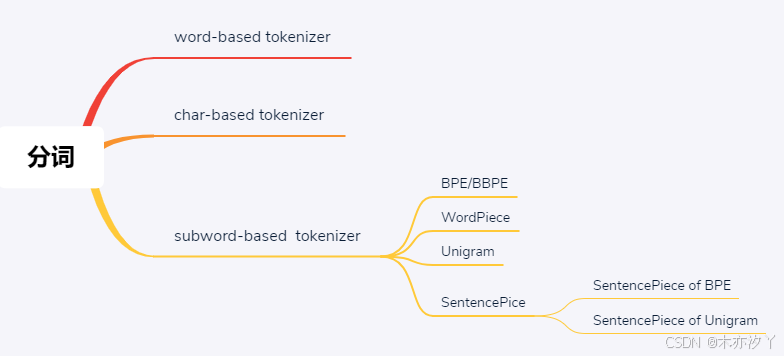
文章目录
一、概念介绍
二、单词级别分词
三、字符级别分词
四、子词级别分词
BPE/BBPE分词
BPE:Byte-Pair Encoding (BPE)
BBPE:Byte-level BPE (BBPE)
WordPiece分词
Unigram分词
五、总结
词元化(Tokenization)是数据预处理中的一个关键步骤,旨在将原始文本分割成模型可识别和建模的词元序列,作为大语言模型的输入数据。
传统自然语言处理研究(如基于条件随机场的序列标注)主要使用基于词汇的分词方法(Word-based Tokenizer),这种方法更符合人类的语言认知。
然而,基于词汇的分词在某些语言(如中文分词)中可能对于相同的输入产生不同的分词结果,导致生成包含海量低频词的庞大词表,还可能存在未登录词(Out-of-vocabulary, OOV)等问题。
因此,一些语言模型开始采用字符作为最小单位来分词(Character-based Tokenizer)。例如,ELMo 采用了 CNN 词编码器。
最近,子词分词器(Subword-based Tokenizer)被广泛应用于基于 Transformer 的语言模型中,包括BPE 分词、WordPiece 分词和 Unigram 分词三种常见方法。
HuggingFace 维护了一个在线自然语言处理课程,是一个很好的学习资源,其中的分词部分提供了非常具体的演示实例,推荐初学者可以参考学习。https://huggingface.co/learn/nlp-course/chapter6
一、概念介绍
Token:是文本数据的基本单元也即词元,通常表示一个词、子词或字符。
Tokenization:中文翻译为分词,是将原始文本字符串分割成一系列Token的过程。这个过程可以有不同的粒度,比如单词级别分词(Word-based Tokenization)、字符级别分词(Character-based Tokenization)和子词级别分词(Subword-based Tokenization)。
Tokenizer:是将文本切分成多个tokens的工具或算法,例如:Word-based Tokenizer,Character-based Tokenizer,Subword-based Tokenizer。
Transformer模型中,Inputs是词元化后token对应的id,而Input Embedding则用来表示token的稠密向量,是由token学习得到。Embedding layer 是Transformer 模型的一部分。
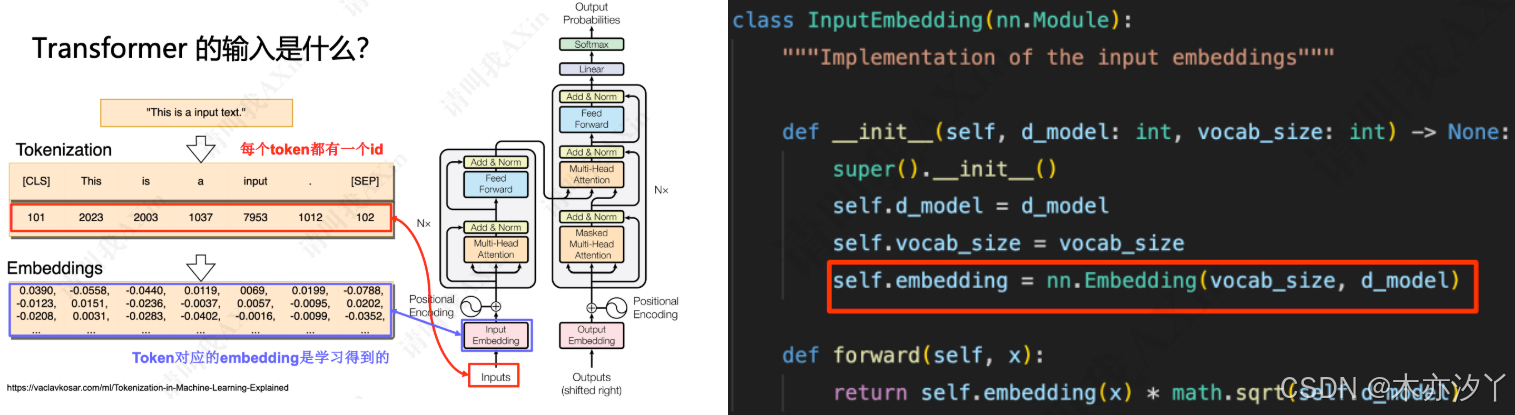
Tokenizer 的作用:将文本序列转化为数字序列(token编号),作为 transformer的输入,是训练和微调 LLM 必不可少的一部分。
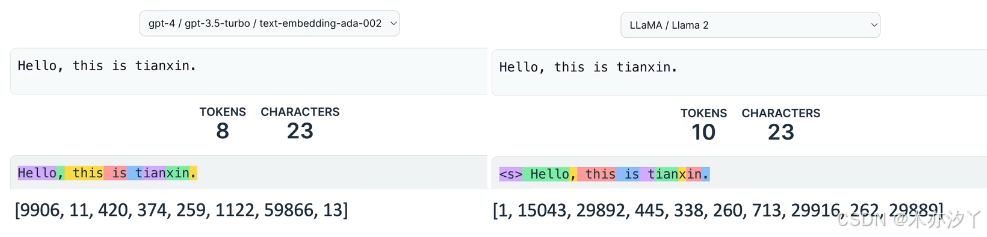
