创建数据库
语法很简单, 主要是看看选项(与编码相关的):
CREATE DATABASE [IF NOT EXISTS] db_name [create_specification [,
create_specification] ...]
create_specification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name1. 语句中大写的是关键字
2. [] 内的是可选项
3. CHARACTER SET: 指定数据库采用的字符集
4. COLLATE: 指定数据库字符集的校验规则
1. 创建一个数据库最简单的命令为: create database db_name; --本质是在/var/lib/mysql/下创建一个目录:
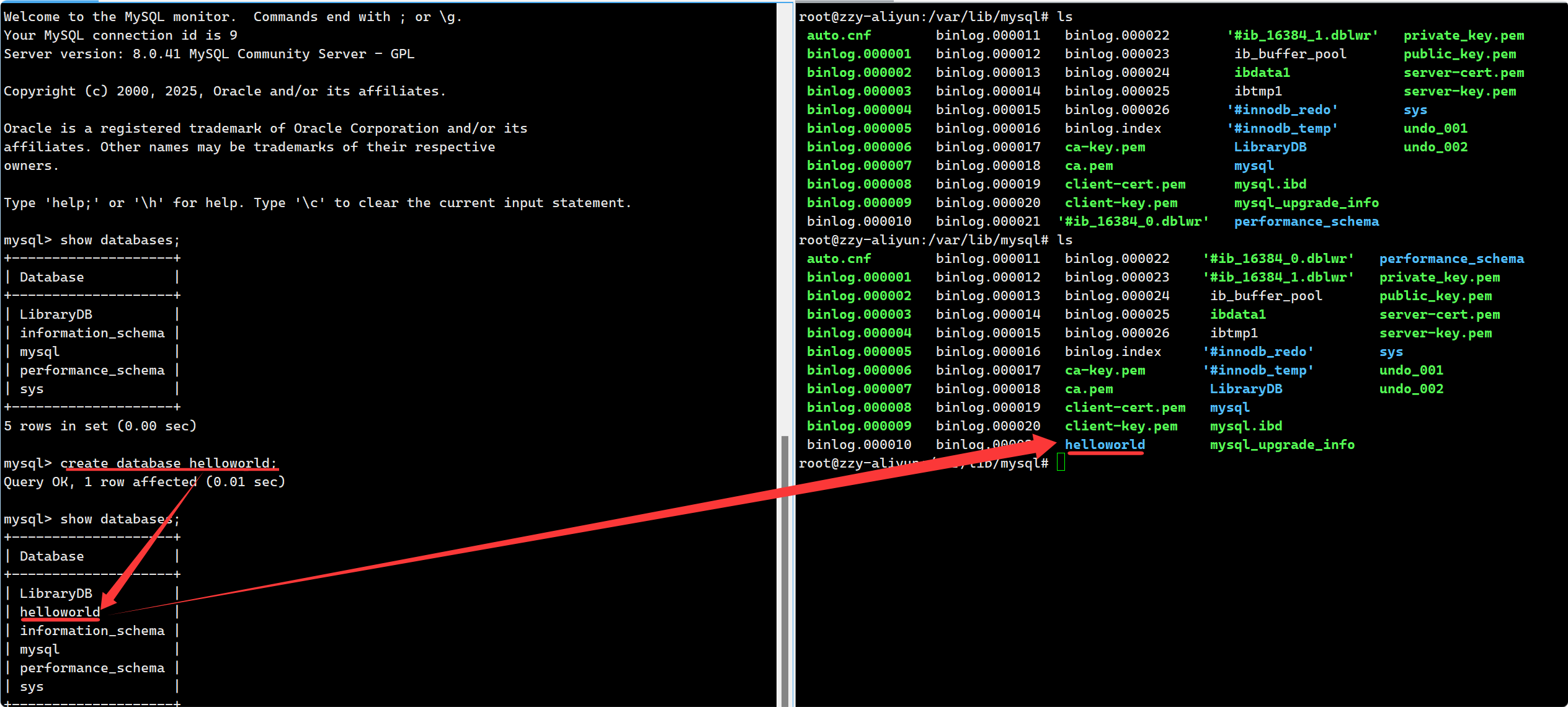
反过来, 在 mysql5.5下, 手动在该目录下创建一个目录, mysql 可以查询到对应目录名的数据库. 但不应该这样创建数据库. 在 mysql 8 这样做就不行了, 因为它采用 data dictionary(数据字典)去维护数据库.
