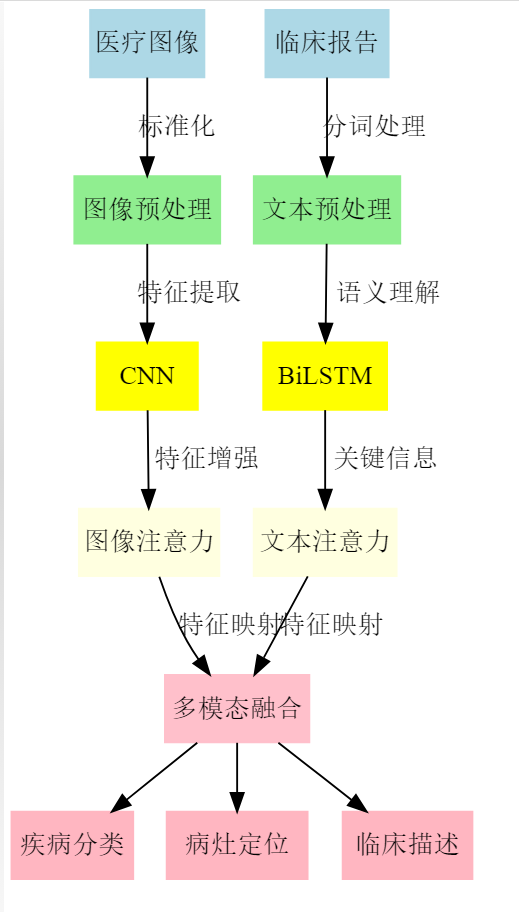
临床双模诊断系统:CNN处理图像 + BiLSTM处理文本
- 论文大纲
- 理解要点
- 1. 确认目标
- 2. 分析过程
- 3. 实现步骤
- 4. 效果展示
- 5. 领域金手指
- 结构分析
- 1. 层级结构分析
- A. 叠加形态(从底层到高层)
- B. 构成形态(涌现特性)
- C. 分化形态
- 2. 线性结构分析(发展趋势)
- 3. 矩阵结构分析
- 4. 系统动力学分析
- 全流程优化
- 数据分析
- 第一步:数据收集
- 第二步:数据规律挖掘
- 第三步:相关性分析
- 第四步:数学模型建立
- 模型价值
- 解法拆解
- 1. 逻辑关系拆解
- A. 特征提取解法
- B. 特征增强解法
- C. 特征融合解法
- 2. 逻辑链分析
- 3. 隐性特征分析
- 4. 潜在局限性
- 为什么要在融合层之前使用注意力机制?
论文:Integrating Medical Imaging and Clinical Reports Using Multimodal Deep Learning for Advanced Disease Analysis
论文大纲
├── 1 多模态深度学习模型【核心主题】
│ ├── 研究背景【背景阐述】
│ │ ├── 医疗图像和临床报告信息整合的挑战【问题提出】
│ │ └── 深度学习在医疗领域应用的重要性【意义说明】
│ │
│ ├── 模型架构【技术框架】
│ │ ├── CNN模块【图像特征提取】
│ │ │ ├── 高维特征提取【功能说明】
│ │ │ └── 视觉信息捕捉【功能说明】
│ │ │
│ │ ├── Bi-LSTM模块【文本特征提取】
│ │ │ ├── 上下文信息处理【功能说明】
│ │ │ └── 时序依赖关系分析【功能说明】
│ │ │
│ │ ├── 注意力机制【特征增强】
│ │ │ ├── 动态权重分配【功能说明】
│ │ │ └── 关键信息聚焦【功能说明】
│ │ │
│ │ └── 多模态融合层【特征整合】
│ │ ├── 特征映射【功能说明】
│ │ └── 深度融合【功能说明】
│ │
│ └── 实验评估【效果验证】
│ ├── 数据集构建【实验基础】
│ │ ├── 医疗图像库【数据来源】
│ │ └── 临床报告文本【数据来源】
│ │
│ └── 性能指标【评估结果】
│ ├── 准确率性能【评估维度】
│ ├── 召回率表现【评估维度】
│ ├── F1分数评估【评估维度】
│ └── IoU指标分析【评估维度】
│
└── 2 应用价值【实践意义】
├── 疾病分类【应用场景】
├── 病灶定位【应用场景】
├── 临床描述生成【应用场景】
