文章目录
- 背景介绍
- 源代码:
- 安装调试过程
- 1.设置第三方镜像源
- 2.预先安装:
- 3.在python中创建代码:
- 4.最终修改程序,将device_map从“cuda”改成“auto”,大模型调用1.5B(1___5B)的
- 5.最终跑出结果
- 解释:
- 示例:
- 总结
背景介绍
在上AI训练营的课程时,老师提供了一段源码,目的是实现从modelscope下载DeepSeek-R1-Distill-Qwen-7B,并通过程序调用大模型,让大模型帮助生成二分查找法。
老师建议在网上租一台有GPU的电脑,推荐如下。
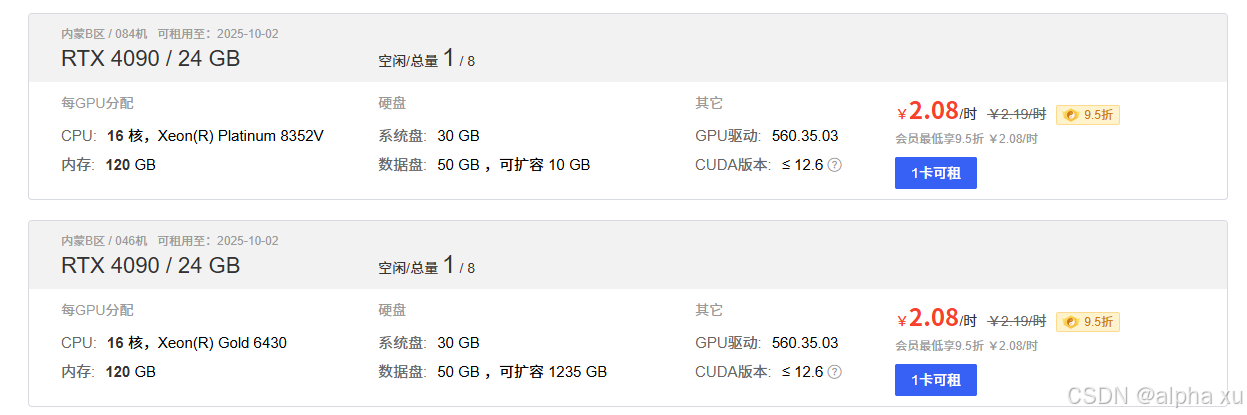
最终本人在自己的surface电脑上(Windows,无GPU)调通了该程序,并实现了功能。
我的电脑配置如下,

源代码:
#!/usr/bin/env python
# coding: utf-8# In[1]:from modelscope import AutoModelForCausalLM, AutoTokenizer
# model_name = "/root/autodl-tmp/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B"
# model_name="C:\\Users\\Administrator\\AInewModels\\deepseek-ai\\DeepSeek-R1-Distill-Qwen-7B" #7B下载后跑不起来,所以改成1.5B
model_name="C:\\Users\\Administrator\\AInewModels\\deepseek-ai\\DeepSeek-R1-Distill-Qwen-1___5B"
model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype="auto",# device_map="cuda" # auto(老师的源程序中是cuda,但是我的电脑没有显卡,因此改成auto)device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "帮我写一个二分查找法"
messages = [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs,max_new_tokens=2000
)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
安装调试过程
1.设置第三方镜像源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
2.预先安装:
(在不断出错中不断安装缺少的组件)
pip install modelscope
pip install setuptools
pip install transformers
安装torch
# CPU版本
pip install torch torchvision torchaudio# GPU版本(需匹配CUDA版本)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
pip install ‘accelerate>=0.26.0’
3.在python中创建代码:
from modelscope import snapshot_download
snapshot_download('deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B',cache_dir="C:\\Users\\Administrator\\AInewModels")
运行它,模型下载到C:\Users\Administrator\AInewModels"