2. create database if not exist db_name, 如果要创建的数据库存在就不创建, 已经存在的数据库没有必要创建.

3. 数据库编码问题, 创建数据库时有两个编码集: 数据库字符集和数据库校验集
1. 数据库字符集(编码集) 是 未来存储数据用的字符集
2. 数据库校验集 是 为了支持数据库进行字段比较所使用的编码, 本质是一种读取数据库中数据所采用的编码格式.
因此, 无论数据库对数据做任何操作, 都必须保证操作和编码是一致的.
a. 当我们创建数据库没有指定字符集和校验规则时, 系统使用默认字符集: utf8, 校验规则是:utf8_ general_ ci. 这里我们的 my.cnf 配置为了 character-set-server=utf8mb4, 所以 mysql 的默认字符集以及校验规则为: utf8mb4 和 utf8mb4_0900_ai_ci.
MySQL 在早期(如 5.5 及更早)中的
utf8实际指的是utf8mb3,它无法存储某些 Unicode 字符,utf8mb4 是UTF-8完全体, 支持所有 Unicode 字符(包括 emoji, 部分罕见汉字等)
查看系统默认字符集以及校验规则:
show variables like 'character_set_database';
show variables like 'collation_database';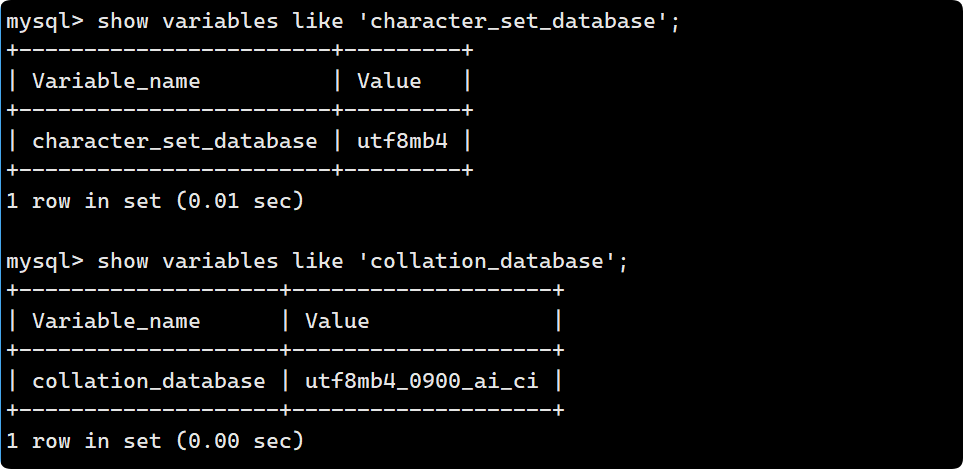
查看数据库支持的字符集和字符集校验规则:
show charset;