└── 医疗AI发展推动【发展前景】
理解要点
- 背景分析:
- 类别问题:医疗数据异构信息的深度整合问题
- 具体问题:如何有效融合医疗图像(CT、MRI等)和临床报告文本的信息,实现精准诊断
- 概念性质:
- 性质:多模态深度学习模型是一个异构信息融合系统
- 原因:医疗数据天然具有图像和文本两种不同形式,需要不同的处理方法
- 对比案例:
- 正例:使用CNN+BiLSTM+注意力机制的多模态模型,准确率达96.42%
- 反例:单独使用CNN的模型,准确率仅为92.26%
- 类比理解:
这个模型就像一个经验丰富的医生,同时具备:
- “火眼金睛”(CNN处理图像)
- “过目不忘”(BiLSTM处理文本)
- “重点关注”(注意力机制)的能力
-
概念归纳:
多模态深度学习模型是一个集成了图像识别、文本理解和特征融合的智能系统,通过多层次的信息提取和整合,实现医疗诊断的智能化 -
概念重组:
"多模态深度学习"可以理解为:多种形式的数据,通过深层次的学习,实现模式化的认知过程 -
上下文关联:
论文通过理论分析、模型构建、实验验证的完整体系,展示了该模型在医疗领域的应用价值 -
规律发现:
主要矛盾:异构数据的有效融合问题
次要矛盾:
- 模型复杂度与计算效率的平衡
- 特征提取的准确性
- 融合策略的优化
- 功能分析:
定量指标:
- 准确率:96.42%
- 召回率:98.48%
- F1值:0.97
定性功能:
- 疾病分类
- 病灶定位
- 临床描述生成
- 来龙去脉:
- 起因:医疗数据形式多样,需要整合分析
- 发展:提出多模态深度学习模型
- 结果:实现了医疗图像和临床报告的有效融合
- 影响:为精准医疗和智能诊断提供了新思路
这个模型的核心价值在于它实现了医疗数据的"多模态"融合,为提高诊断准确性提供了技术支撑。
1. 确认目标
如何有效整合医疗图像和临床报告的异构信息,提升医疗诊断的准确性?
2. 分析过程
大问题拆解:
-
如何处理医疗图像数据?
- 使用CNN提取图像高维特征
- 捕捉关键视觉信息(病灶细节、纹理特征、空间分布)
-
如何理解临床报告文本?
- 采用BiLSTM进行深度语义理解
- 应用注意力机制识别关键语句
- 过滤无关信息,保留诊断要点
-
如何实现异构数据的融合?
- 设计多模态融合层
- 将特征映射到同一特征空间
- 通过加权合并生成联合表示
3. 实现步骤
-
数据预处理阶段
- 医疗图像标准化
- 临床文本分词处理
-
特征提取阶段
- CNN提取图像特征
- BiLSTM处理文本序列
-
特征融合阶段
- 注意力机制增强特征
- 多模态融合生成统一表示
-
任务输出阶段
- 疾病分类
- 病灶定位
- 临床描述生成
4. 效果展示
目标:提高医疗诊断准确性
过程:多模态深度学习
