机器学习概述
机器学习即找一个复杂的人类写不出来的函数,把输入(向量,矩阵,序列)转换为输出。
regression:输出是一个数值(预测PM2.5的数值)
classification:选择设置好的类别(是否为垃圾邮件)
structured Lenrning:生成一个有结构的东西
机器学习的三步
假设求今天视频订阅的人数和昨天视频订阅的人数之间有什么关系。
第一步 Function:先设置一个y=wx+b叫做模型
第二步 Define Loss:误差损失L(b,w)
y=wx+b
频道订阅L(0.5k,1)y=1x+0.5k计算出预测值和label的差值e
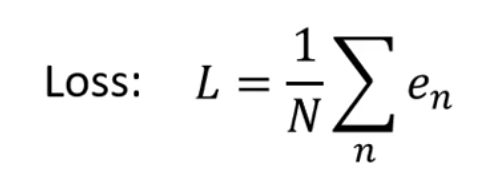
第三步 optimization(最佳化)看看代入哪个数值可以使Loss最小
gradient descent : Loss-w曲线选取一个随机的w0,计算出w=w0时L对W微分,如果为负数增加W,如果为正数减少W,η走的步长自己设置(hyperparameter)W1=W0-η*L对W微分
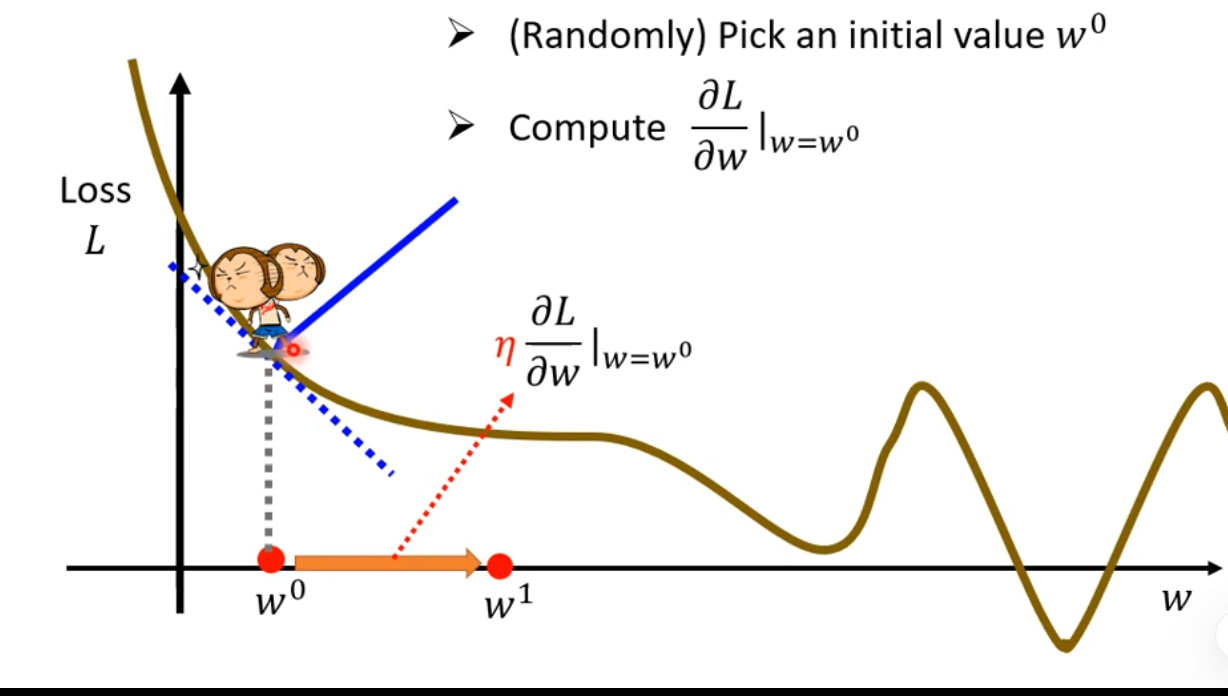
最大的问题时微分为0的时候即看作找到了最佳的点,但是容易为Local minima ,找不到global minima(这种方法为假义的)
这三部叫做Training,只是在已知的数据集合上面去预测,统计2017年到2020年的频道订阅有周期性的原因,只考虑前一天的误差L=0.48k,考虑七天的误差L=0.38k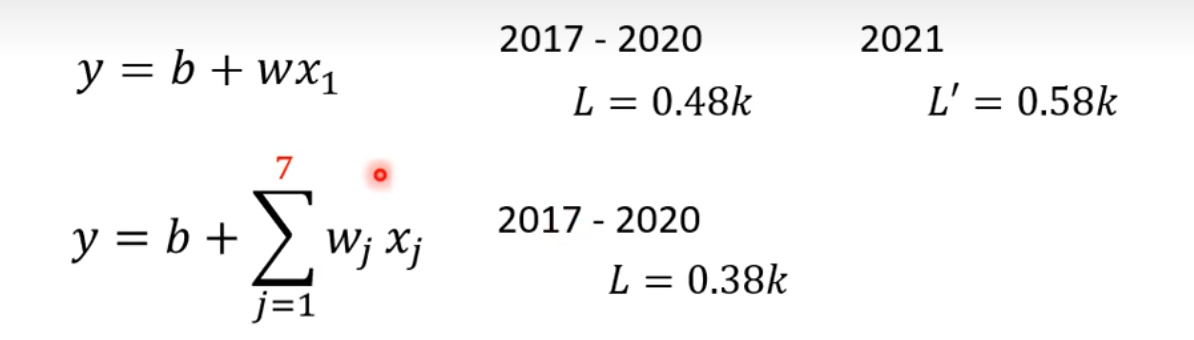
