目录
优化器:
指数加权平均(Exponentially Weighted Moving Average, EWMA)
关键概念与公式
递推公式:
权重分配:
有效窗口长度:
偏差修正
SGD(随机梯度下降):
Momentum:
核心思想
数学公式
效果
变体与改进
直观理解
RSNOProp:
Adam:
AdamW:
Softmax :
作用
数学公式
特性
one hot编码:
Guided Attention(引导注意力):
核心思想
常见方法
1. Guided Attention Loss
2. Attention Mask(注意力掩码)
3. Monotonic Alignment(单调对齐)
应用场景
Batch Normalization(批次标准化):
核心思想
具体步骤
关键优势
训练与测试的区别
常见应用位置
变体与改进
局限性
ReLU(Rectified Linear Unit):
数学定义
核心特性
局限性及解决方案
1. 死亡ReLU问题(Dead ReLU)
2. 输出非零中心化
优化器:
指数加权平均(Exponentially Weighted Moving Average, EWMA)
指数加权平均是一种通过对历史数据赋予指数衰减权重来计算平均值的方法,广泛应用于时间序列分析、金融工程和机器学习等领域。其核心思想是近期的数据具有更高的权重,权重随时间呈指数级下降。
关键概念与公式
-
递推公式:
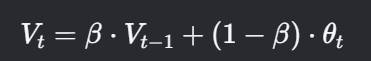
-
Vt:当前时刻的指数加权平均值。
-
θt:当前时刻的实际观测值。
-
β:衰减因子(0<β<10<β<1),控制权重衰减速度。
-
-
权重分配:
-
当前时刻的权重为 1−β。
-
过去第k个时刻的权重为 (1−β)⋅βk。
-
权重总和收敛于1,满足归一化条件。
-
-
有效窗口长度:
-
近似窗口长度 N 与 β 的关系为 β=1−1/N。
-
例如,β=0.9 对应约10个时间步的有效窗口(因 0.910≈1/e)。
-
偏差修正