方法:CNN + BiLSTM + 注意力机制
数据:大规模医疗图像库和配对临床报告
结果:
- 准确率:96.42%
- 召回率:98.48%
- F1分数:0.97
5. 领域金手指
本文的金手指是"注意力机制",它能:
-
在图像中
- 定位关键区域
- 过滤背景噪声
- 突出病灶特征
-
在文本中
- 识别关键词
- 捕捉语义关联
- 提取诊断重点
-
在特征融合中
- 动态分配权重
- 优化特征整合
- 提升模型性能
这个金手指的普适性体现在:
- 可用于各类医疗图像(CT、MRI、超声等)
- 适用于不同疾病类型
- 支持多种诊断任务
- 能处理不同语言的临床报告
应用这个框架,不仅解决了当前的医疗数据融合问题,还为其他领域的多模态数据处理提供了范式。
结构分析
1. 层级结构分析
A. 叠加形态(从底层到高层)
第四层:智能决策层└── 疾病诊断、病灶定位、临床描述生成第三层:融合认知层└── 多模态融合机制、联合表示学习第二层:特征理解层├── 图像特征提取(CNN)└── 文本特征提取(BiLSTM)第一层:数据基础层├── 医疗图像(CT、MRI等)└── 临床报告文本
B. 构成形态(涌现特性)
基础组件 涌现能力
CNN + BiLSTM → 多模态特征提取
特征提取 + 注意力 → 关键信息增强
多模态融合 → 异构信息整合
整体系统 → 智能医疗诊断
C. 分化形态
多模态深度学习模型
├── 图像处理分支
│ ├── 预处理
│ ├── 特征提取
│ └── 特征增强
│
└── 文本处理分支├── 文本分词├── 语义理解└── 关键信息提取
2. 线性结构分析(发展趋势)
单一模态处理 → 双模态并行处理 → 多模态融合 → 智能诊断决策
3. 矩阵结构分析
| 图像模态 | 文本模态
处理层级 | CNN处理 | BiLSTM处理
特征层级 | 视觉特征 | 语义特征
融合层级 | 注意力机制融合
输出层级 | 智能诊断决策
4. 系统动力学分析
核心循环:
数据输入 → 特征提取 → 特征增强 → 模态融合 → 决策输出反馈机制:
├── 正向强化
│ ├── 准确率提升
│ └── 诊断效率提升
│
└── 负向制约├── 计算复杂度└── 数据质量要求
全流程优化
数据分析
第一步:数据收集
论文收集了两类核心数据:
-
医疗图像数据
- 类型:CT、MRI、超声等医学影像
- 来源:大规模医疗图像数据库
- 特点:包含多种疾病案例
-
临床报告数据
- 类型:文本描述、诊断记录
- 特点:与医疗图像一一对应
- 内容:包含疾病描述、诊断结论
第二步:数据规律挖掘
-
图像数据规律
- 使用CNN提取视觉特征
- 发现关键区域特征
- 识别病灶纹理模式
视觉特征 = CNN(医疗图像) -
文本数据规律
- 通过BiLSTM分析语义关联