show collation;show charset 的部分条目:

b. 现在我们可以手动创建两个数据库:
create database d1;
create database d2 charset=gbk colloate gbk_chinese_ci;注意这里 charset=gbk 可以写成 character set gbk
了解: MYSQL 5.5 下可以通过 cat /var/lib/mysql/db_name/db.opt 去查看数据库的配置选项. 而MySQL 8.0 中, 关于数据库的配置信息(如字符集和校验规则)现在存储在 数据字典表 mysql.schema 中, 该表存储了数据库的元数据:
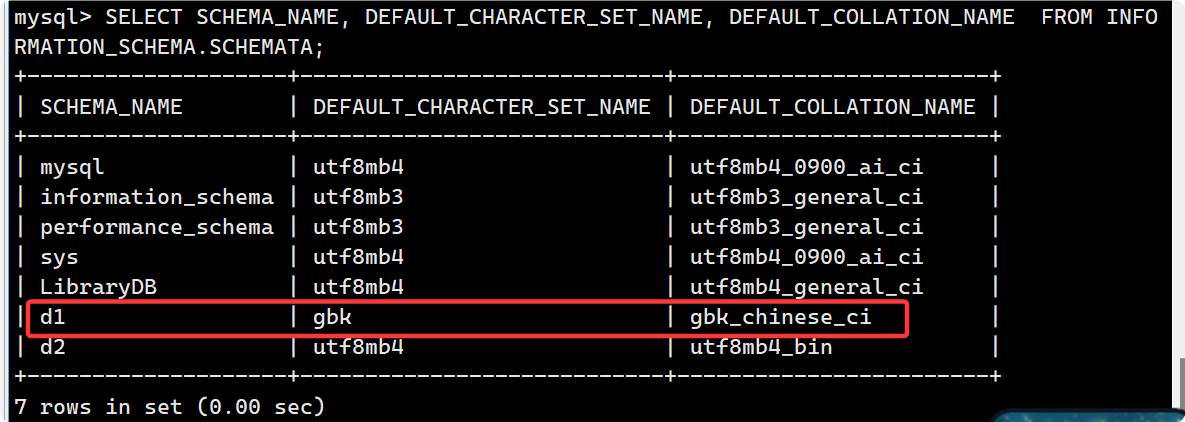
SELECT SCHEMA_NAME, DEFAULT_CHARACTER_SET_NAME, DEFAULT_COLLATION_NAME
FROM INFORMATION_SCHEMA.SCHEMATA;
INFORMATION_SCHEMA.SCHEMATA视图专门用于存储有关 所有数据库(schema) 的信息
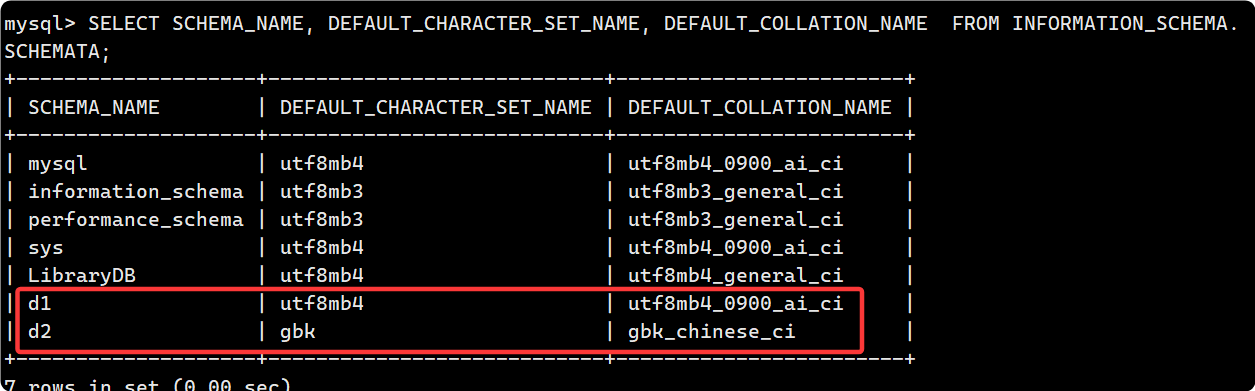
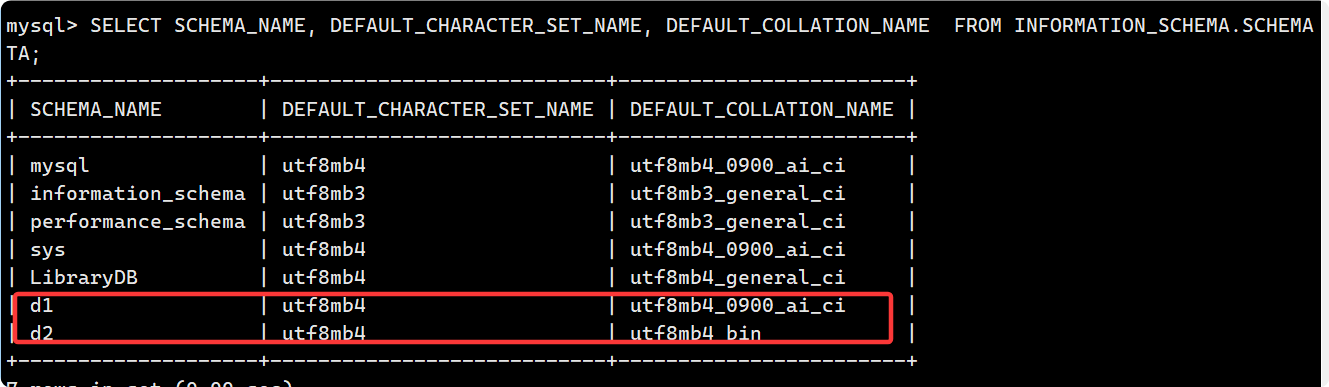
c. 校验规则对数据库的影响
现在创建两个数据库d1 d2, 分别为 utf8mb4_0900_ai_ci 和 utf8mb4_bin, 前者不区分大小写, 后者区分大小写.
