中 key 的数量 | DBSIZE |
MOVE key db | 将指定 key 移动到另一个数据库(前提是目标 DB 不存在同名 key) | MOVE mykey 2 |
KEYS pattern | 获取匹配 pattern 的所有 key(慎用,生产环境不推荐) | KEYS user:* |
SCAN cursor | 安全遍历当前数据库所有 key(推荐) | SCAN 0 |
所以同学们看到第三行的时候,是不是有点毛骨悚然了呢?我们使用的居然是清除所有数据库的操作。

更换数据库的时候我们也可以发现命令行终端也是发生了一定的改变的。其他命令同学们下来自行尝试吧,确实挺简单的,我们平常默认使用0号数据库就可以了。
认识Redis客户端及协议
不知道刚点进来的同学是否会有一定的疑问:啊?Redis的客户端不是我们一直使用的命令行吗?难道说这货还有其他的客户端?
是的,我们更多的时候,其实是通过调用Redis的API来实现定制化的客户端的。这里咱们需要对定制化的客户端有个简单的理解,像王者荣耀,我们是很难出一个它的定制化的客户端的,因为什么,因为在应用层我们没有办法通过协议来和王者荣耀的服务器进行通信。
在之前学习http协议的时候,我们已经了解了对于自定义协议的一些内容,我们非常清楚,客户端想要和服务器进行通信是基于协议的,如果协议没有公开化,那么服务器给的数据包客户端是没有办法解析的,同理,客户端也不知道如何按照协议进行一系列的操作。
那么,我们定制化客户端的话,就明显需要知道对应的协议,那么如果Redis不公开对应的协议的话,咱们也就只能只用命令行进行操作了,好在Redis公开了自己的协议:RESP。
它的协议叫做RESP,有人一看,欸,这货不是response的缩写吗,其实不是,就和之前的有序一样,相同的名字有着不同的意思,对吧。
RESP(Redis Serialization Protocol) 是 Redis 定义的应用层协议,用于客户端与服务端之间命令的序列化和响应的解析。它是状态无关的、基于文本的协议,既具有良好的可读性,也便于高性能实现,尤其适用于 Redis 典型的高并发、短连接场景。
我们在第一次涉及到协议的时候,非常粗鄙的认为了协议相当于是共同的数据类型,那么在RESP中涉及的数据表示为:
| 类型 | 前缀 | 描述 |
|---|---|---|
| 简单字符串(Simple String) | + | 一般表示状态信息,例如 +OK |
| 错误(Error) | - | 错误信息,例如 -ERR wrong type |
| 整数(Integer) | : | 数字,例如 :1000 |
| 批量字符串(Bulk String) | $ | 带长度的字符串,如 $6\r\nfoobar |
| 数组(Array) | * | 表示命令由多个部分组成,如 *2\r\n$3\r\nGET\r\n$3\r\nkey\r\n |
比如发送一个GET mykey,通过RESP编码进行转化之后,实际发送的是:
*2\r\n$3\r\nGET\r\n$5\r\nmykey\r\n
-
RESP 2 是目前 Redis 的默认协议(适用于 Redis 2.6 ~ Redis 6)。
-
从 Redis 6 开始支持 RESP3,提供了更多原生类型(如 Map、Set、属性字段等),更适合新型客户端。
-
客户端可以通过
HELLO 3命令切换协议版本。
那么既然我们知道了对应的协议,我们是否就要手动开始进行协议的序列化等内容呢?当然不用,对应的API接口已经有大佬帮我们写好了,我们直接使用即可。
那么就是需要配置对应的Rdis环境了。
那么如何配置环境,我们下文再细说~~
以上就是对类型的简单补充,以及简单的了解了一下渐进式遍历和管理数据库的命令,最后用RESP协议进行了一个收场。
感谢阅读!





