
小林:https://www.xiaolincoding.com/redis/
官网:https://redis.io/
Redis 是内存数据库。典型使用场景:登录状态 Session 管理,商品详情缓存,秒杀库存控制,排行榜,延迟任务
它也为数据的持久化提供了两个技术—— 「 AOF 日志和 RDB 快照 」
- AOF 文件的内容是操作命令;
- RDB 文件的内容是二进制数据。
文章目录
- 配置
- 1. 数据类型与结构
- 数据类型
- 数据结构
- SDS
- 链表
- 压缩列表 ziplist
- 哈希表
- 整数集合 Set
- 跳表 —— Zset底层
- quicklist
- listpack
- 2. 持久化
- AOF 持久化
- redis 写回逻辑
- 三种写回策略
- AOF 重写机制
- RDB 快照
- 混合持久化
- 3. 过期策略
- 键过期
- 过期删除策略:
- 内存淘汰策略:
- 4. 缓存三剑客
- Redis 故障宕机导致雪崩的解决方案
- 5. 数据库和缓存 保证一致性
- Cache Aside 旁路缓存策略
- 延迟双删
配置
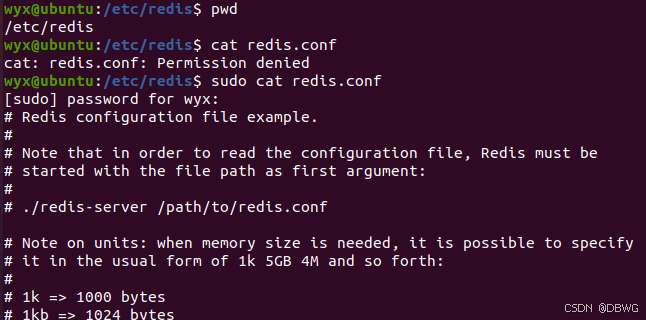
这里可以配置对外 ip,外界才能连接:
bind 0.0.0.0 ::1
1. 数据类型与结构
数据类型
数据结构
key-value 键值对数据库
key 为字符串,value 是字符串或其他数据结构如链表,set
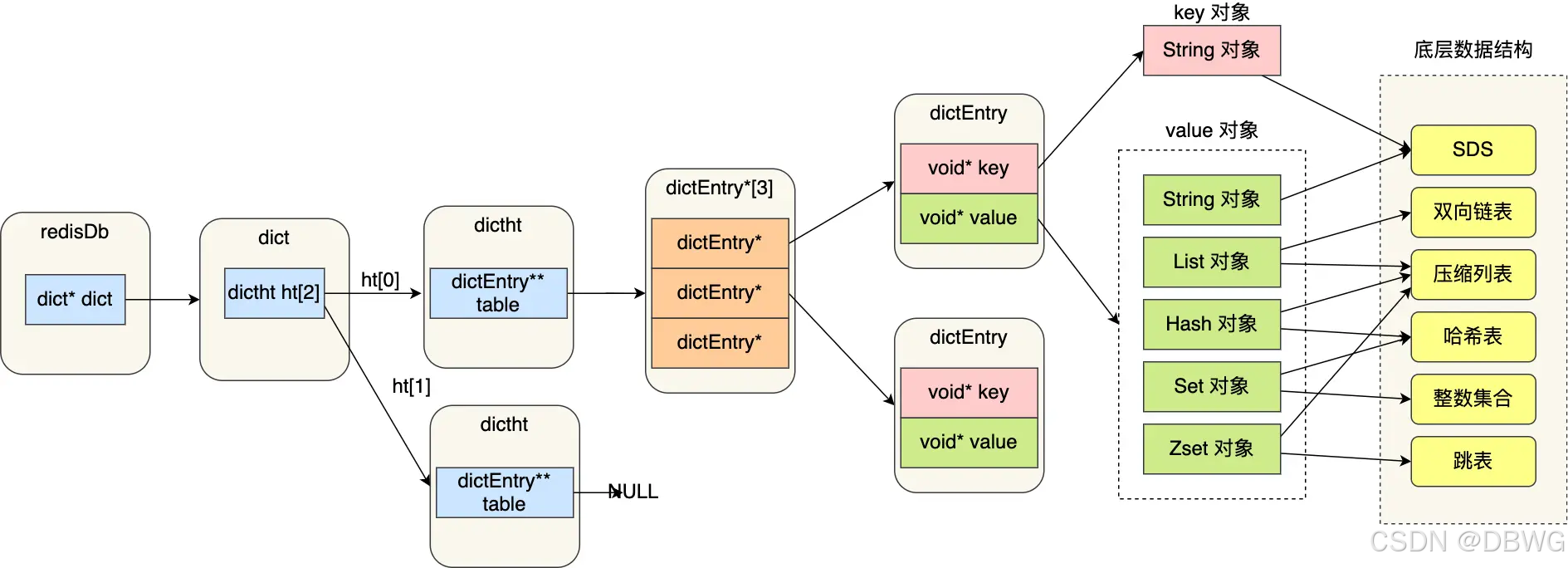
所有 kv 的指针 通过哈希表保存。
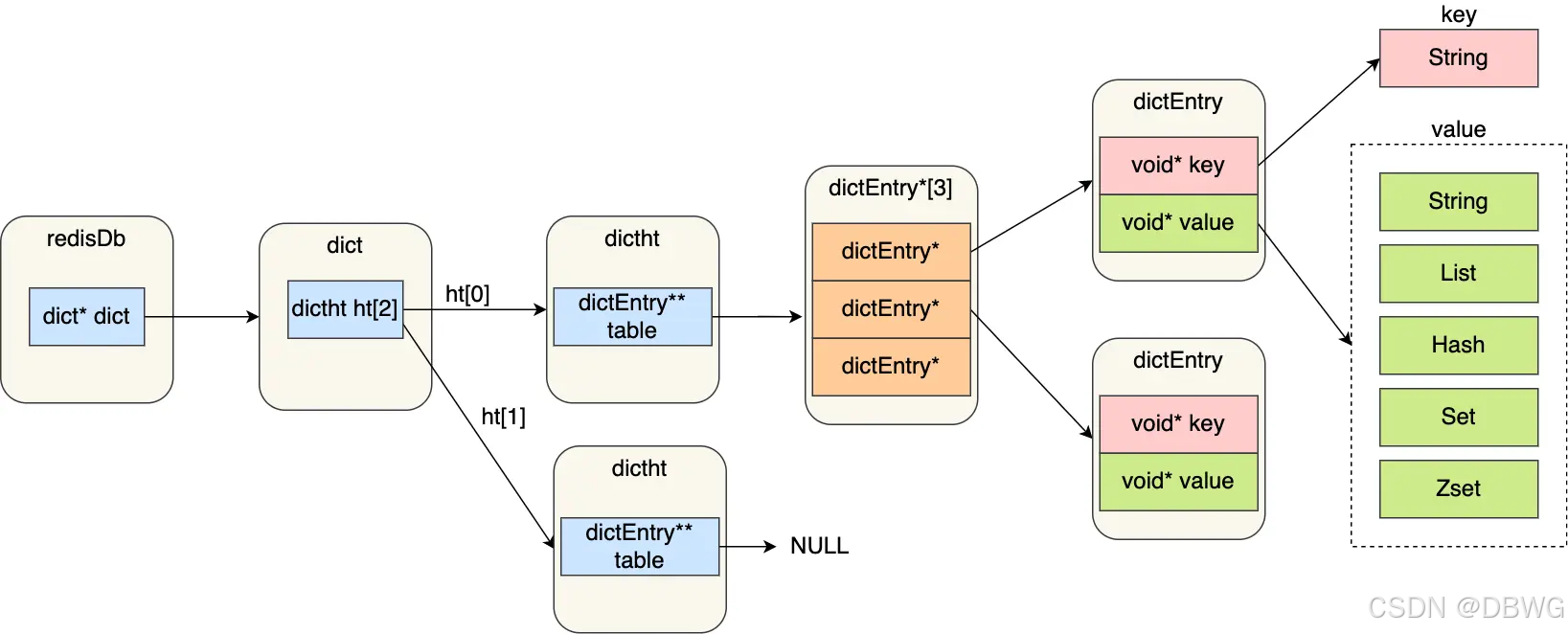
dict 结构就是哈希表,可以有多个库。
dict ht (dictionary hash table字典哈希表)(哈希表对象除了哈希表,还要维护哈希表大小。以及其中有实现的方法)
entry 条目。
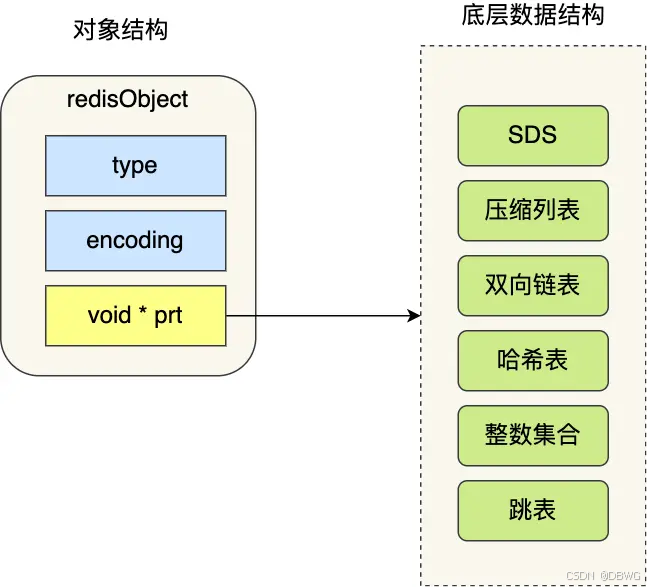
key 和 value 往往是 redis 对象,里面有类型和各种结构如链表。
SDS
