实验目的
- 学习编制多进程并行程序实现如下功能:
- 创建多进程,输出进程号和进程数。
- 运行多进程并行例子程序。
- 编程实现大规模矩阵的并行计算。
实验过程及结果分析
实验环境
- 操作系统:Ubuntu 20.04
- 开发工具:GCC 9.3.0、OpenMPI 4.0.3
实验步骤
多主机无密码登录配置
-
在任意一台主机上生成RSA密钥对:
ssh-keygen -t rsa -C "Kevin"
该命令将在用户主目录下的 ~/.ssh/ 目录中生成id_rsa和id_rsa.pub两个文件。
-
将生成的公钥内容追加至同目录下的
authorized_keys文件中,授权本主机信任该密钥登录:cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys此时,将该
authorized_keys文件拷贝到其他主机,以建立互信。 -
为便于多主机通信与配置,使用以下命令将三台主机分别命名为
master、slave1和slave2:sudo vim /etc/hostname -
编辑
/etc/hosts文件,添加各主机的IP与主机名映射,例如:192.168.1.100 master 192.168.1.101 slave1 192.168.1.102 slave2 -
重启三台主机,而后使用
ssh [username]命令测试主机间的无密码登录是否生效。
安装MPI环境
-
在三台主机上分别执行以下命令安装MPI环境:
sudo apt install openmpi-bin libopenmpi-dev -
验证安装是否成功:
mpicc --version mpirun --version
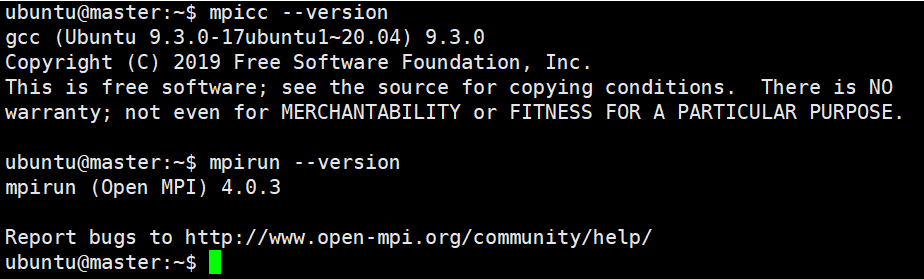 |
| 图 1 安装成功后会显示版本信息 |
配置NFS共享目录
在多主机运行MPI程序时,所有节点需要访问相同的可执行文件和输入输出路径。如果每台主机都独立保存一份代码和数据,会导致维护成本较高且容易出错。因此,此次实验使用NFS(网络文件系统)在master节点上创建共享目录,并将其挂载到所有计算节点,从而确保各节点读取到的是同一份程序和数据。
具体步骤如下:
-
在
master节点上配置NFS服务:-
安装NFS服务端:
sudo apt install nfs-kernel-server -
创建共享目录并设置权限:
sudo mkdir -p /home/ubuntu/shared sudo chown -R ubuntu:ubuntu /home/ubuntu/shared -
在
/etc/exports文件中添加:/home/ubuntu/shared *(rw,sync,no_subtree_check) -
重启NFS服务使配置生效:
sudo exportfs -a sudo systemctl restart nfs-kernel-server
-
-
在
slave1和slave2节点上挂载共享目录:-
安装NFS客户端:
sudo apt install nfs-common -
创建本地挂载点:
sudo mkdir -p /home/ubuntu/shared -
挂载共享目录:
sudo mount master:/home/ubuntu/shared /home/ubuntu/shared
-
挂载完成后,从节点可直接访问/home/ubuntu/shared目录,并与master节点保持实时同步。
MPI程序测试
单主机多进程测试
在master节点上编译运行下面的MPI程序,验证并行能力,如果主机的核心数不够,可添加 --oversubscribe 参数从而允许多个进程共享核心。
#include <mpi.h>
#include <stdio.h>int main(int argc, char **argv)
{MPI_Init(&argc, &argv);int world_rank;MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);int world_size;MPI_Comm_size(MPI_COMM_WORLD, &world_size);printf("Hello from rank %d out of %d processors\n", world_rank, world_size);MPI_Finalize();return 0;
}
运行结果:
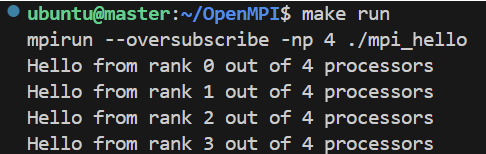 |
| 图 2 单主机多进程测试结果 |
多主机多进程测试
- 在
master节点创建主机清单文件,在其中设置每个节点的slots数:
master slots=2slave1 slots=2slave2 slots=2
-
使用
--hostfile参数指定三台主机运行:mpirun --hostfile hosts -np 6 ./mpi_hello运行结果:
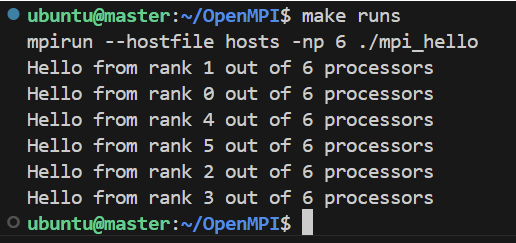 |
| 图 3 多主机多进程测试结果 |
大规模矩阵并行计算测试
在共享目录中编译并运行下面的矩阵乘法程序 :
#include <stdio.h>
#include <stdlib.h>
#include <mpi.h>
#include <string.h>
#include <time.h>#define MASTER 0void MatrixGenerate(double *mat, int size) {for (int i = 0; i < size * size; ++i)mat[i] = (double)rand() / RAND_MAX;
}void LocalMatrixMultiply(double *a_local, double *b, double *c_local, int local_rows, int size) {for (int i = 0; i < local_rows; ++i)for (int j = 0; j < size; ++j) {double sum = 0.0;for (int k = 0; k < size; ++k)sum += a_local[i * size + k] * b[k * size + j];c_local[i * size + j] = sum;}
