注:本文为关于“声波通讯 | 音频识别及应用”相关文章合辑。
略作重排,未全部整理。
如有内容异常,请看原文。
因 csdn 审核问题,删除了文中作者推介。

声波通讯的原理
softlgh 已于 2023-12-17 23:39:13 修改
声波传输是一种利用声音作为传输方式的数据通讯方法。我们日常生活中经常使用声音传输信号,例如说话就是一种典型的声波信号传输实例。说话过程可视为将信号编码为声音的过程,而聆听则是将音频信号解码为语言文字的过程。中文文字与拼音之间的对应关系,可类比为该通讯过程中的音频协议。音乐也可视为一种声波通讯方式,其音频协议可理解为乐谱,演奏过程则是将乐谱编码为声音的过程。古代战争中的战鼓也是一种声波传输方式,战鼓的不同敲击方式代表着进攻、退兵等章法细节,这些细节即为音频协议。

因此,利用声波进行传输对我们而言并不陌生,它不仅在现代生活中广泛应用,而且历史悠久。
然而,本文所讨论的声波通讯的音频协议通常来源于 chirp 的技术文档,其应用场景一般指电脑、android/iphone 等智能手机、各类单片机设备或其他能发声设备之间的信息传播。
chirp 描述了智能设备之间依靠声音进行数据通讯的技术细节,但声波通讯的音频协议实际上可以由使用者自行设计。例如,可将 chirp 音频协议中的声音改为双频音甚至多频音,以增加单位时间内的信息容量,从而提高传输速度,只要存在应用需求,这种改动都是可行的。
chirp 的音频协议技术细节
建立一个包含 32 个字符([0-9,a-v])的表,并将每个字符映射到频率表。频率表是根据乐理,通过伴音的计算生成的。
| 字符 | 频率 (Hz) |
|---|---|
| 0 | 1760 |
| 1 | 1864 |
| … | … |
| v | 10.5k |
一个完整的声波包包含 20 个音(即 20 个字符),每 87.2 毫秒发送一个音。前两位为信息头,采用 “hj”,用于通知接收端开始接收。中间 10 位为有效的信息位,是有效的传输信息,即 Key 值经过映射后的频率信息。最后 8 位为 RS 校验位,通过 RS 校验算法对中间 10 位进行计算,生成 8 位的校验信息。如下表所示:
| 2 位 | 10 位 | 8 位 |
|---|---|---|
| hj | 数据 | rs 校验码 |
校验主要用于处理因噪声干扰造成的信息接收错误。通过 RS 校验,可以纠正 25% 的错误信息。
接收端需要记录声音,并将其进行解码以及容错处理。其对算法的要求相对较高,降噪及容错处理对于能否得到正确的解码信息至关重要,解码端的难点也在于此。
声波通讯的应用场景
目前市场上已有一些应用了声波通讯的实例,如支付宝的声波支付、微信的声波雷达加好友、QQ 音乐中的歌曲声波分享、茄子快传、蛐蛐儿等。国外的 apple、google 也都有声波通讯的应用。
声波实际上可视为一种比二维码更友好的传输方式,二维码能实现的功能与声波有较大相似性,但声波使用起来更为便捷。实现上述功能时,通常只需靠近手机并进行简单的操作(如点击、划动、推送、甩动、摇动等),而无需像使用二维码那样打开摄像头并精准对准拍摄。相比之下,声波传输更像是刷卡一样方便简单,可以理解为类似 NFC 的一种近场通讯技术。
例如,声波支付流程在前面已有介绍,其大致思路如下:
- 声波会员卡:用户到店铺后无需携带物理卡,手机可替代所有会员卡。在商家处一碰,会员信息即可自动显示。
- 声波券票:以电子团购券、电子电影券为例,可设置成唯一编码。到场后与录音设备一碰,系统就能识别该券票。
- 声波签到:在固定位置安装签到软件,用户到达后可快速完成签到操作。
- 声波分享:以文件、图片或 App 内的任何项目为例。假设 A 要将一张图片发送给 B,A 点击共享按钮(或进行其他操作),手机通过声音将图片编号发送出去。B 收到该编号后,立即从平台服务器下载该图片。最终效果是 A 在要分享的图片上一点,B 即可收到该图片,非常方便快捷。
声波通讯的传输效率不高,因此对大数据传输一般采用如下流程:

3 分钟为你的应用添加声波通信功能
softlgh 已于 2023-12-17 23:35:45 修改
android/iphone/windows/linux/微信 声波通信库,使手机与手机或者手机与设备之间具备通信能力,可广泛应用于智能设备的声波 wifi 配码、声波智能锁、手机支付、声波广告互动、手机名片等领域。
基本特征如下:
- 准确性 98% 以上。
- 接口非常简单,有完整的示例,3 分钟就可以让你的应用增加声波通信功能。
