使用Python打造一款集成 PDF转换、编辑、加密、解密、图片提取、日志追踪 等多个功能于一体的桌面工具应用(Tkinter + ttkbootstrap + PyPDF2 等库)。
✨项目背景与开发动机
在日常办公或学习中,我们经常会遇到各种关于PDF文件的操作需求,比如:
-
将 PDF 转换成 Word 文档编辑
-
合并多个PDF为一个
-
分割PDF,按页导出
-
去掉PDF水印、加密、解密
-
从PDF中提取图片
-
将PDF每一页转为图片
-
旋转/删除指定页面
-
记录最近处理文件和操作日志
虽然市场上存在很多PDF软件,但免费+轻量+跨平台的桌面工具仍较少。于是我决定用 Python 打造一个集所有功能于一身的 PDF 工具箱,方便自己和他人使用!
🛠️主要技术栈与依赖
| 模块 | 功能 |
|---|---|
tkinter + ttkbootstrap | GUI 构建 |
tkinterDnD2 | 拖拽支持 |
PyPDF2, pdfplumber, fitz(PyMuPDF) | PDF编辑核心 |
pdf2image, PIL | PDF转图片 |
docx | Word文档生成 |
threading, json, os | 多线程处理和状态记录 |
📂功能结构总览
该程序结构如下图(部分简化):
PDFToolboxApp
├── PDF 转 Word(支持去水印)
├── PDF 分割(每页单独导出)
├── PDF 合并
├── PDF 加密 / 解密
├── 提取 PDF 中的图片
├── 页面旋转
├── 删除指定页面
├── PDF 转图片
└── 查看日志记录
接下来我们分模块详细介绍每个功能实现。
🧾基础组件与通用功能
🔹 日志与历史文件记录
-
log_action(action, file)
每次用户进行操作(如打开、转换文件)都记录到日志文件pdf_toolbox_logs.txt中。 -
add_to_history(filepath)
最近打开文件记录在pdf_toolbox_history.json中,便于下次快速访问。 -
get_recent_history()
读取最近10个操作过的文件。
🔹 去水印功能
def remove_watermark(text):WATERMARK_KEYWORDS = ["Confidential", "Watermark", "Do Not Copy", "内部资料", "机密"]return '\n'.join(line for line in text.split('\n') if not any(wm in line for wm in WATERMARK_KEYWORDS))
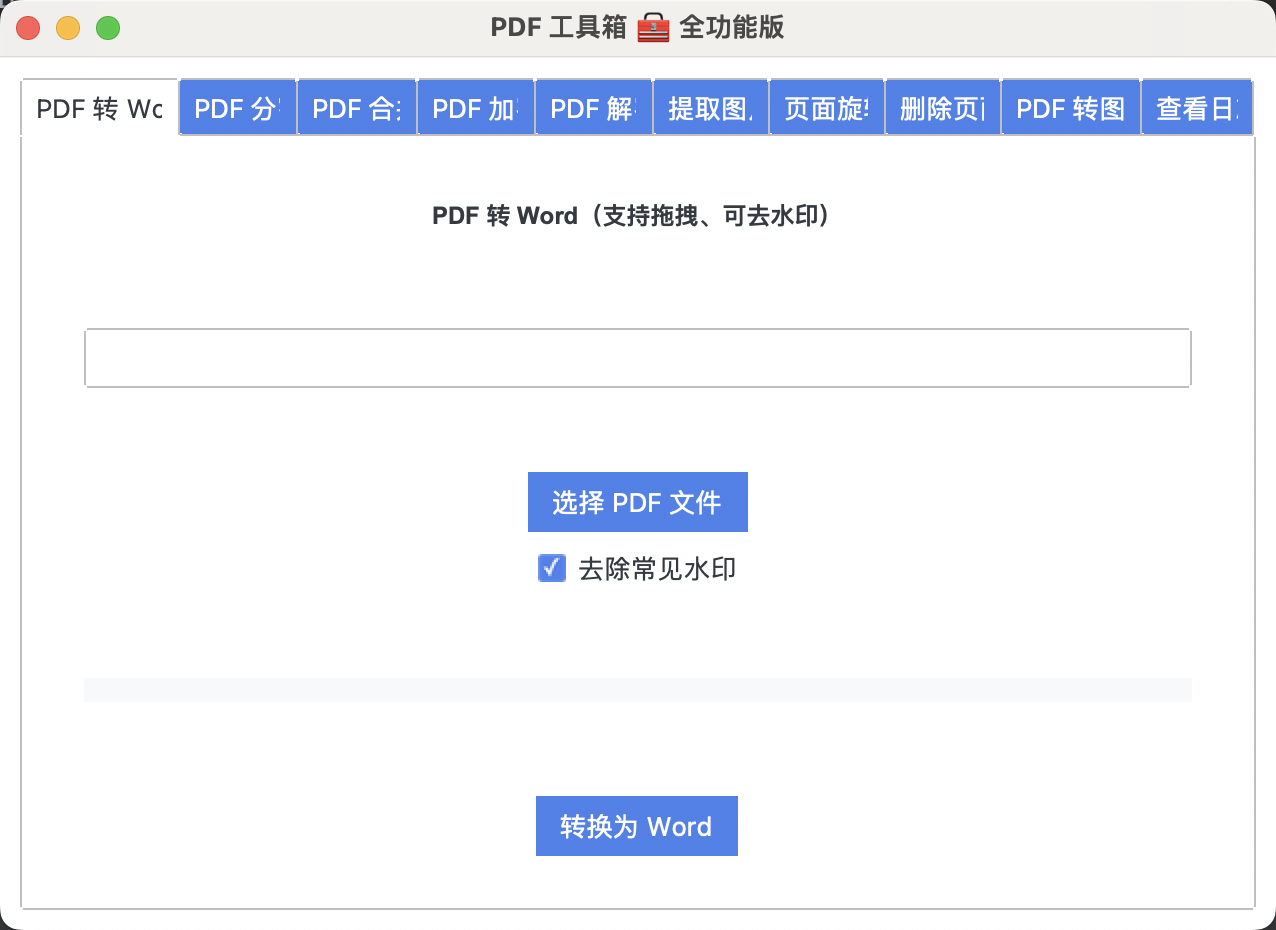
📄PDF 转 Word(支持去水印)
pdfplumber.open(path) → page.extract_text() → remove_watermark() → Word文档-
使用
pdfplumber提取 PDF 每一页文本内容 -
可勾选“去水印”选项过滤掉机密/水印文本
-
保存为
.docx格式,支持拖拽上传PDF
✂️PDF 分割
每页导出为独立文件:
for i, page in enumerate(reader.pages): writer.add_page(page) writer.write(f"page_{i+1}.pdf")用户选择PDF并设置导出目录后,将每一页保存为独立PDF文件。
➕PDF 合并
多文件合并为一个:
for f in files: for p in PdfReader(f).pages: writer.add_page(p)支持多选文件,按照选择顺序合并。
🔐PDF 加密 / 解密
-
加密: 输入密码 → 写入新PDF
-
解密: 输入正确密码 → 导出解密版本
writer.encrypt(password) reader.decrypt(password)🖼️提取PDF图片
使用 fitz(PyMuPDF)逐页扫描PDF,提取嵌入图片并保存为 PNG:
for page_index in range(len(doc)): for img in doc[page_index].get_images(full=True): pix = fitz.Pixmap(doc, img[0]) pix.save(...)🔄页面旋转
用户输入:
-
页码:
1,2,3 -
角度:
90
代码示例:
if i + 1 in pages: page.rotate(angle)🗑️删除指定页面
输入页码列表,如 2,5,7,将这些页从PDF中删除并保存新版本。
🖼️PDF 转图片(每页转 PNG)
images = convert_from_path(file)
for i, img in enumerate(images): img.save(f"page_{i+1}.png")适合需要提取PDF为PPT使用或网页插图等。
🧾日志查看
简单读取 pdf_toolbox_logs.txt 文件,展示操作记录,便于溯源。
with open(LOG_FILE) as f: self.log_text.insert(tk.END, f.read())🧵多线程支持
通过 @threaded 装饰器包装耗时操作(如转换)避免 GUI 卡死:
def threaded(fn): def wrapper(*args, **kwargs): threading.Thread(target=fn, args=args, kwargs=kwargs).start()🎬运行入口
