以下是AI推荐系统的详细解析:
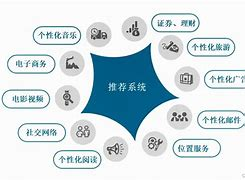
一、核心概念
-
定义
推荐系统是通过分析用户行为、物品特征或用户画像,向用户推荐个性化内容的技术,广泛应用于电商、视频、社交等领域。 -
目标
- 提升用户留存与转化率
- 增强用户体验
- 实现精准营销
二、技术原理
1. 基础算法类型
| 类型 | 描述 | 优点 | 局限性 |
|---|---|---|---|
| 协同过滤 | 基于用户或物品的历史行为相似性推荐(如UserCF/ItemCF) | 不依赖内容特征 | 新用户/物品冷启动问题 |
| 内容推荐 | 通过物品特征(如文本、标签、类别)计算相似性 | 解释性强 | 特征工程复杂,维度灾难风险 |
| 混合推荐 | 融合多种算法(如协同过滤+深度学习) | 综合优势,提升效果 | 系统复杂度高 |
2. 进阶技术
- 矩阵分解:将用户-物品评分矩阵分解为低维向量(如SVD、SVD++)
- 深度学习:
- Wide & Deep:结合广义线性模型与深度神经网络
- NCF(神经协同过滤):纯神经网络学习用户-物品交互
- Graph Neural Networks:利用用户-物品图结构建模
- 强化学习:动态优化推荐策略(如上下文bandit)
3. 关键流程
三、核心模块
-
数据层
- 用户行为日志(点击、购买、停留时长)
- 物品属性(商品描述、标签、类别)
- 上下文信息(时间、地理位置、设备类型)
-
特征工程
- 离散特征编码(One-Hot、Embedding)
- 连续特征归一化
- 组合特征(用户-物品交叉特征)
-
推荐引擎
- 离线训练:模型迭代优化
- 实时计算:处理用户实时行为
- 冷启动策略:
- 基于热门榜单
- 内容相似性填充
- 迁移学习
-
效果评估
- 离线指标:AUC、Recall、NDCG
- 在线指标:CTR、转化率、GMV
- A/B Test验证
四、典型应用场景
| 场景 | 推荐策略示例 |
|---|---|
| 电商 | 基于购买历史的协同过滤 + 促销商品加权 |
| 视频平台 | 短视频点击率预测 + 类似内容推荐 |
| 社交媒体 | 用户兴趣图谱构建 + 社交关系扩散 |
| 新闻资讯 | 实时热点追踪 + 个性化内容排序 |
五、挑战与趋势
-
技术挑战
- 数据稀疏性与冷启动
- 推荐多样性与公平性
- 实时性与计算效率
-
前沿方向
- 多模态推荐:融合文本、图像、视频等多源信息
- 因果推荐:分析推荐对用户行为的因果影响
- 隐私保护:联邦学习、差分隐私技术应用
如需进一步探讨具体算法实现(如Java/Python代码示例)或系统架构设计,可提供更详细需求。
番外1
以下是推荐系统中**滤泡效应(Filter Bubble)**的详细解析,包括成因、影响及解决方案:
一、滤泡效应的定义
滤泡效应是指推荐系统过度依赖用户历史行为,导致用户被“包裹”在信息茧房中,仅接触到符合自身兴趣或观点的内容,而无法获取多元化的信息。这种现象会限制用户的视野,加剧信息偏食。
二、核心成因
1. 算法机制
- 过度个性化:推荐系统通过用户历史行为(如点击、购买)学习偏好,优先推荐相似内容。
- 正反馈循环:用户越点击特定类型内容,系统越强化推荐,形成“信息回声壁”。
- 冷启动依赖:新用户初始行为数据有限,系统可能过度依赖有限兴趣标签。
2. 数据偏见
- 训练数据偏差:若训练数据本身存在用户群体偏好偏差(如年龄、地域),推荐结果会强化已有偏见。
- 长尾效应:热门内容被反复推荐,长尾内容难以触达用户。
3. 用户行为惯性
- 用户倾向于选择已知内容,减少探索新内容的动力。
三、典型影响
1. 负面影响
| 类别 | 具体表现 |
|---|---|
| 信息窄化 | 用户仅接触特定领域内容,丧失对其他领域的认知(如新闻、商品类型) |
| 观点极化 | 社交平台用户被推荐极端观点内容,加剧社会分裂 |
| 商业风险 | 用户兴趣被过度挖掘,长期可能因内容单一化流失 |
2. 电商场景案例
- 用户长期购买某品牌商品,系统仅推荐同类商品,导致用户无法发现潜在偏好。
- 新品或长尾商品曝光率低,商家流量分配不均。
四、解决方案
1. 算法层面优化
(1)多样性增强
-
混合推荐策略:在推荐结果中混合:
- 个性化内容(如协同过滤结果)
- 热门内容(如全局热门商品)
- 探索性内容(随机或基于内容相似性推荐)
Java实现示例:
// 推荐结果混合示例(假设已获取个性化推荐列表) List<Item> personalized = model.recommend(userId, 10); List<Item> popular = getPopularItems(5); List<Item> diverse = getDiverseItems(5); // 基于内容或随机选择// 按比例混合 List<Item> finalResult = new ArrayList<>(); finalResult.addAll(personalized.subList(0, 8)); finalResult.addAll(popular); finalResult.addAll(diverse);
