Fine-grained Dynamic Network for Generic Event Boundary Detection
提出原因
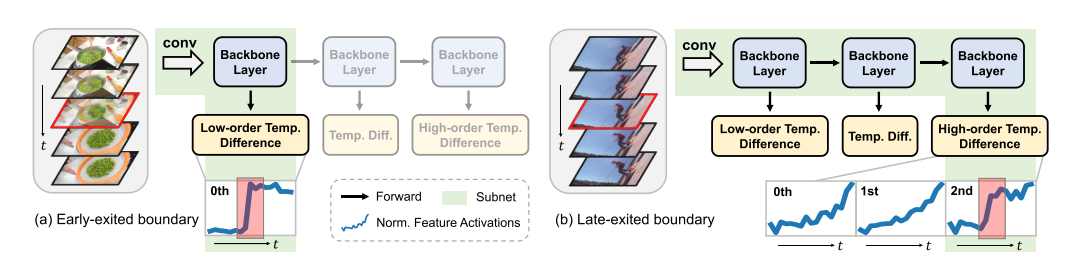
如下图所示, 通用事件边界是无分类的,包含各种低级和高级语义边界,例如有仅仅通过镜头外观更改的低级边界(检测较为容易,图a),也有具有丰富语义信息,需要深层网络建模才能检测出来的高级边界(图b)。
但以往的方法往往都是提出一个网络架构,对所有的边界信息进行相同的建模,使得计算低级边界时成本也大,并且有可能因为本就能够简单分辨的特征被提取的过于复杂从而导致性能下降,因此本文提出了一种多出口网络,通过自动学习子网分配,允许对各种边界进行自适应推理。对应于低层语义信息的边界,例如镜头变化,仅通过具有浅层的子网来捕获外观信息和简单的时间依赖性。而需要高级语义进行边界识别的边界将遍历整个网络进行深入的时空建模。通过以细粒度的方式推断不同的输入,通用事件边界的处理可以被专门化以增强整个检测系统的性能和效率。
这样做的好处是:考虑到骨干网络f的计算成本明显大于检测器h的计算成本(超过FLOP的10倍),允许更多帧提前退出所获得的效率远远超过了难以检测的样本遍历所有检测器所造成的额外负担。
贡献点
设计了一个网络架构即DyBDet,主要由两个关键设计组成:
1.多出口网络,用于在视频片段级别进行自适应推理;(可以在不需要人工干预的情况下,自动地为视频中的不同片段(即不同时间段或事件)分配适当的子网络(subnet),以便对这些片段中的边界进行更加精确和细致的检测。)
2.多阶差分检测器,通过捕获最具特色的运动模式进行边界检测来实现动态性。(替换了原来简单的帧差检测器)
框架
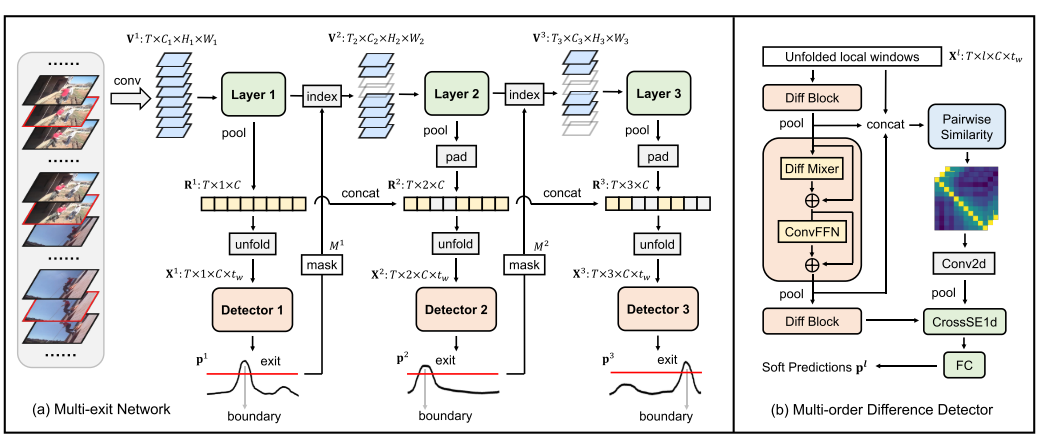
给定一个T帧的视频序列,我们的目标是自适应地分配不同类型的事件边界的时间间隔。DyBDet主要由两个关键设计组成:多出口网络,用于在视频片段级别进行自适应推理;多阶差分检测器,通过捕获最具特色的运动模式进行边界检测来实现动态性。为了实现自适应推理,我们设计了一个具有L个不同阶数检测器的动态网络(第一层网络用一阶检测器,第二层用二阶…),其中这些中间检测器连接在图像主干的不同深度处(如上图的左平面所示)。
