目录
YOLOv10介绍
部署和使用示例
微调训练
YOLO模型因其在计算成本和检测性能之间的平衡而在实时目标检测中很受欢迎。前几天YOLOv10也刚刚发布了。我们这篇文章就来看看YOLOv10有哪些改进,如何部署,以及微调。
概述
实时物体检测旨在以较低的延迟准确预测图像中的物体类别和位置。YOLO 系列在性能和效率之间取得了平衡,因此一直处于这项研究的前沿。然而,对 NMS 的依赖和架构上的低效阻碍了最佳性能的实现。YOLOv10 通过为无 NMS 训练引入一致的双重分配和以效率-准确性为导向的整体模型设计策略,解决了这些问题
YOLOv10介绍
YOLOv10 的架构借鉴了以往 YOLO 模型的优点,同时引入了几项关键创新。模型架构由以下部分组成:
Backbone:YOLOv10 中的骨干网负责特征提取,使用增强版 CSPNet(Cross Stage Partial Network)来改善梯度流并减少计算冗余
Neck:颈部用于汇聚不同尺度的特征,并将其传递给头部。它包括 PAN(Path Aggregation Network)层,可实现有效的多尺度特征融合
One-to-Many Head:在训练过程中为每个对象生成多个预测,以提供丰富的监督信号并提高学习准确性
One-to-One Head:在推理过程中为每个对象生成一个最佳预测,从而消除对 NMS 的需求,减少延迟并提高效率
核心特点
NMS-Free Training:利用一致的双重分配来消除对 NMS 的需求,从而减少推理延迟
Holistic Model Design:从效率和准确性的角度对各种组件进行全面优化,包括轻量级分类头、空间通道去耦向下采样和等级引导块设计
Enhanced Model Capabilities:纳入大核卷积和部分自注意模块,在不增加大量计算成本的情况下提高性能
模型型号
YOLOv10 有多种型号,可满足不同的应用需求
YOLOv10-N:纳米版本,适用于资源极其有限的环境
YOLOv10-S:兼顾速度和精度的小型版本
YOLOv10-M:通用的中型版本
YOLOv10-B:平衡型,宽度增加,精度更高
YOLOv10-L:大型版本,精度更高,但计算资源增加
YOLOv10-X:超大型版本可实现最高精度和性能
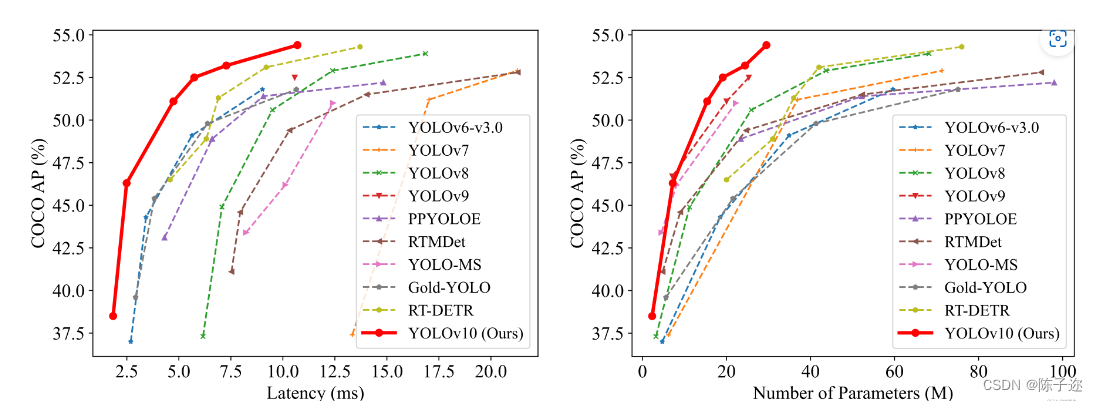
性能
在准确性和效率方面,YOLOv10 优于以前的 YOLO 版本和其他最先进的模型。例如,在 COCO 数据集上,YOLOv10-S 比具有类似 AP 的 RT-DETR-R18 快 1.8 倍;在性能相同的情况下,YOLOv10-B 比 YOLOv9-C 减少了 46% 的延迟和 25% 的参数

