简介
最近在学习I2S音频相关内容,无可避免会涉及到关于音频格式的内容,所以刚开始接触的时候有点一头雾水,后面了解了下WAV相关内容,大致能够看懂wav音频格式是怎么样的了。本文主要为后面ESP32 I2S音频系列文章做铺垫,所以本篇将介绍WAV音频文件格式,并通过C代码生成一段1S的正弦波WAV音频写入到SD卡里面。
WAV(Waveform Audio File Format) 是一种音频文件格式,用于存储音频数据。它是由 微软 和 IBM 开发的,通常用于存储高质量的原始音频数据。
如果一段单声道音频的采样率为 44100 Hz,一分钟的音频数据大约有 5.04MB。这个值是可以大致计算的,后面我们会提到。WAV 文件一般未经过压缩,因此能够提供音频的 高保真度,但相比其他音频格式,相同时间内的文件会显得较大。所以一开始我打算用SPIFFS存储WAV音频的时候发现好像不太现实,毕竟ESP32 SPIFFS空间太小了,而 WAV文件几秒的音频动不动就好几M了,这样子的话只能播放短时间的音频就不符合我的要求了。
WAV文件基于RIFF格式,这是一种用于存储多媒体数据的通用格式。
也就是说WAV是基于RIFF格式的一种具体应用,RIFF格式还被用于许多其他文件类型。
什么是RIFF格式
RIFF(Resource Interchange File Format,资源交换文件格式)是一种通用的文件格式标准,由微软和IBM于1991年联合开发,用于存储和交换多媒体数据,如音频、视频、图像等。RIFF格式以其灵活性和可扩展性著称,能够容纳各种类型的数据,并被广泛应用于多种文件类型,例如:
- WAV(音频)
- AVI(视频)
- ANI(动画光标)
可以简单理解为它是一种通用的文件容器格式,它通过一个个块的形式(称之为chunk)存储多媒体数据。
以下是基于RIFF格式的不同文件类型及其用途的表格:
| 文件类型 | 扩展名 | 用途 |
|---|---|---|
| WAV | .wav | 存储音频数据 |
| AVI | .avi | 存储音频和视频数据 |
| RMI | .rmi | 存储MIDI音乐数据 |
| ANI | .ani | 存储动画光标 |
| WEBP | .webp | 存储图像数据(主要用于Web) |
可以看到除了WAV是基于RIFF格式的,还有其他文件类型也是基于RIFF的,这里我们也可以看到很多文件格式会用特定的标识符,比如WAV, AVI,这里就涉及到FOURCC标识符。RIFF 文件的结构通常以标识符 “RIFF” 开头,紧接着是文件大小(4 字节),再后面跟着的就是一个四字符代码(FOURCC),用于指明文件的数据类型。
FOURCC标识符
FOURCC(Four-Character Code,四字符代码)是由 4 个字节组成的标识符,通常使用可打印的 ASCII 字符,它在 RIFF 文件中用来标识数据的具体格式。比如:
WAV 文件:以 “RIFF” 开头,FOURCC 为 “WAVE”,表示这是一个音频文件。
AVI 文件:以 “RIFF” 开头,FOURCC 为 "AVI “”(注意末尾有空格),表示这是一个视频文件。
FOURCC 的设计要求正好 4 个字符,如果不足则用空格填充,且对大小写敏感。这种标识方式不仅用于文件类型的最顶层定义,还用于文件内部的各个数据块,每个数据块称作一个chunk,比如 WAV 文件中包含 "fmt "(格式信息)和 “data”(音频数据)这两个chunk。
字节序
WAV文件的字节数据还涉及到字节序的问题。字节序(Byte Order)是指多字节数据(如整数、浮点数等)在计算机内存中存储的顺序。不同的计算机体系结构可能采用不同的字节序方式,这可能会导致在不同平台之间传输数据时出现问题。字节序问题主要体现在多字节数据的存储顺序上,尤其是在跨平台的数据交换和存储中需要特别注意。根据字节存储时从低位开始还是从高位开始分为两种:大端序和小端序。
大端序(Big-Endian)
大端字节序是一种字节顺序,其中数据的高字节存储在内存的低地址处,低字节存储在高地址处。
例如,对于一个4字节的整数 0x12345678,它的字节序会按以下顺序存储:
| 地址 | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| 数据 | 0x12 | 0x34 | 0x56 | 0x78 |
这种存储方式类似于我们阅读数字的顺序,从左到右。
小端序(Little-Endian)
小端字节序是一种字节顺序,其中数据的低字节存储在内存的低地址处,高字节存储在高地址处。
对于同样的4字节整数 0x12345678,它的字节序会按以下顺序存储:
| 地址 | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| 数据 | 0x78 | 0x56 | 0x34 | 0x12 |
这种存储方式将数字的低位放在前面,更符合计算机内部的处理逻辑。
WAV文件结构
WAV文件基于RIFF格式。RIFF格式的结构是一个个块构成的,一个块称为一个chunk,每个chunk都有一个4字节的ID(FOURCC),紧随其后的是4字节的块大小(chunk size),然后是块数据 (data) 。 最外层的是RIFF chunk,里面在套着"fmt" chunk和"data" chunk。

我们来看一下WAV文件的结构:

这张图的最左边是字节序,然后是偏移量,每个数据字段区域的名称及对应区域的字节大小。
字节序:
前面我们提到WAV的字节序问题,那在WAV中每个chunk里面的字节数据是以什么方式存储的呢?在RIFF格式中,所有多字节的 数值数据(如块大小、音频采样率等)都以小端序存储。而ID,即FOURCC标识符,是4个ASCII字符的组合,按照ASCII字符的顺序直接存储, 所以它的字节序是大端序。
偏移量:
偏移量是指当前数据字段相对于文件开始位置的字节数。比如ChunkID的偏移量是0,表示它是文件的开始部分;ChunkSize的偏移量是4,表示它从文件的第4个字节开始,
WAVE音频文件结构主要分为三个部分:
1. RIFF Chunk Descriptor (偏移量0-12)
这是文件的头部,提供文件的身份和基本信息:
- ChunkID (偏移量0,4字节) 标识文件为RIFF类型,通常为字符串 "RIFF"。 每个字符在ASCII表中都对应一个十六进制数。比如,R的ASCII码是0x52,I是0x49,F是0x46,第二个F也是0x46,那连起来的话, "RIFF"这四个字母对应的ASCII码就是0x52 0x49 0x46 0x46。
- ChunkSize (偏移量4,4字节) 表示整个文件的大小(不包括前8字节,即 ChunkID 和 ChunkSize)。
- 整个文件大小(不包含前8字节)=
36 + SubChunk2Size或4 + (8 + SubChunk1Size) + (8 + SubChunk2Size)或文件总大小-8 - Format (偏移量8,4字节) 指定文件格式为 "WAVE"。对应57 41 56 45。
2. fmt Sub-chunk (偏移量12-36)
这部分描述音频的格式信息,是播放或处理音频时必须了解的关键数据:
- Subchunk1ID (偏移量12,4字节) 标识这是 "fmt " 子块。和上面的"RIFF"一样,使用ASCII字符标识,不足四个字符,末尾用空格补齐。对应66 6D 74 20
- Subchunk1Size (偏移量16,4字节) 表示此子块的大小(对于PCM通常为16字节)。
- AudioFormat (偏移量20,2字节) 指定音频格式,例如PCM(未压缩音频,值为1)。
- NumChannels (偏移量22,2字节) 声道数,例如1(单声道)或2(立体声)。
- SampleRate (偏移量24,4字节) 采样率,例如44100 Hz(CD音质)。
- ByteRate (偏移量28,4字节) 每秒字节数,计算公式为:
SampleRate * NumChannels * BitsPerSample / 8 - BlockAlign (偏移量32,2字节) 每个采样块的字节数,计算公式为:
NumChannels * BitsPerSample / 8 - BitsPerSample (偏移量34,2字节) 每个样本采样的位数,例如8位或16位。
3. data Sub-chunk (偏移量36起)
这部分存储实际的音频数据:
- Subchunk2ID (偏移量36,4字节) 标识这是 "data" 子块。对应64 61 74 61。
- Subchunk2Size (偏移量40,4字节) 表示音频数据的大小。 datasize =
NumSamples × NumChannels × BitsPerSample / 8,其中NumSamples 是总样本数 - data (偏移量44起,可变大小) 包含原始的音频采样数据。
WAV文件头
WAV文件的前44字节称为 WAV的文件头 ,剩下的data为WAV文件实际的音频数据。所以整个WAV文件的大小应等于
文件头44字节 + data字节大小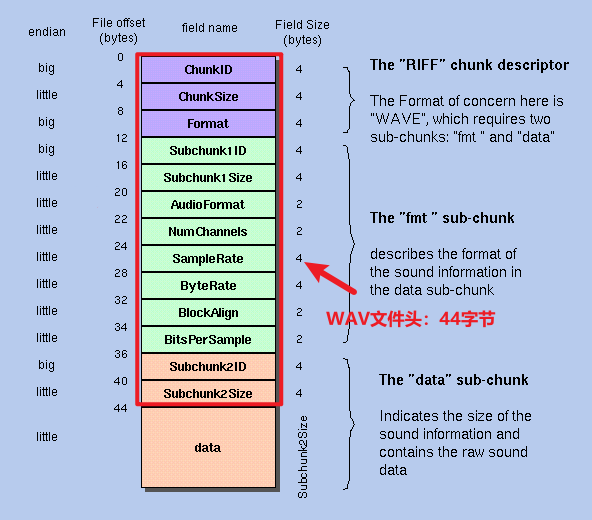
这个文件头主要注意ChunkSize ,Subchunk2Size,ByteRate ,BlockAlign 这几个参数,我们重点介绍一下。