具体如下:
首先从原始视频中采样T帧,并将其发送到图像主干(默认情况下为ResNet50)。来自不同层的空间特征[V1,…,VL]在自适应推理期间被迭代地提取,作为不同语义级别的表示。对于每个尺度,然后对每个帧执行空间池化以节省计算并获得1d时间特征。收集来自先前尺度的所有时间特征并将其连接到当前尺度l以获得富集特征Rl ∈ RT×l×C。
以第一层为例:视频序列经过第一层网络卷积得到Tx1xC,然后需要为每个候选帧k设定框大小来计算帧差(文章里给的是2k+1),从而得到每一帧的帧差(概率)。选出边界后遵循部分退出原则(具体来说,由于事件边界的局部性,我们只允许检测到的点周围的特征退出,并生成一个掩码Ml ∈ {0,1}T,指示在每个时间戳是丢弃还是保留特征),进入下一子网络。
整体公式:
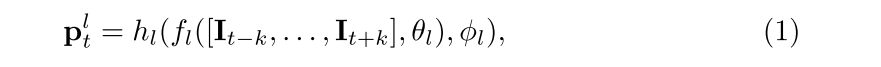
其中I是视频片段(帧数),θl是共享参数,ϕl是每个子网络的非共享参数,fl是主干网的子网,plt是逐帧分数。
边界选择公式:
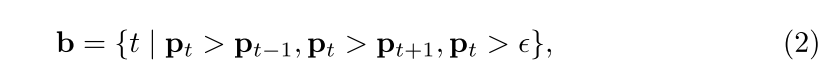
用的峰值检测,是峰值且边界概率大于0.5的被选为边界帧。
部分退出原则:
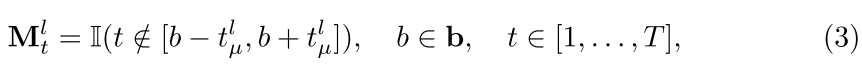
其中其中t1 μ确定检测到的边界B周围的退出特征的量。然后,我们使用掩码Ml来索引骨干特征的哪些部分被保留。我们用附近帧特征的重复填充退出位置以保留局部信息,并且序列在被发送到相应检测器之前被填充回初始长度T。此外,在填充帧特征内检测到的边界也是不期望的,并且将不被记录。
多阶差分检测器
通用事件边界类型跨越简单的镜头更改到复杂的子动作更改。除了整体的动态架构,我们进一步提出了多阶差分检测器,利用从粗到精的骨干特征,并确保这些不同的边界可以检测到专门的策略。检测器应该在各种边界之间探索不同的表示,并区分它们,以确保动态的有效性。基于多阶时间差的检测器通过对局部变化进行建模来捕获并放大用于边界识别的最显著的运动模式。从图2的右平面看,检测器由用于边界识别和定位的多阶差分编码器(MDE)和成对对比度模块(PCM)组成。