方法
一致的双重分配,实现无 NMS 训练
YOLOv10 采用双重标签分配,在训练过程中将一对多和一对一策略结合起来,以确保丰富的监督和高效的端到端部署。一致匹配度量可调整两种策略之间的监督,从而提高推理过程中的预测质量效率-准确度驱动的整体模型设计
由于YOLO模型本身的结构,其计算冗余和能力有限,在平衡效率和准确性方面面临挑战。所以作者提出了全面的模型设计来解决这些问题,同时注重效率和准确性。
效率驱动型模型设计:
通过使用深度可分离卷积的简化架构来减少计算开销。
分离空间减少和信道增加减少计算成本并保留信息。
使用内在秩分析来识别和减少模型阶段的冗余,用更有效的结构代替复杂的块。
精度驱动的模型设计:
通过增加深度阶段的接受场来增强模型能力,有选择地使用大核深度卷积来避免浅阶段的开销。
通过PSA划分特征并将自注意力应用于部分特征,结合有效的自注意力,降低计算复杂性和内存使用,同时增强全局表示学习。
部署和使用示例
我们将从安装所需的库开始。
# Clone ultralytics repogit clone https://github.com/ultralytics/ultralytics# cd to local directorycd ultralytics# Install dependenciespip install -r requirements.txt
1、使用YOLOv10进行目标检测
目标检测是计算机视觉中的一项基本任务。YOLOv10通过在推理期间消除非最大抑制(NMS)的需要来增强这一点,从而降低延迟并提高性能。
我们先载入模型和需要处理的视频
import cv2import numpy as npfrom ultralytics import YOLO# Load YOLOv10 modelmodel=YOLO('yolov10.pt')# Path to the video filevideo_path='path/to/your/deephub.mp4'cap=cv2.VideoCapture(video_path)
然后就可以处理视频帧
whilecap.isOpened():ret, frame=cap.read()ifnotret:break# Perform object detectionresults=model(frame)# Draw bounding boxesfor result in results:boxes=result['boxes']for box in boxes:x1, y1, x2, y2=box['coords']label=box['label']confidence=box['confidence']cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 255, 0), 2)cv2.putText(frame, f'{label}{confidence:.2f}', (x1, y1-10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)# Display the framecv2.imshow('YOLOv10 Object Detection', frame)ifcv2.waitKey(1) &0xFF==ord('q'):breakcap.release()cv2.destroyAllWindows()
2、使用YOLOv10进行区域计数
区域计数可以对指定区域内的对象进行计数,这个例子演示了如何使用YOLOv10对定义区域中的对象进行计数。
定义区域和设置模型
from shapely.geometry import Polygon, Point# Define counting regionscounting_regions= [{"name": "Region 1","polygon": Polygon([(50, 80), (250, 20), (450, 80), (400, 350), (100, 350)]),"counts": 0,"color": (255, 0, 0)},{"name": "Region 2","polygon": Polygon([(200, 250), (440, 250), (440, 550), (200, 550)]),"counts": 0,"color": (0, 255, 0)},]model=YOLO('yolov10.pt')
处理视频和计数区域中的对象
cap=cv2.VideoCapture('path/to/your/deephub.mp4')whilecap.isOpened():ret, frame=cap.read()ifnotret:break# Perform object detectionresults=model(frame)# Draw regionsforregionincounting_regions:points=np.array(region["polygon"].exterior.coords, dtype=np.int32)cv2.polylines(frame, [points], isClosed=True, color=region["color"], thickness=2)region["counts"] =0 # Reset counts for each frame# Count objects in regionsforresultinresults:boxes=result['boxes']forboxinboxes:x1, y1, x2, y2=box['coords']center=Point((x1+x2) /2, (y1+y2) /2)forregionincounting_regions:ifregion["polygon"].contains(center):region["counts"] +=1# Display countsforregionincounting_regions:text=f'{region["name"]}: {region["counts"]}'cv2.putText(frame, text, (int(region["polygon"].centroid.x), int(region["polygon"].centroid.y)), cv2.FONT_HERSHEY_SIMPLEX, 0.5, region["color"], 2)# Display the framecv2.imshow('YOLOv10 Region Counting', frame)ifcv2.waitKey(1) &0xFF==ord('q'):breakcap.release()cv2.destroyAllWindows()

微调训练
在使用模型时最主要的还是要在我们自己的数据集上进行微调,所以我们最后再介绍一下如何使用自己的数据进行微调。
我将使用一个预先准备好的检测x射线图像中的危险物品的数据集来作为演示。

我们只用roboflow直接下载yolov8格式的数据集
!pip install -q roboflowfrom roboflow import Roboflowrf = Roboflow(api_key="your-api-key")project = rf.workspace("vladutc").project("x-ray-baggage")version = project.version(3)dataset = version.download("yolov8")
指定参数和文件路径,然后开始模型训练。
!yolo task=detect mode=train epochs=25 batch=32 plots=True \model='/content/-q/yolov10n.pt' \data='/content/X-Ray-Baggage-3/data.yaml'
这里需要一个data.yaml文件,他的格式如下:
names:- Gun- Knife- Pliers- Scissors- Wrenchnc: 5roboflow:license: CC BY 4.0project: x-ray-baggageurl: https://universe.roboflow.com/vladutc/x-ray-baggage/dataset/3version: 3workspace: vladutctest: /content/X-Ray-Baggage-3/test/imagestrain: /content/X-Ray-Baggage-3/train/imagesval: /content/X-Ray-Baggage-3/valid/images
训练完成后我们可以看看结果:
Image(filename='/content/runs/detect/train/results.png', width=1000)
最后可以测试数据并在网格中显示结果。
fromultralyticsimportYOLOv10importglobimportmatplotlib.pyplotaspltimportmatplotlib.imageasmpimgmodel_path='/content/runs/detect/train/weights/best.pt'model=YOLOv10(model_path)results=model(source='/content/X-Ray-Baggage-3/test/images', conf=0.25,save=True)images=glob.glob('/content/runs/detect/predict/*.jpg')images_to_display=images[:10]fig, axes=plt.subplots(2, 5, figsize=(20, 10))fori, axinenumerate(axes.flat):ifi<len(images_to_display):img=mpimg.imread(images_to_display[i])ax.imshow(img)ax.axis('off') else:ax.axis('off') plt.tight_layout()plt.show()
 YOLOv10的改进在性能和延迟方面均达到了最先进的水平,充分展示了其优越性。并且继承了Ultralytics的传统,无论是部署还是自定义训练和微调都十分的友好,有兴趣的可以现在开始研究了。
YOLOv10的改进在性能和延迟方面均达到了最先进的水平,充分展示了其优越性。并且继承了Ultralytics的传统,无论是部署还是自定义训练和微调都十分的友好,有兴趣的可以现在开始研究了。