一. SELECT显式查询以及结果
然后在数据库插入几个表供查询演示.
1. d1 使用默认字符集 utf8mb4_0900_ai_ci 不区分大小写:
use d1
create table person(name varchar(20));
insert into person (name) values ('A');
insert into person (name) values ('a');
insert into person (name) values ('B');
insert into person (name) values ('b');
insert into person (name) values ('C');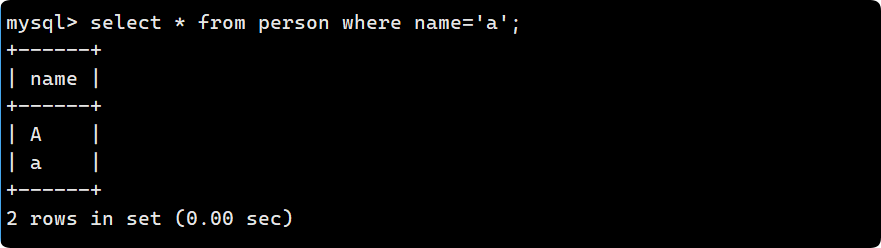
2. d2 使用 utf8mb4_bin, 区分大小写:
use d2
create table person(name varchar(20));
insert into person (name) values ('A');
insert into person (name) values ('a');
insert into person (name) values ('B');
insert into person (name) values ('b');
insert into person (name) values ('C');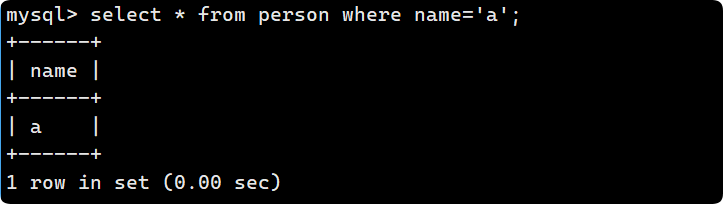
在使用数据库前需要先 use db_name, 再建表. (对应系统级操作 cd dir_name, 相当于在指定目录下创建文件需要先进入目录),
二. SELECT 隐式排序以及结果(默认是升序)
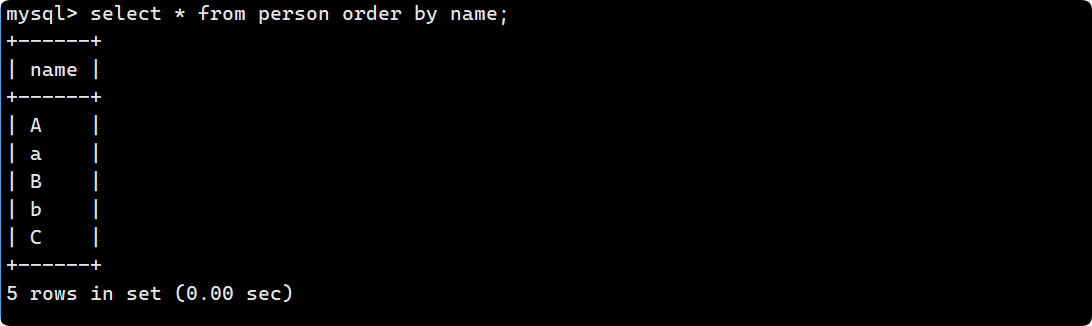
不区分大小写: A 和 a 的值要比 B 和 b 小, 所以整体呈现A->B->C的顺序:
区分大小写, 用 ASSIC 码去进行比较, 小写字母比大写字母ASSIC码要大, 因此为A->B->C->a->b:
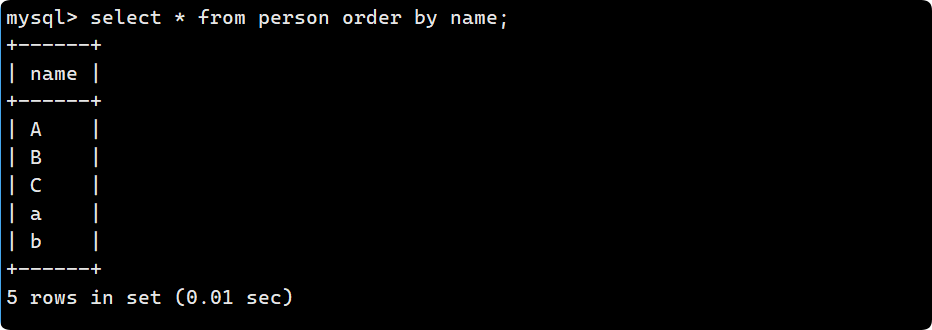
结论: 校验集会影响查询结果, 无论是 显式地用where去指定 还是 隐式的用order去排序.