- 识别关键诊断信息
- 提取时序上下文
语义特征 = BiLSTM(临床报告)
第三步:相关性分析
-
模态间相关性
- 图像特征与文本描述的对应关系
- 病灶位置与诊断结论的关联
- 视觉表现与症状描述的映射
-
特征关联分析
相关性分析流程:
图像特征 ─┐├─> 注意力机制 ─> 权重分配 ─> 特征融合
文本特征 ─┘
第四步:数学模型建立
- 基础数学模型
# CNN模型
y_ij^(l) = σ(∑w_mn^(l)x_(i+m-1,j+n-1)^(l-1) + b^(l))# BiLSTM模型
h_t = [h_t→; h_t←]# 注意力模型
Attention(Q,K,V) = softmax(QK^T/√d_k)V
- 综合评估指标
模型性能 = {"准确率": 96.42%,"召回率": 98.48%,"F1分数": 0.97,"IoU": 0.89
}
- 预测模型建立
最终预测 = f(图像特征, 文本特征) = {"疾病分类": 分类结果,"病灶定位": 位置坐标,"临床描述": 生成文本
}
模型价值
-
预测能力
- 通过已知图像预测疾病类型
- 通过文本描述定位病灶位置
- 基于多模态信息生成诊断报告
-
泛化能力
- 适用于多种医疗场景
- 支持不同类型的疾病诊断
- 具备跨模态分析能力
-
实践意义
- 提供可靠的辅助诊断
- 降低医生工作负担
- 提升医疗诊断效率
这个数据分析过程不仅揭示了医疗数据的内在规律,还建立了可靠的预测模型,为医疗诊断提供了有力的技术支持。
解法拆解
1. 逻辑关系拆解
目的:提升医疗诊断的准确性和效率
问题:如何有效整合医疗图像和临床报告信息
解法 = 特征提取 + 特征增强 + 特征融合
A. 特征提取解法
因为数据异构性特征,分为:
1. 图像特征提取(CNN)└── 因为:医疗图像具有空间局部性和层次性特征2. 文本特征提取(BiLSTM)└── 因为:临床报告具有序列性和上下文依赖特征
举例:肺部CT图像中的结节特征提取和对应的临床描述文本处理
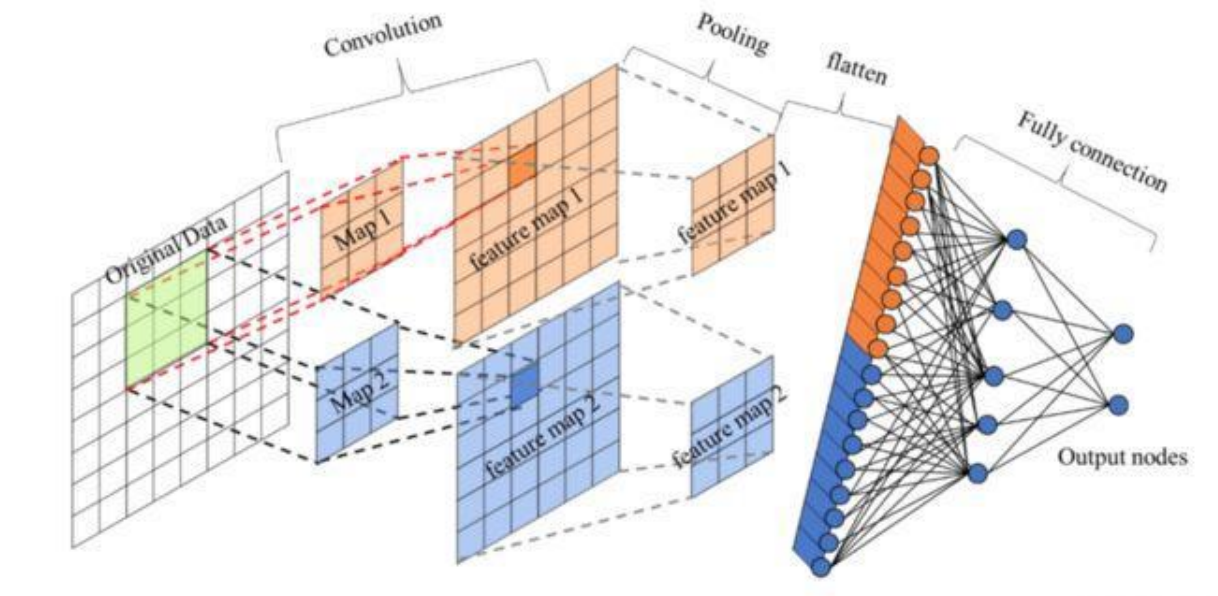
CNN:
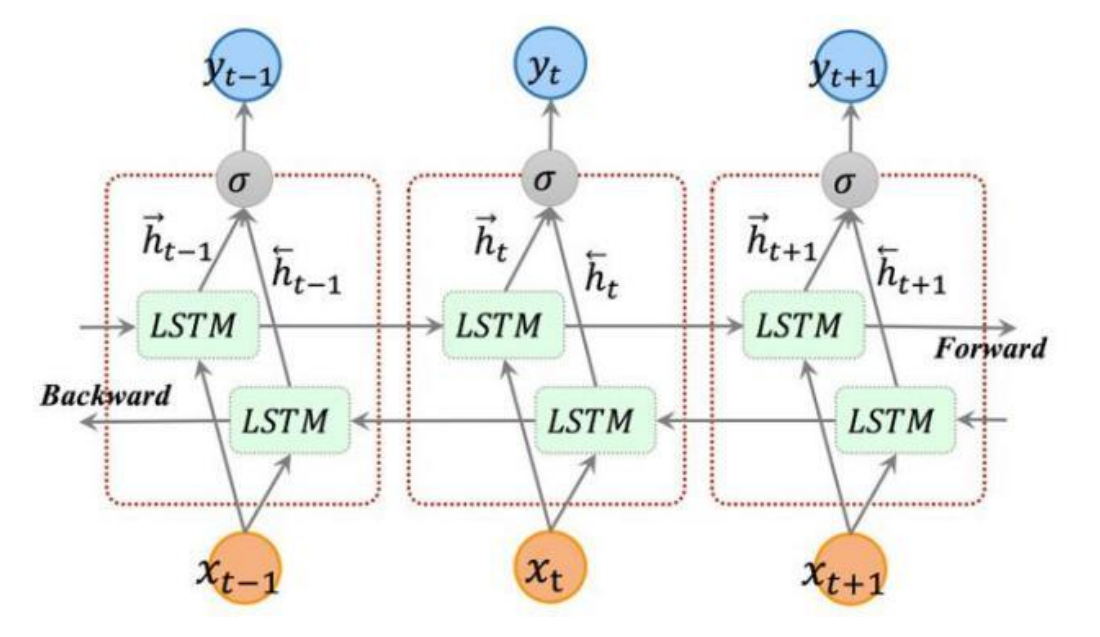
LSTM:
B. 特征增强解法
因为关键信息不均匀分布特征,使用:
1. 空间注意力机制└── 因为:病灶区域在图像中分布不均匀2. 语义注意力机制└── 因为:诊断关键词在文本中分布稀疏
举例:自动聚焦肺部阴影区域和相关症状描述
C. 特征融合解法
因为多模态互补性特征,采用:
1. 特征映射└── 因为:不同模态特征空间不一致2. 联合表示学习└── 因为:需要捕捉模态间的相互关系
举例:将肺部CT的视觉特征与放射科报告的文本特征融合
2. 逻辑链分析
