📝前言:
这篇文章我们来讲讲C++中map和set的使用:
🎬个人简介:努力学习ing
📋个人专栏:C++学习笔记
🎀CSDN主页 愚润求学
🌄其他专栏:C语言入门基础,python入门基础,python刷题专栏,Linux
文章目录
- 一,二叉搜索树
- 1 基本介绍
- 2 性能分析
- 3 查找,插入,删除操作
- 4 ⼆叉搜索树key和key/value
- 二,set
- lower_bound
- equal_range
- 使用
- 三,map
- 1 基本介绍
- 2 使用示例
- 2.1 初始化map
- 2.2 [ ]
- multimap
- 四,其他知识
一,二叉搜索树
1 基本介绍
在了解map和set之前我们先来介绍一下二叉搜索树(二叉排序树)。
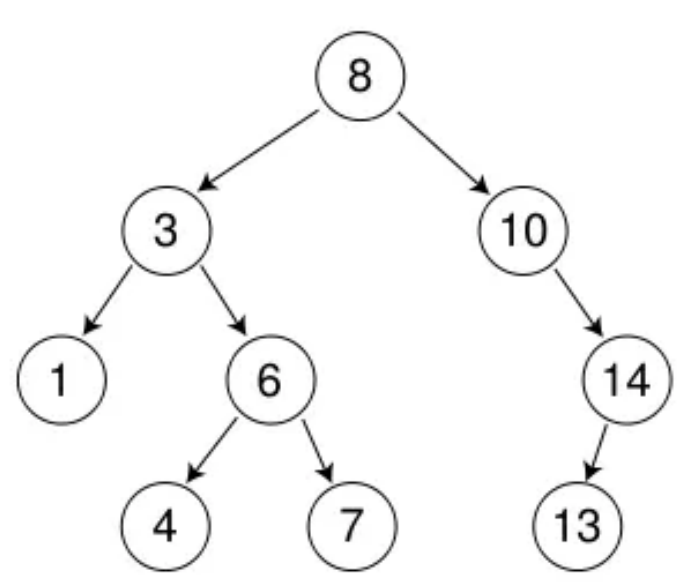
二叉搜索树是空树,或者是具有以下特点的二叉树:
- 对于一个“根节点”,左子树的元素小于根节点,右子树的元素都大于根节点
- 根节点的左右子树也要满足1
- map/set/multimap/multiset系列容器底层就是⼆叉搜索树,其中map/set不⽀持插入相等值,multimap/multiset⽀持插入相等值
如下图所示,就是一颗二叉搜索树:
2 性能分析
- 最优情况下,⼆叉搜索树为完全⼆叉树(或者接近完全⼆叉树),其⾼度为:
logN,搜索的时间复杂度也是O(logN) - 最差情况下,⼆叉搜索树退化为单⽀树(或者类似单⽀),其⾼度为: N,时间复杂度为
O(N)
也就是说想要实现较高的查找效率O(logN)需要让二叉树的高度劲量小,即:用二叉平衡搜索树。(二叉平衡树:左右子树高度差不大于1)
3 查找,插入,删除操作
二叉搜索树是不支持修改的,因为乱修改会破话搜索树原有的特性。
查找与插入操作:
思想基本一致:给定一个元素val遍历搜索整棵树,过程类似二分查找,当val > root->val,就往右边走,反之,往左边走
删除操作:
主要分为三种情况:
- 删除的节点为叶子节点:直接删除
- 删除的节点为单孩子节点:把孩子交给父亲,再删除
- 删除的节点为双孩子节点:替换方法:(1)用要删除节点的左子树中的最大值(这个最大值一定是叶子节点)替换要删除的节点的值,然后再把这个叶子节点删掉。(2)或者,用右子树中的最小值来替换
bool Erase(const int& val)
{// 删除大体上分三种情况:1、删除叶子,2、删除单孩子节点,3、删除双孩子节点if (!_root) { return false; }TreeNode* erase = _root;TreeNode* eraseparent = _root;while (erase){if (erase->_val > val){eraseparent = erase; // 记录父亲节点erase = erase->_left;}else if (erase->_val < val){eraseparent = erase;erase = erase->_right;}else // 找到要删除的节点{if (!erase->_left || !erase->_right) // 处理 叶子节点 和 单孩子节点的情况{if (erase == _root) // 特殊处理要删除的节点为根节点时{if (erase->_left){_root = erase->_left;}else{_root = erase->_right;}}else if (eraseparent->_left == erase) // 代表要删除的节点是父节点的左孩子{if (erase->_left) // 确定要删除的节点的孩子是哪一个{eraseparent->_left = erase->_left; // 然后把它的孩子交给父亲}else{ // 不是左孩子,就是右。// 同时处理:面对叶子节点,就随便取左右孩子链接上去eraseparent->_left = erase->_right; // 被删除节点为父节点的左孩子,且有右孩子,所以把被删除节点的右孩子给父节点的左孩子}}else{if (erase->_left) // 确定要删除的节点的孩子是哪一个{eraseparent->_right = erase->_left; // 然后把它的孩子交给父亲}else{ // 不是左孩子,就是右。// 同时处理:面对叶子节点,就随便取左右孩子链接上去eraseparent->_right = erase->_right;}}delete erase; // delete nullptr 不会出问题return true;}// 处理双节点情况(这里选择去左子树找最大节点)else{TreeNode* replaceparent = erase;TreeNode* replace = erase->_left;while (replace->_right){replaceparent = replace;replace = replace->_right;}// 找出来的最大节点一定是叶子节点erase->_val = replace->_val; // 替换if (replaceparent->_left == replace){replaceparent->_left = nullptr;}else{replaceparent->_right = nullptr;}delete replace;return true;}}}return false;
}
如果需要更多实现代码(包括key:value的二叉搜索树的实现),可以访问我的github仓库
4 ⼆叉搜索树key和key/value
key:只有key作为关键码,结构中只存储key,关键码即为需要搜索到的值,且key不支持修改。set就是只存储键的。key/val:存储键值对key: val的,搜索和查找时,只根据key的值进行查找,可以修改key对应的val的值。map就是存储键值对的。
二,set
set像python里面的集合,set不允许有重复的键存在(也就是说有去重效果),multiset允许
set的声明:

T就是元素,也就是键Compare是仿函数,默认要求T支持小于比较,如果不支持或者像更改比较方式,需要自己时间仿函数传入。- ⼀般情况下,我们都不需要传后两个模版参数。
大部分接口和之前的string、vector相同,介绍几个特别的。
lower_bound

lower_bound(a):返回第一个不小于a的迭代器upper_bound(b):返回第一个大于b的迭代器
为什么这样设计呢?因为大多数方法的迭代器要求都是传入左闭右开区间。
equal_range
equal_range(b)找到所有值等于b的迭代器的区间
使用
insert接收一个initializer_list作为参数find:找到了就返回对应元素的迭代器,没找到返回end()count:返回找到的个数erase:会造成迭代器失效
int main()
{set<int> s = {1,2,3};// 插入s.insert({ 4,5,6 });s.insert(7);s.insert(7);s.insert(7);// 搜索s.find(7); // 找到了返回对应键的迭代器if (s.find(8) == s.end()) // 没找到返回s.end(){cout << "买找到" << endl;}// 迭代器auto it = s.begin();while (it != s.end()){cout << *it << " ";it++;}cout << endl;// it = s.begin();// s.erase(it);// cout << "迭代器失效 :" << *it << endl;multiset<int> s2 = { 1,1,1,1,0,0,0 };cout << s2.count(1) << endl; // 返回找到的个数cout << s2.count(2) << endl;}
运行结果:

三,map
1 基本介绍
map像python里面的字典,map不允许有重复的键存在multimap允许
map的原型:

T就是对应的value
map的元素是键值对pair类型的,pair<key, value>是一个结构体,第一个元素first是键,第二个元素second是值:

pair的排序顺序是:按key比,key相同再比value(默认按字典顺序)map的操作都是按key来操作的key不能修改,但是对应的value可以修改- 大部分接口和方法与
set类似 set和map插入元素以后,会按key的大小排序,默认是从小到大的。这个“排序”会影响iterator的遍历顺序…insert一个已经存在的键,是不会被修改的
2 使用示例
2.1 初始化map
方法一:(显示定义pair对象):
pair<string, string> kv1("first", "第一个");
map<string, string> dict1 = {kv1};
方法二(匿名对象):
dict1.insert(pair<string, string>("second", "第二个"));
方法三(用隐式类型转换):
dict1.insert({ "left", "左边" });
在这里{ "left", "左边" }被隐式类型转换成pair类型,同时也是匿名对象(隐式转换指的是编译器自动进行的类型转换)
2.2 [ ]
dict[key] = value
key不存在的时候,会创建一个key: valuekey存在时,dict[key]会返回对应value的引用,则dict[key] = value会修改dict[key]的值
使用示例:
int main()
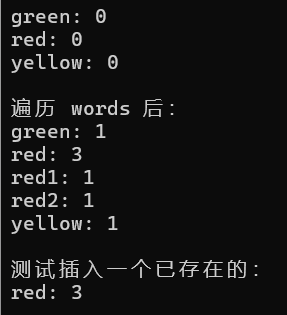
{// 隐式类型转换成pair,然后用多个pair构成的初始化列表调用构造函数初始化dictmap<string, int> dict = { {"red", 0},{ "green",0 } };dict.insert({"yellow", 0});Print(dict);vector<string> words = { "red","green","red","yellow","red2","red1","red" };cout << "遍历 words 后:" << endl;for (auto word : words){if (dict[word]){dict[word] += 1;}else{dict[word] = 1;}}Print(dict);cout << "测试插入一个已存在的:" << endl;dict.insert({ "red", 1 });cout << "red: " << dict["red"] << endl;return 0;
}
运行结果:
multimap
multimap允许有多个相同的key存在
multimap和multiset都没有[],erase的话会把所有key对应的都删掉
int main()
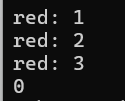
{multimap<string, int> dict = { {"red", 1} };dict.insert({ "red", 2 });dict.insert({ "red", 3 });multimap<string, int>::iterator it = dict.begin();while(it != dict.end()){cout << it->first << ": " << it->second;cout << endl;it++;}dict.erase("red");cout << dict.size();return 0;
}
运行结果:
四,其他知识
<algorithm>里面的sort()是快排,具有不稳定性,如果需要使用稳定的排序,可以使用stable_sort()
🌈我的分享也就到此结束啦🌈
要是我的分享也能对你的学习起到帮助,那简直是太酷啦!
若有不足,还请大家多多指正,我们一起学习交流!
📢公主,王子:点赞👍→收藏⭐→关注🔍
感谢大家的观看和支持!祝大家都能得偿所愿,天天开心!!!



)