- 抗干扰性强,基本上无论外界怎么干扰,信号都是准确的。
- 可自行任意调整通信频段,支持低频有声频段,也支持高频无声频段。无声频段可混音任意效果声音,如咻咻咻等。
- 支持半双工通信,使用两个频段可支持全双工通信。
- 可同时最多支持 3 个频段进行通信。
- 通信速度正常在 60bps,也可调整到 120bps 或者 200bps(包含校验和纠错码)。
- 基本的编码为 16 进制,而通过编码可传输任何字符。
- 一般通信的传输距离版本为 1 米以内,加大音量可在 5 - 10 米,声波广告互动的信号传输距离在 10 - 20 米以上,通过设备传输距离可在 50 米以上。
- 性能非常强,没有运行不了的平台。而且通过内存池优化,长时间解码不再分配新内存,可 7×24 小时运行。
可支持任何平台,常见的平台 android、iphone、windows、linux、arm、mipsel、stm32、微信小程序等都可以运行。
一、准确性
准确性 98% 以上。如果有识别问题的情况,可开启调试模式。该模式下会自动保存识别失败的音频段,可将该音频段发送进行分析,以确定识别失败的原因。如果确实是识别器未考虑到的情况,调整识别规则即可完善识别。此外,传输中加入了校验码,校验码有两个目的:一是保证识别正确性,确保识别结果要么失败,要么正确,不会出现传输的是 1,而识别提示为 0 的情况;二是错误自动修正,从而保证传输中可以有 20% 左右(取决于传输的数据长度)的错误而可以自动修正,使得使用过程中基本不会出现识别错误。识别接口中的参数指定了识别是否成功完成,错误码则指出了如果识别失败的话,失败的原因。
二、接口简单
接口尽量设计得简单易用。既然是作为库使用,使用起来越简单越好,尽量不要去管底层的一些控制参数,例如声音采样频率、采样精度、采样格式、传输频率、传输码表、音量、缓冲区大小等。当然,如果需要定制,这些参数也都可以进行调整。在这里,这些参数的默认值如下:声音采样频率为 44100,单声道,2 个字节(16 位)长的采样精度,小端编码,帧大小为 1×2 = 2 个字节,那么每秒处理的数据量为 44100×2 = 88200 字节。传输频率为高频段,抗干扰能力非常好,无论是在闹市、马路、KTV 或其他室外场景下,还是在家里开着大音箱听歌,都不会影响到数据的传输。码表为 16 进制的数据编码,即所有数据都会编成 16 进制后传输。缓冲区默认需 10k 左右的缓冲区(其他内存分配都在内存池中完成,长时间运行解码不会再分配内存)。如果对这些参数完全不懂,可直接忽略,因为接口足够简单,能用即可,也不用理解太多原理。不过解码器要求传入的音频数据必须是这些格式,特别是输入数据要求为 44100,单声道,16bits 采样精度,小端编码的音频数据。
三、混音音效
由于传输频率属于高频段,开始超出正常人可听到的阶段,所以发送时感觉没什么反应。因此,可以在人耳可听到的范围另外加一段可听到的音频音效(如咻咻咻、啾啾啾等),让用户知道系统正在通讯中。最终效果是人听到的是人耳可听到的那部分音频音效,而设备则可解码出真正的信号,且两者不会相互干扰。
四、传输距离
传输距离取决于音量。音量较大时,传输距离就远。一般手机使用在 1 米以内,加大音量可在 5 - 10 米,特别定制的声波广告互动版本信号传输距离在 10 - 20 米以上,通过设备传输距离可在 50 米以上。
五、性能
系统有两种工作模式:一种是优化内存模式,耗 CPU 稍多一点,但耗内存小,在当前正常使用的电脑或智能手机下使用是没有问题的。正常 PC 机的 CPU 基本上在 1% 以下,反正 Windows 任务管理器里显示的是 0,应该是 1% 以下就会显示为 0%,估计在百分之零点几左右。另一种是优化 CPU 模式,如果是在计算能力非常有限的平台上使用(例如计算能力不到 PC 千分之一的平台),可以使用这种模式。这种模式下,基本不会占用 CPU,但会占用较多内存。如果 CPU 真的非常慢,解码时间会长一点,但无论系统有多慢,都不会解不出来,也不会影响解码正确性,只是速度慢的话解码出来的时间稍长一些。
六、数据传输量