(2)探索与利用平衡
- Bandit算法:结合多臂老虎机(如LinUCB),在推荐中平衡探索新内容与利用已知偏好。
- 多样性正则化:在模型损失函数中加入多样性惩罚项(如余弦相似度惩罚)。
(3)冷启动改进
- 迁移学习:利用跨领域数据(如用户跨平台行为)扩展兴趣维度。
- 主动学习:主动询问用户对未接触过类别的兴趣(如弹窗调查)。
2. 系统设计层面
-
透明度与用户控制:
- 提供“推荐原因”解释(如“因您喜欢A,推荐B”)。
- 允许用户手动调整兴趣标签或屏蔽内容类型。
Java实现示例:
@PostMapping("/preferences") public ResponseEntity<?> updatePreferences(@RequestBody UserPreferences prefs) {// 更新用户兴趣标签,影响后续推荐userService.updateUserInterests(prefs.getUserId(), prefs.getTags());return ResponseEntity.ok().build(); } -
分层推荐:
- 将推荐结果分为:
- 核心层:高置信度个性化推荐(如前80%)
- 探索层:低置信度或多样化内容(如后20%)
- 将推荐结果分为:
3. 数据层面
- 反偏见数据增强:
- 通过重采样或加权,提升长尾内容的曝光概率。
- 引入外部数据源(如社会热点事件)打破信息孤岛。
五、评估指标
在传统CTR、转化率之外,需增加多样性评估指标:
- 覆盖率(Coverage):推荐商品占总商品库的比例。
- 熵值(Entropy):推荐结果的类别分布均匀性。
- 新颖性(Novelty):推荐内容的流行度排名(越低越新颖)。
六、实际案例
电商场景应用:
- 淘宝“猜你喜欢”:
- 核心推荐基于用户历史行为(如购买手机的用户推荐配件)。
- 混合推荐“新品上市”或“跨品类爆款”(如家居用品)。
- Netflix:
- 在电影推荐中加入“随机推荐”按钮,允许用户主动探索陌生类型。
七、总结
滤泡效应是推荐系统设计中需谨慎处理的副作用。通过算法多样性增强、用户可控性设计和数据反偏见策略,可在保持个性化的同时,提升系统的社会价值与用户长期粘性。
番外2
以下是基于Java构建电商推荐系统的分步实现方案,结合机器学习与工程实践:
一、技术选型
1. 核心框架
- 数据处理:Apache Spark(Java API)或Flink
- 机器学习库:
- DeepLearning4J:Java深度学习框架,支持神经网络
- TensorFlow Java API:调用TensorFlow模型
- H2O:集成随机森林、GBM等算法
- 实时计算:Flink或Kafka Streams
- 模型部署:Spring Boot + REST API
2. 推荐算法
| 算法类型 | Java实现工具 | 适用场景 |
|---|---|---|
| 协同过滤 | Apache Spark MLlib | 用户/物品相似性推荐 |
| 矩阵分解 | Breeze(Scala,可通过Java调用) | 隐式反馈数据处理 |
| 深度学习 | DeepLearning4J | 复杂特征交互建模 |
| 混合推荐 | 多模型融合(如协同过滤+内容推荐) | 综合优势场景 |
二、实现步骤
1. 数据准备
// 使用Spark读取电商行为日志(Java API示例)
SparkSession spark = SparkSession.builder().appName("DataPrep").getOrCreate();
Dataset<Row> rawLogs = spark.read().option("header", "true").csv("hdfs://user/behavior_logs.csv");// 过滤有效行为(如点击、购买)
Dataset<Row> filteredLogs = rawLogs.filter(col("eventType").isin("click", "purchase"));
2. 特征工程
// 特征构建示例(Spark DataFrame)
Dataset<Row> features = filteredLogs.withColumn("user_id", col("userId").cast("integer")).withColumn("item_id", col("itemId").cast("integer")).withColumn("timestamp", col("eventTime").cast("long")).withColumn("label", expr("CASE WHEN eventType='purchase' THEN 1 ELSE 0 END"));
3. 模型训练(协同过滤)
// 使用Spark ALS算法(隐式反馈)