w为斜率,b为截距,这个函数恒为直线,但是现实情况下不一定是直线,这种限制叫Model Bias,我们需要更复杂的方程来做模型,用多条曲线相加去拟合原来的直线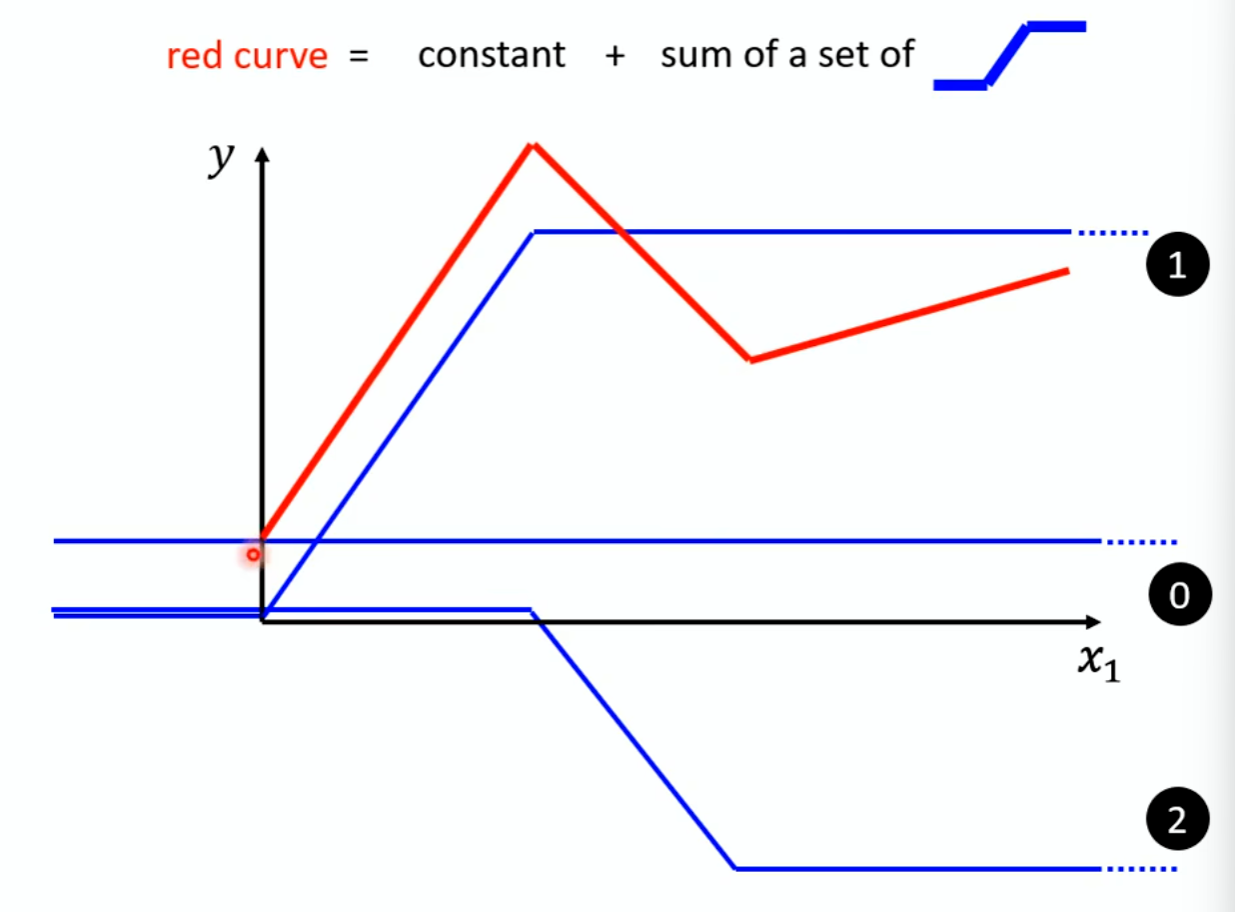
但是很多情况下原来的变化曲线很复杂,要用多条曲线去拟合相加,导致模型很复杂。甚至是原来的完美数据变化图是曲线,要用Sigmoid Function去拟合。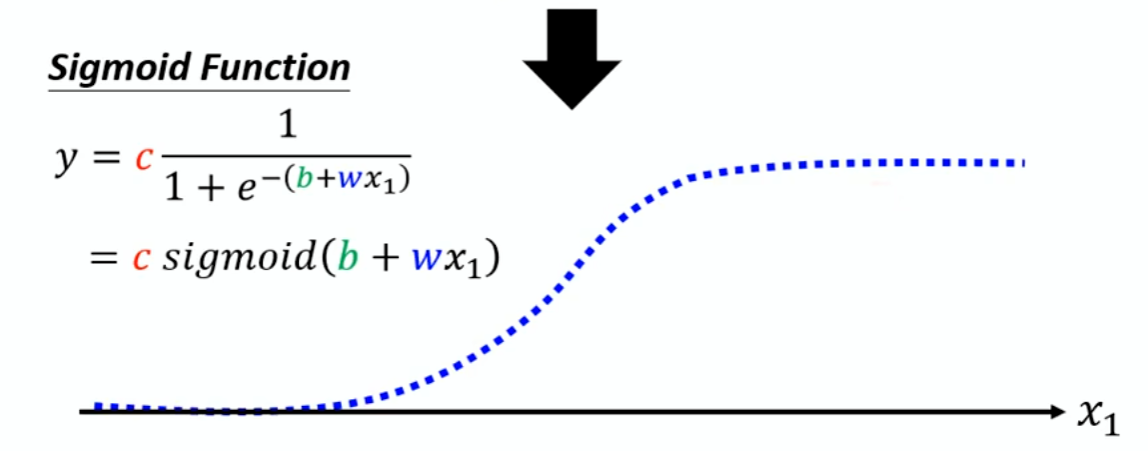