simple dynamic string 简单动态字符串
Redis 用的是 C 语言,C 没有标准的可变字符串类型,自己实现字符串(SDS)更适合 Redis 的性能、内存管理和二进制安全需求。

flags类型(为了能灵活保存不同大小的字符串,从而有效节省内存空间):
sdshdr5
sdshdr8
sdshdr16
sdshdr32
sdshdr64
表示 SDS 类型,len 和 alloc 的类型不同。🤯
struct __attribute__ ((__packed__)) sdshdr16 {uint16_t len;uint16_t alloc; //2^ 16unsigned char flags;char buf[];
};struct __attribute__ ((__packed__)) sdshdr32 {uint32_t len;uint32_t alloc; //2^ 32unsigned char flags;char buf[];
};
扩容策略:
如果所需的 sds ⻓度⼩于 1 MB,扩容是按照翻倍执⾏,即 2 倍的newlen
如果所需的 sds ⻓度超过 1 MB,扩容是 newlen + 1MB。
链表
在 Redis 3.0 版本中 List 对象的底层数据结构由「双向链表」或「压缩表列表」实现;
在 3.2 版本之后,List 数据类型底层数据结构是由 quicklist 实现的
在最新的 Redis 代码中,压缩列表数据结构已经废弃,交由 listpack 数据结构来实现了。
压缩列表 ziplist
⼀种内存紧凑型的数据结构,占⽤⼀块连续的内存空间,不仅可以利⽤ CPU 缓存,⽽且会针对不同⻓度的数据进⾏相应编码,可以有效地节省内存开销。
entry条目 是不定长。

zlbytes: 整个压缩列表占用对内存字节数;
zltail: 记录压缩列表「尾部」节点距离起始地址由多少字节,也就是列表尾的偏移量;
zllen: 记录压缩列表包含的节点数量;
zlend: 标记压缩列表的结束点,固定值 0xFF(十进制255)
头和尾元素可以直接定位,其他元素得遍历。
entry:
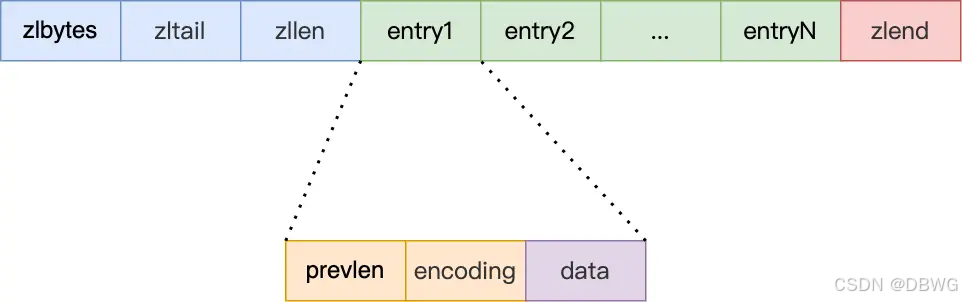