决策树形式:
多模态深度学习模型
├── 特征提取层
│ ├── CNN
│ │ ├── 卷积运算
│ │ └── 池化操作
│ └── BiLSTM
│ ├── 前向传播
│ └── 反向传播
├── 特征增强层
│ ├── 空间注意力
│ └── 语义注意力
└── 特征融合层├── 特征映射└── 联合表示
3. 隐性特征分析
发现的隐性特征:
-
特征粒度依赖性
- 表现:不同层次特征的选择影响最终效果
- 定义:特征提取的深度和广度平衡问题
-
模态对齐问题
- 表现:不同模态信息的时空对应关系
- 定义:多模态数据的同步性和一致性要求
-
特征冗余性
- 表现:提取的特征存在重复和冗余
- 定义:特征选择的有效性和必要性问题
4. 潜在局限性
-
技术局限
- 计算复杂度高
- 需要大量配对数据
- 模型可解释性不足
-
应用局限
- 对数据质量要求高
- 难以处理罕见病例
- 泛化能力有限
-
实践局限
- 部署成本高
- 需要专业维护
- 医生接受度挑战
-
安全性局限
- 隐私保护问题
- 数据安全风险
- 模型鲁棒性挑战
这种详细拆解有助于我们更深入地理解模型的优势和局限,为未来改进提供方向。
为什么要在融合层之前使用注意力机制?
5Why分析
Why 1: 为什么需要在融合前使用注意力机制?
- 因为原始特征中包含大量冗余和无关信息,需要筛选和突出关键特征
Why 2: 为什么要筛选和突出关键特征?
- 因为不同特征的重要性不同,直接融合会导致关键信息被噪声干扰或被稀释
Why 3: 为什么会有特征重要性的差异?
- 因为在医疗诊断中,某些特定区域(如病灶)或关键词(如症状描述)对诊断结果的影响更大
Why 4: 为什么这些差异会影响融合效果?
- 因为如果不区分重要性,模型可能会过分关注无关信息,导致决策偏差
Why 5: 最根本的原因是什么?
- 医疗数据的本质是信息密度不均匀的,需要智能化的特征选择机制来提高信息利用效率
5So分析
So 1: 如何优化注意力机制?
- 设计多层次的注意力机制,分别处理空间维度和语义维度的特征选择
So 2: 这种优化会带来什么效果?
- 能够更准确地定位关键信息,提高特征表示的质量,为后续融合提供更好的基础
So 3: 这个改进如何影响整个系统?
- 提升模型的判断准确性,增强结果的可解释性,使系统更适合实际临床应用
So 4: 更深层的影响是什么?
- 推动医疗AI系统向更精准、更可靠的方向发展,增强医生对系统的信任度
So 5: 最终目标是什么?
- 实现智能、精准的医疗辅助诊断,在保证准确性的同时提供清晰的诊断依据
基于这个分析,我想继续探讨:您认为在注意力机制的设计中,如何平衡模型的复杂度和实时性需求?是否有可能通过简化注意力机制来提高处理效率而不显著影响性能?





)