感兴趣的同学可以在HuggingFace的The Tokenizer Playground 体验部分模型的分词。
二、单词级别分词
单词级别分词:将文本划分为一个个词(包括标点)。
我们以这句话为例:"Don't you love 🤗 Transformers? We sure do."

但是这里的Don't 应该被划分为Do,n't,引入规则之后事情就变得复杂起来了。
英文的划分有两个常用的基于规则的工具spaCy 和 Moses,划分如下:
["Do", "n't", "you", "love", "🤗", "Transformers", "?", "We", "sure", "do", "."]
- 优点:符合人类的自然语言和直觉
- 缺点:相同意思的词被划分为不同的token,导致词表非常大,例如:dog、dogs会是两个token。
- 如果词表非常大,我们可以设置词表上限比如上限为10000,未知的词用Unkown表示。但是这样会存在信息损失,加重OOV问题,模型性能大打折扣。
- 难以处理拼写错误的单词。
三、字符级别分词
字符级别分词:将文本划分为一个个字符(包括标点)。

- 优点
-
可以表示任意(英文)文本,不会出现word-based中的unknown情况。
-
对西文来说,不需要很大的词表,例如英文只需不到256个字符(ASCII码表示)。
-
- 缺点
-
字母相对于单词包含的信息量低,所以模型性能一般很差。
例如:一个字母 “T” 无法知道它具体指代的是什么,但如果是 “Today” 语义就比较明确。 -
相对于Word-based Tokenizer ,会产生很长的token序列。
-
如果是中文,依然会有很大的词表。
-
四、子词级别分词
子词级别分词:常用词不应该再被切分成更小的token或子词(subword),不常用的词或词群应该用子词来表示。
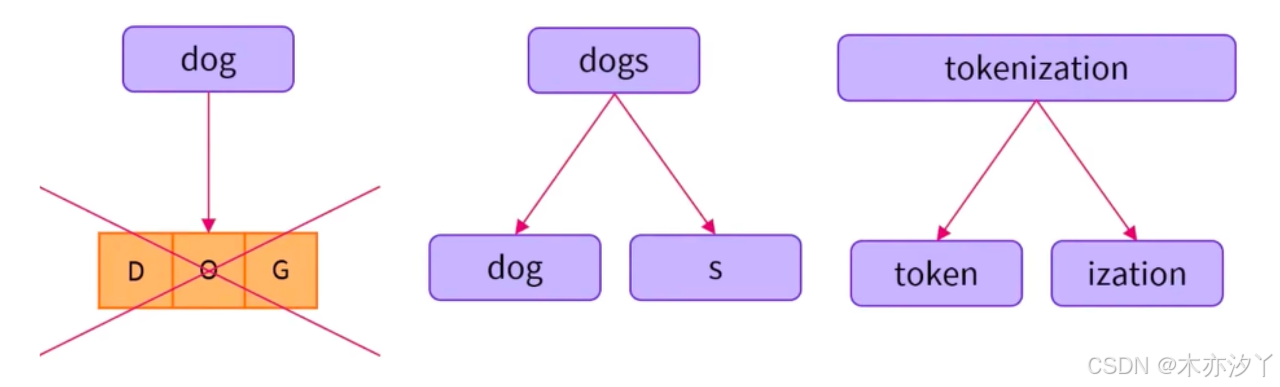
使用subword划分符合英文词群,能够充分表意。

例如:BERT会将“tokenization”分为“token”和“##ization”; ##表示该token是一个词的结尾。
常用的三种分词:BPE/BBPE 分词、WordPiece 分词和 Unigram 分词
BPE/BBPE分词
BPE:Byte-Pair Encoding (BPE)
BPE算法包含两部分: “词频统计”与“词表合并”。BPE算法从一组基本符号(例如字母和边界字符)开始,迭代地寻找语料库中的两个相邻词元,并将它们替换为新的词元,这一过程被称为合并。合并的选择标准是计算两个连续词元的共现频率,也就是每次迭代中,最频繁出现的一对词元会被选择与合并。合并过程将一直持续达到预定义的词表大小。
词频统计依赖于一个预分词器(pre-tokenization)将训练数据分成单词。预分词器可以非常简单,按照空格进行分词。例如GPT2,RoBERTa等就是这样实现的,更高级的预分词器引入了基于规则的分词,例如XLM,FlauBERT 使用Moses, GPT 使用spaCy和ftfy来统计语料中每个单词的词频。