prevlen,记录了「前一个节点」的长度,因此可从后向前遍历;
encoding,记录了当前节点实际数据的「类型和长度」,类型主要有:字符串和整数。有特定编码。
data,记录了当前节点的实际数据
encoding 编码:
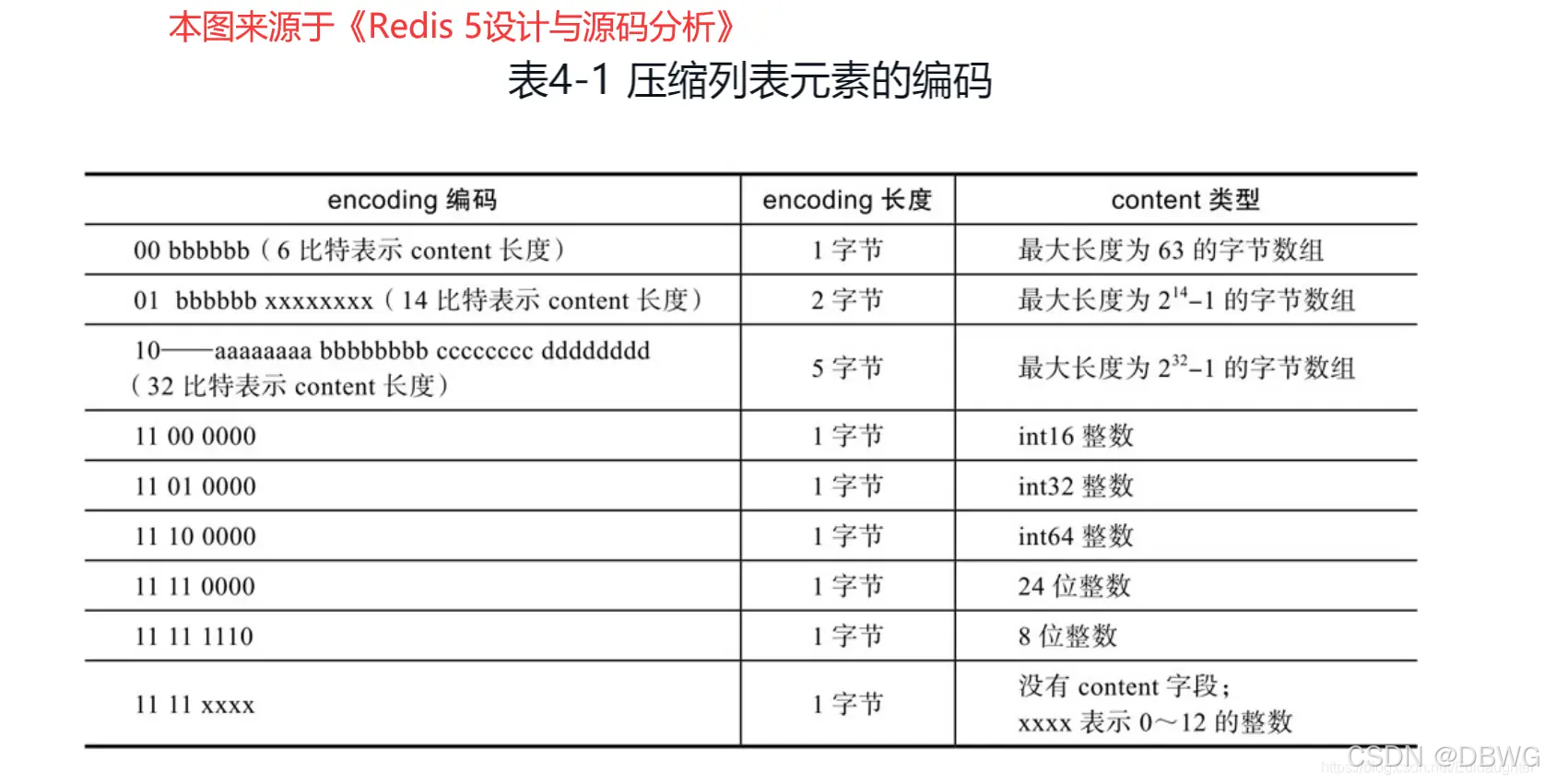
压缩列表新增或修改元素,需要重新分配内存。中间部分修改同数组一样,后续都需要更新。
而且如果中间插入的数据很长,后面的 prevlen就需要换编码为更大的。而后面的长度也会变,再往后的也需要修改。
quicklist 和 listpack 是对其的改进。
哈希表
整数集合 Set
跳表 —— Zset底层
通过倍增的方式,以不同值为跨度,快速搜索。
(倍增: 通过 z[32] 数组存 2的幂的距离的位置。如 ST表对每个位置表示各个2的幂区间的最值)

相比之下,平衡搜索树范围查找复杂,插入删除时调整多
近似倍增,更加灵活,
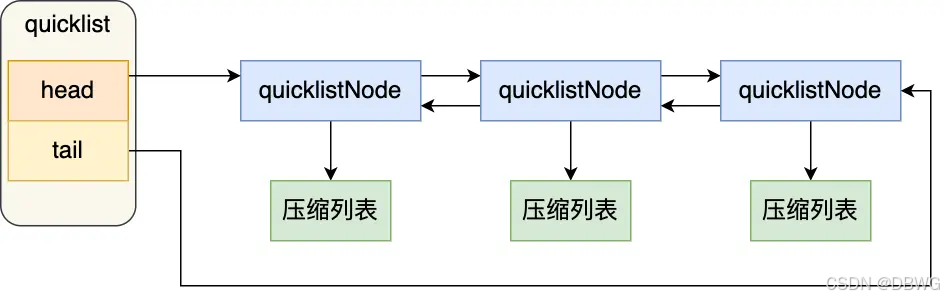
quicklist
「双向链表 + 压缩列表」组合
多个压缩列表,即可连锁更新问题。类似 deque
listpack
Redis 在 5.0 新设计的数据结构,目的是替代压缩列表。
listpack 中每个节点不再包含前⼀个节点的⻓度了,规避了连锁更新的隐患。可以看到尾部有个len —— listpack 一样可以支持从后往前遍历的
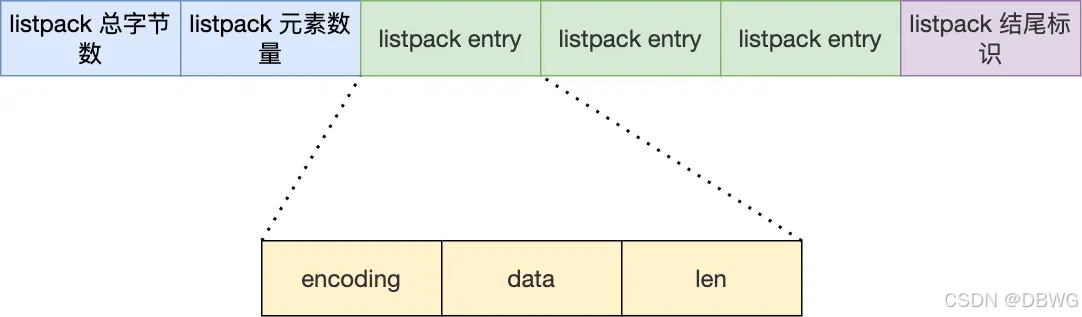
6.2版本还未替换。
2. 持久化
AOF 持久化
Append Only File
把所有执行过的语句写入文件。
默认不开启,在配置文件一半的位置可以修改:
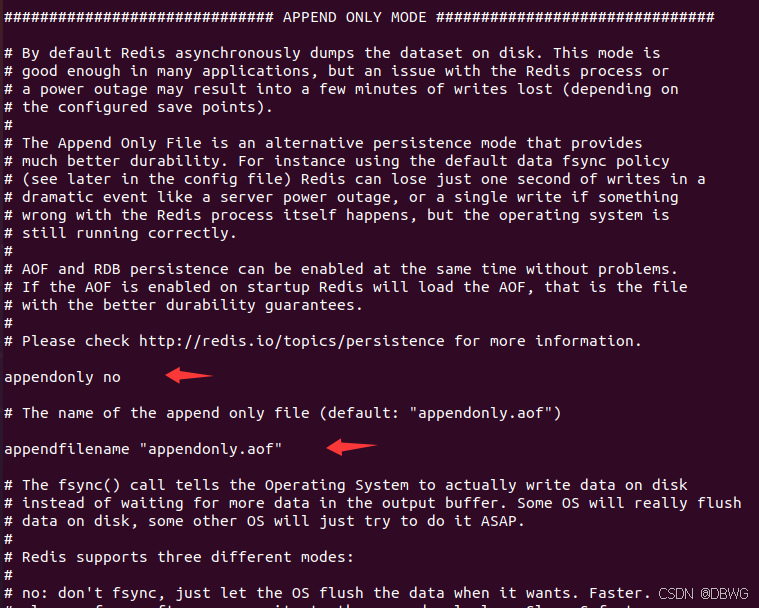
写回内容解读:
*3 当前命令有三部分
$3 每部分的长度 (字节):$3 set $4 name $7 aaaaaaa
redis 写回逻辑
- redis 执行完命令后,会将命令追加到 server.aof_buf 缓冲区;
- 通过系统调用 write() ,将缓冲区数据写入AOF文件。(write 会先把数据拷贝到 内核缓冲区 page cache,等待内核写入)