import org.apache.spark.ml.recommendation.ALS;ALS als = new ALS().setMaxIter(10).setRegParam(0.01).setUserCol("user_id").setItemCol("item_id").setRatingCol("label").setColdStartStrategy("drop");ALSModel model = als.fit(trainData);
4. 实时推荐服务(Flink)
// Flink实时处理用户行为流
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<>("user_behavior", new SimpleStringSchema(), props);DataStream<String> stream = env.addSource(kafkaSource);
stream.keyBy("user_id").process(new RecommendProcessFunction(model)) // 调用预训练模型.print();
5. 冷启动策略
// 基于热门商品的冷启动推荐
public List<Item> getPopularItems() {return jdbcTemplate.query("SELECT item_id, COUNT(*) AS cnt FROM behaviors GROUP BY item_id ORDER BY cnt DESC LIMIT 10",(rs, rowNum) -> new Item(rs.getInt("item_id"), rs.getString("name")));
}
三、系统架构设计
graph TB
A[用户行为采集] --> B[Kafka消息队列]
B --> C[Spark/Flink实时计算]
C --> D[特征存储(HBase/MySQL)]
D --> E[离线训练集群]
E --> F[模型服务(Spring Boot)]
F --> G[推荐API]
G --> H[电商前端]
四、关键优化点
-
性能优化
- 使用HBase存储用户画像,支持毫秒级查询
- 模型轻量化(如使用TensorFlow Lite导出模型)
-
实时性保障
- Flink窗口计算(如5分钟滑动窗口)
- 内存缓存热门推荐结果
-
A/B Test
// 接口分流示例 @RestController public class RecommendController {@GetMapping("/recommend")public List<Item> getRecommendations(@RequestParam String userId) {if (RandomUtils.nextDouble() < 0.3) {return newVersionModel.predict(userId); // 新模型} else {return oldVersionModel.predict(userId); // 基线模型}} }
五、完整代码示例(矩阵分解)
// 使用DeepLearning4J实现矩阵分解
import org.deeplearning4j.nn.conf.layers.EmbeddingLayer;
import org.deeplearning4j.nn.conf.MultiLayerConfiguration;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration;// 定义模型配置
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder().list().layer(new EmbeddingLayer.Builder().nIn(numUsers) // 用户数量.nOut(128) // 嵌入维度.build()).layer(new EmbeddingLayer.Builder().nIn(numItems) // 物品数量.nOut(128).build()).pretrain(false).backprop(true).build();// 训练模型
INDArray userFeatures = ... // 用户特征矩阵
INDArray itemFeatures = ... // 物品特征矩阵
MultiLayerNetwork model = new MultiLayerNetwork(conf);
model.fit(userFeatures, itemFeatures);
六、部署与监控
-
模型服务化
- 使用Spring Boot暴露REST API
- 示例接口:
@PostMapping("/predict") public List<Recommendation> predict(@RequestBody UserRequest request) {return modelService.recommend(request.getUserId(), 10); }
-
监控指标
- CTR(点击率)
- 覆盖率(推荐多样性)
- 离线AUC/在线GMV
如需进一步优化(如图神经网络实现或冷启动策略细节),可提供具体需求继续深入。

)


:垃圾回收器—CMS(图文+代码))