ChunkSize
ChunkSize字段里面存储着 “它之后的数据总大小” 的这个数据 (对于当前chunk的剩余部分)。所以 ChunkSize 指 对于ChunkSize字段后面的数据大小,不包括前8字节,即 4字节的ChunkID 和4字节的ChunkSize,所以ChunkSize大小是
文件总大小-8。 (从ChunkID到data是一个WAV文件,ChunkSize实际就是从下个地址08开始到WAV文件结尾的总字节数)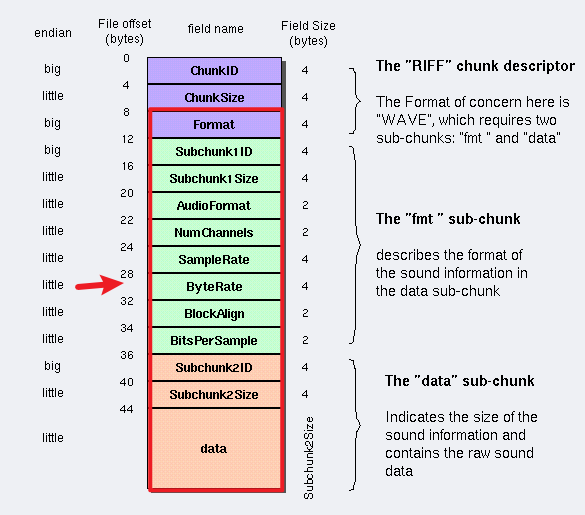
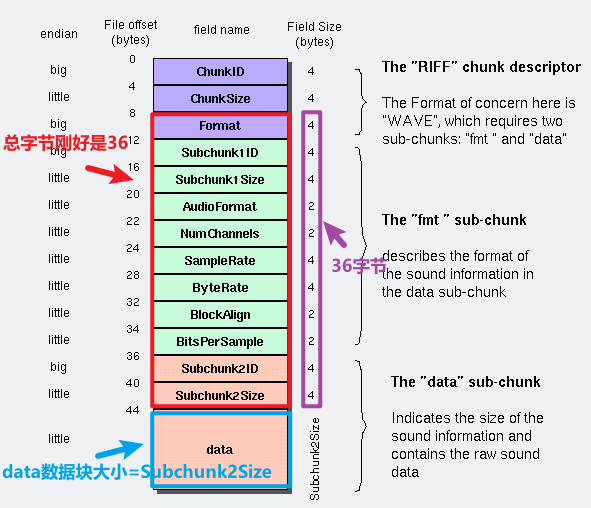
ChunkSize大小还等于
36 + SubChunk2Size。(下图红色框+蓝色框)。因为同理Subchunk2Size 指 对于Subchunk2Size字段后面的数据大小,而这个数据刚好就是WAV真正的音频数据,即 datasize,
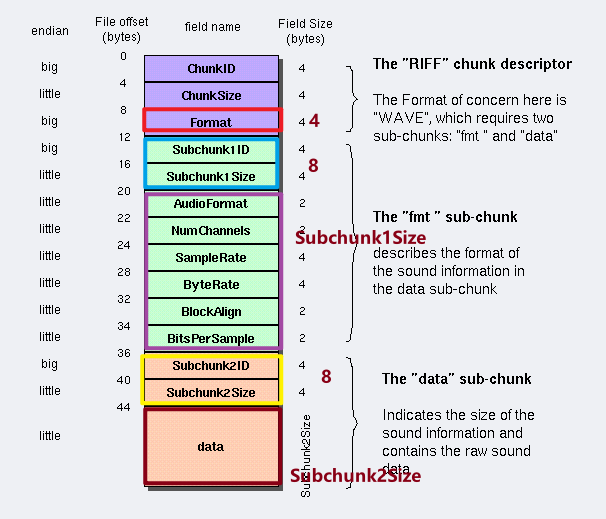
ChunkSize还等于
4 + (8 + SubChunk1Size) + (8 + SubChunk2Size),这个式子比较长,主要是分的比较细,如下图:
ByteRate
ByteRate表示每秒传输的字节数,比如一段采样率8000hz,采样深度16bit的音频,单声道,则一秒采样8000个样本,每个样本16位,每秒采样样本字节大小为
8000 * 16 / 8 * 1声道 = 16000字节,除以8是为了转换为字节,所以ByteRate = SampleRate * NumChannels * BitsPerSample / 8BlockAlign
BlockAlign指每个采样块的字节数,或者说一帧的样本,如果是单声道音频,一帧样本就包含一个声道数据;如果是双声道音频,一帧样本包含左声道数据和右声道数据。比如一段采样深度16bit的音频,单声道,一帧就是
16 / 8 * 1声道 = 2字节。所以BlockAlign = NumChannels * BitsPerSample / 8。讲到采样帧这里顺便提一下之前学习遇到的困惑,之前学习I2S了解到在对音频样本采样时,如果是双声道音频,左声道和右声道是一帧样本,在同一时刻采样,那为什么WS又区分WS=0和WS=1呢? 在之前学过I2S的通信格式的那个图里一般左边是左声道,右边是右声道,这样子看起来并不是在同一个时刻。这里其实是我混淆了采样和传输的过程,采样确实是同时采样的,但是传输是先传输左声道,再传输右声道。这里参考了别人画的图,很形象借用一下。
假设一个 buffer 包含 4 个周期、而一个周包含 1024 帧、一帧包含两个样本(左、右两个声道),每个样本长度为2bytes。

Subchunk2Size
Subchunk2Size表示音频数据的大小(字节),一般可以预估计算,有了ByteRate ,一般乘以时间,就可以得到音频总大小。 或者知道样本数也可以估算出来,比如一段采样率44100,采样深度16bit的音频,单声道,时间一分钟60s,字节速率
ByteRate=44100 * 16 / 8 = 88200,即每秒传输字节数88200字节,再乘以时间,88200 * 60 = 5292000字节 ≈ 5.04 MB。Subchunk2Size大小因为表示的是WAV音频实际数据大小,所以也叫datasize,后面编写程序时我们将使用datasize这个字段名称。 使用时间去估计音频数据大小可能会有误差,但是这个误差一般不会很大。我们还可以通过样本数去估计音频数据大小,即NumSamples × NumChannels × BitsPerSample / 8,其中NumSamples是总样本数,NumChannels × BitsPerSample / 8 就是每个采样样本的字节数(即BlockAlign), 乘以总样本数,就可以得到总样本字节大小。以上我们讲了ChunkSize ,Subchunk2Size,ByteRate ,BlockAlign 这几个比较主要的参数,还有一些其他参数在WAV文件中是默认的。为了方便查看,将以上内容整理为表格:
偏移 大小 字段名 内容/说明 0 4 ChunkID "RIFF"(52 49 46 46)4 4 ChunkSize 文件大小 - 8
或
36 + SubChunk2Size
或
