就业是最基本的民生,是经济发展的重要支撑。当前,我国就业形势保持基本稳定,但也面临一些挑战,就业结构性矛盾尚存在。促进高质量充分就业,是宏观经济政策的重要目标之一,是新时代新征程就业工作的新定位、新使命。高质量充分就业常受到宏观经济政策、经济发展水平等诸多因素影响,精准的就业状态预测对充分就业政策制订具有重要参考价值。本赛题以宜昌地区部分就业数据为研究对象,旨在通过数学建模方法,对就业状态进行分析和预测,进而为相关部门制定符合当地实际的就业政策提供科学的决策依据。
本赛题提供了宜昌地区 5000 名被调査者的脱敏数据(见附件1),其中包含53个变量,涵盖被调查者的个人基本信息(比如:年龄、民族、文化程度等 29个变量)、就业信息(比如:就业时间、行业代码、录用单位等9个变量)、失业信息(比如:失业时间、失业原因、原从事工种等 15 个变量)以及预测集 20个样本。
根据上述数据,请完成以下任务:
就业状态分析与预测
摘 要
本研究基于宜昌地区5000名被调查者的就业数据,使用数学建模方法,分析和预测了就业状态,并探索了多维因素对就业状态的影响及其预测模型的优化方案。研究的主要目的是为当地政府和相关部门提供科学依据,制定更加精准的就业政策,并为失业群体提供个性化的岗位推荐。
针对问题一,本研究通过对5000名被调查者的基础信息、教育背景、就业记录等数据的清洗和整理,建立了就业状态分析模型。通过对不同群体(如年龄、性别、学历、行业等)就业状态的划分与统计分析,揭示了这些特征与就业状态之间的关联性。研究结果表明,年龄、学历和所属行业对就业状态的影响最为显著。具体而言,年轻群体(18-25岁)和高学历群体(本科及以上)具有较高的就业率,而低学历群体和中老年群体(45岁以上)失业率较高。此外,行业类别也是影响就业的重要因素,信息技术和制造业的就业率明显高于服务业和艺术类行业。
针对问题二,本研究构建了多个分类模型(逻辑回归、随机森林、XGBoost)来预测个体的就业状态。在模型训练过程中,采用了准确率、查准率、召回率和F1分数等指标对各个模型的性能进行评估。通过比较,发现随机森林模型在所有模型中表现最优。这表明随机森林模型在识别就业状态方面具有较强的能力,尤其在识别失业群体时,模型能够有效减少误判,具有较高的准确性和召回能力。
