一、安装依赖
用WindTerm在远程服务器上创建并激活虚拟环境(以下为示例):
python3 -m venv llama
source llama/bin/activate如果是第二次激活虚拟环境:
cd /root/llama
source bin/activate在本地用Git下载llama factory项目源码:
git clone https://github.com/hiyouga/LLaMA-Factory.git 然后上传源码文件到远程服务器,再安装llama factory依赖:
(ps:以下命令要在虚拟环境中进行)
cd /root/LLaMA-Factory/
pip install -r requirements.txt
pip install -e .[metrics] #下载llama factory命令二、下载模型
下载modelscope(魔塔社区——该平台有许多大模型的源码和数据集)的python库,以方便下载各种文件:(当然也可以去hugging face下载,这一步可选)
pip install modelscope -U 比如我想下载deepseek-r1-distill-qwen-7b模型,就可以在命令行输入:
modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B具体的下载命令去modelscope官网找就可以了,每个模型的详情页面都会提供。
三、准备数据集
有以下几点需要注意:
1.llama factory仅支持alpaca和sharegpt格式,要确保你的数据集是以上两种格式之一。
如下是alpaca格式:
[{"instruction": "用户指令(必填)","input": "用户输入(选填)","output": "模型回答(必填)","system": "系统提示词(选填)","history": [["第一轮指令(选填)", "第一轮回答(选填)"],["第二轮指令(选填)", "第二轮回答(选填)"]]}
]
2.准备好数据集之后,还需要创建一个 dataset_info.json 文件,并将其放在数据集目录中。该文件应包含数据集的相关信息,例如数据集的名称、路径、语言、格式等。
文件结构
假设你的数据集文件是 data.json,并且存储在 my_dataset 文件夹中,目录结构应如下所示:
my_dataset/
├── data.json
└── dataset_info.json示例 dataset_info.json
以下是一个示例 dataset_info.json 文件的内容:
{"my_custom_dataset": {"file_name": "data.json","columns": {"prompt": "instruction","query": "input","response": "output","system": "system","history": []}}
}字段解释
-
my_custom_dataset: 是你为这个数据集指定的名称。在微调命令中,你需要用这个名称来指定数据集。 -
file_name:["data.json"]是数据集目录中实际的数据文件名。
四、开始微调
首先需要确认电脑是否有足够的显存、内存来进行模型微调:
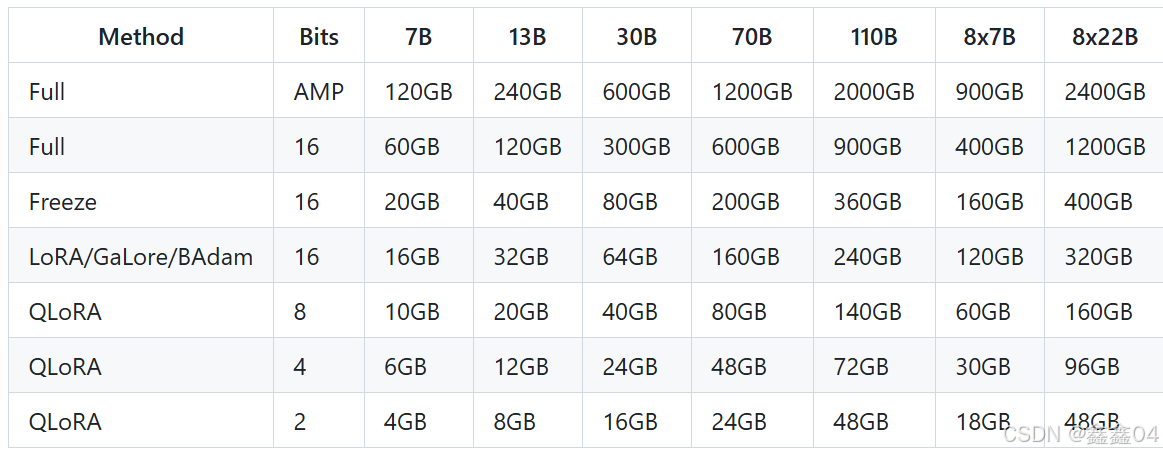
通过上面这张图,我们可以根据自身显存的情况来选择合适的微调方法。
方法1:启动WebUI
在/LLaMA-Factory的项目路径下,启动llama factory的前端微调界面:
CUDA_VISIBLE_DEVICES=0 llamafactory-cli webui会显示以下内容:

这就说明远程服务器已经启动了WebUI。
配置 SSH 端口转发:
-
在本地终端中,使用以下命令建立 SSH 隧道,将远程服务器的
7860端口转发到本地的7860端口:ssh -CNg -L 7860:127.0.0.1:7860 用户名@远程服务器IP -p 22-
将
用户名替换为远程服务器的用户名。 -
将
远程服务器IP替换为远程服务器的 IP 地址。 -
如果服务器的 SSH 端口不是
22,请相应地修改-p参数。
-
输入远程服务器的密码,就可以在本地运行WebUI了。
方法2:命令行微调
我们也可以不使用WebUI,而是直接用命令行进行微调。以下为示例:
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train \
--model_name_or_path /path/to/DeepSeek-R1-Distill-Qwen-7B \ #这里替换为你的模型文件路径
--dataset my_custom_dataset \
--dataset_dir ./my_dataset \ #这里替换为你的数据文件夹路径(包含数据集和dataset_info)
--template alpaca \
--finetuning_type lora \
--output_dir ./results \
--per_device_train_batch_size 4 \
--num_train_epochs 3 \
--learning_rate 2e-5 \
--stage sft \
--do_train \
--fp16 \
--quantization_method bnb逐行解释:
-
CUDA_VISIBLE_DEVICES=0:指定使用第 0 块 GPU。 -
--model_name_or_path:指定模型的路径。 -
--dataset:指定数据集的名称,必须与dataset_info.json中的dataset_name一致。 -
--dataset_dir:指定数据集目录,必须包含dataset_info.json文件。 -
--template:指定数据集的模板格式,这里使用alpaca。 -
--finetuning_type:指定微调类型,如lora。 -
--output_dir:指定微调结果的输出目录。这里就是会保存在results文件夹。 -
--per_device_train_batch_size:每个设备的训练批量大小。 -
--num_train_epochs:训练的轮数。 -
--learning_rate:学习率。 -
--stage:指定训练阶段,如sft(Supervised Fine-Tuning)。 -
--do_train:启用训练模式。 -
--fp16:启用混合精度训练,可以减少显存使用。 -
--quantization_method bnb: 使用 QLoRA,这里 bnb 表示使用bitsandbytes进行 8 比特或 4 比特量化。
确保安装了 bitsandbytes 库:
pip install bitsandbytes如果你的命令行支持自动补全功能,输入时可以利用 Tab 键快速补全参数。

)

)
)