4 + (8 + SubChunk1Size) + (8 + SubChunk2Size)8 4 Format "WAVE"(57 41 56 45)12 4 Subchunk1ID "fmt "(66 6D 74 20)16 4 Subchunk1Size 16(表示 PCM 格式时) 20 2 AudioFormat 1 表示 PCM;其他为压缩格式 22 2 NumChannels 声道数(1=单声道,2=立体声) 24 4 SampleRate 采样率(如 44100) 28 4 ByteRate 每秒传输的字节数 = SampleRate * NumChannels * BitsPerSample / 832 2 BlockAlign 每个采样块的字节数 = NumChannels × BitsPerSample / 834 2 BitsPerSample 每个样本的位数(如 16) 36 4 Subchunk2ID "data"(64 61 74 61)40 4 Subchunk2Size 音频数据的大小(字节) = NumSamples × NumChannels × BitsPerSample / 8WAV音频文件格式示例
了解了RIFF格式,字节序和WAV文件结构等相关参数后,我们先举一个WAV音频文件格式示例,再来看看实际的音频文件格式是什么样子的。
假设有一段WAV音频文件如下(十六进制显示)52 49 46 46 24 08 00 00 57 41 56 45 66 6d 74 20 10 00 00 00 01 00 02 00
22 56 00 00 88 58 01 00 04 00 10 00 64 61 74 61 00 08 00 00 00 00 00 00
24 17 1e f3 3c 13 3c 14 16 f9 18 f9 34 e7 23 a6 3c f2 24 f2 11 ce 1a 0d对音频数据按照上面WAV文件结构进行划分:

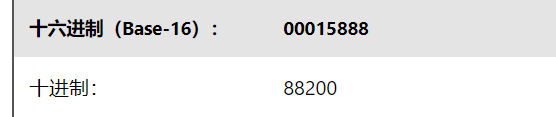
我们可以得到RIFF chunk, ChunkSize, Subchunk1Size,AudioFormat等相关参数,这里要注意除了ASCII字符,其他数据都是以小端序存储的。 比如ByteRate为 88 58 01 00,小端序应为:0x00015888,对应的十进制为88200。
再比如BlockAlign=4, 根据我们前面举的例子计算(双倍),它是一段双声道音频。那对于一段实际音频,我们如何查看它的十六进制格式呢?我们可以通过 Hex Editor这个软件,
HxD Hex Editor 是一款功能强大的十六进制编辑器和磁盘编辑器,它可以让你直接查看和编辑二进制文件的内容。你可以使用HxD Hex
Editor来分析、修改和处理各种数据格式,包括程序文件、磁盘映像、内存转储以及其他二进制文件。这里我自己生成了一段30S的WAV音频。我们用HxD软件打开它看看。

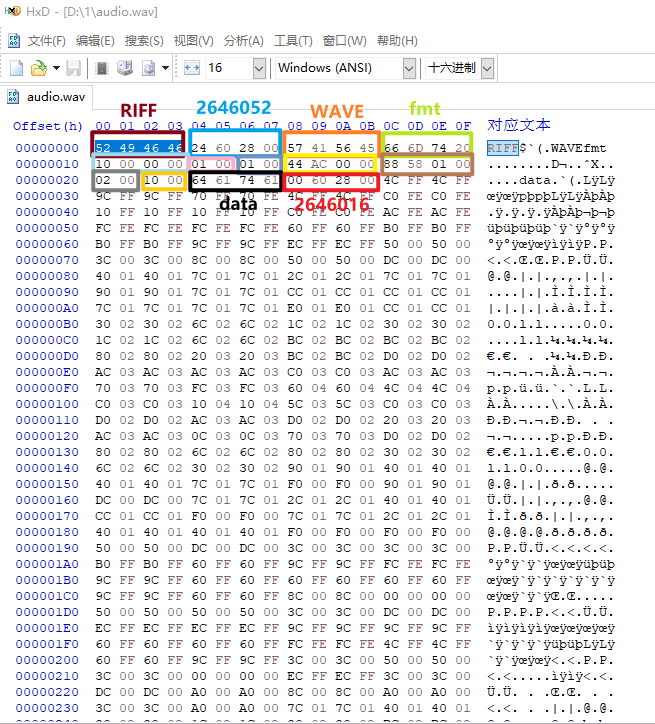
当我们框选头四个字节时,可以看到右边也有显示它的对应文本为:RIFF,表示这是一个基于RIFF格式的文件。我们将每个数据按照上面的结构进行划分,可以看到这个数据格式和我们介绍的WAV格式相符。除了框选的部位,后面都是真正的WAV音频数据即data。 框选的所有部分我们称之为 文件头,以四个字节为一组,数一下可以发现刚好有11组,11 * 4= 44字节,刚好是WAV文件头的字节数。 而WAV数据大小就是上面图片最后红色框的2646016字节,则整个WAV文件字节数应为
2646016 + 44 = 2646060字节。右键查看这个音频的文件属性:
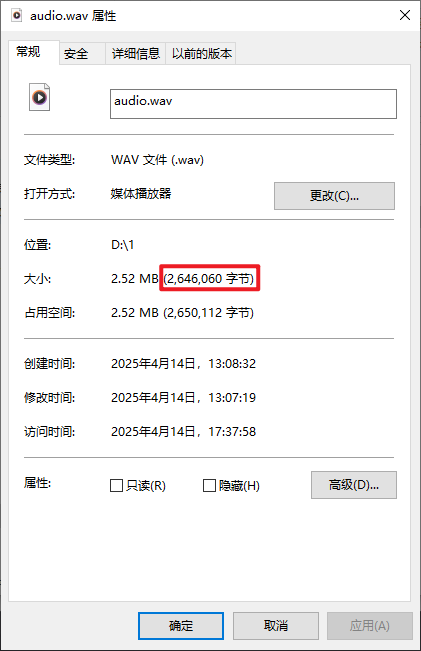
这和我们的计算结果一致。关于这个WAV文件头的详细信息如下:
52 49 46 46 RIFF标识
24 60 28 00 ChunkSize = 2646052(除去前8个字节文件大小)
57 41 56 45 WAV标识
66 6D 74 20 fmt标识
10 00 00 00 , Subchunk1Size =16(表示 PCM 格式时固定为16)
01 00 AudioFormat=1 ,音频格式:PCM(未压缩)(表示 PCM 格式时固定为1)
01 00 声道数:1(单声道)
44 ac 00 00 采样率:44100 Hz
88 58 01 00 字节率:88200 字节/秒
02 00 块对齐:2字节(每个采样点的字节数)
10 00 位深度:16位(每个采样点2字节)
64 61 74 61 data标识
00 60 28 00 Subchunk2Size = 2646016 (音频数据大小)WAV文件大小:2646060 字节
