语音活动检测(Voice Activity Detection,简称VAD)。简单来说,VAD就是用来判断一段音频里有没有人说话的技术。在实时语音识别的场景里,这个技术特别重要,因为它决定了什么时候把采集到的音频数据扔进大模型里处理。
但问题来了:怎么精准判断“最佳时机”呢?用如果固定时间间隔的方法,问题就大了——间隔太短,模型会频繁启动,浪费算力,还抓不住完整的一句话;间隔太长,文字输出就会拖拖拉拉,用户体验直接崩掉。
为了解决这个难题,大家常用webrtcvad库里的VAD_MODE方法。它通过分析音频的波动特征,智能判断有没有人说话,然后触发语音识别流程。这个方法在安静环境下表现不错,但实际测试发现,它在复杂环境里(比如白噪音很大或者特别安静的场景)灵敏度不够,根本做不到真正的自适应识别。
所以,需要换个思路!把声波能量检测、VAD和频谱分析这三兄弟结合起来,通过验证多重机制,精准判断音频里有没有有效语音活动。这样不仅能大幅提升语音信号捕捉的准确性,还能把背景噪音过滤掉,确保输出的文字又快又准。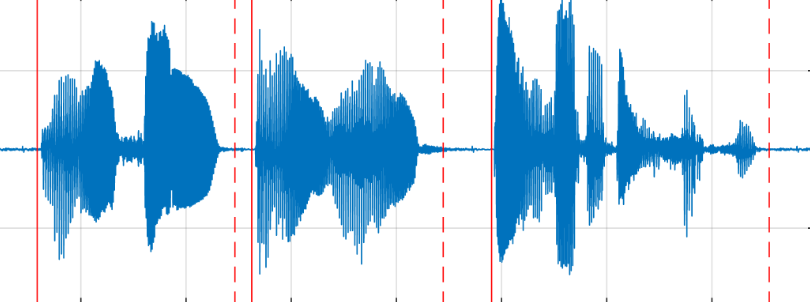
下面是基于这三种技术的语音检测系统代码实现,能实时判断音频里有没有语音活动。一步一步拆开看:
1. 参数配置
-
AUDIO_RATE:音频采样率(16000 Hz),决定了音频的频率分辨率。 -
CHUNK_SIZE:每次处理的音频块大小(480 采样点),对应 30 毫秒的音频数据。 -
VAD_MODE:VAD 模式(0-3),数值越小越保守,用于控制语音活动检测的灵敏度。
# 参数配置
AUDIO_RATE = 16000 # 采样率:16000(支持8000, 16000, 32000或48000)
CHUNK_SIZE = 480 # 每块大小(30ms,保证为10/20/30ms的倍数)
VAD_MODE = 1 # VAD模式(0-3,数值越小越保守)2. 初始化 VAD
-
使用
webrtcvad库的Vad类,初始化语音活动检测器。
# 初始化VAD
vad = webrtcvad.Vad(VAD_MODE)3. SpeechDetector 类
这是代码的核心部分,封装了语音检测的逻辑。
(1) 初始化
-
calibration_seconds:校准背景噪音所需时间(默认 2 秒)。 -
chunk_duration_ms:每块音频的时长(默认 30 毫秒)。 -
calibrated:标记是否完成背景噪音校准。 -
amplitude_threshold:背景噪音的自适应阈值。 -
speech_state:当前状态(语音活动或非语音活动)。 -
consecutive_speech和consecutive_silence:连续语音帧和静音帧的计数器。 -
required_speech_frames和required_silence_frames:用于状态转换的阈值(例如,连续 3 帧语音确认进入语音状态)。
(2) 校准背景噪音
-
calibrate方法:-
录制固定时长的背景噪音(默认 2 秒),计算音频的平均幅值和标准差。
-
设置自适应阈值为 均值 + 2×标准差,用于后续的能量检测。
-
校准完成后,
calibrated标记为True。
-
(3) 频谱分析
-
analyze_spectrum方法:-
对音频块应用 汉宁窗 减少频谱泄漏。
-
计算 FFT(快速傅里叶变换)得到频谱。
-
统计频谱中超过均值 1.5 倍的局部峰值数量。
-
如果峰值数量大于等于 3,则认为该音频块具有语音特征。
-
(4) 综合判断
-
is_speech方法:-
能量检测:通过幅值均值与阈值比较,过滤低能量数据。
-
VAD 检测:使用
webrtcvad判断是否为语音活动。 -
频谱检测:通过频谱分析进一步验证语音特性。
-
只有当 能量检测、VAD 和频谱分析 三者同时满足时,才认为当前音频块为语音。
-
(5) 状态平滑
-
process_chunk方法:-
对每一块音频数据进行综合判断。
-
使用 连续帧策略 避免短时噪音导致的误判:
-
如果连续检测到语音活动(
required_speech_frames帧),则确认进入语音状态。 -
如果连续检测到静音(
required_silence_frames帧),则确认退出语音状态。
-
-
class SpeechDetector:def __init__(self, calibration_seconds=2, chunk_duration_ms=30):"""calibration_seconds: 校准背景噪音所需时间(秒)chunk_duration_ms: 每块时长(毫秒)"""self.calibration_seconds = calibration_secondsself.chunk_duration_ms = chunk_duration_msself.calibrated = Falseself.amplitude_threshold = None# 连续帧判决参数(降低短时噪音误判)self.speech_state = False # 当前状态:True为语音,False为无语音self.consecutive_speech = 0 # 连续语音帧计数self.consecutive_silence = 0 # 连续静音帧计数self.required_speech_frames = 3 # 连续3帧语音后确认进入语音状态(约90ms)self.required_silence_frames = 5*5 # 750ms 连续5帧静音后退出语音状态(约150ms)def calibrate(self, stream):"""校准背景噪音:录制固定时长音频,计算平均幅值与标准差,从而设置自适应阈值"""print("开始校准背景噪音,请保持安静...")amplitudes = []num_frames = int(self.calibration_seconds * (1000 / self.chunk_duration_ms))for _ in range(num_frames):audio_chunk = stream.read(CHUNK_SIZE, exception_on_overflow=False)audio_data = np.frombuffer(audio_chunk, dtype=np.int16)amplitudes.append(np.abs(audio_data).mean())mean_noise = np.mean(amplitudes)std_noise = np.std(amplitudes)# 阈值设置为均值加2倍标准差self.amplitude_threshold = mean_noise + 2 * std_noiseprint(f"校准完成:噪音均值={mean_noise:.2f},标准差={std_noise:.2f},设置阈值={self.amplitude_threshold:.2f}")self.calibrated = Truedef analyze_spectrum(self, audio_chunk):"""通过频谱分析检测语音特性:1. 