有一个warning
2025-04-04 13:39:40,696 - modelscope - WARNING - Failed to create symbolic link C:\Users\Administrator\AInewModels\deepseek-ai\DeepSeek-R1-Distill-Qwen-1.5B for C:\Users\Administrator\AInewModels\deepseek-ai\DeepSeek-R1-Distill-Qwen-1___5B.
中间有过报错,和CUDA有关。
AssertionError: Torch not compiled with CUDA enabled
4.最终修改程序,将device_map从“cuda”改成“auto”,大模型调用1.5B(1___5B)的
model_name="C:\\Users\\Administrator\\AInewModels\\deepseek-ai\\DeepSeek-R1-Distill-Qwen-1___5B"
model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype="auto",# device_map="cuda" # autodevice_map="auto" # auto
)
5.最终跑出结果
D:\PycharmProjects\PythonProject\AI0331.venv\Scripts\python.exe D:\PycharmProjects\PythonProject\AI0331\lecture02\3-deepseek-r1-7b使用.py
Sliding Window Attention is enabled but not implemented for sdpa; unexpected results may be encountered.
Setting pad_token_id to eos_token_id:151643 for open-end generation.
好,我现在需要帮用户写一个二分查找法。首先,我得理解用户的需求。用户可能是一个刚开始学习编程的学生,或者对算法感兴趣的人。他们可能需要一个简明的示例来理解二分查找法的实现。
二分查找法的时间复杂度是O(log n),适用于有序数组。所以,我应该包括一个示例代码,帮助用户直观地看到如何实现它。用户可能还希望了解代码的结构和各个部分的作用,比如low、high、mid的计算,以及循环的条件。
接下来,我需要考虑代码的结构。通常,二分查找法的代码会初始化low和high,然后在循环中不断调整mid的值,直到找到目标值或者确定不在数组中。同时,还需要处理找到和未找到的情况,返回相应的索引。
我应该使用清晰的变量名,比如low和high,分别表示数组的起始索引和结束索引。mid的计算方式应该是(low + high)//2,这样可以避免溢出。然后,比较target和arr[mid],如果相等,就返回mid;如果arr[mid]小于target,那么目标值在mid的右边,所以low更新为mid+1;否则,high更新为mid-1。循环的条件是low <= high。
此外,我还需要处理无法找到的情况,比如low > high,这时候返回-1。这样用户就能全面了解二分查找法的实现细节。
最后,我应该测试一下这个代码是否正确。比如,用一个简单的例子,比如数组[1,3,5,7,9],查找5,应该返回2。如果查找10,应该返回-1。这样用户可以验证代码是否正确。
总的来说,我需要写出一个完整的示例代码,解释各个部分的功能,并通过示例验证代码的正确性。这样用户不仅能理解算法,还能通过实际例子加深理解。
以下是一个简单的实现二分查找法的代码示例:
def binary_search(arr, target):low = 0high = len(arr) - 1while low <= high:mid = (low + high) // 2if arr[mid] == target:return midelif arr[mid] < target:low = mid + 1else:high = mid - 1return -1
解释:
-
参数:
arr:需要查找的有序数组。target:需要查找的目标值。
-
初始化:
low初始值为数组的索引 0。high初始值为数组的最后一个索引(len(arr) - 1)。
-
循环条件:
- 当
low <= high时,继续循环查找。
- 当
-
计算中点:
mid计算为(low + high) // 2,避免溢出。
-
比较和调整范围:
- 如果
arr[mid]等于target,返回mid。 - 如果
arr[mid]小于target,则目标值在mid右侧,将low更新为mid + 1。 - 否则,将
high更新为mid - 1。
- 如果
-
结束条件:
- 当
low > high时,说明目标值不在数组中,返回-1。
- 当
示例:
arr = [1, 3, 5, 7, 9]
target = 7print(binary_search(arr, target)) # 输出:3
这个函数会返回数组中 7 的索引 3。如果 target 不在数组中,函数会返回 -1。
Process finished with exit code 0
总结
由于本人用的surface 没有GPU卡,CPU 也不强劲,内存也不大。因此为了尝试调用本地的大模型模拟deepseek和人的对话和分析,只能调整程序,使用DeepSeek-R1-Distill-Qwen-1___5B 并将device_map从“cuda”改成=“auto”。

)
![[CISSP] [7] PKI和密码应用](http://pic.xiahunao.cn/nshx/[CISSP] [7] PKI和密码应用)
)