现在我们是通过WAV文件信息得到这些参数,比如音频数据大小 2646016 。前面我们说过WAV文件大小可以预估,那我们来计算一下看看有什么差异。以上面我生成的audio.wav文件为例, 假设我们已经知道一些基本参数,一段采样率44100, 采样深度16bit, 单声道WAV音频,如果我们通过字节速率ByteRate去计算再乘以时间,则
估计总音频文件大小应为44100 * 16 / 8 * 30 = 2646000字节,但实际大小为2646016字节,我们估计出来的音频大小比实际小。这是因为采样音频时长并不是精确的30 秒, 如果是精确30秒,采样点数量应该是44100 × 30 = 1323000个,我们通过 Subchunk2Size (实际音频大小),计算实际样本数却为2646016 / 2 = 1323008,比 1323000 多 8 个采样点,而每个采样点占 2 字节,所以实际整体多了16字节。 反过来我们可以计算实际采样时间为1323008 / 44100 ≈ 30.0001814058956秒, 多出8个采样点的时间刚好为1 / 44100 * 8 = 0.0001814058956秒。所以我们通过时间去预估WAV音频数据大小的话和实际相比是有差异的,但是我们一般会先预估大小,然后再更新WAV文件头。使用ESP32将WAV文件写入SD卡
以上我们介绍了WAV相关内容后,我们将介绍一个例子,将WAV音频文件写入SD卡,生成的WAV音频为一段1S的正弦波音频。
上面我们知道通过一段WAV文件头信息,可以得到它的一些参数;反过来我们也可以写入一些参数到WAV文件头里,生成WAV文件,所以WAV头部的定义是不可避免的。【定义WAV文件头】
假设我们要生成的WAV音频参数,采样率8000,采样深度16bit, 单声道,那么我们可以预估ChunkSize,Subchunk2Size(即datasize)大小,因为采样率是8000Hz,我们要生成1秒的音频,则1秒有8000个样本,每个样本大小为2字节(采样深度16bit),则 datasize = 16000, 根据公式直接计算的话就是
NumSamples × NumChannels × BitsPerSample / 8 = 8000 x 1 x 16 /8 = 16000字节。ChunkSize = 36 + datasize = 16036字节。其他参数可以参考上面的表格,这里就不赘述了。将其转化为16进制,小端序,定义WAV文件头:
const uint8_t wavHeader[44] = {0x52, 0x49, 0x46, 0x46, // "RIFF"0xA4, 0x3E, 0x00, 0x00, // chunksize: 160360x57, 0x41, 0x56, 0x45, // "WAVE"0x66, 0x6D, 0x74, 0x20, // "fmt "0x10, 0x00, 0x00, 0x00, // fmt块大小 (16)0x01, 0x00, // 音频格式 (1 = PCM)0x01, 0x00, // 声道数 (1)0x40, 0x1F, 0x00, 0x00, // 采样率 (8000 Hz)0x80, 0x3E, 0x00, 0x00, // 字节率 (16000)0x02, 0x00, // 块对齐 (2)0x10, 0x00, // 每样本位数 (16)0x64, 0x61, 0x74, 0x61, // "data"0x80, 0x3E, 0x00, 0x00 // datasize: 16000 };【创建并打开文件】
为了写入SD卡,我们还要初始化SD卡。创建一个文件取名为test.wav并打开它:
#define SD_CS_PIN 5// 初始化SD卡 if (!SD.begin(SD_CS_PIN)) { Serial.println("SD卡初始化失败!"); return; } Serial.println("SD卡初始化成功。");//创建并打开文件 File wavFile = SD.open("/test.wav", FILE_WRITE); if (!wavFile) { Serial.println("无法创建文件!"); return; }【写入WAV头部】
File 类是Arduino SD库的一部分,这里我们创建了一个 File 类对象取名为wavFile,wavFile.write用于向 SD 卡上的文件写入数据。使用
size_t write(const uint8_t *buf, size_t size)将文件头写入前面创建的文件中,这里要注意第一个参数类型是uint8_t *类型的,如果写入的buffer不是uint8_t *类型,需要进行强制类型转换。wavFile.write(wavHeader, 44);【 生成440Hz正弦波音频】