在预分词之后,创建一个包含不同单词和对应词频的集合,接下来根据这个集合创建包含所有字符的词表,再根据词表切分每个单词,按照合并规则两两合并形成一个新词,如将词内相邻token出现频率最高的新词加入词表,直到达到预先设置的数量,停止合并。
假设在预分词(一般采用Word-based Tokenization)之后,得到如下的包含词频的集合:
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4),("hugs", 5)
因此,基本词表是这样的:["b", "g", "h", "n", "p", "s", "u"] ,
将所有单词按照词汇表里的字符切割得到如下形式:
("h" "u" "g", 10), ("p" "u" "g", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "u" "g" "s", 5)
接下来统计相邻的两个字符组成的字符对的出现的频率,频率最高的合并加入词表,设置BPE合并次数(超参数),达到则停止合并。
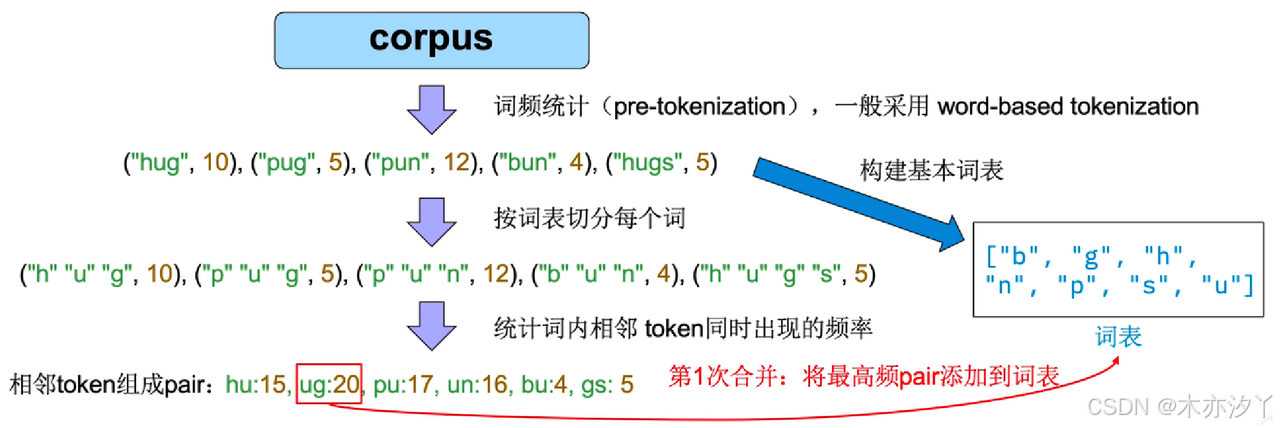
经过三轮迭代,得到新的词表:["b", "g", "h", "n", "p", "s", "u","ug","un", "hug"]
进行tokenization时,对于不在词表中的设置为特殊词<unk>。如:bug => ["b", "ug"],mug => ["<unk>", "ug"]。
例如:GPT的词汇表大小就是40478,包含基本字符478个,并经过40000次合并,添加了高频pair,然后就利用这个词表进行分词。
BPE 算法的代码如下:
import re
from collections import defaultdictdef extract_frequencies (sequence):"""给定一个字符串,计算字符串中的单词出现的频率,并返回词表(一个词到频率的映射一字典)。"""token_counter = Counter()for item in sequence:tokens = ' '.join(list(item))+'</w>'token_counter[tokens] += 1return token_counterdef frequency_of_pairs(frequencies):"""给定一个词频字典,返回一个从字符对到频率的映射字典。"""pairs_count = Counter()for token, count in frequencies.items():chars = token.split()for i in range(len(chars) - 1):pair=(chars[i], chars[i+1])pairs_count[pair] += countreturn pairs_countdef merge_vocab(merge_pair, vocab):"""给定一对相邻词元和一个词频字典,将相邻词元合并为新的词元,并返回新的词表。"""