初始阶段(t 较小时),由于初始值 V0=0,估计值可能偏低。通过偏差修正可调整:
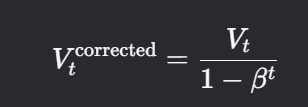
修正后的值在训练初期更准确,随着 tt增大,修正因子趋近于1。
SGD(随机梯度下降):
先设计一个学习率η,参数沿着梯度的反方向移动,假设更新的参数为w梯度为g,那么w=w-ηg。

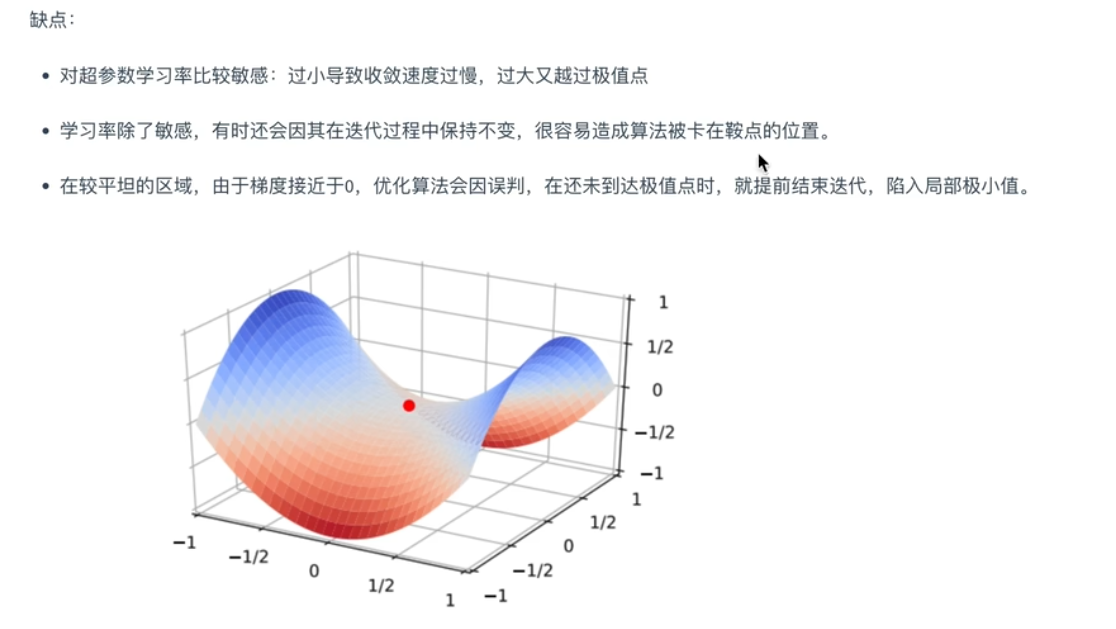
两个需要优化的参数,如果有一个的参数梯度很大,会出现震荡。
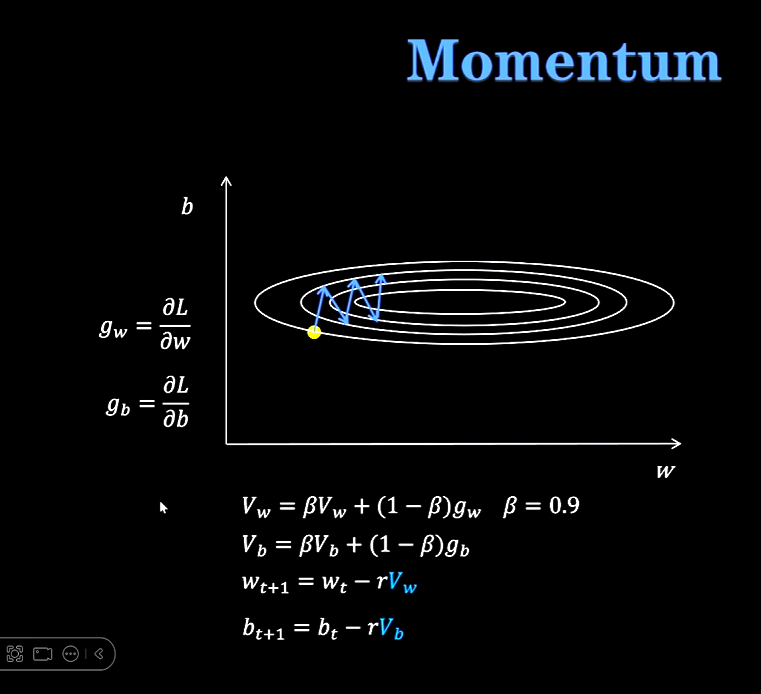
Momentum:
用梯度的指数加权平均值来更新参数。
核心思想
-
指数加权移动平均
Momentum 会计算梯度的指数加权移动平均(类似于“惯性”),而不仅仅使用当前时刻的梯度。这使得参数更新方向不仅依赖于当前的梯度,还受到历史梯度的影响。 -
减少震荡
在优化过程中,如果梯度方向频繁变化(如病态曲率或噪声较多的场景),Momentum 能平滑更新方向,减少震荡,更快穿过平坦区域或狭窄山谷。
数学公式
Momentum 的更新规则(以梯度下降为例):
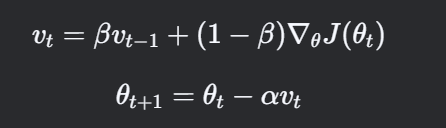
其中:
-
vt:当前时刻的动量(累积梯度)。
-
β:动量系数(通常设为 0.9 或 0.99),控制历史梯度的权重。
-
α:学习率。
-
∇θJ(θt):损失函数在参数 θt 处的梯度。
注意:有些实现会省略 (1−β),直接使用
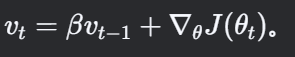
效果
-
加速收敛:在梯度方向一致的维度上,动量会累积梯度,增大更新步长。
-
抑制震荡:在梯度方向变化的维度上,动量会抵消部分震荡,使更新更稳定。
变体与改进
-
Nesterov Accelerated Gradient (NAG)
Nesterov 动量是 Momentum 的改进版,先根据动量项预测下一步的参数位置,再计算梯度。公式:
NAG 能更准确地调整更新方向,进一步提升收敛速度。
-
结合自适应方法
现代优化器(如 Adam、Nadam)将 Momentum 与自适应学习率结合,同时利用动量和梯度的二阶矩信息。
直观理解
想象一个小球从山顶滚下:
-
普通梯度下降:小球每一步只根据当前坡度决定方向,容易卡在局部低谷或震荡。
-
Momentum:小球像有“惯性”,会记住之前的运动方向,更容易冲过平坦区域或窄谷。
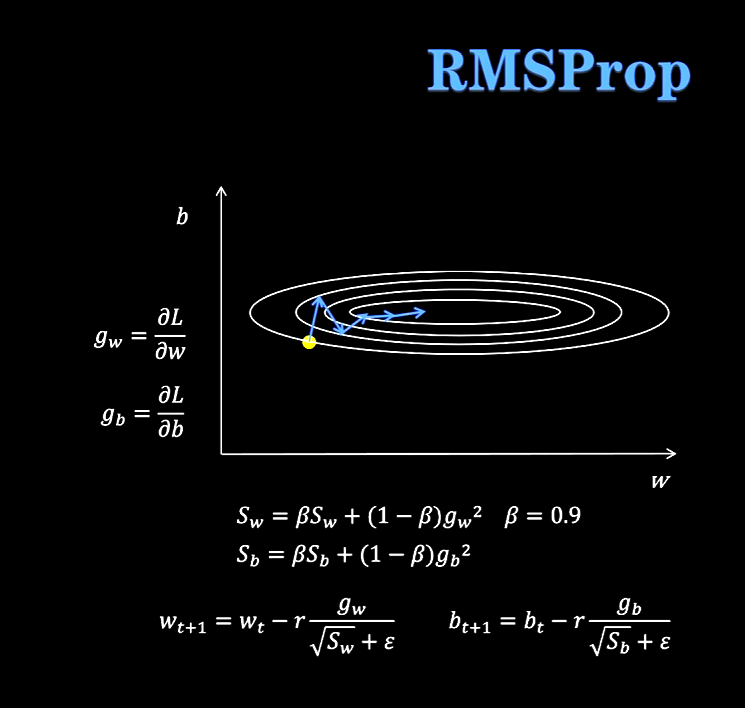
RSNOProp:
每个参数的梯度大小不一样,有的很大有的很小,让每一个参数都除一个代表自己过去梯度大小的值。
Adam:
前两种的结合并对指数加权平均值进行了修正。

AdamW:
更新参数的时候进行权重衰减,防止参数过大,提高泛化性。

Softmax :
作用
Softmax 是一种归一化函数,将模型的原始输出(logits)转换为概率分布,使得每个类别的预测概率在 0 到 1 之间,且所有类别的概率之和为 1。
适用场景:多分类任务(如 MNIST 手写数字识别、CIFAR-10 图像分类等)。
数学公式
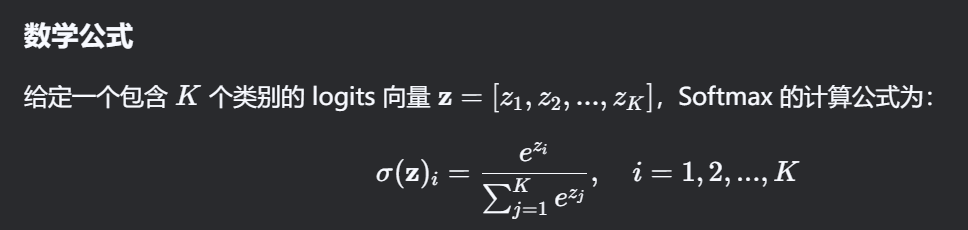
其中:
-
σ(z)i是第 i个类别的预测概率。
-
分母是所有类别的指数和,确保归一化。
特性
-
放大差异:Softmax 会放大较大 logits 的占比(指数效应),抑制较小值。
-
可导性:便于反向传播优化模型。
-
与交叉熵的配合:Softmax 的输出直接作为交叉熵损失的输入。
One Hot编码:
如果用softmax进行分类,标记1为牛、2为海牛、3为海公牛。假定x为牛,那么把他标记为2海牛和3海公牛都是错误的,但是明显把他标记为海牛的可能性远大于海公牛,没有做到各个类别的独立性,那么我们可以引用ont hot编码。标记(1,0,0)为牛、(0,1,0)为海牛、(0,0,1)为海公牛。如x计算为(0.75,0.2,0.05)表示为x为牛的概率为0.75为海牛的概率为0.2为海公牛的概率为0.05.