正弦波公式为:
y = A * sin(ωt+φ)其中,
A:振幅,那么y的取值范围就是
[-A, A];
ω:角频率,ω = 2 * π * f,其中f为频率,周期T = 1 / f;
φ:初相位;以下是生成一段1秒440Hz正弦波音频的示例:
// 生成并写入440Hz正弦波音频数据 const int sampleRate = 8000; // 采样率 const int frequency = 440; // 正弦波频率 const int numSamples = sampleRate * 1; // 1秒的样本数 for (int i = 0; i < numSamples; i++) { float time = (float)i / sampleRate; int16_t sample = (int16_t)(32767.0 * sin(2.0 * PI * frequency * time)); }【写入WAV音频文件并关闭文件】
使用
size_t write(const uint8_t *buf, size_t size)将前面生成的正弦波音频数据写入前面创建的文件中并进行强制类型转换。wavFile.write((uint8_t*)&sample, 2); // 写入16位样本 wavFile.close(); Serial.println("WAV文件写入完成。");整合后的代码如下:
#include <SD.h> #include <SPI.h>// SD卡片选引脚 #define SD_CS_PIN 5// WAV文件头部(44字节) const uint8_t wavHeader[44] = {0x52, 0x49, 0x46, 0x46, // "RIFF"0xA4, 0x3E, 0x00, 0x00, // chunksize: 160360x57, 0x41, 0x56, 0x45, // "WAVE"0x66, 0x6D, 0x74, 0x20, // "fmt "0x10, 0x00, 0x00, 0x00, // fmt块大小 (16)0x01, 0x00, // 音频格式 (1 = PCM)0x01, 0x00, // 声道数 (1)0x40, 0x1F, 0x00, 0x00, // 采样率 (8000 Hz)0x80, 0x3E, 0x00, 0x00, // 字节率 (16000)0x02, 0x00, // 块对齐 (2)0x10, 0x00, // 每样本位数 (16)0x64, 0x61, 0x74, 0x61, // "data"0x80, 0x3E, 0x00, 0x00 // datasize: 16000 };void setup() { Serial.begin(115200);// 初始化SD卡 if (!SD.begin(SD_CS_PIN)) { Serial.println("SD卡初始化失败!"); return; } Serial.println("SD卡初始化成功。");// 创建并打开文件 File wavFile = SD.open("/test.wav", FILE_WRITE); if (!wavFile) { Serial.println("无法创建文件!"); return; }// 写入WAV头部 wavFile.write(wavHeader, 44);// 生成并写入440Hz正弦波音频数据 const int sampleRate = 8000; // 采样率 const int frequency = 440; // 正弦波频率 const int numSamples = sampleRate * 1; // 1秒的样本数 for (int i = 0; i < numSamples; i++) { float time = (float)i / sampleRate; int16_t sample = (int16_t)(32767.0 * sin(2.0 * PI * frequency * time)); wavFile.write((uint8_t*)&sample, 2); // 写入16位样本 }// 关闭文件 wavFile.close(); Serial.println("WAV文件写入完成。"); }void loop() { }这里我们观察到如果使用数组定义WAV文件头的话需要计算它的十六进制比较麻烦,我们可以定义一个WAV头部结构体,写入ASCII字符和公式,这样可以更方便地计算 WAV 文件头的信息,而不用手动去处理十六进制数据。
使用结构体定义WAV文件头:
// 定义 WAV 头部结构体 struct WavHeader {char riff[4] = {'R', 'I', 'F', 'F'}; // "RIFF"uint32_t chunkSize; // 文件大小 - 8char wave[4] = {'W', 'A', 'V', 'E'}; // "WAVE"char fmt[4] = {'f', 'm', 't', ' '}; // "fmt "uint32_t fmtChunkSize = 16; // fmt 块大小 (16 for PCM)uint16_t audioFormat = 1; // 音频格式 (1 = PCM)uint16_t numChannels = 1; // 声道数 (1 = 单声道)uint32_t sampleRate = SAMPLE_RATE; // 采样率 (8000 Hz)uint32_t byteRate = SAMPLE_RATE * 2; // 字节率 (sampleRate * numChannels * bitsPerSample / 8)uint16_t blockAlign = 2; // 块对齐 (numChannels * bitsPerSample / 8)uint16_t bitsPerSample = 16; // 每样本位数 (16 bits)char data[4] = {'d', 'a', 't', 'a'}; // "data"uint32_t dataSize; // 数据块大小 };使用结构体定义WAV文件头的话我们只是定义了一个类型,所以我们需要定义一个结构体变量,因为我们没有直接给出 chunkSize 和 datasize ,所以我们需要计算音频数据大小,创建并初始化WAV文件头。这里由于样本比较简单,所以我们直接可以确定样本数去计算音频数据大小,后面就不需要再更新WAV文件头了。
// 计算音频数据大小const int numSamples = SAMPLE_RATE * 1; // 1 秒的样本数const int bytesPerSample = 2; // 16 位,每个样本 2 字节uint32_t dataSize = numSamples * bytesPerSample; // 数据大小:16000 字节uint32_t chunkSize = 36 + dataSize; // 文件总大小 - 8:16036 字节// 创建并初始化 WAV 头部WavHeader header;header.chunkSize = chunkSize; // 设置 chunkSizeheader.dataSize = dataSize; // 设置 dataSize完整代码
修改后的完整代码如下:
#include <SD.h> #include <SPI.h>// 定义常量 #define SD_CS_PIN 5 // SD卡片选引脚 #define SAMPLE_RATE 8000 // 采样率(8000 Hz) #define PI 3.1415926535 // π 值// 定义 WAV 头部结构体 struct WavHeader {char riff[4] = {'R', 'I', 'F', 'F'}; // "RIFF"uint32_t chunkSize; // 文件大小 - 8char wave[4] = {'W', 'A', 'V', 'E'}; // "WAVE"char fmt[4] = {'f', 'm', 't', ' '}; // "fmt "uint32_t fmtChunkSize = 16; // fmt 块大小 (16 for PCM)uint16_t audioFormat = 1; // 音频格式 (1 = PCM)uint16_t numChannels = 1; // 声道数 (1 = 单声道)uint32_t sampleRate = SAMPLE_RATE; // 采样率 (8000 Hz)uint32_t byteRate = SAMPLE_RATE * 2; // 字节率 (sampleRate * numChannels * bitsPerSample / 8)uint16_t blockAlign = 2; // 块对齐 (numChannels * bitsPerSample / 8)uint16_t bitsPerSample = 16; // 每样本位数 (16 bits)char data[4] = {'d', 'a', 't', 'a'}; // "data"uint32_t dataSize; // 数据块大小 };void setup() {Serial.begin(115200);// 