三种写回策略
- Always:每次
- Everysec:每秒
- No:不自动写回
底层是在控制 fsync() 函数调用时机
AOF 重写机制
压缩 AOF 文件
当AOF 文件的大小超过所设定的阈值后,Redis 就会启用 AOF 重写机制
为什么能重写呢?像两个 set 语句,第二个会覆盖第一个,那第一个就不用再执行了。
AOF的重写机制是: 在重写时,读取当前数据库中的所有键值对,然后将每一个键值对用一条命令记录到「新的 AOF 文件」,等到全部记录完后,就将新的 AOF 文件替换掉现有的 AOF 文件。
以上重写是由子进程完成的:
写AOF日志一般是在主进程中完成,写入内容并不多。
如果AOF文件大于64M,就会触发对AOF的重写,重写比较耗时,是由后台子进程来完成的。
这样不会阻塞主进程。而且子进程有相同的数据(fork;写时拷贝),如果用线程,就得有加锁保证数据安全等操作。
–
当子进程写时,主进程可能又修改值了:主进程会正常执行,会把该写命令追加到 【AOF 缓冲区】和【AOF重写缓冲区】
子进程重写完后通过信号告知主进程,此时主进程把AOF重写缓冲区内容追加到新的AOF文件,然后覆盖现有AOF文件
RDB 快照
我们关掉 Redis内存数据库,下次打开数据仍在。
RDB 快照就是记录某一个瞬间的所有内存数据,记录的是实际数据。而AOF是命令操作日志。
因此在 Redis 恢复数据时, RDB 恢复数据的效率会比 AOF 高些。
save bgsave 命令可以生成 RDB 文件,主线程/子进程生成。
RDB 文件的加载工作是在服务器启动时自动执行的,Redis 并没有提供专门用于加载 RDB文件的命令。
Redis会自动执行 bgsave
配置文件可以自定义:
save 900 1
save 300 10
save 60 10000
(实际执行的都是 bgsave)
意思是 多少秒过后,这期间对数据库做了至少多少次修改,就执行。
如 900s内,执行了1次修改,900s结束时,就会执行 bgsave。
由于 RDB快照 会对所有数据都去记录,因此执行消耗大,且故障时会丢失更多数据。