声波通信的传输数据量有限。声波 1 秒只能传输十几个字符左右,而且一般来说,传输总字符如果达到 40 个以上,解码正确率就会下降,数据量越大,出错率就会升高。因此,不能期望以 k 级来传输数据量。声波传输主要用于握手和对接,真正的数据是通过对接后在互联网上传输的。例如面对面的声波支付,A 要付款给 B,声波通信主要是传输用户标志或付款单编号来快速握手(这当然与设计的支付流程有关)。以模拟刷卡的流程为例:A(客户)在 B(商家)的 POS 机上刷一下银行卡,B(商家)就知道 A(客户)是哪张银行卡,从而把该卡和金额传到支付公司去扣款。换成声波后也是一样的,A(客户)在手机上点一下付款,A(客户)的手机发出一串声波,声波上传输 A(客户)的用户标识,传到 B(商家)的手机,这时 B(商家)就可以把 A(客户)的标志和扣款金额传到支付公司去扣款了。当然也可以设计一个反过来的流程,即由 B 端(商家端)发出一串账单音频,而由 A 端接收(客户端),但原理是一样的。在整个流程中,声波是作为系统对接使用的,替代刷银行卡或扫二维码的对接方式,然后真正的数据传输还是在互联网上进行的。
七、编码
采用 16 进制的传输码,要传输的信息可自行先编成 16 进制码。不过码表是可以定制的,例如想传输数据量更大一点,可扩展到 32 进制,这样相对来说传输数据量编码后会更小,数据量可以传输得更大一些。如果要传输的是数字,先把数字编成 16 进制编码;如果要传字母,那么一个字母可以编成 2 个 16 进制的字符。以下列出几种编码的情况。例如要传输 QQ 号、手机号这类数字,最好转成 16 进制后再传输。以传输手机号为例:手机号肯定是以 1 开始的,那么 1 就可以不传了。而且手机号都是以 13、15、18 开头,可把 3、5、8 先映射为 1、2、3,然后再做 16 进制转码。当然解码端要按照编码时的方法进行解码。这样,一个手机号本来有 11 位,优化下来可以做到 9 位或 8 位。声波传输就是要尽量减少数据量,数据量越小,传输准确率就越可靠,系统就越可靠。以下列出几种编码的示例。
手机号编成 16 进制声波通信编码:
/************************************************************************
声波通信库示例,16进制声波通信编码
声波通信库特征:
准确性98%以上,其实一般是不会出错的。
接口非常简单,有完整的示例,3分钟就可以让你的应用增加声波通信功能
抗干扰性强,基本上无论外界怎么干扰,信号都是准确的
基本的编码为16进制,而通过编码可传输任何字符
性能非常强,没有运行不了的平台,而且通过内存池优化,长时间解码不再分配新内存,可7*24小时运行
可支持任何平台,常见的平台android, iphone, windows, linux, arm, mipsel都有示例
详情可查看:[softlgh-CSDN博客](http://blog.csdn.net/softlgh)
作者: 夜行侠 QQ:3116009971 邮件:3116009971@qq.com
************************************************************************///13,14,15,18开头的手机号,手机号去除1以后,16进制在9位以内
public static String encode(String _mobile)
{if(_mobile.length() == 11 && _mobile.startsWith("1")){ long _number = Long.parseLong(_mobile.substring(1));String s = Long.toHexString(_number);while(s.length() < 9){s = "0" + s;}return s;}return null;
}
任意字符串(先换成 byte[])编成 16 进制声波通信编码:
/************************************************************************
声波通信库示例,16进制声波通信编码
声波通信库特征:
准确性98%以上,其实一般是不会出错的。
接口非常简单,有完整的示例,3分钟就可以让你的应用增加声波通讯功能
抗干扰性强,基本上无论外界怎么干扰,信号都是准确的
基本的编码为16进制,而通过编码可传输任何字符
性能非常强,没有运行不了的平台,而且通过内存池优化,长时间解码不再分配新内存,可7*24小时运行
可支持任何平台,常见的平台android, iphone, windows, linux, arm, mipsel都有示例
详情可查看:[softlgh-CSDN博客](http://blog.csdn.net/softlgh)
作者: 夜行侠 QQ:3116009971 邮件:3116009971@qq.com