对音频块应用汉宁窗后计算 FFT2. 统计局部峰值数量(峰值必须超过均值的1.5倍)3. 当峰值数量大于等于设定阈值时,认为该块具有语音特征"""audio_data = np.frombuffer(audio_chunk, dtype=np.int16)if len(audio_data) == 0:return False# 使用汉宁窗减少FFT泄露window = np.hanning(len(audio_data))windowed_data = audio_data * window# FFT计算得到频谱(只需正频率部分)spectrum = np.abs(np.fft.rfft(windowed_data))# 使用均值作为参考,统计超过均值1.5倍的局部峰值数量spectral_mean = np.mean(spectrum)peak_count = 0for i in range(1, len(spectrum) - 1):if spectrum[i] > spectrum[i - 1] and spectrum[i] > spectrum[i + 1] \and spectrum[i] > spectral_mean * 1.5:peak_count += 1# 参数阈值:这里设定至少需要3个峰值(可根据实际情况调整)return peak_count >= 3def is_speech(self, audio_chunk):"""综合判断:先通过能量预处理(阈值)过滤低能量数据,再利用VAD和频谱分析判断语音。两者结合能有效降低噪音导致的误判。"""# 使用背景校准得到的阈值(若未校准则取较低默认值)amplitude_threshold = self.amplitude_threshold if self.amplitude_threshold is not None else 500# 能量检测audio_data = np.frombuffer(audio_chunk, dtype=np.int16)amplitude = np.abs(audio_data).mean()if amplitude < amplitude_threshold:return False# VAD检测vad_result = vad.is_speech(audio_chunk, AUDIO_RATE)# 频谱检测spectral_result = self.analyze_spectrum(audio_chunk)# 仅当两种检测均为True时,认为当前块为语音return vad_result and spectral_resultdef process_chunk(self, audio_chunk):"""对每一块数据进行处理:综合能量检测、VAD、频谱分析,并采用连续帧策略实现状态平滑。"""is_speech_chunk = self.is_speech(audio_chunk)# 连续帧计数策略if is_speech_chunk:self.consecutive_speech += 1self.consecutive_silence = 0else:self.consecutive_silence += 1self.consecutive_speech = 0# 状态转换逻辑if not self.speech_state and self.consecutive_speech >= self.required_speech_frames:self.speech_state = Trueprint("Detected Speech")elif self.speech_state and self.consecutive_silence >= self.required_silence_frames:self.speech_state = Falseprint("No speech")4. 主程序
-
初始化音频流:使用
pyaudio打开麦克风输入流。 -
校准背景噪音:在程序启动时调用
calibrate方法。 -
实时监听:进入循环,逐块处理音频数据,检测语音活动。
-
退出机制:通过键盘中断(Ctrl+C)停止程序。
p = pyaudio.PyAudio()stream = p.open(format=pyaudio.paInt16,channels=1,rate=AUDIO_RATE,input=True,frames_per_buffer=CHUNK_SIZE)detector = SpeechDetector()# 校准背景噪音(建议在程序启动时进行)detector.calibrate(stream)print("开始监听,请开始说话...(按Ctrl+C停止)")try:while True:audio_chunk = stream.read(CHUNK_SIZE, exception_on_overflow=False)detector.process_chunk(audio_chunk)except KeyboardInterrupt:print("停止监听")finally:stream.stop_stream()stream.close()p.terminate()完整代码
import pyaudio
import webrtcvad
import numpy as np# 参数配置
AUDIO_RATE = 16000 # 采样率:16000(支持8000, 16000, 32000或48000)
CHUNK_SIZE = 480 # 每块大小(30ms,保证为10/20/30ms的倍数)
VAD_MODE = 1 # VAD模式(0-3,数值越小越保守)# 初始化VAD