Guided Attention(引导注意力):
Encoder和Decoder框架来处理不定长的输入和输出。Encoder把不定长的输入转换为定长的向量。Seq2Seq有一些问题,输入的序列长度过长时,只靠最后一个时间点的编码结果会造成信息丢失,编码向量由最后一个时间点输出的,导致网络对靠近结尾的信息“记忆深刻”,对起始部位的记忆模糊。
Guided Attention 是一种在序列到序列(Seq2Seq)任务中通过显式约束注意力权重分布的技术,旨在引导模型在训练过程中学习符合任务先验知识的对齐方式。它常用于需要严格对齐关系的任务,如语音合成(TTS)、语音识别(ASR)或图像描述生成,以避免注意力权重发散或错误对齐。
核心思想
-
强制对齐约束
通过引入额外的监督信号(如位置掩码或正则化损失),限制注意力权重的分布范围,使其符合任务特性(例如语音合成中文本与语音帧的单调对齐)。 -
加速收敛
减少模型在训练初期因随机初始化导致的无效探索,直接学习合理的注意力路径。 -
提升鲁棒性
抑制噪声或冗余区域的关注,增强模型对关键特征的聚焦能力。
常见方法
1. Guided Attention Loss
在损失函数中增加对注意力权重的正则化项,惩罚不符合预期的注意力分布。
典型应用:语音合成(Tacotron等模型)。
数学公式:
假设注意力权重矩阵为 A∈RT×S(T为输出序列长度,S 为输入序列长度),引导损失可设计为:
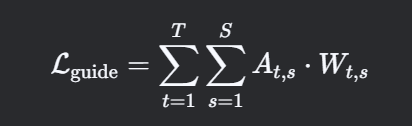
其中 Wt,s 是预定义的权重矩阵,用于惩罚偏离期望区域的注意力权重。
例如,在语音合成中,期望注意力权重沿对角线分布(文本与语音帧单调对齐),则 Wt,s 可设置为:

(高斯分布惩罚偏离对角线的权重)
2. Attention Mask(注意力掩码)
通过硬性掩码限制注意力权重的可访问区域。
示例:
-
在语音合成中,强制模型在解码第 tt 帧时只能关注输入文本的前 k⋅tk⋅t 个词(kk 为缩放因子)。
-
在图像描述生成中,限制解码器在生成某个词时仅关注图像的特定区域。
3. Monotonic Alignment(单调对齐)
强制注意力路径单调递增,适用于输入与输出严格按顺序对齐的任务(如TTS)。
实现方式:
-
使用单调注意力机制(Monotonic Attention),在训练中逐步约束注意力权重的移动方向。
应用场景
-
语音合成(TTS)
-
问题:文本与语音帧需严格按时间顺序对齐,但原始注意力机制可能出现跳跃或重复。
-
方案:使用 Guided Attention Loss 或单调注意力,强制对齐路径沿对角线分布。
-
效果:减少合成语音的漏词、重复等问题,提升自然度。
-
-
语音识别(ASR)
-
问题:语音帧与文本需大致对齐,避免注意力权重分散。
-
方案:添加对角引导损失,约束注意力权重集中在合理范围内。
-
-
图像到文本生成
-
问题:生成某个词语时需聚焦图像相关区域。
-
方案:通过注意力掩码限制模型仅关注图像特定区域(如通过目标检测框先验)。
-
Batch Normalization(批次标准化):
在层次的深度学习中,上一层的输出即是下一层的输入,而每一层的分布都无法预测。由于参数更新,每一层的都在变化,导致难以收敛。
Batch Normalization(批次标准化)是一种用于深度神经网络训练的技术,由Sergey Ioffe和Christian Szegedy在2015年提出。它的主要目的是通过标准化神经网络的中间层输入,加速训练过程并提高模型的稳定性。
核心思想
在训练深度神经网络时,每一层的输入分布会随着参数更新而发生变化(称为 Internal Covariate Shift),这可能导致训练速度变慢或梯度消失/爆炸。Batch Normalization 通过对每一层的输入进行标准化(均值为0,方差为1),强制其分布保持稳定。