且 生成 RDB快照时,后续的修改是没有被记录的。
混合持久化
Redis 4.0 提出的,该方法叫混合使用 AOF 日志和内存快照,也叫混合持久化。
使用了混合持久化,AOF 文件的前半部分是 RDB 格式的全量数据,后半部分是 AOF 格式的增量数据(即生成RDB时主线程又有的新操作)。
配置:
aof-use-rdb-preamble yes
3. 过期策略
键过期
Redis 是可以对 key 设置过期时间的,因此有相应的机制将已过期的键值对删除——过期键值删除策略。
设置命令:
expire <key> <n>设置 key 在 n 秒后过期pexpire <key> <n>毫秒expireat <key> <n>时间戳。 (expireat key3 1655654400 在 1655654400时过期)pexpireat <key> <n>精确到毫秒的时间戳
设置key时设置过期:
set <key> <value> ex <n>set <key> <value> px <n>setex <key> <n> <valule>
persist <key> 取消过期时间
TTL <key> 查看 key 剩余的存活时间。(结果为 -1 表明永不过期。)
我们设置过期后,Redis 会把对应 key 带上过期时间存储到一个过期字典中。
typedef struct redisDb {dict *dict; /* 数据库键空间,存放着所有的键值对 */dict *expires; /* 键的过期时间 */....
} redisDb;
字典实际上是哈希表,哈希表的最⼤好处就是让我们可以⽤ O(1) 的时间复杂度来快速查找。
当我们查询⼀个 key 时,Redis ⾸先检查该 key 是否存在于过期字典中:如果不在,则正常读取键值;如果存在,就会对比过期时间。
过期删除策略:
- 定时删除
在设置 key 的过期时间时,同时创建⼀个定时事件,当时间到达时,由事件处理器⾃动执⾏ key 的删除操作。
[ 可以保证过期key尽快删除,内存可以尽快地释放;但是会占用 CPU 时间。 ] - 惰性删除
访问时检查是否过期,如果过期再删除。
[ 占用很少的系统资源,但是浪费空间。 ] - 定期删除