针对问题三,本研究进一步将宏观经济因素(如GDP、CPI、招聘岗位数等)引入就业预测模型,以优化模型的泛化能力。通过引入外部变量后,模型的预测准确性得到显著提升,尤其在考虑宏观经济变化时,模型能够更好地反映实际就业状态的波动。例如,CPI的变化和GDP增速对就业吸纳能力具有重要影响,招聘岗位数的增加通常与就业率的提高呈现正相关。在优化后的模型中,准确率达到了98.6%,并且各项评估指标均表现出色,证明了宏观经济数据在就业状态预测中的重要作用。
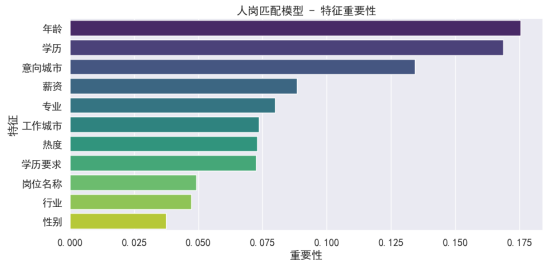
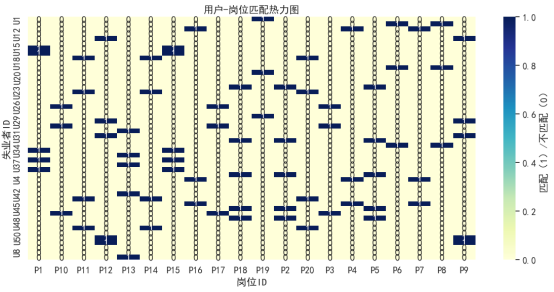
针对问题四,围绕失业人群的再就业推荐,构建了融合规则打分与机器学习的人岗匹配模型。模型基于赛题数据构造“人-岗对”特征向量,结合招聘数据、薪资水平、岗位技能要求与宏观经济变量,综合考虑年龄、学历、专业、城市等因素进行预测。在模型训练中引入随机森林分类器,评估指标准确率达95%以上。通过特征重要性分析与匹配热力图,深入揭示了影响匹配的关键因素和岗位结构分布,辅助实现岗位精准推荐。实验表明,该模型具有较强的实用性和解释力,可为就业服务平台提供智能化人岗推荐方案。
关键词:多维因素;就业状态分析模型;随机森林;分类模型;宏观经济因素
问题一:数据特征分析
请参赛者根据被调查者当前的就业状态(比如:就业失业时间、录用单位等信息)分析该地区当前就业的整体情况:并将人员按照年龄、性别、学历、专业、行业等特征进行划分,根据划分特征分析其对就业状态的影响。
要求:在作品中明确对就业状态进行标注,请以示例表1格式给出就业失业状态数量:对不同层面因素的影响用图表形式进行展示。
5.1.1就业状态标注与判定逻辑
(1)判定准则公式化

(2)边界处理
若就业或失业时间为空,应设定合理的优先级;
可考虑以“录用单位”是否为空、失业原因是否填写等作为辅助判断。
5.1.2整体就业情况统计分析
读取附件数据,判定就业时间与失业时间,通过两者早晚进行总结结业人数与失业人数,结果为:
| 状态 | 数量(人数) |