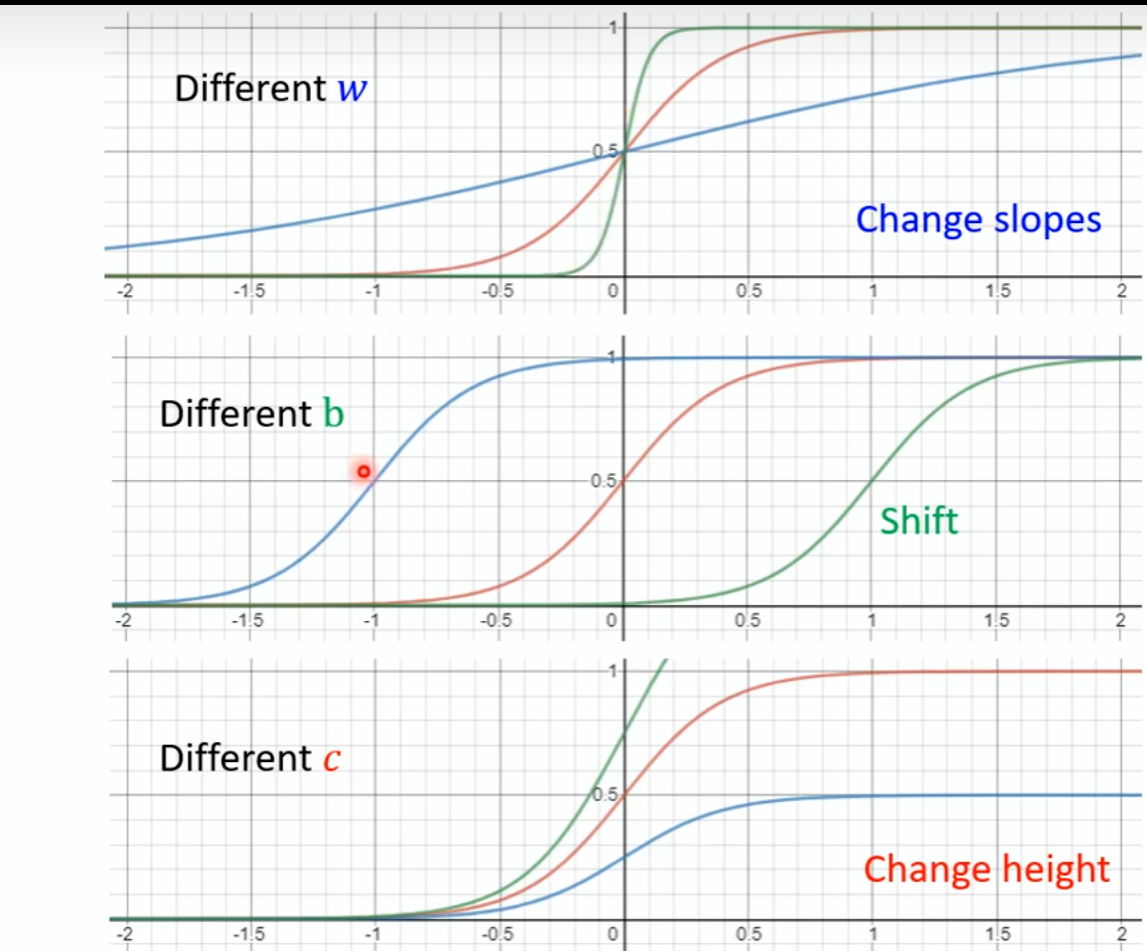
所以原来的相加拟合可以用这个来表示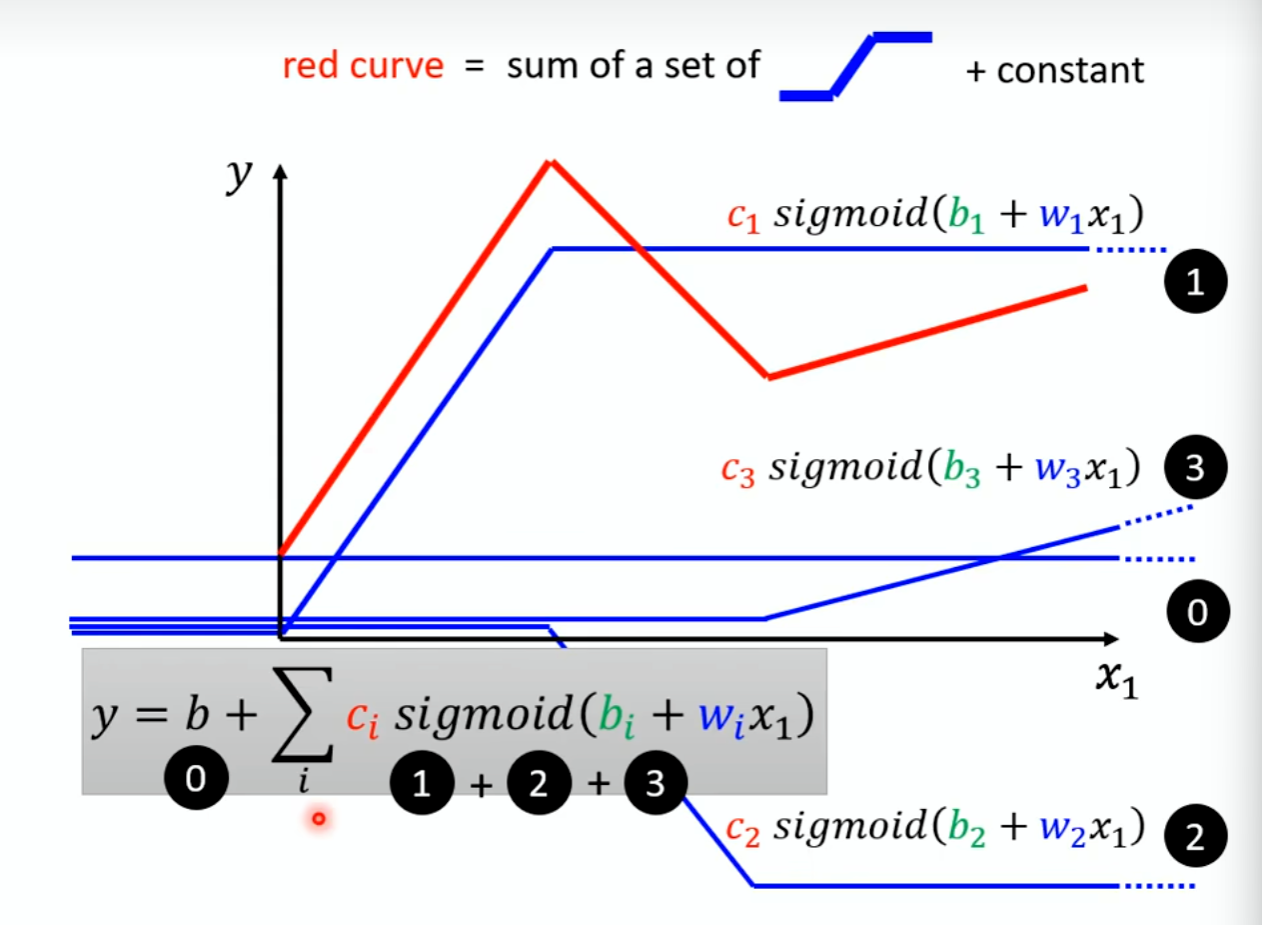
用θ表示所有的未知数,然后去一个θ0求出η,计算出θ1,然后利用batch不断迭代,
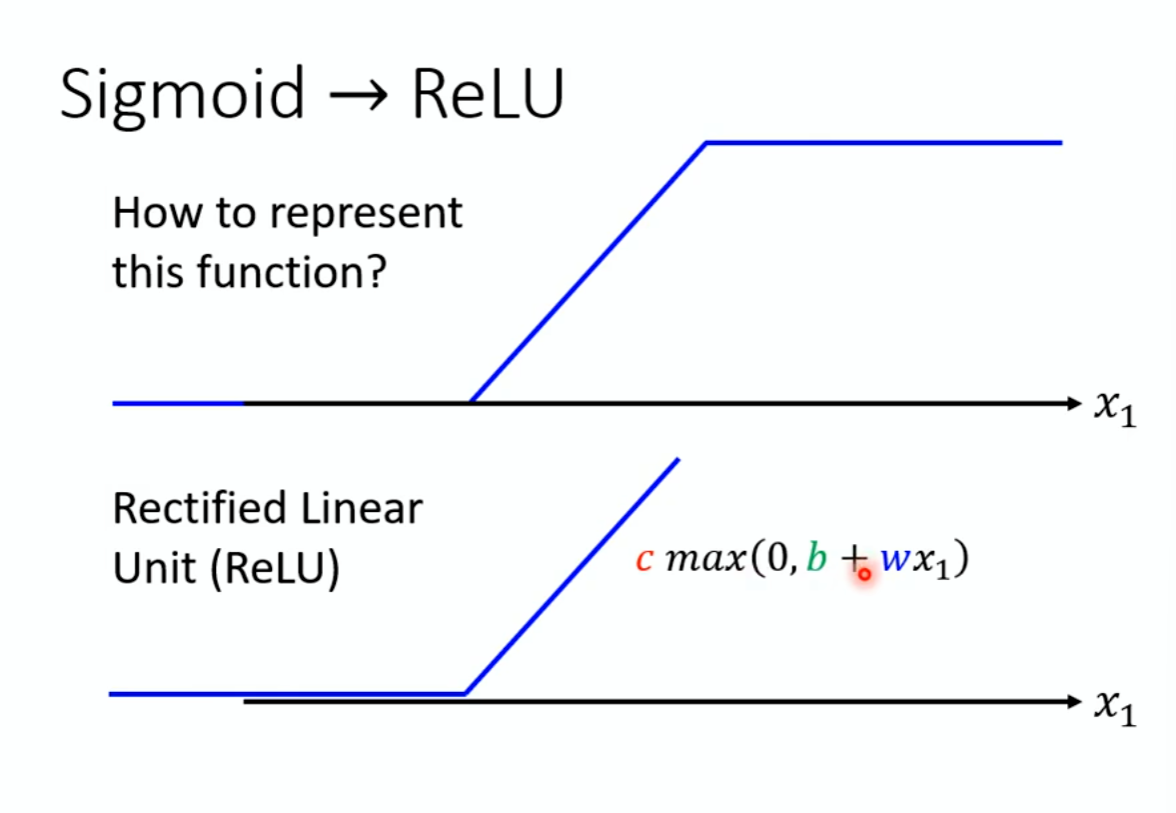
Sigmoid---->ReLU:
两个ReLU叠起来可以代替一个Hard Sigmoid