具体步骤
-
计算批次统计量
对于一个批次(batch)的输入数据 x∈RN×H×W×C(N为批次大小):-
计算批次的均值:
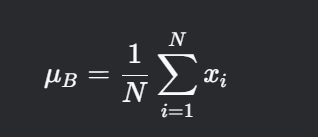
-
计算批次的方差:
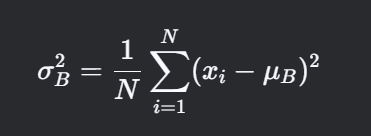
-
-
标准化
对每个样本进行标准化: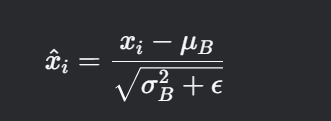
其中,ϵϵ 是一个极小值(如 10−5),防止分母为零。
-
可学习的缩放与偏移
引入两个可训练参数 γ(缩放因子)和 β(偏移因子),恢复模型的表达能力: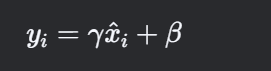
关键优势
-
加速训练
-
缓解梯度消失/爆炸问题,允许使用更大的学习率。
-
减少对参数初始化的敏感度。
-
-
正则化效果
-
通过对每个批次的均值和方差添加噪声,隐式地起到正则化作用(类似Dropout)。
-
-
降低过拟合
-
尤其在小数据集或复杂模型中表现显著。
-
训练与测试的区别
-
训练阶段:使用当前批次的均值和方差进行标准化。
-
测试阶段:使用训练过程中所有批次均值和方差的移动平均值(running mean/variance),而非单个批次的统计量。
常见应用位置
Batch Normalization 通常插入在:
-
全连接层或卷积层 之后。
-
激活函数(如ReLU) 之前(主流做法)。
例如,在卷积神经网络中:
Conv → BatchNorm → ReLU → Pooling
变体与改进
-
Layer Normalization
对单个样本的所有神经元进行标准化,适用于循环神经网络(RNN)。 -
Instance Normalization
对图像每个通道单独标准化,常用于风格迁移任务。 -
Group Normalization
将通道分组后标准化,适合小批量(batch size较小)场景。
局限性
-
依赖批次大小
-
当批次过小时(如batch size < 8),统计量估计不准确,效果下降。
-
-
不适用于RNN
-
时间步动态变化时,需结合其他标准化方法(如Layer Norm)。
-
ReLU(Rectified Linear Unit):
ReLU(Rectified Linear Unit) 是深度学习中应用最广泛的激活函数之一。它通过简单的非线性变换,有效缓解了梯度消失问题,成为现代神经网络的核心组件。以下是关于ReLU的详细解析:
数学定义
ReLU函数定义为:
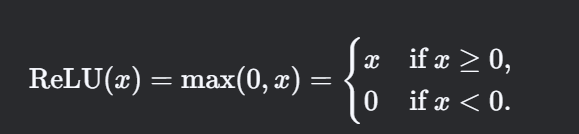
其导数为:
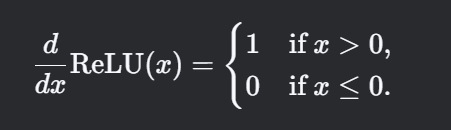
核心特性
-
稀疏激活
对负输入输出零,仅激活部分神经元,使网络更轻量且易于优化。 -
缓解梯度消失
正区间的导数为1,反向传播时梯度直接传递,避免深层网络中的梯度衰减。 -
计算高效
仅需比较和阈值操作,计算速度远超Sigmoid、Tanh等函数。
局限性及解决方案
1. 死亡ReLU问题(Dead ReLU)
-
现象:某些神经元可能永远输出0(尤其初始化不当或学习率过高时),导致参数无法更新。
-
解决方案:
-
Leaky ReLU:负区间引入微小斜率(如0.01):
LeakyReLU(x)=max(αx,x)(α≈0.01) -
Parametric ReLU (PReLU):将斜率αα作为可学习参数。
-
Randomized ReLU (RReLU):训练时随机采样αα,测试时固定。
-
2. 输出非零中心化
-
影响:可能导致梯度更新效率下降。
-
缓解:配合Batch Normalization使用,标准化输入分布。

)