re_pattern = re.escape(' '.join(merge_pair))pattern = re.compile(r'(?<!\S)' + re_pattern + r'(?!\S)')updated_tokens = {pattern.sub(''.join(merge_pair), token): freq for token,freq in vocab.items()}return updated_tokensdef encode_with_bpe(texts, iterations):"""给定待分词的数据以及最大合并次数,返回合并后的词表。"""vocab_map = extract_frequencies(texts)for _ in range(iterations):pair_freqs = frequency_of_pairs(vocab_map)if not pair_freqs:breakmost_common_pair = pair_freqs.most_common(1)[0][0]vocab_map = merge_vocab(most_common_pair, vocab_map)return vocab_mapnum_merges = 1000
bpe_pairs = encode_with_bpe(data, num_merges)BPE的缺点:包含所有可能的基本字符(token)的基本词汇表可能相当大。例如:将所有Unicode字符都被视为基本字符(如中文)。
如果仅仅是英文,那么BPE的基本词汇表大小就是ASCII的词汇表大小,但如果是多种语言,比如加入了韩语,中文,日语甚至表情,那么BPE的基本词汇表就变成了全部Unicode字符,这个时候词汇表就将非常庞大,那么这个时候我们就会思考,有没有一种可能用统一的方式表示各种语言呢,那就是用字节Byte表示,也就是先将所有的字符转成UTF-8编码。
BBPE:Byte-level BPE (BBPE)
字节级别的 BPE(Byte-level BPE, B-BPE)是 BPE 算法的一种拓展。它将字节视为合并操作的基本符号,从而可以实现更细粒度的分割,且解决了未登录词问题。采用这种词元化方法的代表性语言模型包括 GPT2、GPT3、GPT4、BART 和 LLaMA 。
具体来说,如果将所有 Unicode 字符都视为基本字符,那么包含所有可能基本字符的基本词表会非常庞大(例如将中文的每个汉字当作一个基本字符)。而将字节作为基本词表可以设置基本词库的大小为 256,同时确保每个基本字符都包含在词汇中。
改进:将字节(byte)视为基本token,两个字节合并即可以表示Unicode。比如中文、日文、阿拉伯文、表情符号等等。
UTF-8 是一种针对Unicode的可变长度字符编码,也是一种前缀码。它可以用一至四个字节对Unicode字符集中的所有有效编码点进行编码。
每一个字节都是8位比特,8位比特的无符号整数范围为0-255,因此,BBPE的基本词汇表又回到了256,是不是特别神奇。