用很多Sigmoid和ReLU即可构成Neuron,多个Neuron可以构成Neuron Netw(神经元网络),这一整套技术叫做Deep Learning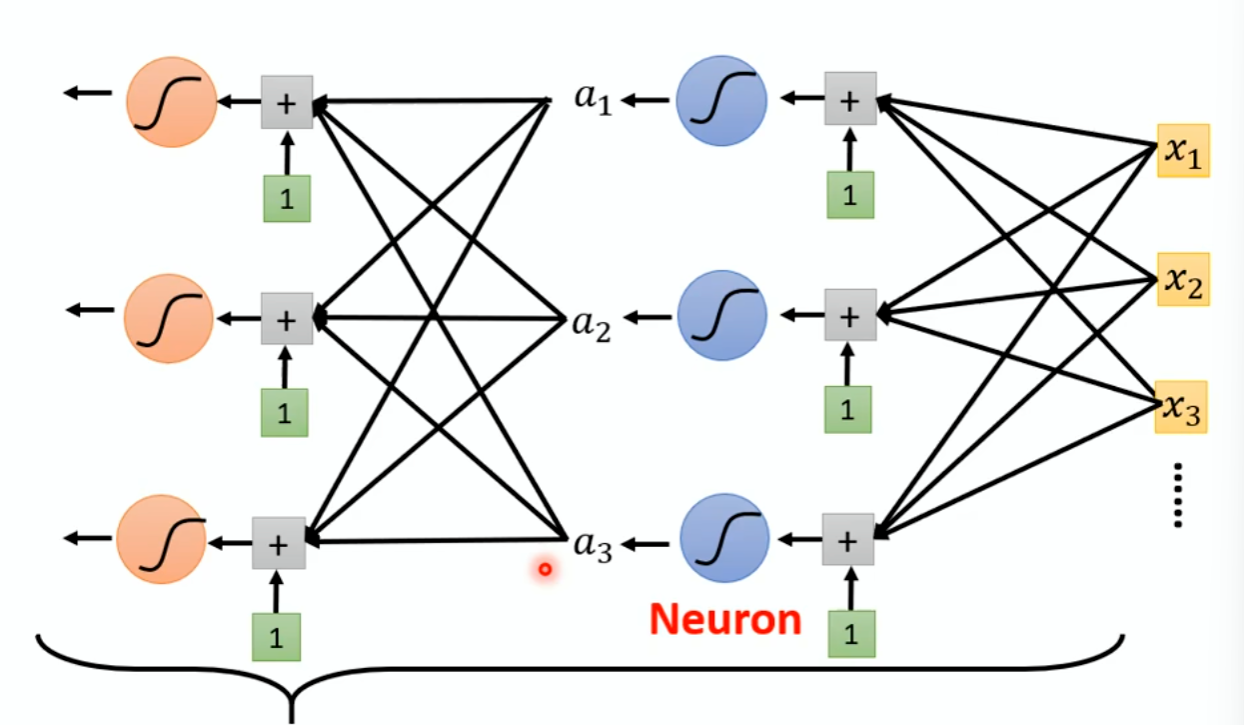
层数过多会发生Overfitting,在测试数据上表现好,在预测数据上表述的差
误差过大有两个原因:Model弹性不足,Optimization不好。为了知道是哪个原因,可以换一个训练资料。先跑一个比较浅的,再跑一个深的,深的弹性更大但是Loss更高,说明Optimization不够好。