操纵数据库
MySQL 建议我们关键字(create select等)使用大写, 但是不是必须的.
1. 查看数据库, 经常用到:
show databases;2. 查看当前使用的是哪个数据库:
select database();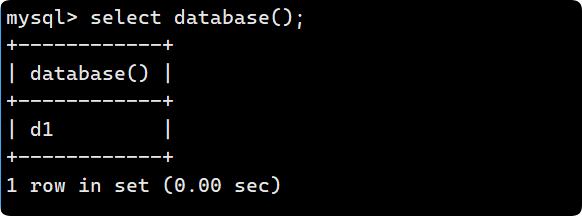
3. 修改数据库
对数据库的修改主要指的是修改数据库的字符集, 校验规则:
ALTER DATABASE db_name
[alter_spacification [,alter_spacification]...]
alter_spacification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name将 mytest 数据库字符集改成 gbk :
alter database mytest charset=gbk;

4. 查询当时创建数据库时的创建语句:
show create database 数据库名;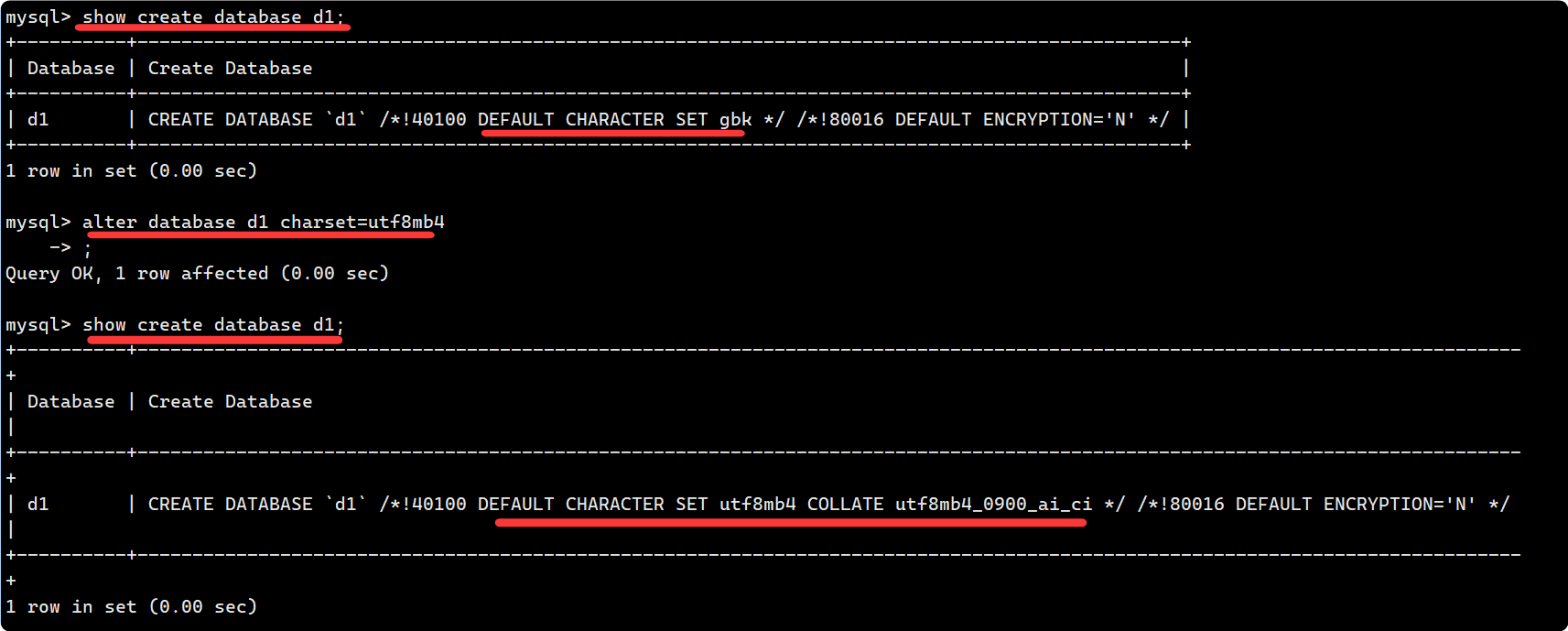
- 数据库名字的反引号``, 是为了防止使用的数据库名刚好是关键字.