例如:GPT-2的词汇表大小为 50257,对应于256字节的基本词元、一个特殊的文末词元以及通过 50000 次合并学习到的词元。通过使用一些处理标点符号的附加规则,GPT2 的分词器可以对文本进行分词,不再需要使用 “<UNK>” 符号。
❗️需要注意的是,由于 Unicode 中存在重复编码的特殊字符,可以使用标准化方法(例如NFKC)来预处理我们的语料。但 NFKC 并不是无损的,可能会降低分词性能。
WordPiece分词
WordPiece 是谷歌内部非公开的分词算法,最初是由谷歌研究人员在开发语音搜索系统时提出的。随后,在 2016 年被用于机器翻译系统,并于 2018年被 BERT 采用作为分词器。
WordPiece 分词和 BPE 分词的想法非常相似,都是通过迭代合并连续的词元,但是合并的选择标准略有不同。
在合并前,WordPiece分词算法会首先训练一个语言模型,并用这个语言模型对所有可能的词元对进行评分。然后,在每次合并时,它都会选择使得训练数据的似然性增加最多的词元对。
由于谷歌并未发布 WordPiece 分词算法的官方实现,这里我们参考了 HuggingFace 在线自然语言课程中给出的 WordPiece 算法的一种实现。
与 BPE 类似,WordPiece 分词算法也是从一个小的词汇表开始,其中包括模型使用的特殊词元和初始词汇表。由于它是通过添加前缀(如 BERT 的##)来识别子词的,因此每个词的初始拆分都是将前缀添加到词内的所有字符上,除第一个字符外。
举例来说,“word”会被拆分为:“w、##o、##r、##d”。
与 BPE 方法的另一个不同点在于,WordPiece 分词算法并不选择最频繁的词对,而是使用下面的公式为每个词对计算分数:

例如,它不一定会合并(“un”、“##able”),即使这对词在词汇表中出现得很频繁,因为“un”和“###able”这两对词可能都会出现在很多其他单词中,并且频率很高。
相比之下,像(“hu”、“##gging”)这样的一对可能会更快地融合(假设“hugging”一词经常出现在词汇表中),因为 “hu”和“##ggig”单独出现的频率可能较低。 所以(“hu”、“##gging”)词对的得分会比(“un”、“##able”)词对的得分更高,更需要合并。
Unigram分词
与 BPE 分词和 WordPiece 分词不同,Unigram 分词方法从语料库的一组足够大的字符串或词元初始集合开始,迭代地删除其中的词元,直到达到预期的词表大小。
它假设从当前词表中删除某个词元,并计算训练语料的似然增加情况,以此来作为选择标准。这个步骤是基于一个训练好的一元语言模型来进行的。
为估计一元语言模型,它采用期望最大化(Expectation–Maximization, EM)算法:
在每次迭代中,首先基于旧的语言模型找到当前最优的分词方式,然后重新估计一元概率从而更新语言模型。
这个过程中一般使用动态规划算法(即维特比算法,Viterbi Algorithm)来高效地找到语言模型对词汇的最优分词方式。
采用这种分词方法的代表性模型包括 AlBERT、 T5 和 mBART。
如何删减token?