每隔一段时间「随机」从数据库中取出一定数量的 key 进行检查,并删除其中的过期key。(默认10s 20个,如果超过 25% 过期,会再次检查。会有 25ms 时间上限)
Redis 选择「惰性删除+定期删除」这两种策略配和使⽤,以求在合理使⽤ CPU 时间和避免内存浪费之间取得平
衡。
内存淘汰策略:
当 Redis 的运⾏内存已经超过 Redis 设置的最⼤内存之后,则会使⽤内存淘汰策略删除符合条件的 key,以此来保障 Redis ⾼效的运⾏。
配置文件:
maxmemory <bytes>
64位操作系统默认为 0,表示没有内存大小限制,哪怕崩溃。
32位操作系统内存最大 4GB,maxmemory 默认为 3GB
- 不进行数据淘汰的策略
noeviction 内存超过最大设置时,会报错禁止写入。 - 进行淘汰策略
『在设置了过期时间的数据中进行淘汰』
- volatile-random: 随机淘汰设置了过期时间的键值;
- volatile-ttl: 优先淘汰更早过期的键值;
- volatile-lru: 淘汰设置了过期时间的,最久未使用的键值;
- volatile-lfu: 淘汰所有设置了过期时间的,最少使用的键值。
『在所有数据范围内进行淘汰』
- allkeys-random: 随机淘汰任意键值;
- allkeys-lru: 淘汰整个键值中最久未使用的键值;
- allkeys-lfu: 淘汰整个键值中最少使用的键值。
config get maxmemory-policy 查看当前内存淘汰策略。
config set maxmemory-policy <策略> 设置本次运行的内存淘汰策略。
maxmemory-policy <策略> 重启后仍会生效,不过需要先重启。
Redis 实现的是一种近似 LRU 算法,为了节省内存。(LRU本身要维护链表,并且需要频繁移动节点)
Redis 在对象结构体添加一个额外字段,用于记录最后一次访问时间。当 Redis 进⾏内存淘汰时,会使⽤随机采样的⽅式来淘汰数据,它是随机取 5 个值(此值可配置),然后淘汰最久没有使⽤的那个。
但是 LRU 算法 无法解决缓存污染问题,即只会被读一次的数据也会维护,大量读取时,占用了链表。