- /*!40100 default.... */ 这个不是注释, 表示当前 mysql 版本大于4.01版本, 就执行这句话.
- alter 之后, show create database db_name; 也会相应更改
5. 数据库删除
DROP DATABASE [IF EXISTS] db_name;执行删除之后的结果:
- 数据库内部看不到对应的数据库
- 对应的数据库文件夹被删除, 级联删除, 里面的数据表全部被删
注意: 不要随意删除数据库.
数据库的备份和恢复
mysql 不提供直接对数据库进行重命名, 也不要直接对数据库对应的目录文件重命名. 如果非要重命名, 方法是对数据库进行备份, 然后把文件导入到新的数据库中.
数据库迁移
数据库在两个机器上转移很容易, 只需要将备份文件交给另一台机器, 然后还原即可.
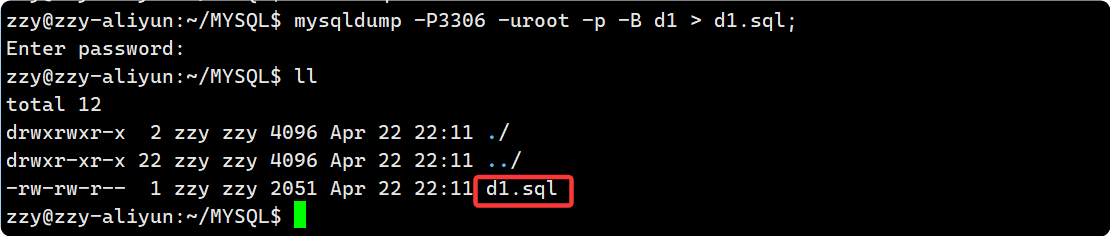
1. 备份要使用 mysql 提供的工具去备份, 备份成功之后, 会生成一个指定的备份文件, 图中为d1.sql:
2. 删掉d1数据库之后, 再在mysql环境下用 source 命令还原回去:
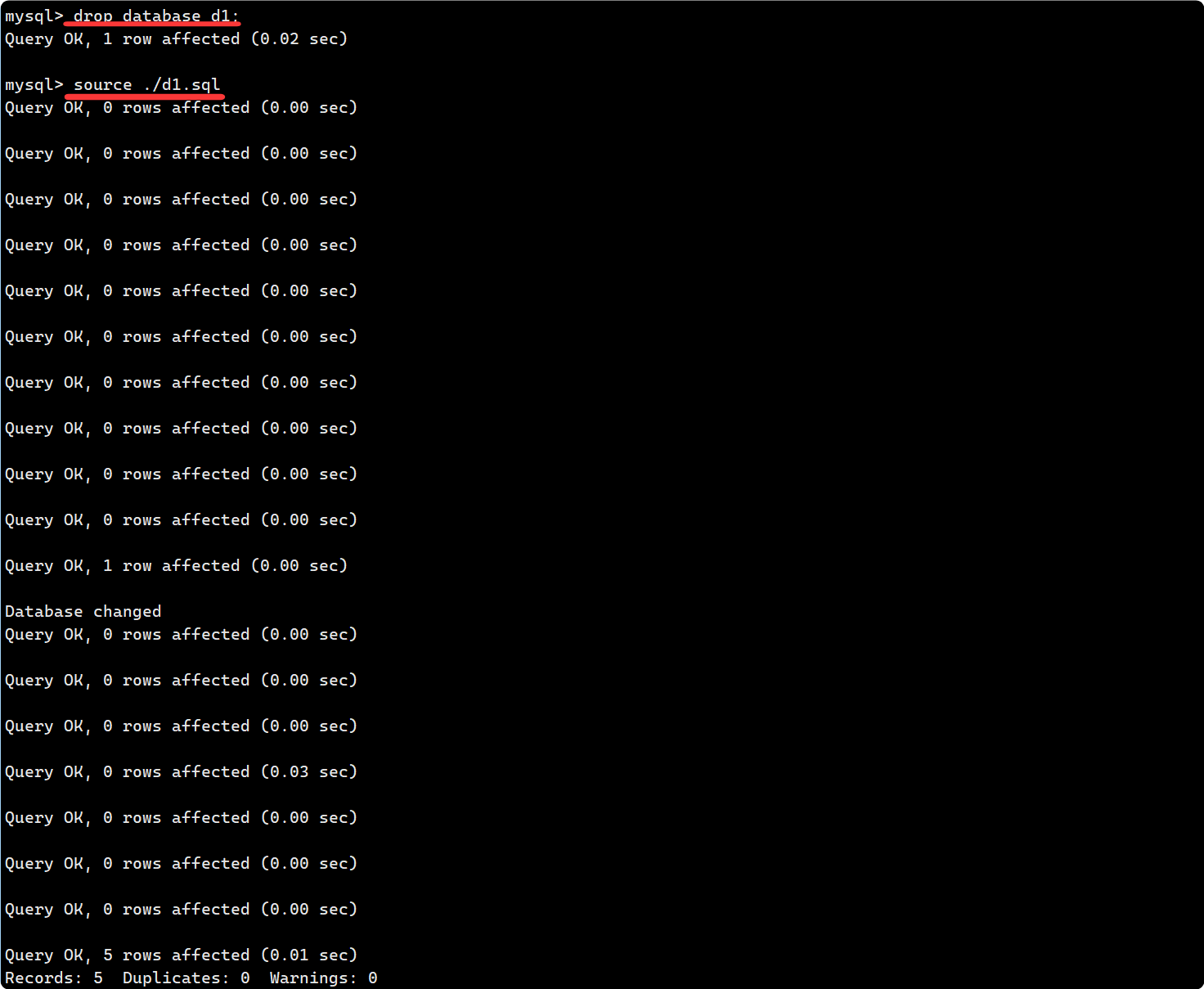
3. 由于 d1.sql 备份文件中备份的是关于该数据库曾经的所有操作, 所以会依次执行 d1.sql 中保存的操作.
数据库重命名