if __name__ == '__main__': app = TkinterDnD.Tk() PDFToolboxApp(app) app.mainloop()使用 TkinterDnD2 支持拖拽,整体体验更为现代化。
✅总结亮点
-
支持所有常用 PDF 操作(转换、编辑、处理、日志)
-
界面清晰、操作直观、支持拖拽上传
-
轻量级、不依赖大型软件,可本地私有化使用
-
拥有日志与历史记录,适合办公自动化场景
📦部署建议
安装依赖:
pip install tkinterdnd2 ttkbootstrap PyPDF2 pdfplumber python-docx pymupdf pdf2image pillow如果你要将其打包为桌面可执行程序:
pyinstaller -F -w pdf_toolbox.py如果你觉得这个项目实用,欢迎点赞、评论支持 🧡
如需源码或扩展功能可以私信我,我会继续更新!
以下为完整代码:
import tkinter as tk
from tkinter import filedialog, messagebox, simpledialog
from tkinterdnd2 import TkinterDnD, DND_FILES
import ttkbootstrap as ttk
from ttkbootstrap.constants import *
from PyPDF2 import PdfReader, PdfWriter
import pdfplumber
from docx import Document
import fitz # PyMuPDF
from pdf2image import convert_from_path
from PIL import Image
import os
import threading
import json
from datetime import datetime# 日志 & 历史记录配置
LOG_FILE = "pdf_toolbox_logs.txt"
HISTORY_FILE = "pdf_toolbox_history.json"def log_action(action: str, file: str = ""):with open(LOG_FILE, "a", encoding="utf-8") as f:now = datetime.now().strftime("%Y-%m-%d %H:%M:%S")f.write(f"[{now}] {action}: {file}\n")def add_to_history(filepath: str):filepath = os.path.abspath(filepath)history = []if os.path.exists(HISTORY_FILE):with open(HISTORY_FILE, "r", encoding="utf-8") as f:try:data = json.load(f)history = data.get("recent_files", [])except:history = []if filepath not in history:history.insert(0, filepath)history = history[:10]with open(HISTORY_FILE, "w", encoding="utf-8") as f:json.dump({"recent_files": history}, f, indent=2, ensure_ascii=False)def get_recent_history():if os.path.exists(HISTORY_FILE):with open(HISTORY_FILE, "r", encoding="utf-8") as f:try:data = json.load(f)return data.get("recent_files", [])except:return []return []def remove_watermark(text):WATERMARK_KEYWORDS = ["Confidential", "Watermark", "Do Not Copy", "内部资料", "机密"]lines = text.split('\n')return '\n'.join(line for line in lines if not any(wm in line for wm in WATERMARK_KEYWORDS))def threaded(fn):def wrapper(*args, **kwargs):threading.Thread(target=fn, args=args, kwargs=kwargs).start()return wrapper