vad = webrtcvad.Vad(VAD_MODE)class SpeechDetector:def __init__(self, calibration_seconds=2, chunk_duration_ms=30):"""calibration_seconds: 校准背景噪音所需时间(秒)chunk_duration_ms: 每块时长(毫秒)"""self.calibration_seconds = calibration_secondsself.chunk_duration_ms = chunk_duration_msself.calibrated = Falseself.amplitude_threshold = None# 连续帧判决参数(降低短时噪音误判)self.speech_state = False # 当前状态:True为语音,False为无语音self.consecutive_speech = 0 # 连续语音帧计数self.consecutive_silence = 0 # 连续静音帧计数self.required_speech_frames = 3 # 连续3帧语音后确认进入语音状态(约90ms)self.required_silence_frames = 5*5 # 750ms 连续5帧静音后退出语音状态(约150ms)def calibrate(self, stream):"""校准背景噪音:录制固定时长音频,计算平均幅值与标准差,从而设置自适应阈值"""print("开始校准背景噪音,请保持安静...")amplitudes = []num_frames = int(self.calibration_seconds * (1000 / self.chunk_duration_ms))for _ in range(num_frames):audio_chunk = stream.read(CHUNK_SIZE, exception_on_overflow=False)audio_data = np.frombuffer(audio_chunk, dtype=np.int16)amplitudes.append(np.abs(audio_data).mean())mean_noise = np.mean(amplitudes)std_noise = np.std(amplitudes)# 阈值设置为均值加2倍标准差self.amplitude_threshold = mean_noise + 2 * std_noiseprint(f"校准完成:噪音均值={mean_noise:.2f},标准差={std_noise:.2f},设置阈值={self.amplitude_threshold:.2f}")self.calibrated = Truedef analyze_spectrum(self, audio_chunk):"""通过频谱分析检测语音特性:1. 对音频块应用汉宁窗后计算 FFT2. 统计局部峰值数量(峰值必须超过均值的1.5倍)3. 当峰值数量大于等于设定阈值时,认为该块具有语音特征"""audio_data = np.frombuffer(audio_chunk, dtype=np.int16)if len(audio_data) == 0:return False# 使用汉宁窗减少FFT泄露window = np.hanning(len(audio_data))windowed_data = audio_data * window# FFT计算得到频谱(只需正频率部分)spectrum = np.abs(np.fft.rfft(windowed_data))# 使用均值作为参考,统计超过均值1.5倍的局部峰值数量spectral_mean = np.mean(spectrum)peak_count = 0for i in range(1, len(spectrum) - 1):if spectrum[i] > spectrum[i - 1] and spectrum[i] > spectrum[i + 1] \and spectrum[i] > spectral_mean * 1.5:peak_count += 1# 参数阈值:这里设定至少需要3个峰值(可根据实际情况调整)return peak_count >= 3def is_speech(self, audio_chunk):"""综合判断:先通过能量预处理(阈值)过滤低能量数据,再利用VAD和频谱分析判断语音。两者结合能有效降低噪音导致的误判。"""# 使用背景校准得到的阈值(若未校准则取较低默认值)amplitude_threshold = self.amplitude_threshold if self.amplitude_threshold is not None else 500# 能量检测audio_data = np.frombuffer(audio_chunk, dtype=np.int16)amplitude = np.abs(audio_data).mean()if amplitude < amplitude_threshold:return False# VAD检测vad_result = vad.is_speech(audio_chunk, AUDIO_RATE)# 频谱检测spectral_result = self.analyze_spectrum(audio_chunk)# 仅当两种检测均为True时,认为当前块为语音return vad_result and spectral_resultdef process_chunk(self, audio_chunk):"""对每一块数据进行处理:综合能量检测、VAD、频谱分析,并采用连续帧策略实现状态平滑。"""is_speech_chunk = self.is_speech(audio_chunk)# 连续帧计数策略if is_speech_chunk:self.consecutive_speech += 1self.consecutive_silence = 0else:self.consecutive_silence += 1self.consecutive_speech = 0# 状态转换逻辑if not self.speech_state and self.consecutive_speech >= self.required_speech_frames:self.speech_state = Trueprint("Detected Speech")elif self.speech_state and self.consecutive_silence >= self.required_silence_frames:self.speech_state = Falseprint("No speech")def main():p = pyaudio.PyAudio()stream = p.open(format=pyaudio.paInt16,channels=1,rate=AUDIO_RATE,input=True,frames_per_buffer=CHUNK_SIZE)detector = SpeechDetector()# 校准背景噪音(建议在程序启动时进行)detector.calibrate(stream)print("开始监听,请开始说话...(按Ctrl+C停止)")try:while True:audio_chunk = stream.read(CHUNK_SIZE, exception_on_overflow=False)detector.process_chunk(audio_chunk)except KeyboardInterrupt:print("停止监听")finally:stream.stop_stream()stream.close()p.terminate()if __name__ == "__main__":main()




)