尝试删去一个 token,并计算对应的 unigram loss, 删除 p% 使得 loss 增加最少的 token。

如何将文本切分成token? 假设每个词的出现都是独立的。
我们按照所有的子词划分方式列出,构建基本词表;对所有词进行词频统计,总计为180。
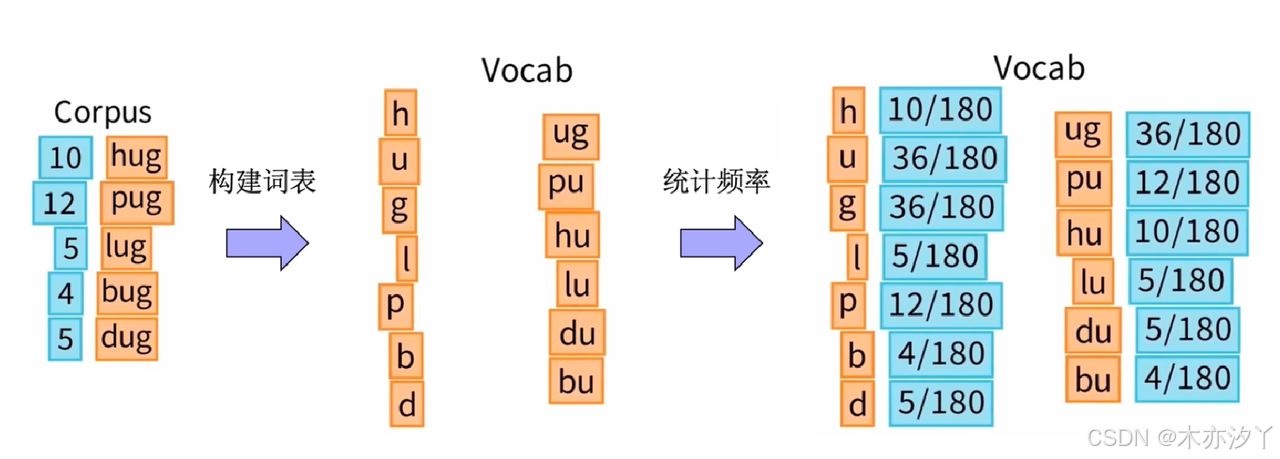
对于语料中的每个词,我们算出每种划分的概率,以hug为例,它有4种划分方式:
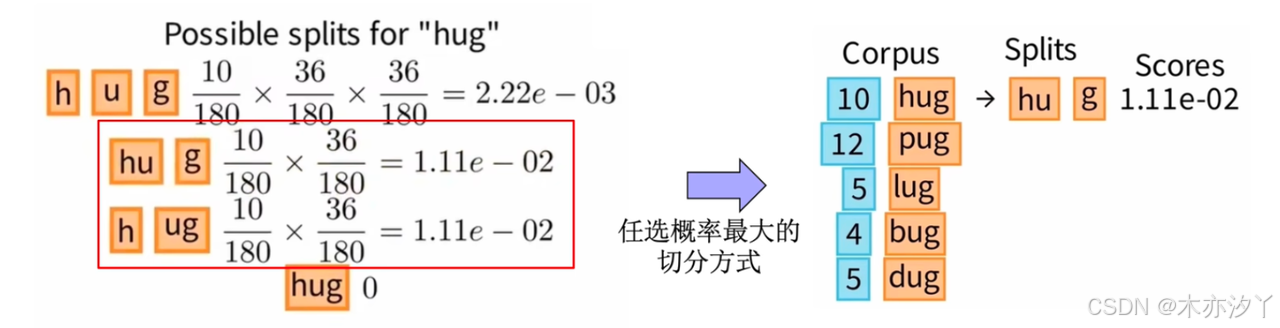
在这四种划分中("hu","g"),("h","ug")这两种概率最大且相等,我们可以任选一种,比如选("hu","g") 。
对于其他词我们也依次类推,就得到了每个词划分的概率。
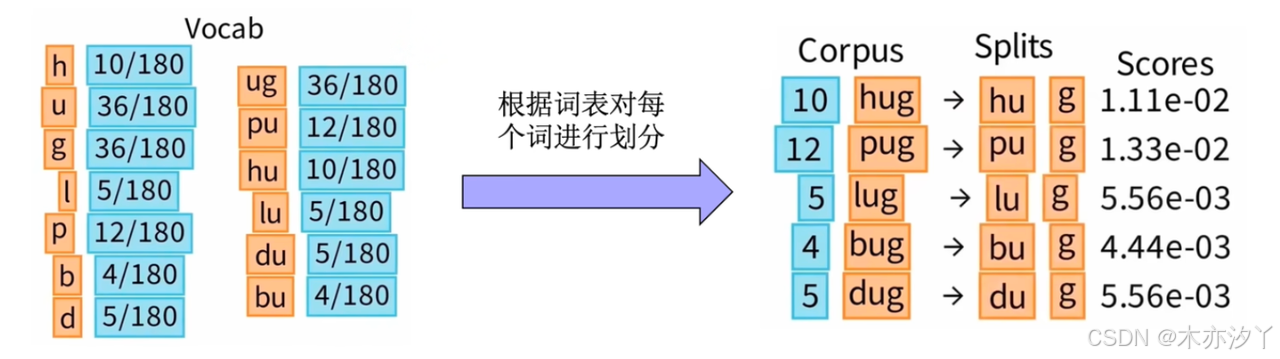
如何计算语料的Unigram loss? 得到Loss = 170.4。

接下来就是对词表进行删减,注意:不删除基本token,如26个字母和标点。
第一次迭代,分别删除"ug"、"pu"、"hu"、"lu"、"du"、"bu",得到Loss都为170.4,这里我们随机删除一个token,如ug;重新计算Vocab。
第二次迭代,分别删除"pu"、"hu"、"lu"、"du"、"bu",得到相应的Loss,假设我们要删除40%的token,则删除"du"、"bu"。
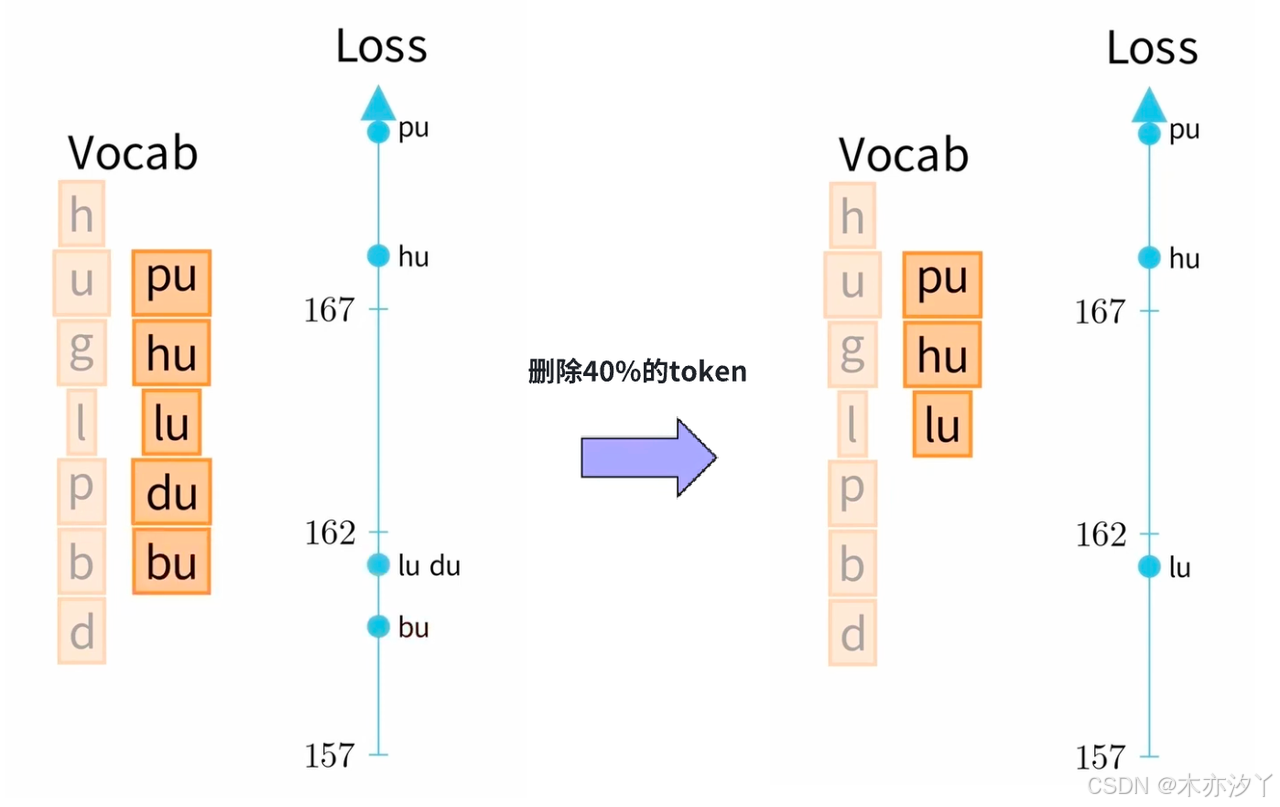
迭代直到词表的大小缩减到预设值;为单词的每种划分计算概率非常耗时,采用更高效的维特比(Viterbi)算法。
五、总结
