AI Agent系列【十】
- 前言
- 一、 Open Interpreter
- 1.1 Open Interpreter的特点
- 1.2 Open Interpreter的优势
- 1.3 Open Interpreter的应用场景
- 二、DB-GPT
- 2.1 核心能力
- 2.2关键特性:
- 2.3 系统架构
- 三、DeepBI
- 3.1 特点
前言
DataAgent的能力本质上比较依赖大模型的自然语言转API/SQL/代码的能力,目前有很多开源的项目可以供参考学习。
一、 Open Interpreter
Open Interpreter是一款革新性的工具,它让大语言模型在本地环境中执行多种语言代码,无需联网,它能直接与通用大模型交互从而实现简易智能体。
作为最基本和直接的实现数据分析的方式,其本质上是个高效的python代码Interpreter,属于当前最强大的开源代码解释器之一,其完美复刻了OpenAI代码解释器的实现,并额外支持读取本地各种文件的功能。
Open Interpreter核心设计理念是讲大模型生成的代码在本地执行并将结果与历史对话(上下文)一起再交给LLM来不断交互,改进。
1.1 Open Interpreter的特点
- 无需联网:Open Interpreter可以在本地环境中运行,无需联网,解决了传统代码执行方式中需要联网的限制。
- 多语言支持:Open Interpreter支持多种编程语言,如Python、JavaScript、Shell等,可以满足不同开发者的需求。
- 强大的功能:Open Interpreter不仅支持代码生成、图像操作、数据分析等操作,还可以控制Chrome浏览器进行搜索,创建和编辑照片、视频、PDF等文件,具有强大的通用功能。
1.2 Open Interpreter的优势
- 提高代码执行效率:由于Open Interpreter无需联网,因此可以大大提高代码执行的效率,特别是在网络不稳定或无法联网的情况下。
- 保障数据安全:Open Interpreter在本地环境中运行,可以有效避免数据泄露和安全问题,保护用户的隐私和数据安全。
- 灵活性和可扩展性:Open Interpreter可以完全访问互联网,不受运行时间或文件大小的限制,可以使用任何软件包或库,具有极高的灵活性和可扩展性。
1.3 Open Interpreter的应用场景
本地开发:Open Interpreter可以作为本地开发环境,支持多种编程语言,方便开发者进行代码编写、调试和测试。
数据处理和分析:Open Interpreter支持数据分析操作,可以帮助用户处理和分析大型数据集,为数据科学家和分析师提供强大的工具。
图像和视频处理:Open Interpreter支持创建和编辑照片、视频等文件,可以作为图像处理和视频编辑的辅助工具。
开源项目地址:https://github.com/KillianLucas/open-interpreter
二、DB-GPT
DB-GPT是一个国内团队以重新定义数据交互为使命的开源项目。目的是构建大模型领域的基础设施,通过开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单,更方便。
2.1 核心能力
-
RAG(Retrieval Augmented Generation):RAG是当下落地实践最多,也是最迫切的领域,DB-GPT目前已经实现了一套基于RAG的框架,用户可以基于DB-GPT的RAG能力构建知识类应用。
-
GBI:生成式BI是DB-GPT项目的核心能力之一,为构建企业报表分析、业务洞察提供基础的数智化技术保障。
-