class PDFToolboxApp:def __init__(self, root):self.root = rootself.root.title("PDF 工具箱 🧰 全功能版")self.root.geometry("900x650")self.root.resizable(True, True)self.build_tabs()def build_tabs(self):self.notebook = ttk.Notebook(self.root, bootstyle="primary")self.notebook.pack(fill=tk.BOTH, expand=True, padx=10, pady=10)self.pages = {}features = {"PDF 转 Word": self.build_pdf_to_word_tab,"PDF 分割": self.build_split_tab,"PDF 合并": self.build_merge_tab,"PDF 加密": self.build_encrypt_tab,"PDF 解密": self.build_decrypt_tab,"提取图片": self.build_extract_images_tab,"页面旋转": self.build_rotate_tab,"删除页面": self.build_delete_pages_tab,"PDF 转图片": self.build_pdf_to_image_tab,"查看日志": self.build_log_viewer_tab}for title, builder in features.items():frame = ttk.Frame(self.notebook, padding=20)self.pages[title] = frameself.notebook.add(frame, text=title)builder(frame)def select_file(self, variable):file = filedialog.askopenfilename(filetypes=[("PDF files", "*.pdf")])if file:variable.set(file)add_to_history(file)log_action("选择文件", file)def on_drop_file(self, event, variable):filepath = event.data.strip('{}')if os.path.isfile(filepath):variable.set(filepath)add_to_history(filepath)log_action("拖拽导入", filepath)def build_pdf_to_word_tab(self, frame):ttk.Label(frame, text="PDF 转 Word(支持拖拽、可去水印)", font=("Arial", 12, "bold")).pack(pady=10)self.pdf_path_var = tk.StringVar()entry = ttk.Entry(frame, textvariable=self.pdf_path_var)entry.pack(fill='x', expand=True, padx=10, pady=5)# 拖拽支持entry.drop_target_register(DND_FILES)entry.dnd_bind('<<Drop>>', lambda e: self.on_drop_file(e, self.pdf_path_var))ttk.Button(frame, text="选择 PDF 文件", command=lambda: self.select_file(self.pdf_path_var)).pack(pady=5)self.remove_wm_var = tk.BooleanVar(value=True)ttk.Checkbutton(frame, text="去除常见水印", variable=self.remove_wm_var).pack(pady=5)self.progress = ttk.Progressbar(frame, bootstyle="info-striped")self.progress.pack(fill='x', expand=True, padx=10, pady=10)ttk.Button(frame, text="转换为 Word", command=self.run_pdf_to_word).pack(pady=5)@threadeddef run_pdf_to_word(self):path = self.pdf_path_var.get()if not path.endswith(".pdf"):messagebox.showwarning("警告", "请选择 PDF 文件")returnsave_path = filedialog.asksaveasfilename(defaultextension=".docx")if not save_path:returndef update_progress(val): self.progress['value'] = valtry:document = Document()with pdfplumber.open(path) as pdf:for i, page in enumerate(pdf.pages):text = page.extract_text() or ""if self.remove_wm_var.get():text = remove_watermark(text)document.add_paragraph(text)update_progress((i + 1) / len(pdf.pages) * 100)document.save(save_path)messagebox.showinfo("完成", "Word 文件已保存!")log_action("PDF 转 Word", path)except Exception as e:messagebox.showerror("错误", str(e))def