BPE(字节对编码)
BPE的核心概念是从字母开始,反复合并频率最高且相邻的两个token,直到达到目标词数。
BBPE(字节级字节对编码)
BBPE的基本思想是将BPE从字符级别扩展到字节(Byte)级别。BPE在处理unicode编码时可能会导致基础字符集过大,而BBPE将每个字节视为一个“字符”,不论实际字符集用多少字节表示。这样,基础字符集的大小就固定为256(2^8),从而实现跨语言共享词表,并显著缩减词表大小。然而,对于像中文这样的语言,文本序列长度会显著增加,这可能使得BBPE模型的性能优于BPE模型,但其序列长度较长也会导致训练和推理时间增加。BBPE的实现与BPE类似,主要差别在于基础词表使用256的字节集。
WordPiece
WordPiece算法可视为BPE的变种。不同之处在于,WordPiece通过概率生成新的subword,而不是简单地选择频率最高的字节对。WordPiece每次从词表中选出两个子词合并成一个新子词,但选择的是能最大化语言模型概率的相邻子词。
Unigram
Unigram与BPE和WordPiece在本质上有明显区别。前两者从小词表开始,逐步增加到设定的词汇量,而Unigram则先初始化一个大词表,通过语言模型评估逐步减少词表,直到达到目标词汇量。
虽然直接使用已有的分词器较为方便,但是使用为预训练语料专门训练或设计的分词器会更加有效,尤其是对于那些混合了多领域、多语言和多种格式的语料。最近的大语言模型通常使用SentencePiece 代码库为预训练语料训练定制化的分词器,这一代码库支持字节级别的 BPE 分词和 Unigram 分词。
为了训练出高效的分词器,我们应重点关注以下几个因素。