因此,在 Redis 4.0 之后引入了 LFU 算法:
Least Frequently Used 最不频繁常用,是根据数据访问次数来淘汰数据的,它的核⼼思想是“如果数据过去被访问多次,那么将来被访问的频率也更⾼”。
typedef struct redisObject {...// 24 bits,用于记录对象的访问信息unsigned lru:24;
} robj;
lru字段在LRU算法中用来记录时间戳。
在LFU算法中,高16位记录 上次访问时间戳 ldt(Last Decrement Time)
低8位存储 key的访问频次 logc(Logistic Counter) (不是次数,会随着时间推移衰减。每次访问时会先衰减,然后增加,越大加的会越少)
4. 缓存三剑客
redis 缓存中没有,而要去数据库查,导致速度慢。
缓存穿透:要访问的不存在
缓存击穿:刚好过期
缓存雪崩:大量同时过期
Redis 故障宕机导致雪崩的解决方案
针对 Redis 故障宕机而引发的缓存雪崩问题,常见的应对方法:
- 服务熔断或请求限流机制;
- 构建 Redis 缓存高可靠集群;
- 服务熔断或请求限流机制
服务熔断即暂停业务应用对缓存服务的访问,直接返回错误,不再访问数据库,从而降低对数据库的访问压力,保证数据库系统的正常运行。
也可以 请求限流:只将少部分请求发送到数据库进行处理,再多的请求就在入口直接拒绝服务
等redis恢复正常并把缓存预热完后,再解除。 - 构建 Redis 缓存高可靠集群
通过主从节点的方式构建 Redis 缓存高可靠集群。
如果 Redis 缓存的主节点故障宕机,从节点可以切换成为主节点,继续提供缓存服务,避免了由于 Redis 故障宕机而导致的缓存雪崩问题。
5. 数据库和缓存 保证一致性
当两个修改同时发生时,由于是异步,两边(数据库和缓存)都要改,就容易出现先后问题:
先改数据库:
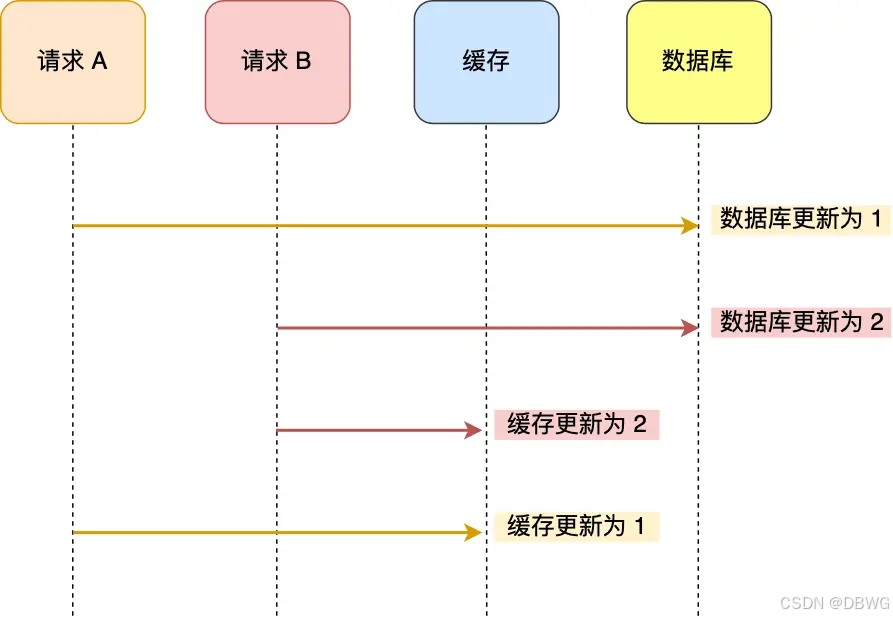
先改缓存:
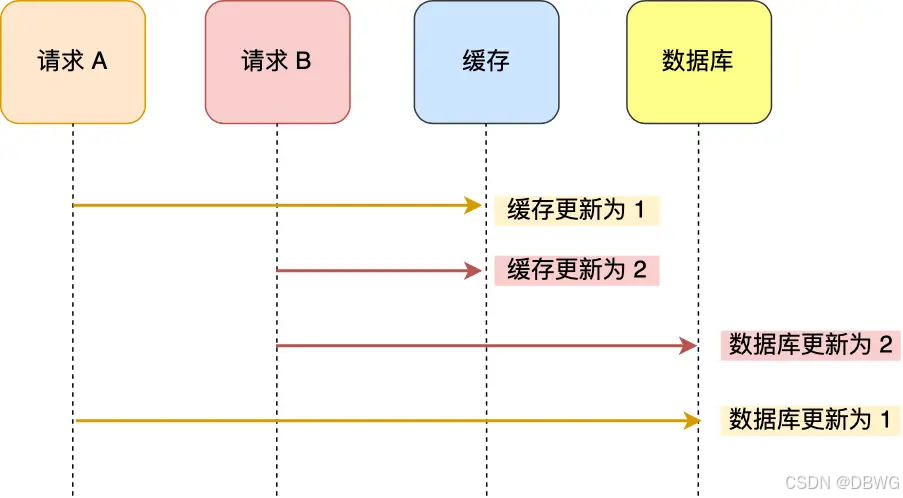
Cache Aside 旁路缓存策略
