目录
怎么把一张影响当成一个模型输入?
同样的 pattern出现在图片不同的位置。
第三个问题:Pooling:
阿尔法Go是怎么下围棋的:
CNN不能处理的问题
CNN专门用在影像辨识方面
怎么把一张影响当成一个模型输入?
一张图像相当于一个三维的Tensor,看成三维的矩阵,长宽channels。识别一个图像的时候,没必要全部都看,只需要每一个neural 只观察一个自己的pattern就行了,构建这个neural自己的receipt file矩阵,可以自己设计多维矩阵的边长。一般设计kernel size为3×3、all channels。测量完一个receipt file之后移动下一个stride(一般设计的很小,因为希望测定每一个地区扫过每一个地方)个位置测定下一个receipt file,如果边边位置不够超出范围了也要考虑,超出的部分padding。
同样的 pattern出现在图片不同的位置。
比如说鸟嘴出现在不同地方。如果每个地方都有一个侦测鸟嘴的neural的话其实是不影响的。但是真的要在每个地方都放一个侦测鸟嘴的neural吗?这样的话参数会太多了。能不能让每个neural共享参数。每个receipt file都只有一组参数,每个receipt file的每个neural共用一个参数,叫做filter1...
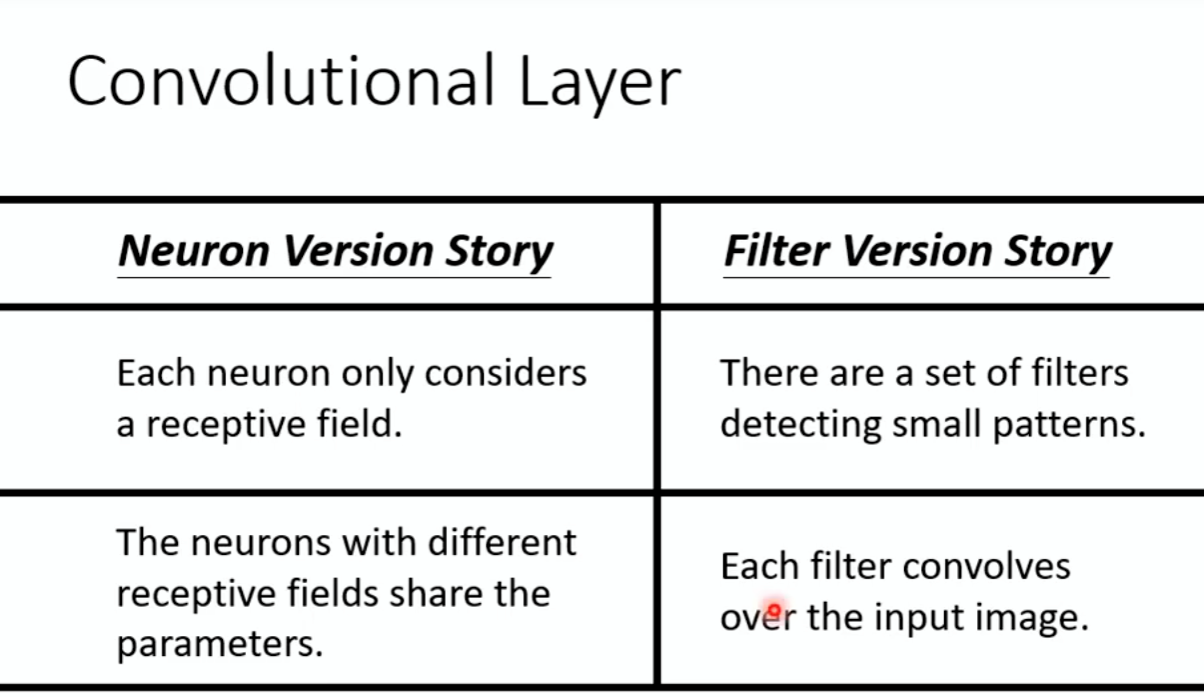
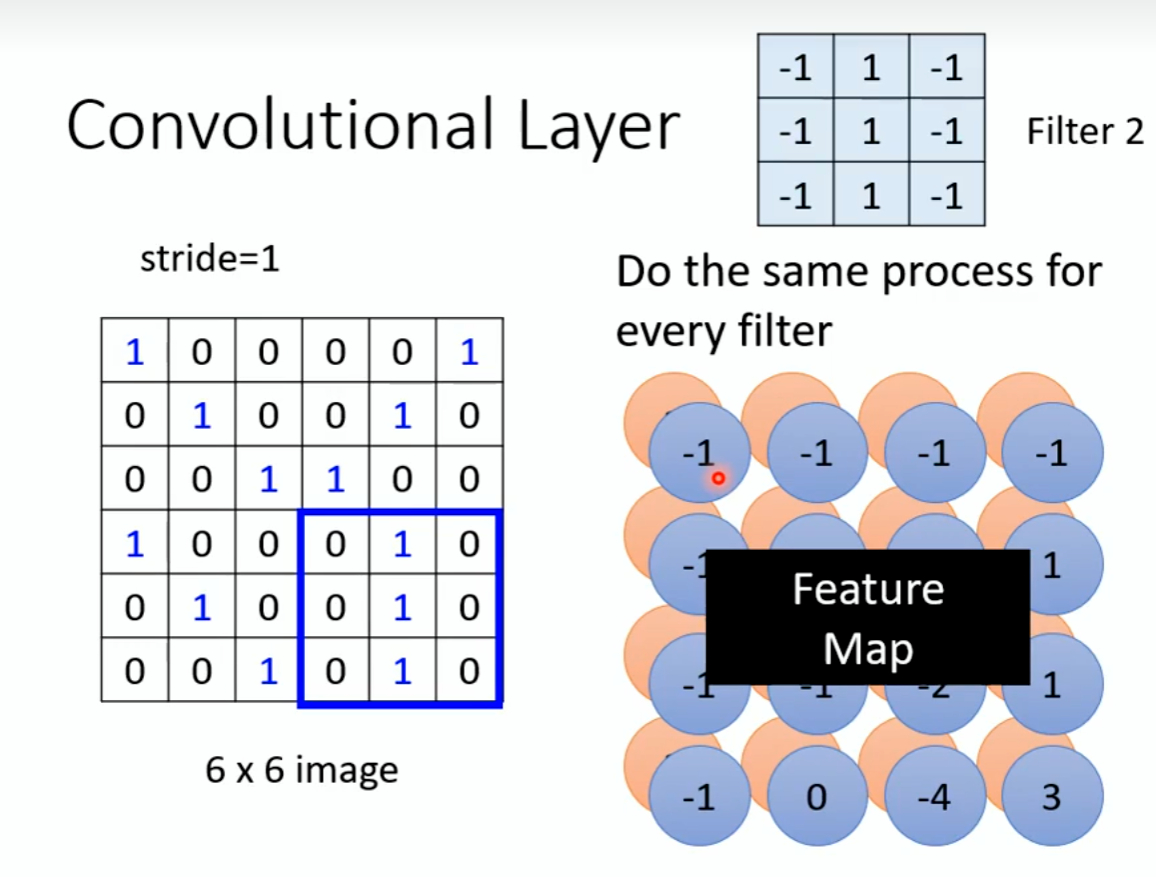
Filter和图片矩阵相乘,再相加,移动stride个位置,一直计算。组成了新的矩阵,然后再进行3×3的矩阵相乘。