如果备份一个数据库时, 没有带上 -B 参数, 在恢复数据库时, 需要:
1. 先创建空数据库, 自己命名
2. 使用数据库
3. 直接输入 source 来还原
本质是因为没有 -B 的参数, 备份的文件中就不会有第一行 create database db_name 语句, 只会保留一些表信息. 因此需要自己创建一个数据库并命名.
备份表和多个数据库
另外, 我们如果备份的不是整个数据库, 而是其中的若干张表.
mysqldump -u root -p 数据库名 表名1 表名2 > 备份文件路径同时备份多个数据库:
mysqldump -u root -p -B 数据库名1 数据库名2 ... > 数据库存放路径查看连接情况
show processlist;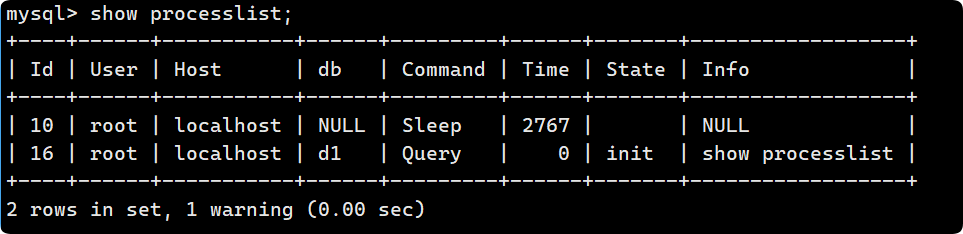 可以告诉我们当前有哪些用户连接到我们的MySQL, 如果查出某个用户不是你正常登陆的, 很有可能你的数据库被人入侵了. 以后大家发现自己数据库比较慢时, 可以用这个指令来查看数据库连接情况.
可以告诉我们当前有哪些用户连接到我们的MySQL, 如果查出某个用户不是你正常登陆的, 很有可能你的数据库被人入侵了. 以后大家发现自己数据库比较慢时, 可以用这个指令来查看数据库连接情况.
总结
数据库的名称不要轻易改, 数据库不要轻易删除, 因为上层应用依赖数据库且认定改数据库的名称, 改动会出错.


:融会贯通 - 多变量、模型选择与未来之路)