在更新数据时,不更新缓存,而是删除缓存中的数据。然后到读取数据时,发现缓存中没数据,再从数据库中读取数据,更新到缓存中。
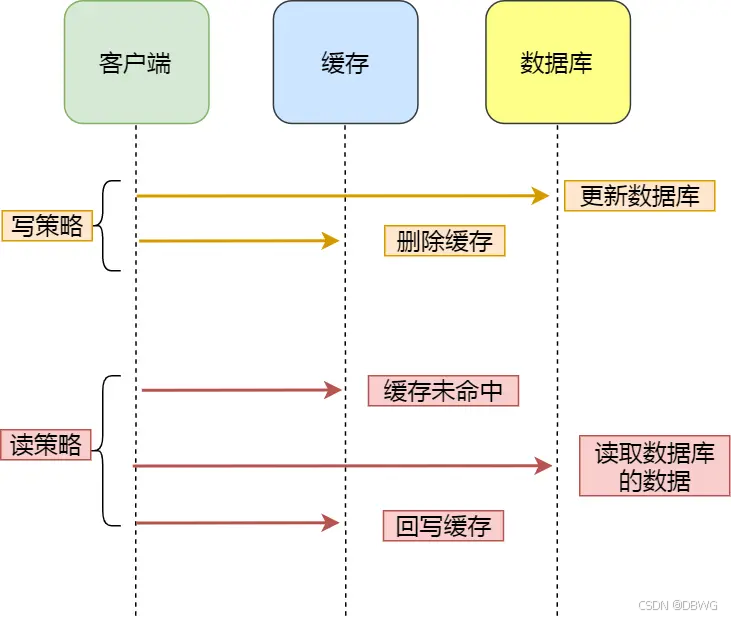
- 先更新数据库再删除缓存,可能还没删除,就有读操作读缓存了。
但是缓存的写入非常快,几乎不会出现这种情况!✅ - 先删缓存再更新数据库,可能还没修改完,另一个读操作已经去数据库读了。❌
先更新数据库再删除缓存能解决数据一致性问题。
有时可能缓存删除执行失败,导致前台发现数据没有修改。等redis缓存过期更新时,才恢复。
解决方法:
- 消息队列重试机制
引入消息队列,将第二个操作(删除缓存)要操作的数据加入到消息队列,由消费者来操作数据。- 重试机制:如果应用删除缓存失败,可以从消息队列中重新读取数据,然后再次删除缓存。重试次数过多再报错。
(不过需要改的已有业务代码——入侵)
- 重试机制:如果应用删除缓存失败,可以从消息队列中重新读取数据,然后再次删除缓存。重试次数过多再报错。
- Canal 中间件 + 消息队列
订阅 MySQL binlog,拿到具体要操作的数据,再操作缓存
阿里巴巴开源的 Canal 中间件 模拟 MySQL 主从复制的交互协议,把⾃⼰伪装成⼀个 MySQL 的从节点,向 MySQL 主节点发送 dump 请求。MySQL 收到请求后,就会开始推送 Binlog 给 Canal,Canal 解析 Binlog 字节流之后,转换为便于读取的结构化数据,供下游程序订阅使⽤。
不过还是希望不删除缓存的:
延迟双删
在更新完缓存时,给缓存加上较短的过期时间,这样即时出现缓存不一致的情况,缓存的数据也会很快过期,对业务还是能接受的。
为什么是删除缓存,而不是更新缓存呢?
删除⼀个数据,相⽐更新⼀个数据更加轻量级,出问题的概率更⼩。在实际业务中,缓存的数据可能不是直接来⾃数据库表,也许来⾃多张底层数据表的聚合。
另外,不是所有的缓存数据都是频繁访问的,更新后的缓存可能会⻓时间不被访问,所以从计算资源和整体性能的考虑,更新的时候删除缓存,等到下次查询命中再填充缓存,是⼀个更好的⽅案。
像 Lazy Loading 懒加载。





: === 与 == 比较运算符)