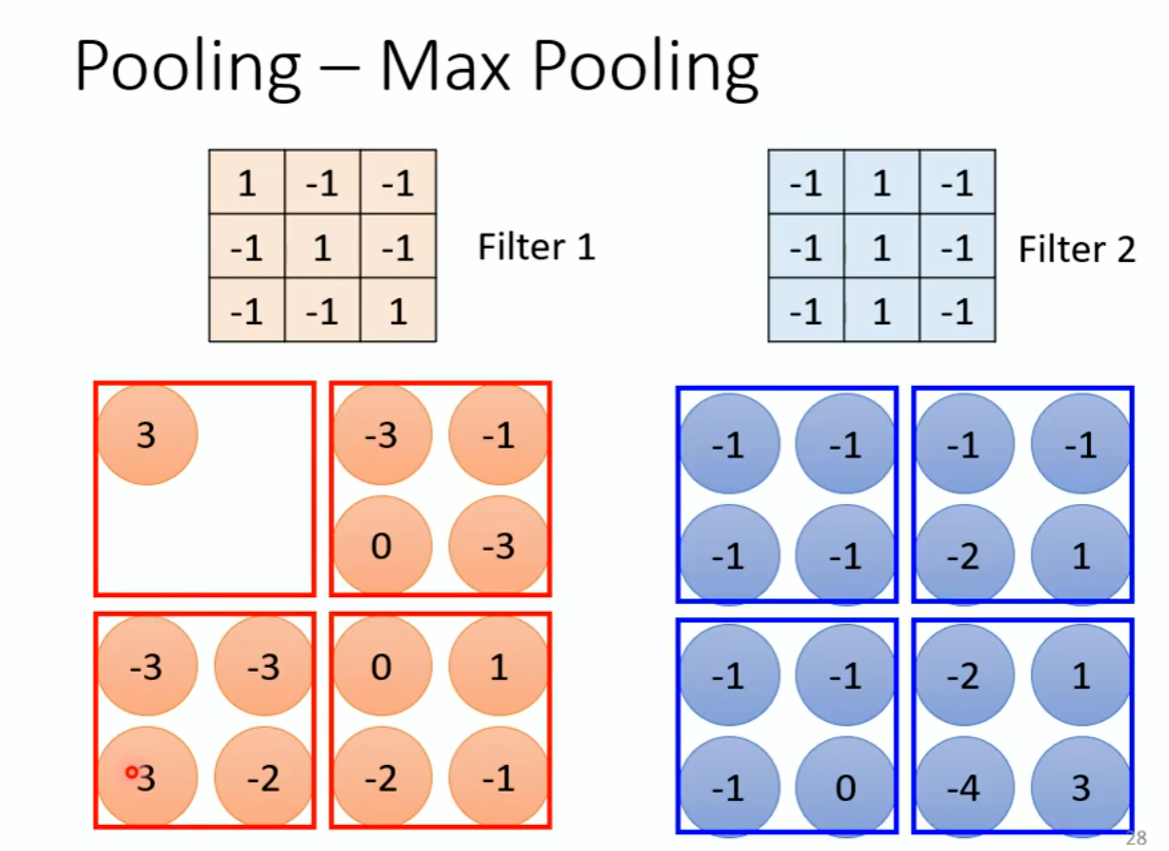
第三个问题:Pooling:
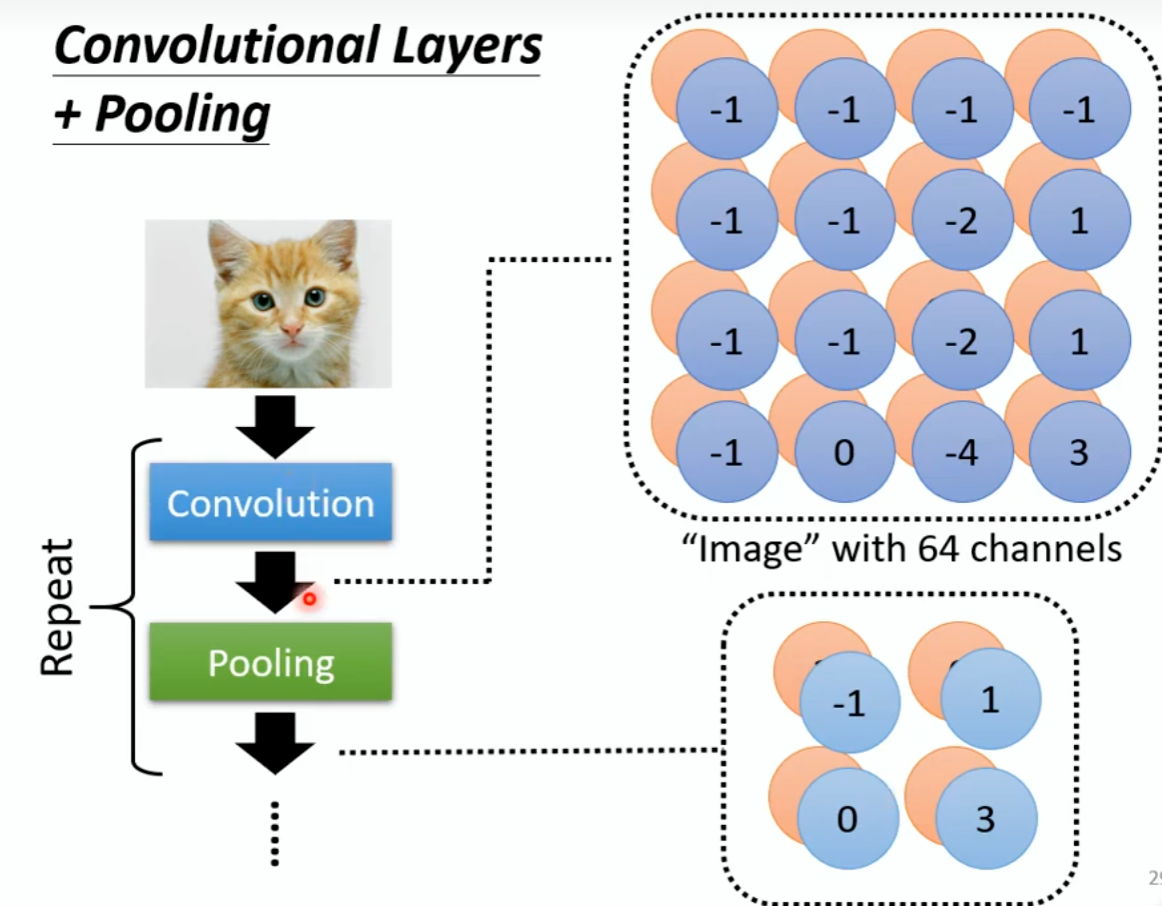
图片是一只鸟,缩小图片之后还是一只鸟。每个filter产生数字,Max Pooling是2×2在这个范围内选择最大的数字,相当于把图片变小。通常是Convolution和Pooling一层一层的循环往复的使用。
阿尔法Go是怎么下围棋的:
把围棋的棋盘看成一个19×19的图片,不使用Pooling。
CNN不能处理的问题
影像放大缩小和旋转的问题,训练完成之后如果把照片放大,CNN会识别不出来。这里可以用到data implementation你可以把自己输入的影响自动放大缩小旋转翻转。




