一个很简单的机器学习任务
前言
基于线上colab做的一个简单的案例,应用了线性回归算法,预测了大概加州3000多地区的房价中位数
过程
先导入了Pandas,这是一个常见的Python数据处理函数库
用Pandas的read_csv函数把网上一个共享数据集(csv文件)读入DataFrame数据结构df_housing
这个文件是加州某个时期的房价数据集
用DataFrame数据结构的head方法显示数据集中的部分信息
import pandas as pd
df_housing = pd.read_csv("https://raw.githubusercontent.com/huangjia2019/house/master/house.csv")
df_housing.head()
结果如下
在这里插入图片描述
然后构建特征集x和特征集y
x = df_housing.drop("median_house_value",axis=1) #构建特征集x
y = df_housing.median_house_value #构建特征集y
现在把数据集一分为二,80%用于机器训练(训练数据集),剩下的留着做测试(测试数据集)
from sklearn.model_selection import train_test_split #导入sklearn工具库
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=0) #以80%/20%的比例进行数据集的拆分
接下来开始训练机器,首先选择模型的类型,也就是算法
然后通过其中的fit方法来训练机器,进行函数的拟合
拟合意味着找到最优的函数去模拟训练集中的输入(特征)和目标(标签)的关系,这是确定模型的参数
from sklearn.linear_model import LinearRegression #导入线性回归算法模型
model = LinearRegression() #确定线性回归算法
model.fit(x_train,y_train) #根据训练集数据,训练机器,拟合函数
y_pred = model.predict(x_test) #预测验证集的y值
print('房价的真值(测试集)',y_test)
print('预测的真值(测试集)',y_pred)
显示预测可以多少评分
print('给预测评分',model.score(x_test,y_test)) #评估预测分数
也可以画出来
import matplotlib.pyplot as plt
#用散点图显示家庭收入中位数和房价中位数的分布
plt.scatter(x_test.median_income,y_test,color='brown')
#画出回归函数(从特征到预测标签)
plt.plot(x_test.median_income,y_pred,color='blue',linewidth=2)
plt.xlabel('median Income')
plt.ylabel('median House Value')
plt.show()
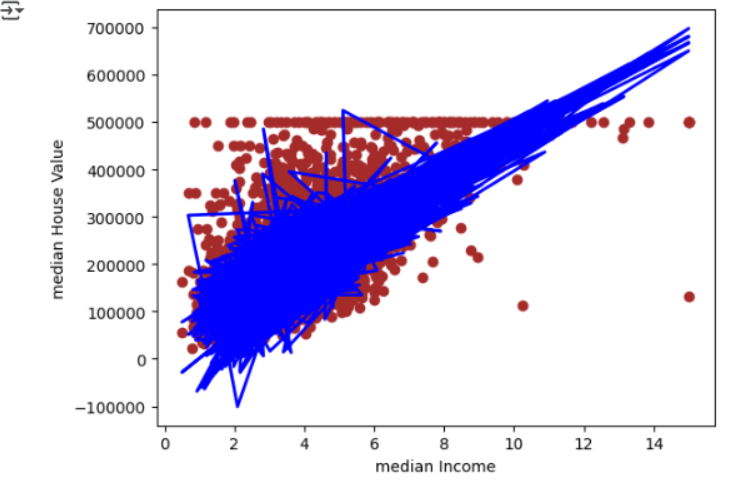
可以看出各个地区的平均房价中位数有随该地区家庭收入中位数的上升而增加的趋势,而机器学习到的函数也同意体现了着一点
后记
学习产出记录
)



)