MDE:
提出了一种类似于transformer的架构来捕获多阶时间依赖,该架构由n个块组成,其中有池化层。用DW卷积在时间轴(帧与帧之间)上卷积,得到帧间特征,具体方法如下图,以前的DW卷积是在HxWxC上操作,视频里把HxW压成了一通道,所以视频里的通道实际上是Tx(HxW)x C,
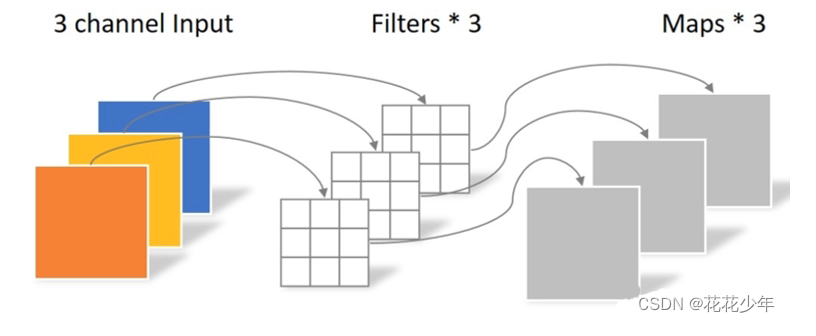
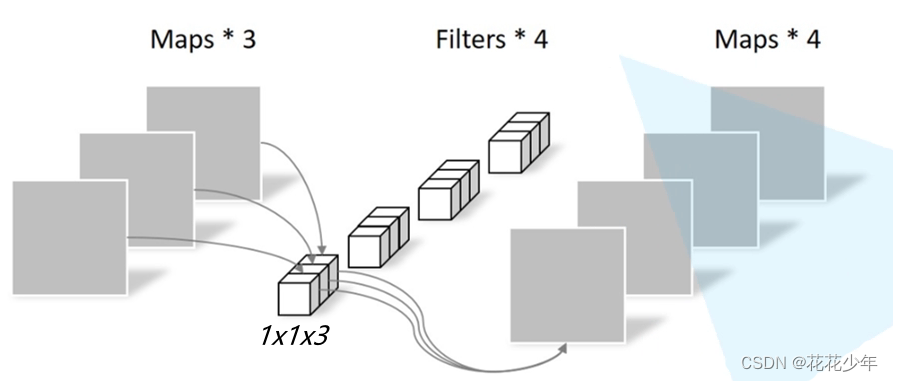
MDE里最关键的就是差分混合器(Diff Mixer)
Diff Mixer 的工作原理:
输入特征序列:Diff Mixer 接收来自骨干网络的特征序列,该特征序列包含了视频片段的时空信息。
DWConv 计算:Diff Mixer 使用多个 DWConv 对特征序列进行卷积操作,每个 DWConv 对应一个特定的时间差分阶次。
激活函数:每个 DWConv 的输出经过激活函数进行非线性变换。
特征融合:将所有 DWConv 的输出进行融合,得到最终的多阶时间差分特征。
我们还将vanilla FFN替换为ConvFFN以提高鲁棒性,我们选择步幅为1的最大池化作为块之间的连接(这里的最大池化:Difference Mixer 可以计算一阶、二阶甚至更高阶的时间差分特征。每增加一阶时间差分,特征图的通道数就会增加一倍。Pool 操作通常在特征图的最后一个维度上进行,即通道维度。Pool 操作可以将特征图的通道数减少,并提取更抽象的特征。)
PCM:
我们计算帧级成对相似度如下:
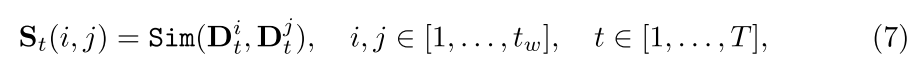
然后将所获得的相似性图发送到由几层卷积组成的轻量化编码器中以进行特征细化。最后,我们通过交叉SE(挤压和激励)模块融合所提出的检测器中两个分支的输出,以重新加权和平衡特征。融合的特征通过基于MLP的分类器来生成最终的预测。
交叉SE模块如下:

本质上就是一个给权重,一个给原特征图,实际上就是一个通道注意力。
)