微调框架: 模型微调是任何一个企业在垂直、细分领域落地不可或缺的能力,DB-GPT提供了完整的微调框架,实现与DB-GPT项目的无缝打通,在最近的微调中,基于spider的准确率已经做到了82.5%
-
数据驱动的Multi-Agents框架: DB-GPT提供了数据驱动的自进化Multi-Agents框架,目标是可以持续基于数据做决策与执行。
-
数据工厂: 数据工厂主要是在大模型时代,做可信知识、数据的清洗加工。
-
多数据源: 对接各类数据源,实现生产业务数据无缝对接到DB-GPT核心能力。
2.2关键特性:
● 私域问答&数据处理&RAG
支持内置、多文件格式上传、插件自抓取等方式自定义构建知识库,对海量结构化,非结构化数据做统一向量存储与检索
● 多数据源&GBI(Generative Business Intelligence)
支持自然语言与Excel、数据库、数仓等多种数据源交互,并支持分析报告,可对接各类数据源,包括SQL,CSV,Excel。
● 多模型管理
海量模型支持,包括开源、API代理等几十种大语言模型。如LLaMA/LLaMA2、Baichuan、ChatGLM、文心、通义、智谱、星火等。
● 隐私安全
通过私有化大模型、代理脱敏等技术保障数据的隐私安全。
2.3 系统架构
具体架构示意图:
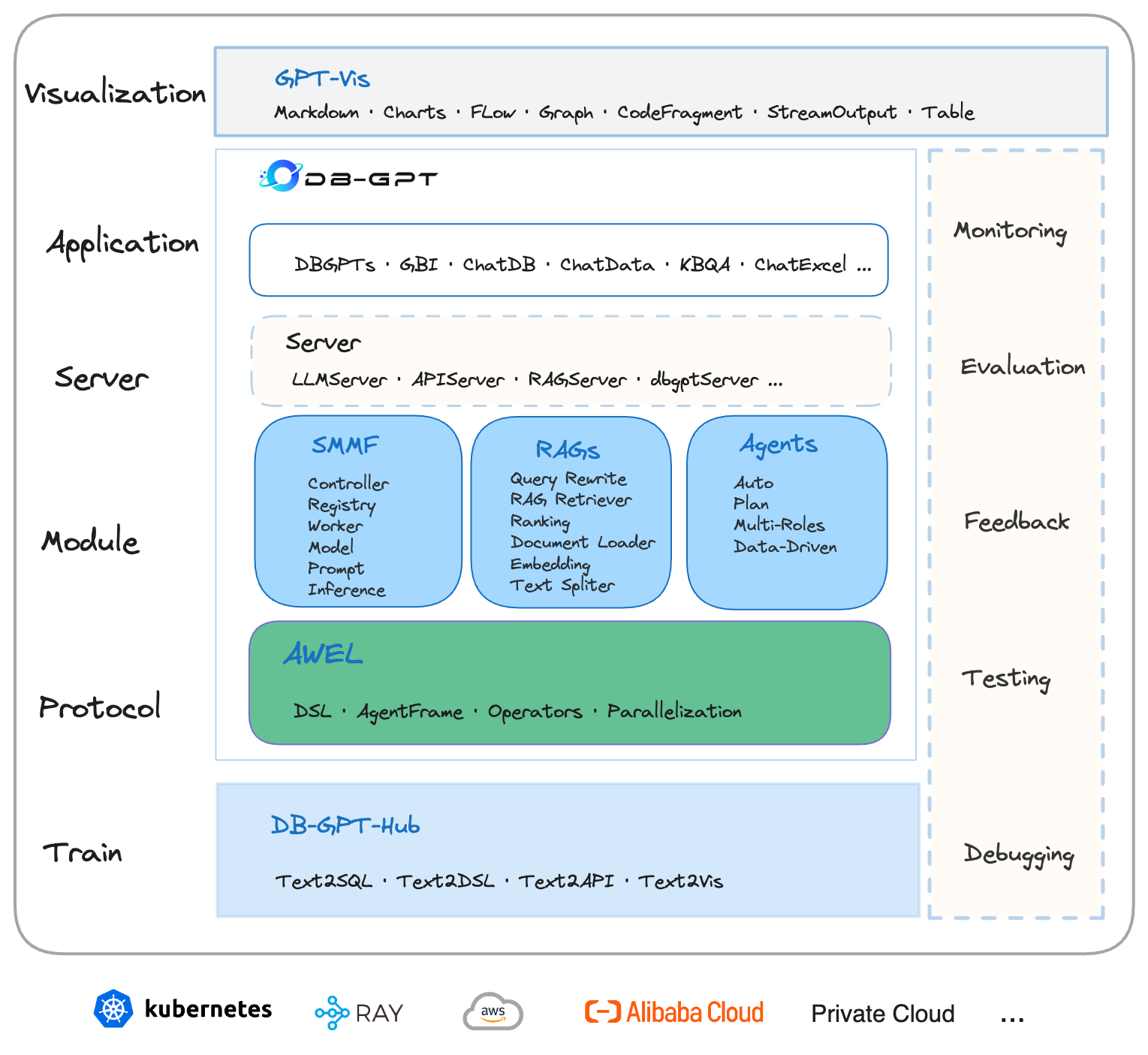
Train(训练层): DB-GPT-Hub 旨在增强文本转 SQL 中的模型性能 项目地址
Protocol(协议层): 通过标准协议编排自己智能的工作流。
Module(模块层):SMMF 服务化多模型管理框架,云原生的那一套微服务的架构,应用服务通过微服务的方式去服务,在大模型领域中,把模型进行了服务化,调用模型就相当于调用服务一样,通过服务的方式使用各种各样的模型。
RAGS 有了大模型这个超级大佬,那我们去管理私域知识,通过私域知识构建我们 Agents 工作时上下文。Agents 具体要做一些事情,通过这个 Agents 去实现的。
Server(服务层): 真正和客户端去交互,去工作的,去连接的接口层。
Application(应用层): 像 ChatDB、ChatData 等都是基于 Server 层进行实现的。
Visualization(可视层): 实际生产环境中可以服用,让大模型通过标准协议进行反馈。提供整体效果的微调。
开源项目地址:https://github.com/eosphoros-ai/DB-GPT
三、DeepBI
DeepBI 是一个开源的大型语言模型 (LLM) 的 AI 原生数据分析平台,利用大语言模型的力量来探索、查询、可视化和分享来自任何数据源的数据。可以使用 DeepBI 来获得数据洞察并做出数据驱动的决策。该平台支持多种数据源,包括 MySQL、PostgreSQL、Doris、StarRocks、CSV/Excel 等,方便用户进行灵活的数据分析和可视化。
3.1 特点
● 对话式数据分析: 用户可以通过对话,得到任意的数据结果和分析结果。
● 对话式报表生成:通过对话生成持久化的报表和可视化图形。
● 仪表板大屏:将持久化的可视化图组装为仪表板。
● 自动化数据分析报告:根据用户指令自动完成完整的数据分析报告。
● 多数据源支持:支持 MySQL、PostgreSQL、Doris,Starrocks, CSV/Excel等。
● 多平台支持:支持 Windows-WSL、Windows、Linux、Mac。
● 多语言支持:支持中文、英文。
开源项目地址:https://github.com/DeepInsight-AI/DeepBI


)