build_split_tab(self, frame):ttk.Label(frame, text="PDF 分割(每页导出为独立文件)", font=("Arial", 12)).pack(pady=10)ttk.Button(frame, text="选择 PDF 文件", command=self.split_pdf_gui).pack(pady=5)def split_pdf_gui(self):file = filedialog.askopenfilename(filetypes=[("PDF Files", "*.pdf")])if not file:returnoutput_dir = filedialog.askdirectory()if not output_dir:returntry:reader = PdfReader(file)for i, page in enumerate(reader.pages):writer = PdfWriter()writer.add_page(page)out_path = os.path.join(output_dir, f"page_{i+1}.pdf")with open(out_path, "wb") as f:writer.write(f)messagebox.showinfo("完成", "分割成功!")log_action("PDF 分割", file)except Exception as e:messagebox.showerror("错误", str(e))def build_merge_tab(self, frame):ttk.Label(frame, text="PDF 合并(多个 PDF 合为一个)", font=("Arial", 12)).pack(pady=10)ttk.Button(frame, text="选择多个 PDF 文件", command=self.merge_pdfs_gui).pack(pady=5)def merge_pdfs_gui(self):files = filedialog.askopenfilenames(filetypes=[("PDF Files", "*.pdf")])if not files:returnoutput = filedialog.asksaveasfilename(defaultextension=".pdf")if not output:returntry:writer = PdfWriter()for f in files:reader = PdfReader(f)for p in reader.pages:writer.add_page(p)with open(output, "wb") as f:writer.write(f)messagebox.showinfo("完成", "合并成功!")log_action("PDF 合并", ",".join(files))except Exception as e:messagebox.showerror("错误", str(e))def build_encrypt_tab(self, frame):ttk.Label(frame, text="PDF 加密(设置访问密码)", font=("Arial", 12)).pack(pady=10)ttk.Button(frame, text="选择 PDF 文件", command=self.encrypt_pdf_gui).pack(pady=5)def encrypt_pdf_gui(self):file = filedialog.askopenfilename(filetypes=[("PDF Files", "*.pdf")])if not file:returnpassword = simpledialog.askstring("加密密码", "请输入加密密码:", show="*")if not password:returnoutput = filedialog.asksaveasfilename(defaultextension=".pdf")if not output:returntry:reader = PdfReader(file)writer = PdfWriter()for page in reader.pages:writer.add_page(page)writer.encrypt(password)with open(output, "wb") as f:writer.write(f)messagebox.showinfo("完成", "加密成功!")log_action("PDF 加密", file)except Exception as e:messagebox.showerror("错误", str(e))def build_decrypt_tab(self, frame):ttk.Label(frame, text="PDF 解密(需要密码)", font=("Arial", 12)).pack(pady=10)ttk.Button(frame, text="选择加密 PDF 文件", command=self.decrypt_pdf_gui).pack(pady=5)def decrypt_pdf_gui(self):file = filedialog.askopenfilename(filetypes=[("PDF Files", "*.pdf")])if not file:returnpassword = simpledialog.askstring("解密密码", "请输入密码:", show="*")if not password:returnoutput = filedialog.asksaveasfilename(defaultextension=".pdf")if not output:returntry:reader = PdfReader(file)if reader.is_encrypted:reader.decrypt(password)writer = PdfWriter()for page in reader.pages:writer.add_page(page)with open(output, "wb") as f:writer.write(f)messagebox.showinfo("完成", "解密成功!")log_action("PDF 解密", file)except Exception as e:messagebox.showerror("错误", str(e))def build_extract_images_tab(self, frame):ttk.Label(frame, text="提取 PDF 中的所有图片", font=("Arial", 12)).pack(pady=10)ttk.Button(frame, text="选择 PDF 文件", command=self.extract_images_gui).pack(pady=5)def extract_images_gui(self):file = filedialog.askopenfilename(filetypes=[("PDF Files", "*.pdf")])if not file:returnoutput_dir = filedialog.askdirectory()if not output_dir:returntry:doc = fitz.open(file)for page_index in range(len(doc)):for img_index, img in enumerate(doc[page_index].get_images(full=True)):xref = img[0]pix = fitz.Pixmap(doc, xref)output_path = os.path.join(output_dir, f"page{page_index+1}_img{img_index+1}.png")if pix.n < 5:pix.save(output_path)else:pix = fitz.Pixmap(fitz.csRGB, pix)pix.save(output_path)pix = Nonemessagebox.showinfo("完成", "图片提取成功!")log_action("提取图片", file)except Exception as e:messagebox.showerror("错误", str(e))def build_rotate_tab(self, frame):ttk.Label(frame, text="页面旋转(输入页码如 1,2,5)", font=("Arial", 12)).pack(pady=10)ttk.Button(frame, text="选择 PDF 文件", command=self.choose_rotate_file).pack(pady=5)self.rotate_pages_var = tk.StringVar()ttk.Entry(frame, textvariable=self.rotate_pages_var).pack(fill='x', padx=10, pady=5)self.rotate_angle_var = tk.StringVar(value="90")ttk.Entry(frame, textvariable=self.rotate_angle_var).pack(fill='x', padx=10, pady=5)ttk.Button(frame, text="执行旋转", command=self.rotate_pdf_gui).pack(pady=5)def choose_rotate_file(self):self.rotate_file = filedialog.askopenfilename(filetypes=[("PDF Files", "*.pdf")])def rotate_pdf_gui(self):if not hasattr(self, "rotate_file"):returnpages = list(map(int, self.rotate_pages_var.get().split(",")))angle = int(self.rotate_angle_var.get())output = filedialog.asksaveasfilename(defaultextension=".pdf")if not output:returntry:reader = PdfReader(self.rotate_file)writer = PdfWriter()for i, page in enumerate(reader.pages):if i + 1 in pages:page.rotate(angle)writer.add_page(page)with open(output, "wb") as f:writer.write(f)messagebox.showinfo("完成", "旋转成功!")log_action("页面旋转", self.rotate_file)except