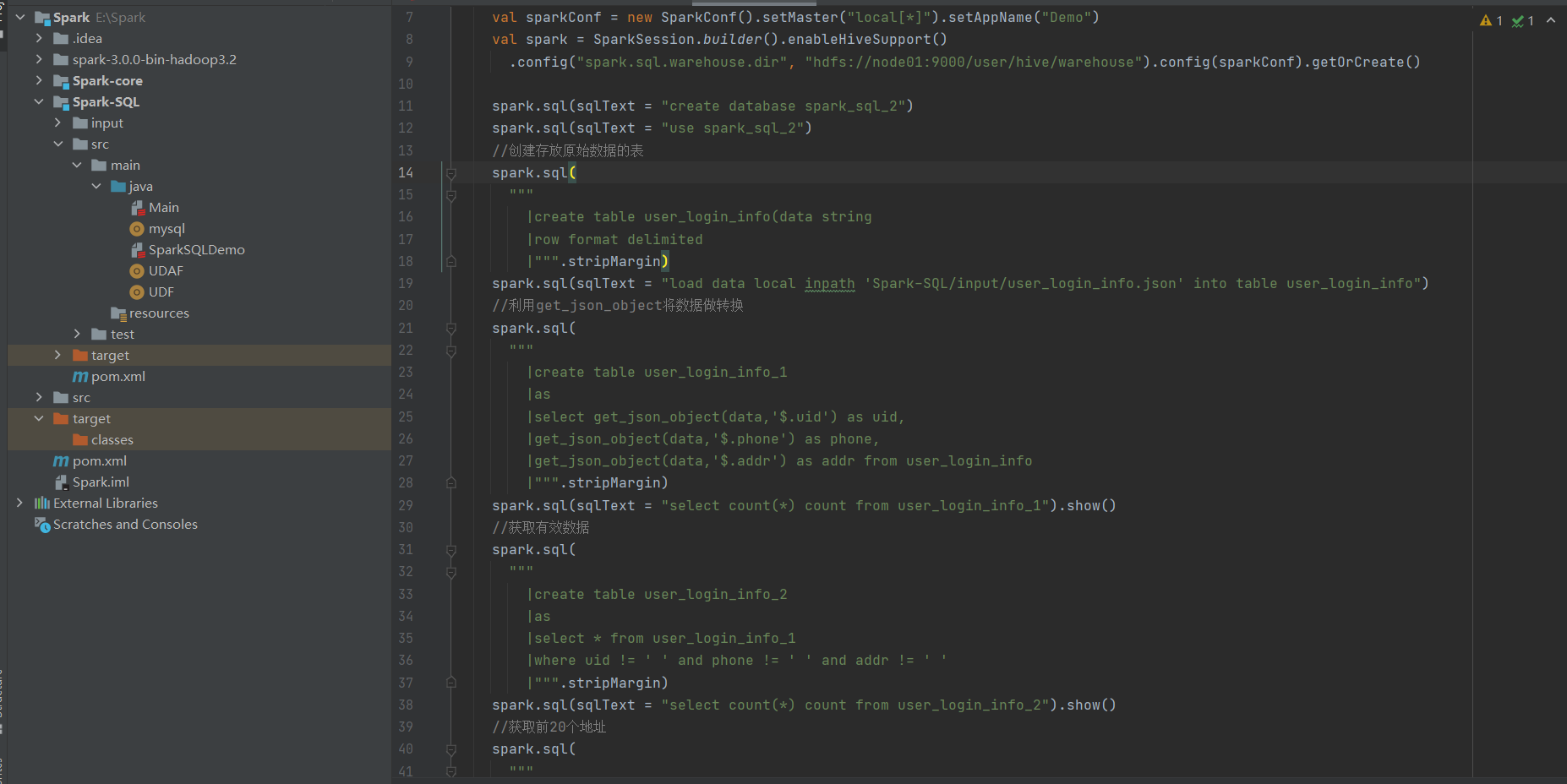
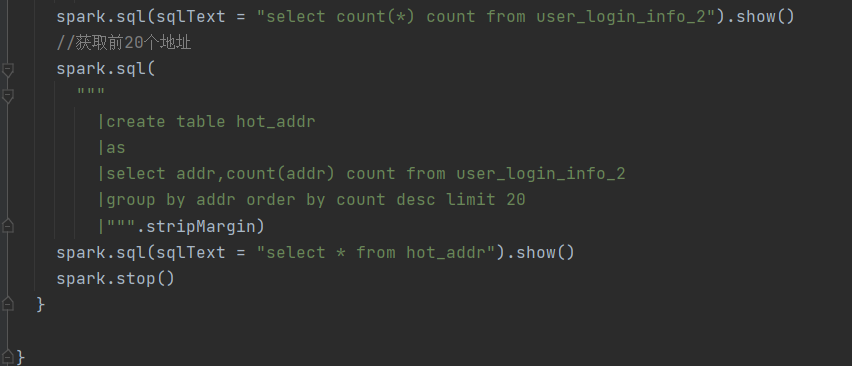
spark–sql项目代码,找出所有有效数据,要求电话号码为11位,但只要几列中没有空值就算作有效数据。按照地址分类,输出条数最多的前20个地址及其数据。
Spark-Streaming概述
Spark Streaming 用于流式数据的处理。Spark Streaming 支持的数据输入源很多,例如:Kafka、Flume、Twitter等,以及和简单的 TCP 套接字等等。数据输入后可以用 Spark 的高度抽象原语如:map、reduce、join、window 等进行运算。而结果也能保存在很多地方,如 HDFS,数据库等。Spark Streaming 使用离散化流(discretized stream)作为抽象表示,叫作 DStream。

Spark-Streaming的特点:
易用性:Spark Streaming支持Java、Python、Scala等编程语言,可以像编写离线程序一样编写实时计算的程序
容错:Spark Streaming在没有额外代码和配置的情况下,可以恢复丢失的数据。对于实时计算来说,容错性至关重要。
易整合:Spark Streaming可以在Spark上运行,并且还允许重复使用相同的代码进行批处理。也就是说,实时处理可以与离线处理相结合,实现交互式的查询操作。
Spark Streaming架构:
驱动程序(StreamingContext)处理数据并传给SparkContext。
工作节点接收和处理数据,执行任务并备份数据到其他节点。
背压机制协调数据接收能力和资源处理能力,避免数据堆积和资源浪费。
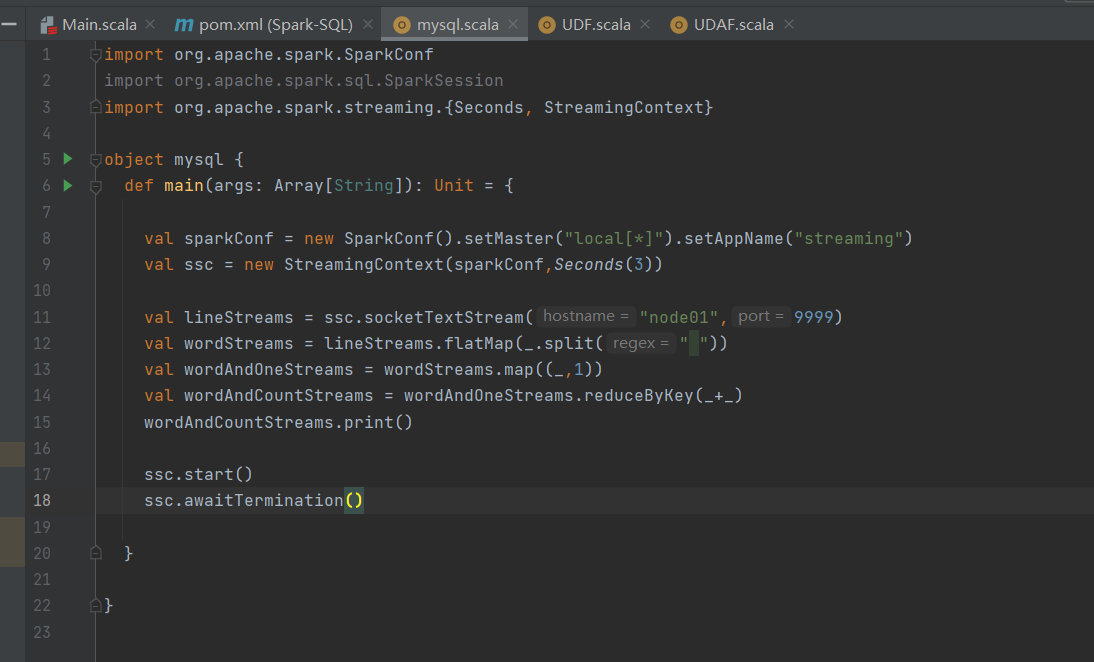
DStream实操
WordCount案例
1.添加依赖

2.编写代码
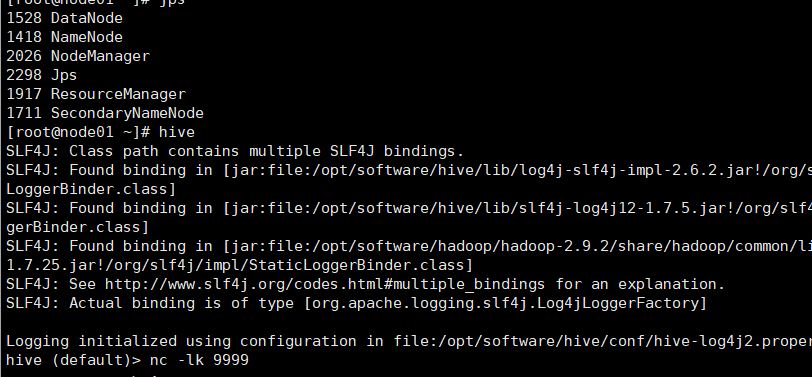
3.启动netcat发送数据
自定义数据源
自定义数据源需要继承 Receiver,并实现 onStart、onStop 方法来自定义数据源采集。
需要导入新的函数并继承现有的函数。注意创建数据源时需选择class而不是object。
在class中定义on start和on stop方法,并在这些方法中实现具体的功能。
类的定义和初始化
类的定义包括数据类型的设定,如端口号和TCP名称。使用extends关键字继承父类的方法。
数据存储类型设定为内存中保存。
数据接收和处理
在on start方法中创建新线程并调用接收数据的方法。连接到指定的主机和端口号,创建输入流并转换为字符流。逐行读取数据并写入到spark stream中,进行词频统计。
数据扁平化和词频统计
使用block map进行数据扁平化处理。将原始数据转换为键值对形式,并根据相同键进行分组和累加。输出词频统计结果。
程序终止条件
设定手动终止和程序异常时的终止条件。在满足终止条件时输出结果并终止程序。


![[特殊字符][特殊字符] HarmonyOS相关实现原理聊聊![特殊字符][特殊字符]](http://pic.xiahunao.cn/nshx/[特殊字符][特殊字符] HarmonyOS相关实现原理聊聊![特殊字符][特殊字符])