初始化 SD 卡if (!SD.begin(SD_CS_PIN)) {Serial.println("SD卡初始化失败!");return;}Serial.println("SD卡初始化成功。");// 创建并打开文件File wavFile = SD.open("/test.wav", FILE_WRITE);if (!wavFile) {Serial.println("无法创建文件!");return;}// 计算音频数据大小const int numSamples = SAMPLE_RATE * 1; // 1 秒的样本数const int bytesPerSample = 2; // 16 位,每个样本 2 字节uint32_t dataSize = numSamples * bytesPerSample; // 数据大小:16000 字节uint32_t chunkSize = 36 + dataSize; // 文件总大小 - 8:16036 字节// 创建并初始化 WAV 头部WavHeader header;header.chunkSize = chunkSize; // 设置 chunkSizeheader.dataSize = dataSize; // 设置 dataSize// 写入 WAV 头部wavFile.write((uint8_t*)&header, sizeof(header));// 生成并写入音频数据(440 Hz 正弦波)const int frequency = 440;for (int i = 0; i < numSamples; i++) {float time = (float)i / SAMPLE_RATE;int16_t sample = (int16_t)(32767.0 * sin(2.0 * PI * frequency * time));wavFile.write((uint8_t*)&sample, 2);}// 关闭文件wavFile.close();Serial.println("WAV文件写入完成。"); }void loop() { }以上通过ESP32生成的一段1S的正弦波音频写入SD卡模块,硬件上只需ESP32和SD模块。下面我们介绍如何将ESP32和SD模块进行接线。
ESP32

SD卡模块

ESP32和SD模块接线
ESP32 SD模块 D5 CS D18 SCK D23 MOSI D19 MISO 5V VCC GND GND 按照以上步骤,编译上传代码后,应能在SD卡找到生成的名为test.wav的音频文件,播放会听到1秒的正弦波声音。
同样我们用HxD软件打开我们生成的test.wav文件
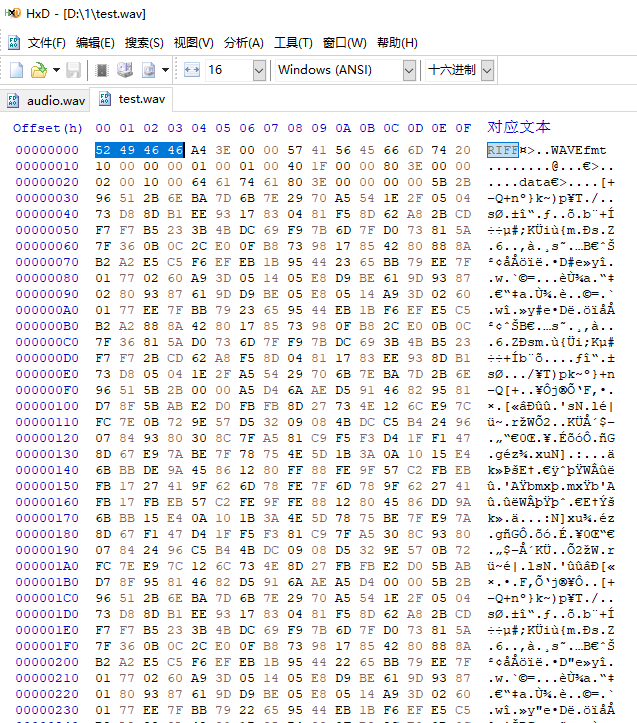
对比我们代码里的WAV文件头数据,可以发现数据是一样的,这说明WAV文件头确实是按照我们的要求写入了WAV文件了,而且使用数组或者结构体表示 WAV 头部这两种方法都可以实现,建议采用第二个代码的方式,使用结构体和动态计算 chunkSize等数据,确保 WAV 文件头部的正确性、灵活性和兼容性。
总结
以上我们介绍了什么是WAV音频文件,还有一些音频格式的相关概念、参数,并实际观察了WAV文件的数据内容,对WAV文件结构有了更深入的了解,然后我们通过ESP32生成了一段1S的正弦波音频,并将其写入SD模块,方法是通过将音频参数写入WAV文件头,并通过SD和文件系统相关函数将文件头写入我们创建的文件里,这样我们就可以在SD卡里通过读卡器读取里面的正弦波音频数据了。
关于WAV文件头的每个参数是如何计算和填写的,在我们介绍WAV文件头的时候,已经举例并且说明了,我们也可以直接参考一开始总结的表格,里面有详细说明和相关公式,这些公式并不需要死记硬背,理解了每个参数的含义还是比较容易理解的。在介绍WAV文件头的时候,还有一些参数没有详细说明,比如AudioFormat, 1表示PCM,至于其他值表示的压缩格式应该是什么样子这里没有提到,还有LIST 块相关本文也没有提到,因为我们主要针对WAV文件进行介绍,所以这里不作提及,感兴趣的小伙伴可以自行去了解下~
本文是为后面ESP I2S音频学习内容作为铺垫,因为WAV文件格式的内容还是比较多的,所以单独写一篇介绍。后面大家关于WAV文件有疑惑的地方,可以参考这篇文章。因为本人也是初学,以上是个人理解加上搜索资料学习到的,如果有什么问题,可以提出交流讨论,欢迎指正!需要HxD软件和想听一下源代码工程生成的WAV音频文件是什么声音的可以评论区留言!已经整理好所有文件 ~ 创作不易,多多点赞收藏哦! ~



VTK C++开发示例 --- 交互式3D部件)