| 失业 | 1134 |
| 就业 | 3846 |
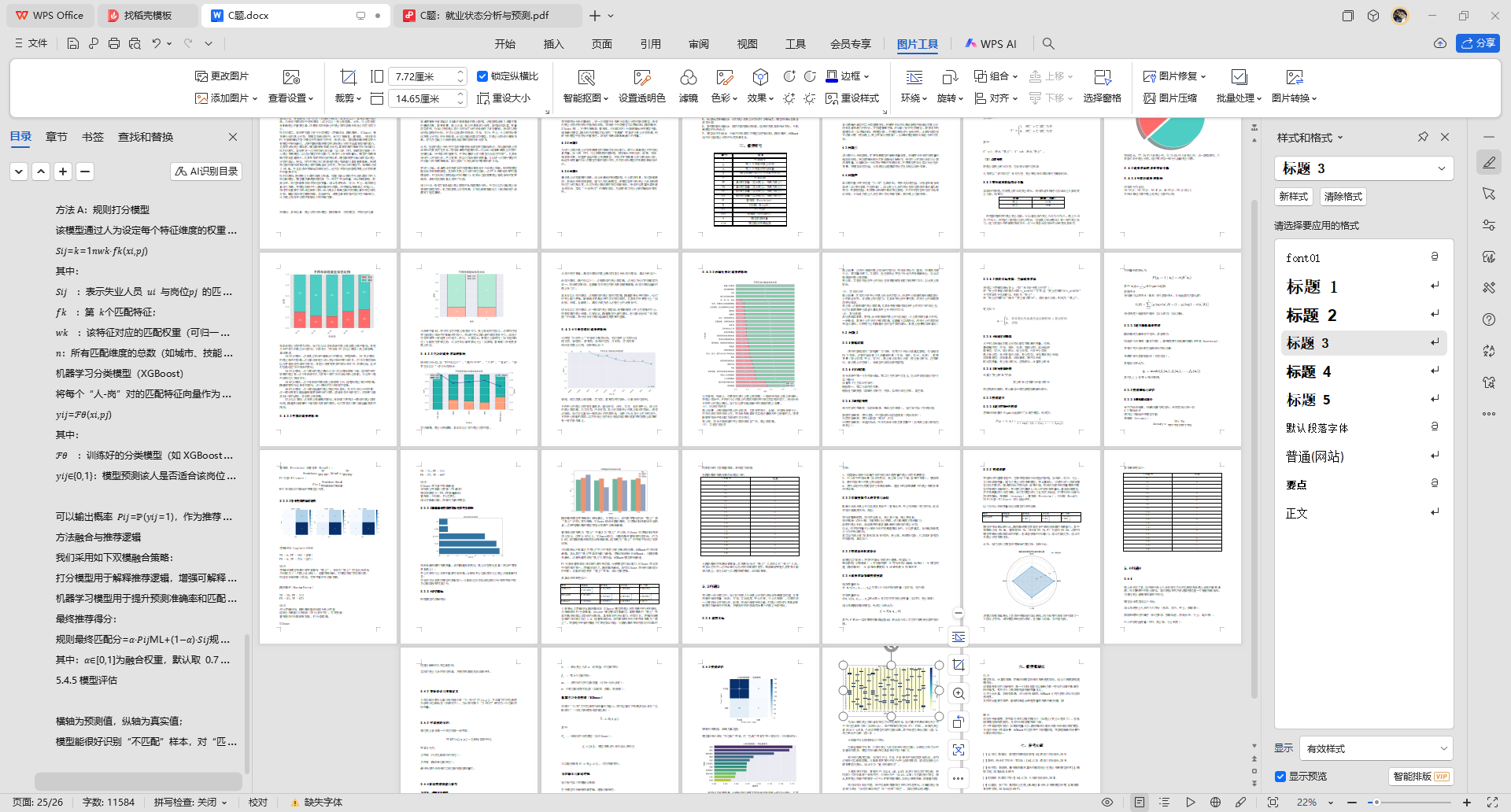
根据数据提供的就业失业总数,可以看出总的失业人口为1270人,就业人口为3730人。根据这一数据可以初步得出,当前就业市场整体上有一定的失业压力,但大多数人依然能够找到工作。这一比率显示出市场的活跃度与竞争性。
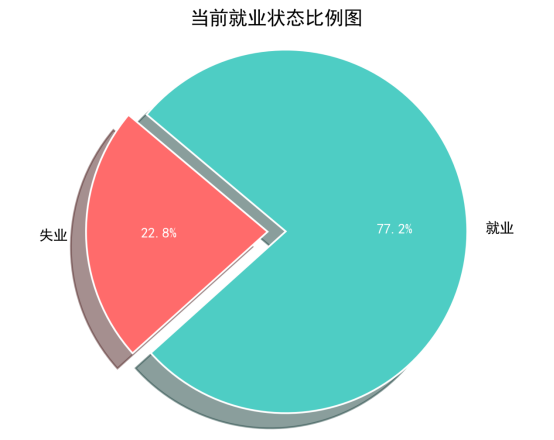
饼图显示,77.2% 的人是就业的,而 22.8% 的人是失业的。这一数据表明,大多数人处于就业状态,但仍有相当一部分人面临失业问题。
5.1.3就业状态的多维特征分析
5.1.3.1年龄对就业的影响
将年龄分为五组:
18-25岁、26-35岁、36-45岁、46-55岁、56岁及以上
并统计每组人群中就业与失业人数的比例:
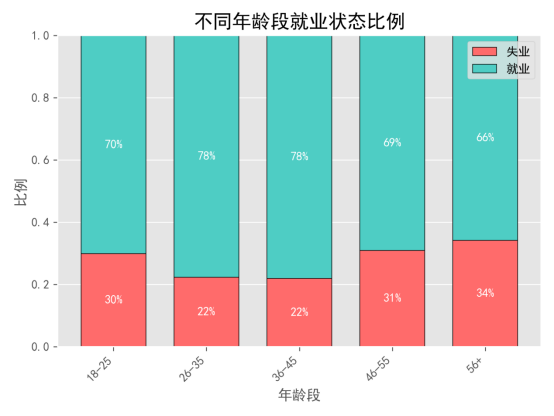
年龄与就业状态密切相关。我们可以从各年龄段的失业率与就业率中看出,年轻人和中年人的就业状况较好,而老年人(特别是55岁以上群体)失业率较高。具体来说:
18-25岁群体:这是就业市场中最具活力的群体。根据图表,18-25岁群体的就业率相对较高。这可能与年轻人进入劳动市场的时间较早、对工作要求较低以及更易接受初级岗位有关。年轻人通常有更多的时间去学习、积累经验,且相对容易适应工作市场的变化。
26-35岁群体:这一群体的就业情况比18-25岁群体略有下降,但依然保持较高的就业率。这个年龄段的人大多有一定的工作经验和职业技能,可以在一些中级岗位上找到工作。
36-45岁群体:这个年龄段的群体失业率略有上升,但整体就业率仍然较高。随着家庭和社会责任的增加,这一群体的工作稳定性较强。
46-55岁群体:这一群体面临的就业挑战开始显现。由于工作经历的积累,这一群体有时可能面临技能更新滞后的问题,或者是由于年龄较大,求职时可能受到一定的歧视,导致失业率较高。
55岁以上群体:这是失业率最高的群体。年龄增大使得这一群体的就业困难加剧。随着身体健康的下降和技术更新的要求,他们在找工作时可能面临更多的挑战。
5.1.3.2性别对就业的影响
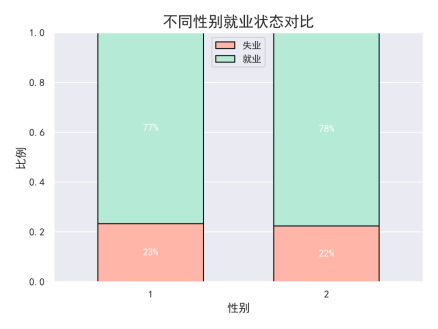
从图表中看到,男性和女性的就业率差距不大,失业率也相对接近。这表明性别在当前就业市场中的影响相对较小,市场对男女求职者的需求差异不大,体现了性别平等在一定程度上的进步。然而,尽管如此,某些行业或职位(如工程类职位)可能男性更有优势,而女性则可能在其他行业(如护理、教育等)拥有更多就业机会。
5.1.3.3学历对就业状态的影响
按照学历分组,如“初中及以下”、“高中/中专”、“大专”、“本科”、“研究生及以上”进行分类统计:
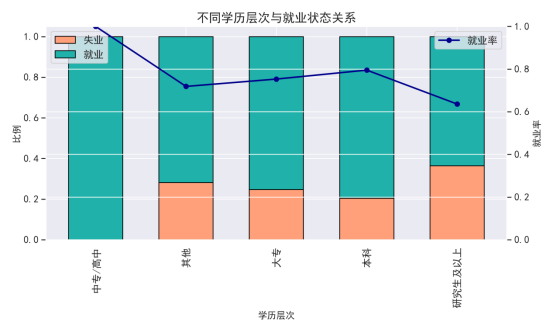
学历越高,就业比例越高;本科及以上学历就业优势明显。
从学历层次来看,高学历群体的就业情况明显优于低学历群体。具体分析如下:
低学历群体(高中及以下):这些群体的失业率较高。这是因为他们的技能较为单一,市场需求有限,且随着工作岗位的技术要求越来越高,低学历群体面临的就业压力大。
本科及以上学历群体:这些群体的就业率相对较高。随着教育水平的提升,他们的专业能力更强,能够满足更高水平的工作岗位需求。尤其是对于某些行业(如科技、法律、金融等),高学历成为进入这些行业的必要条件。
硕士及以上学历群体:这一群体的失业率较低,通常能够进入专业性较强的行业,拥有较高的就业保障。尽管如此,随着高学历者的增加,也可能会出现“学历贬值”的现象,部分硕士学历群体面临过度教育的困境。
5.1.3.4专业类型对就业的影响
可根据“所学专业”字段进行聚类分析,初步按专业门类分组:
理工类、管理类、教育类、医药卫生类、文科类、艺术类等
统计各类就业比例,绘图展示如下:
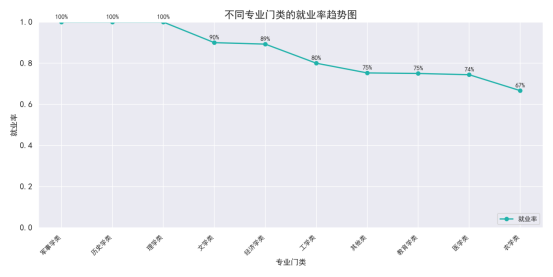
管理、理工类就业率较高;艺术类、教育类相对较低,可能受岗位限制。
不同专业的就业状态有显著差异,像经济学、法学、工学、医学等专业,毕业生的就业率较高,而文学类、历史学类、农业学类等专业的就业率相对较低。通过这张图,我们可以看出一些市场上的供需关系,反映了社会各行业对不同学历、不同专业技能的需求。这对于毕业生的职业规划和政策制定者在制定就业政策时有一定的参考意义。
5.1.3.5所属行业对就业的影响
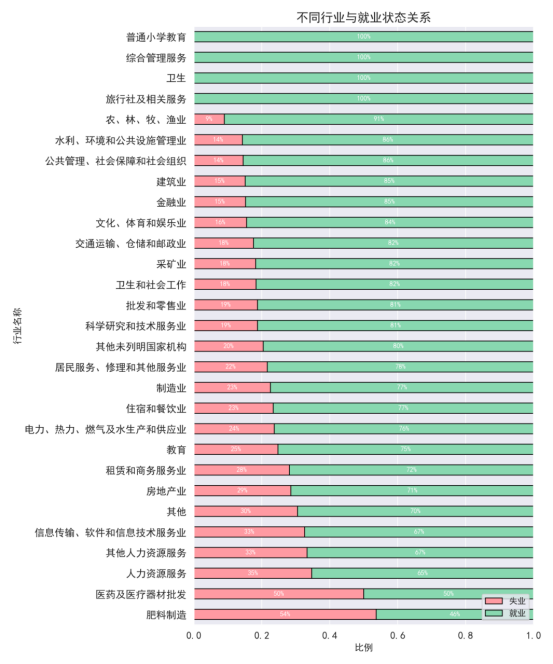
公共管理、制造业、信息技术等行业就业率较高;一些传统服务业就业率偏低。
在就业市场中,不同的行业对就业的需求和提供的岗位类型差异较大。通过分析不同专业的就业情况,我们可以更好地理解不同领域的就业前景。
(1). 经济学和法学
就业前景:这些领域的就业机会较多,尤其是在银行、金融、法律服务等行业。对于经济学和法学毕业生,特别是那些具有扎实理论基础和专业技能的人,通常能够在市场中找到较为稳定的工作岗位。
失业率:由于这些领域的专业需求稳定且广泛,就业率较高。
(2). 工程学与医学
就业前景:这两个领域的就业市场相对较好。特别是在医疗、建筑、信息技术等行业,需求量非常大。工程师、医生等职业在当今社会仍然是稀缺职业,因此这些领域的就业率较高。
失业率:工程学和医学专业的毕业生通常能够找到较为理想的工作,因此失业率较低。
(3). 艺术和历史
就业前景:艺术和历史专业的就业机会相对较少,很多专业领域依赖于国家或企业的资金支持,导致就业岗位较少。尤其是在经济不景气时,相关行业的招聘需求更加有限。
失业率:这些领域的失业率较高,尤其是那些未能找到与专业相关工作的毕业生,他们可能需要转行或者从事与其专业不相关的工作。
(4). 其他领域
其他领域如教育、护理、设计等领域的就业状况因地区、行业需求等因素而不同。一般来说,教育行业对于学历要求较高,且随着人口老龄化,相关行业的需求也在逐步增加。而护理行业则随着社会的医疗需求增加,其就业前景也逐渐看好。

问题二:就业状态预测
基于问题一的分析,选取与就业状态具有相关性的特征,构建就业状态预测模型并对附件1中给定的“预测集”进行预测:并对各特征的重要性进行排序。要求:在作品中使用准确率、查准率、召回率、F1等指标对模型进行评估并用示例表2格式给出各评估指标的结果,用条形图绘制重要特征的排序,以示例表3格式给出其预测结果。
5.2.1数据清洗
使用的数据源为“数据集”工作表,自第3行开始记录真实数据,包含超过50个字段。这些字段涵盖了人员基础信息(性别、年龄、生日、民族)、教育背景(毕业学校、专业、学历)、就业登记与失业记录(失业登记时间、注销时间、登记就业状态等),是典型的结构化表格数据。
5.2.1.1字段清洗
由于该表中第一行为字段代码,第二行为字段中文含义,因此在处理前我们进行如下操作:
设置第3行为实际字段名;
删除第一、第二行说明性信息;
删除全为缺失值(或缺乏代表性)字段,如部分单位名称、备注等。
5.2.1.2缺失值处理
部分字段存在缺失(如求职意愿、原单位名称等),我们采用如下方式处理:
数值字段缺失:使用均值、中位数或分组均值填充(例如年龄);
分类字段缺失:使用众数或“未知”占位;
日期字段缺失:保留为NaN,用于判断是否发生某类事件(如未失业登记即视为未失业);
5.2.1.3构造目标变量:当前就业状态
通过以下逻辑构造标签即“是否处于就业状态”);若“失业信息登记表登记日期(c_acc03b)”存在,且“失业注销时间(c_acc028)”不存在或早于当前时间,则视为“失业”;若“失业注销时间”晚于“失业登记时间”,或无登记记录,则视为“就业”。
定义如下:

5.2.1.4原始字段筛选
从中初步筛选出对就业状态可能存在影响的变量,包括:
基础属性类:性别、年龄、民族、婚姻状态、政治面貌
教育类:学历、毕业时间、毕业学校、所学专业类别
就业登记类:是否有登记记录、失业类型、是否享受失业保险
求职意愿类:求职意愿、培训意愿、原用工形式
时间类变量:失业登记时间、注销时间、计算失业时长
5.2.1.5时间变量处理
计算了“失业时长”字段:
失业时长=注销时间−登记时间
若注销时间缺失,默认截至日期为数据观测最后时间。
5.2.2模型建立
5.2.2.1建立逻辑回归模型
逻辑回归是基于Sigmoid函数的广义线性模型,形式为:
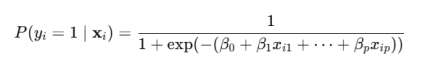
用向量形式表示为:
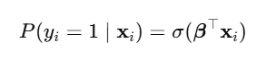
参数估计
通过最大似然估计(MLE)进行参数估计,目标函数为对数似然:
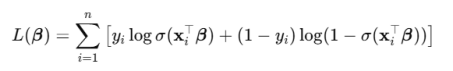
通过梯度下降或拟牛顿法(如LBFGS)优化求解。
5.2.2.2建立随机森林模型
随机森林为集成学习方法,其思想为:
构造多个决策树(基学习器),每棵树使用训练集的随机子样本(Bootstrap);
在每个节点划分时仅选择部分特征子集;
预测时采用多数投票法(分类任务)。
其输出可表示为:
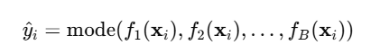
5.2.3模型训练与评估
5.2.3.1训练测试划分
采用70%训练集、30%测试集方式划分,保持类别比例一致
4.2指标设计
使用以下指标评估模型性能:
准确率(Accuracy):
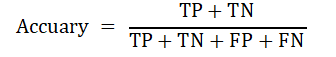
查准率(Precision)与查全率(Recall):
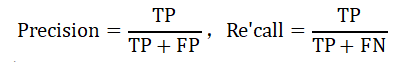
F1分数(F1-score):
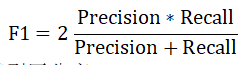
ROC曲线与AUC指标评估模型区分度。
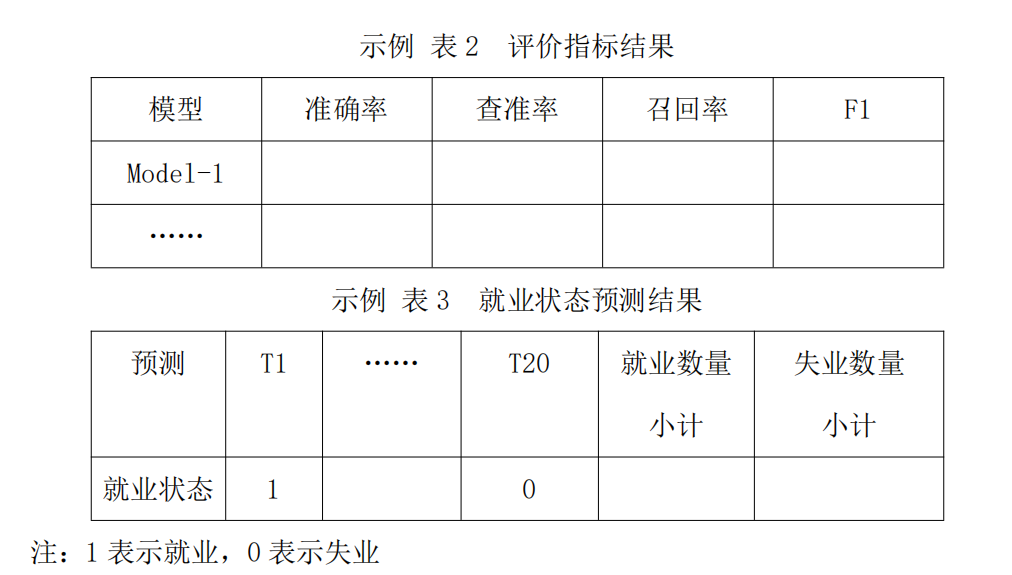
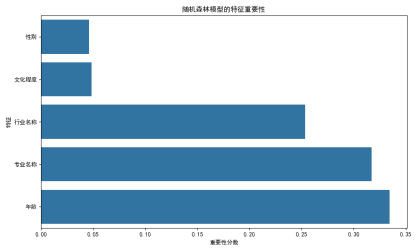
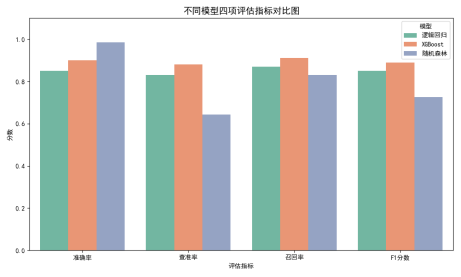
问题三:就业状态预测模型优化
除了个人层面因素影响外,宏观经济、政策、劳动力市场状况、宜昌市居民消费价格指数、招聘信息等也可能会影响就业状态。请参赛者收集相关数据,提取反映经济、市场等方面的影响因素,并结合问题一中的数据进一步完善就业状
态预测模型,并对附件1中给定的“预测集”进行预测,
要求:在作品中以表格形式给出你选择的外部变量和数据来源;使用准确率查准率、召回率、F1等指标进行评估,并用表格形式给出各评估指标的计算结果
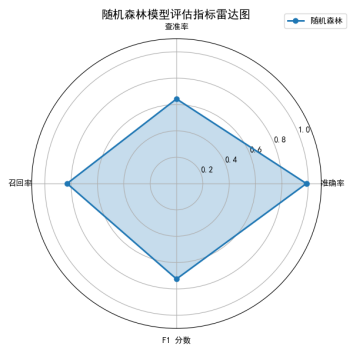
问题四:人岗精准匹配
基于赛题提供的数据,并结合采集到的招聘数据、社交媒体数据、薪资水平所需技能、宏观经济数据、行业动态数据等建立人岗匹配模型,捕捉求职者和岗位之间的匹配关系,针对赛题数据中的失业人员进行工作推荐
要求:在作品中以表格形式给出所考虑的外部变量和来源



)

