一、 当前主流模型的参数规模对比
(1)当前主流模型有哪些
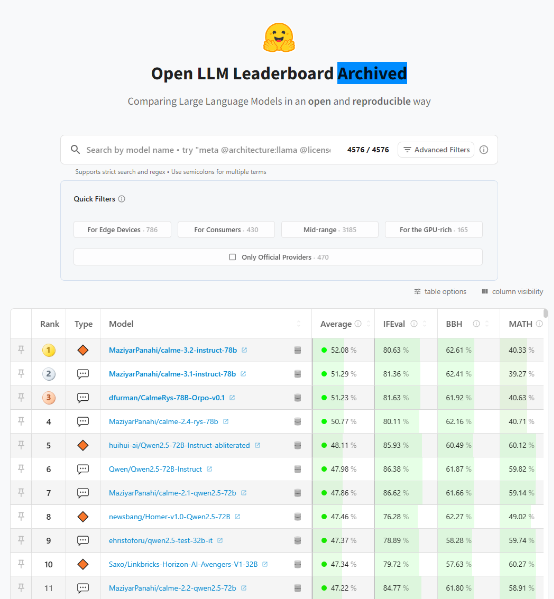
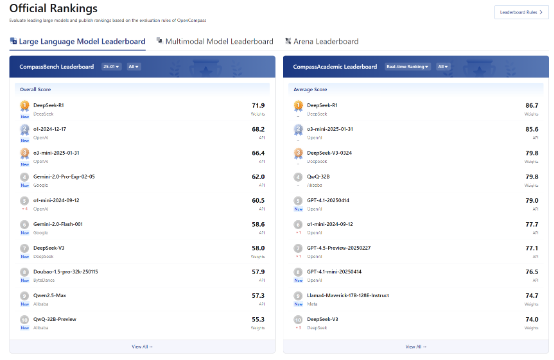
参考全球最大AI开源社区Hugging Face发布的榜单、上海AI实验室推出的开放评测体系OpenCompass和国内开源AI社区魔塔社区的下载排行。
- 闭源模型则指那些由公司或组织开发,但不对外公开其详细实现细节或训练数据的模型。这些模型通常是出于商业利益考虑而保持私有,有时也可能因为涉及敏感的数据或技术而选择不公开。
- 开源模型是指其架构、训练数据集(如果适用)、以及训练代码都是公开的,允许任何人查看、使用、修改并部署这些模型。这种开放性促进了技术的快速传播和发展,并且有助于提高模型的透明度和信任度。
(2)模型参数规模对比
| 模型名 | 模型参数 |
| DeepSeek-R1 | 671B |
| o1-2024-12-17 | 未知 |
| o3-mini-2025-01-31 | 未知 |
| Gemini-2.0-Pro-Exp-02-05 | 未知 |
| o1-mini-2024-09-12 | 未知 |
| Gemini-2.0-Flash-001 | 未知 |
| DeepSeek-V3 | 未知 |
| Doubao-1.5-pro-32k-250115 | 未知 |
| Qwen2.5-Max | 未知 |
| QwQ-32B-Preview | 32B |
| calme-3.2-instruct-78b | 78B |
| calme-3.1-instruct-78b | 78B |
| CalmeRys-78B-Orpo-v0.1 | 78B |
| calme-2.4-rys-78b | 78B |
| Qwen2.5-72B-Instruct-abliterated | 72B |
| Qwen2.5-72B-Instruct | 72B |
| calme-2.1-qwen2.5-72b | 72B |
| Homer-v1.0-Qwen2.5-72B | 72B |
| qwen2.5-test-32b-it | 32B |
| Linkbricks-Horizon-AI-Avengers-V1-32B | 32B |
| calme-2.2-qwen2.5-72b | 72B |
| Qwen2-32B | 32B |
| Qwen2.5-7B-Instruct | 7B |
| DeepSeek-R1-Distill-Qwen-32B-AWQ | 32B |
| DeepSeek-R1-Distill-Qwen-32B-GPTQ-Int4 | 32B |
| DeepSeek-R1-Distill-Llama-70B | 70B |
| Qwen2-72B-Instruct | 72B |
| DeepSeek-R1-Distill-Qwen-32B | 32B |
| DeepSeek-R1-Distill-Qwen-1.5B | 1.5B |
| CodeQwen1.5-7B-Chat | 7B |
把主流的模型参数汇总成表,并剔除未知参数的模型,能得到下面这个表:
| 模型参数规模B | SOTA模型个数 |
| 671 | 1 |
| 32 | 5 |
| 78 | 4 |
| 72 | 3 |
| 7 | 1 |
| 1.5 | 1 |
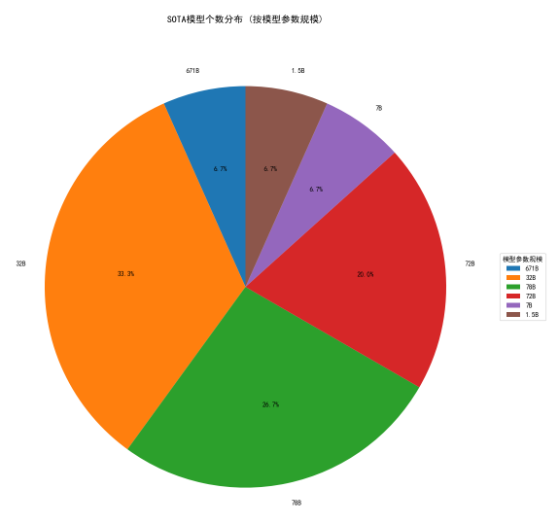
统计可知参数规模在32到78B之间的模型是目前的主流。
二、模型部署配置
| 模型参数规模(B) | FP16精度(GB) | INT8量化(GB) |
| 671 | 1342 | 671 |
| 32 | 64 | 32 |
| 78 | 156 | 78 |
| 72 | 144 | 72 |
| 7 | 14 | 7 |
| 1.5 | 3.0 | 1.5 |
在模型微调时,显存占用通常会比推理时更高,因为微调需要存储额外的梯度信息、优化器状态以及激活值。一般的估算如下:
● FP32精度:微调显存通常为推理显存的 3-4倍,因为需要存储梯度和优化器状态。
● FP16精度:由于混合精度训练的存在,显存占用通常为推理显存的 2-3倍。
● INT8量化:量化微调(QLoRA等)技术可以明显降低显存需求,通常为推理显存的 1.5-2倍。


安卓开发中DataBinding 和 ViewBinding详解)