先确定根据训练集数据的Loss是不是过大,如果过大考虑Model或者是Optimization,确定了之后考虑测试集上的Loss,如果过大,说明是overfitting(过拟合)或者是mismatch(不协调)
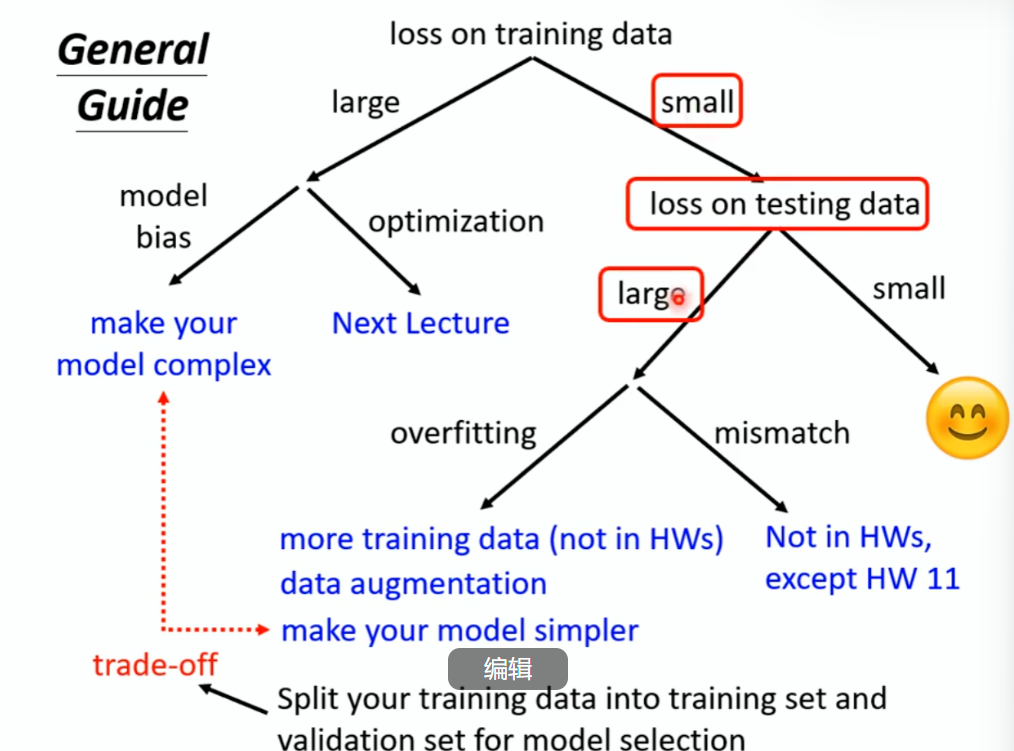
overfitting:减少模型的弹性 ,减少的features,early stop
把数据集分成两部分:Training Set和Validation Set来用为模型的选择
mismatch:





