- Spark Streaming基础概念
用于流式数据处理,支持Kafka、Flume等多种数据源,能使用Spark的map、reduce等原语运算,结果可存储于HDFS、数据库等。它以离散化流DStream为抽象表示,DStream是RDD序列,具有易用、容错、易整合到Spark体系的特点。其架构包含背压机制,1.5版本后可依据JobScheduler反馈动态调整Receiver数据接收率,通过“spark.streaming.backpressure.enabled”控制,默认不启用。
Spark-Streaming的特点:易用、容错、易整合到spark体系。
易用性:Spark Streaming支持Java、Python、Scala等编程语言,可以像编写离线程序一样编写实时计算的程序
容错:Spark Streaming在没有额外代码和配置的情况下,可以恢复丢失的数据。对于实时计算来说,容错性至关重要。
易整合:Spark Streaming可以在Spark上运行,并且还允许重复使用相同的代码进行批处理。也就是说,实时处理可以与离线处理相结合,实现交互式的查询操作。
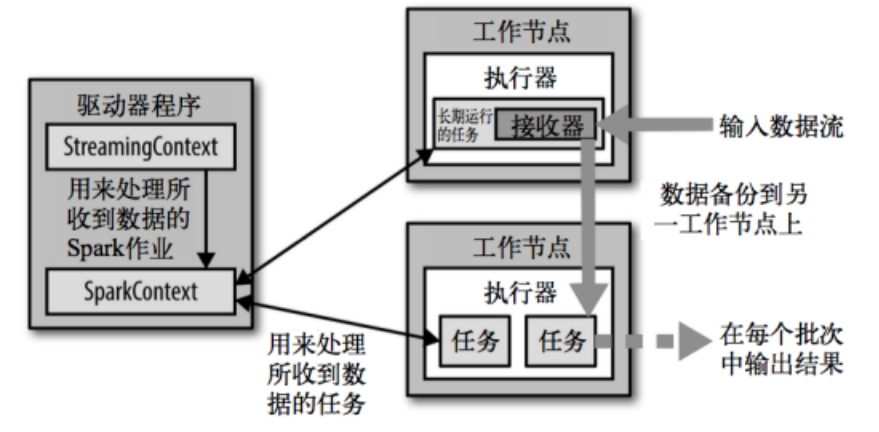
Spark-Streaming架构图:
背压机制:
在Spark 1.5 以前版本,用户如果要限制 Receiver 的数据接收速率,可以通过设置静态配制参数“spark.streaming.receiver.maxRate”的值来实现,此举虽然可以通过限制接收速率,来适配当前的处理能力,防止内存溢出,但也会引入其它问题。比如:producer 数据生产高于 maxRate,当前集群处理能力也高于 maxRate,这就会造成资源利用率下降等问题。
为了更好的协调数据接收速率与资源处理能力,1.5 版本开始 Spark Streaming 可以动态控制数据接收速率来适配集群数据处理能力。背压机制(即 Spark Streaming Backpressure): 根据JobScheduler 反馈作业的执行信息来动态调整 Receiver 数据接收率。通过属性“spark.streaming.backpressure.enabled”来控制是否启用 backpressure 机制,默认值为false,即不启用。
2. Spark部署模式
Yarn模式:需解压缩文件并改名,修改Hadoop的yarn-site.xml和Spark的spark-env.sh配置文件,启动HDFS和Yarn集群后提交测试应用。还可配置历史服务,修改相关文件设置日志路径和参数,开启历史服务后重新提交应用便于查看历史任务。
Windows模式:将文件解压到无中文空格路径,执行bin目录下的spark-shell.cmd启动本地环境,在命令行执行代码指令进行数据处理。
3. DStream实操案例
可以通过使用 ssc.queueStream(queueOfRDDs)来创建 DStream,每一个推送到这个队列中的 RDD,都会作为一个DStream 处理。
自定义数据源需要继承 Receiver,并实现 onStart、onStop 方法来自定义数据源采集。
WordCount案例:借助netcat向9999端口发送数据,Spark Streaming读取并统计单词出现次数。步骤包括添加依赖、编写代码创建SparkConf和StreamingContext,进行数据读取与转换操作后打印结果,最后启动netcat发送数据得到统计结果。
Kafka数据源案例:从Kafka读取数据并处理,有ReceiverAPI和DirectAPI两种方式,当前推荐DirectAPI。以Kafka 0 - 10 Direct模式为例,导入依赖后编写代码配置Kafka参数,创建DStream并处理数据,运行时需开启Kafka集群和生产者,还可查看消费进度。
DirectAPI:是由计算的 Executor 来主动消费 Kafka 的数据,速度由自身控制。
4. DStream转换操作
无状态转化操作:将简单RDD转化操作应用于DStream的每个RDD,如reduceByKey()仅归约每个时间区间内数据。Transform原语可执行任意RDD - to - RDD函数,扩展Spark API;join操作要求两个流批次大小一致,对当前批次RDD进行join计算。

有状态转化操作:UpdateStateByKey用于跨批次维护状态,使用时需定义状态和更新函数,并配置检查点目录。Window Operations通过设置窗口时长和滑动步长获取当前Streaming状态,二者需为采集周期整数倍。
- DStream输出操作
决定处理后数据的去向,print()用于开发调试;saveAsTextFiles、saveAsObjectFiles、saveAsHadoopFiles分别以不同格式存储数据;foreachRDD(func)是通用输出操作,可对每个RDD执行计算并推送数据到外部系统,但使用时要注意连接创建位置,避免序列化和资源浪费问题。
输出操作
➢ print():在运行流程序的驱动结点上打印 DStream 中每一批次数据的最开始 10 个元素。这用于开发和调试。
➢ saveAsTextFiles(prefix, [suffix]):以 text 文件形式存储这个 DStream 的内容。每一批次的存储文件名基于参数中的 prefix 和 suffix。”prefix-Time_IN_MS[.suffix]”。
➢ saveAsObjectFiles(prefix, [suffix]):以 Java 对象序列化的方式将 Stream 中的数据保存为SequenceFiles . 每一批次的存储文件名基于参数中的为"prefix-TIME_IN_MS[.suffix]".
➢ saveAsHadoopFiles(prefix, [suffix]):将 Stream 中的数据保存为 Hadoop files. 每一批次的存储文件名基于参数中的为"prefix-TIME_IN_MS[.suffix]"。
➢ foreachRDD(func):这是最通用的输出操作,即将函数 func 用于产生于 stream 的每一个RDD。其中参数传入的函数 func 应该实现将每一个 RDD 中数据推送到外部系统,如将
RDD 存入文件或者通过网络将其写入数据库。
通用的输出操作 foreachRDD(),它用来对 DStream 中的 RDD 运行任意计算。这和 transform() 有些类似,都可以让我们访问任意 RDD。在 foreachRDD()中,可以重用我们在 Spark 中实现的所有行动操作。