}int main(int argc, char *argv[]) {int rank, size;MPI_Init(&argc, &argv);MPI_Comm_rank(MPI_COMM_WORLD, &rank);MPI_Comm_size(MPI_COMM_WORLD, &size);int test_sizes[] = {1000, 2000, 3000};int num_tests = sizeof(test_sizes) / sizeof(int);for (int test = 0; test < num_tests; ++test) {int matrix_size = test_sizes[test];int rows_per_proc = matrix_size / size;int remaining = matrix_size % size;int local_rows = rows_per_proc + (rank < remaining ? 1 : 0);int offset = rank * rows_per_proc + (rank < remaining ? rank : remaining);double *A = NULL, *B = NULL, *C = NULL;double *A_local = (double *)malloc(local_rows * matrix_size * sizeof(double));double *C_local = (double *)malloc(local_rows * matrix_size * sizeof(double));B = (double *)malloc(matrix_size * matrix_size * sizeof(double));if (rank == MASTER) {A = (double *)malloc(matrix_size * matrix_size * sizeof(double));C = (double *)malloc(matrix_size * matrix_size * sizeof(double));srand(time(NULL) + test); // 避免相同种子MatrixGenerate(A, matrix_size);MatrixGenerate(B, matrix_size);}// 广播 B 矩阵MPI_Bcast(B, matrix_size * matrix_size, MPI_DOUBLE, MASTER, MPI_COMM_WORLD);// 发送 A 子矩阵if (rank == MASTER) {int pos = 0;for (int i = 0; i < size; ++i) {int send_rows = rows_per_proc + (i < remaining ? 1 : 0);if (i == MASTER) {memcpy(A_local, A + pos * matrix_size, send_rows * matrix_size * sizeof(double));} else {MPI_Send(A + pos * matrix_size, send_rows * matrix_size, MPI_DOUBLE, i, 0, MPI_COMM_WORLD);}pos += send_rows;}} else {MPI_Recv(A_local, local_rows * matrix_size, MPI_DOUBLE, MASTER, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);}// 开始计时并进行乘法double start = MPI_Wtime();LocalMatrixMultiply(A_local, B, C_local, local_rows, matrix_size);double end = MPI_Wtime();// 收集结果if (rank == MASTER) {int pos = 0;memcpy(C + pos * matrix_size, C_local, local_rows * matrix_size * sizeof(double));pos += local_rows;for (int i = 1; i < size; ++i) {int recv_rows = rows_per_proc + (i < remaining ? 1 : 0);MPI_Recv(C + pos * matrix_size, recv_rows * matrix_size, MPI_DOUBLE, i, 1, MPI_COMM_WORLD, MPI_STATUS_IGNORE);pos += recv_rows;}printf("Matrix Size %dx%d, Time = %.3f seconds\n", matrix_size, matrix_size, end - start);} else {MPI_Send(C_local, local_rows * matrix_size, MPI_DOUBLE, MASTER, 1, MPI_COMM_WORLD);}// 清理内存free(A_local); free(C_local); free(B);if (rank == MASTER) {free(A); free(C);}}
单主机运行结果:
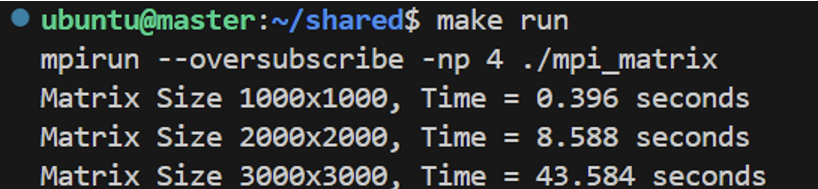 |
| 图 4 单主机矩阵运算结果 |
多主机运行结果:
 |
| 图 5 多主机矩阵运算结果 |
可以看到,随着任务规模扩大,多主机MPI并行计算在性能上展现出明显优势。
问题分析
初次运行程序时,可能出现通信错误:
ubuntu@master:~/shared$ make runs
mpirun --hostfile hosts -np 6 ./mpi_matrix
[slave1][[55832,1],2][btl_tcp_endpoint.c:625:mca_btl_tcp_endpoint_recv_connect_ack] received unexpected process identifier [[55832,1],3]
经排查发现,原因在于通过OpenMPI进行多主机运行时,OpenMPI会寻找主机之前的所有IP接口,但是程序实际上不会用到所有的IP接口,从而发生运行时阻塞或连接被拒绝得问题。所以此时需要通过--mca btl_tcp_if_include 参数来限制网络接口。
mpirun --hostfile hosts --mca btl_tcp_if_include eth0 -np 6 ./mpi_matrix
通过显式指定接口为eth0后,问题得以解决。
总结
通过本次实验,我系统掌握了分布式MPI环境的搭建流程,也进一步巩固了SSH无密码登录以及NFS共享配置的方法。实验中通过多主机MPI程序运行验证了并行计算在大规模数据处理中的高效性。这让我联想到在数据库系统中也有通过部署大规模集群来实现高并发访问和海量数据处理的能力,不过我并不确定这两者之间的原理是否相同,希望以后有机会能进一步学习其中的原理。