首先,分词器必须具备无损重构的特性,即其分词结果能够准确无误地还原为原始输入文本。
其次,分词器应具有高压缩率,即在给定文本数据的情况下,经过分词处理后的词元数量应尽可能少,从而实现更为高效的文本编码和存储。
具体来说,压缩比可以通过将原始文本的 UTF-8 字节数除以分词器生成的词元数(即每个词元的平均字节数)来计算:

例如,给定一段大小为1MB(1,048,576字节)的文本,如果它被分词为200,000个词元,其压缩率即为 1,048,576/200,000=5.24。
值得注意的是,在扩展现有的大语言模型(如继续预训练或指令微调)的同时,还需要意识到原始分词器可能无法较好地适配实际需求。
以 LLaMA 为例,它基于主要包含英语文本的预训练语料训练了 BPE 分词器。因此,当处理中文等非英语数据时,该分词器可能表现不佳,甚至可能导致推理延迟的增加。
此外,为进一步提高某些特定能力(如数学能力),还可能需要针对性地设计分词器。例如,BPE 分词器可能将整数 7,481 分词为“7、481”,而将整数 74,815 分词为“74、815”。这导致相同的数字被分割成不同的子串,降低了解决相关数学问题的能力。
相比之下,专门设计基于数字的分词方式可以避免这种不一致性,从而提升大语言模型的数值计算能力。
综上所述,在设计和训练分词器时,我们需要综合考虑多种因素,以确保其在实际应用中能够发挥最佳效果。
🔥🔥🔥 OpenAI、Google、HuggingFace分别都提供了开源的tokenizer工具:tiktoken、sentencepiece、tokenizers,支持主流的分词算法。