Exception as e:messagebox.showerror("错误", str(e))def build_delete_pages_tab(self, frame):ttk.Label(frame, text="删除指定页(如 2,4,5)", font=("Arial", 12)).pack(pady=10)ttk.Button(frame, text="选择 PDF 文件", command=self.choose_delete_file).pack(pady=5)self.delete_pages_var = tk.StringVar()ttk.Entry(frame, textvariable=self.delete_pages_var).pack(fill='x', padx=10, pady=5)ttk.Button(frame, text="删除并保存", command=self.delete_pages_gui).pack(pady=5)def choose_delete_file(self):self.delete_file = filedialog.askopenfilename(filetypes=[("PDF Files", "*.pdf")])def delete_pages_gui(self):if not hasattr(self, "delete_file"):returnpages_to_delete = list(map(int, self.delete_pages_var.get().split(",")))output = filedialog.asksaveasfilename(defaultextension=".pdf")if not output:returntry:reader = PdfReader(self.delete_file)writer = PdfWriter()for i, page in enumerate(reader.pages):if i + 1 not in pages_to_delete:writer.add_page(page)with open(output, "wb") as f:writer.write(f)messagebox.showinfo("完成", "删除成功!")log_action("删除页面", self.delete_file)except Exception as e:messagebox.showerror("错误", str(e))def build_pdf_to_image_tab(self, frame):ttk.Label(frame, text="PDF 转图片(每页保存为 PNG)", font=("Arial", 12)).pack(pady=10)ttk.Button(frame, text="选择 PDF 文件", command=self.convert_pdf_to_images).pack(pady=5)def convert_pdf_to_images(self):file = filedialog.askopenfilename(filetypes=[("PDF Files", "*.pdf")])if not file:returnoutdir = filedialog.askdirectory()if not outdir:returntry:images = convert_from_path(file)for i, img in enumerate(images):img.save(os.path.join(outdir, f"page_{i+1}.png"), "PNG")messagebox.showinfo("完成", "转换成功!")log_action("PDF 转图片", file)except Exception as e:messagebox.showerror("错误", str(e))def build_log_viewer_tab(self, frame):ttk.Label(frame, text="操作日志查看", font=("Arial", 12)).pack(pady=10)self.log_text = tk.Text(frame, wrap="word", height=30)self.log_text.pack(fill='both', expand=True)ttk.Button(frame, text="刷新日志", command=self.load_logs).pack(pady=5)def load_logs(self):if os.path.exists(LOG_FILE):with open(LOG_FILE, "r", encoding="utf-8") as f:self.log_text.delete(1.0, tk.END)self.log_text.insert(tk.END, f.read())else:self.log_text.insert(tk.END, "暂无日志记录。")# 主程序入口
if __name__ == '__main__':app = TkinterDnD.Tk()PDFToolboxApp(app)app.mainloop()
![[FPGA]设计一个DDS信号发生器](http://pic.xiahunao.cn/nshx/[FPGA]设计一个DDS信号发生器)
)
——DDS信号发生器设计)