************************************************************************/
public static final char[] hexChars = {'0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'a', 'b', 'c', 'd', 'e', 'f'};
public static String encodeString(byte[] _val)
{StringBuffer result = new StringBuffer(_val.length*2);for(int i = 0; i < _val.length; i ++){result.append(hexChars[(_val[i] >> 4) & 0x0f]);result.append(hexChars[_val[i] & 0x0f]);}return result.toString();
}
八、使用场景
目前市场上已有一些应用了声波通讯的实例,如支付宝的声波支付、微信的声波雷达加好友、QQ 音乐中的歌曲声波分享、茄子快传、蛐蛐儿等。国外的 apple、google 也都有声波通讯的应用。
声波实际上可视为一种比二维码更友好的传输方式,二维码能实现的功能与声波有较大相似性,但声波使用起来更为便捷。实现上述功能时,通常只需靠近手机并进行简单的操作(如点击、划动、推送、甩动、摇动等),而无需像使用二维码那样打开摄像头并精准对准拍摄。相比之下,声波传输更像是刷卡一样方便简单,可以理解为类似 NFC 的一种近场通讯技术。
例如,声波支付流程在前面已有介绍,其大致思路如下:
- 声波会员卡:用户到店铺后无需携带物理卡,手机可替代所有会员卡。在商家处一碰,会员信息即可自动显示。
- 声波券票:以电子团购券、电子电影券为例,可设置成唯一编码。到场后与录音设备一碰,系统就能识别该券票。
- 声波签到:在固定位置安装签到软件,用户到达后可快速完成签到操作。
- 声波分享:以文件、图片或 App 内的任何项目为例。假设 A 要将一张图片发送给 B,A 点击共享按钮(或进行其他操作),手机通过声音将图片编号发送出去。B 收到该编号后,立即从平台服务器下载该图片。最终效果是 A 在要分享的图片上一点,B 即可收到该图片,非常方便快捷。
九、运行平台
该声波传输库可运行在 Windows 平台(所有 Windows 系统)、Linux 平台、mipsel 平台、arm 平台、iphone 平台、android 平台,全部都有 SDK。后面的附件中有各个平台的库,可自行选择下载。
十、代码及示例
库的结构非常简单:一个发送端,一个接收端。发送端很简单,基本上就是一个 send 函数。接收端稍微复杂一点,但也很简单:创建一个解码器,设置监听,往解码器送音频数据(解码器就会开始分析音频数据,并在监听到信号后通知),最后停止解码器和销毁解码器。使用非常简单,下面和附件中有例子说明。
这种库的使用毕竟是商用,所以不能免费。不过如果完全是没有任何商业目的的公益项目,完全可以免费使用。试用库识别次数有限,或者没有进行降噪处理。
各个平台的例子及源码如下:
android 平台声波通信发送端接口:
/************************************************************************
声波通讯库示例,android平台声波通讯发送端
声波通讯库特征:
准确性98%以上,其实一般是不会出错的。
接口非常简单,有完整的示例,3分钟就可以让你的应用增加声波通讯功能
抗干扰性强,基本上无论外界怎么干扰,信号都是准确的
基本的编码为16进制,而通过编码可传输任何字符
性能非常强,没有运行不了的平台,而且通过内存池优化,长时间解码不再分配新内存,可7*24小时运行
可支持任何平台,常见的平台android, iphone, windows, linux, arm, mipsel都有示例
详情可查看:[softlgh-CSDN博客](http://blog.csdn.net/softlgh)
作者: 夜行侠 QQ:3116009971 邮件:3116009971@qq.com
************************************************************************///创建声波通讯播放器
player = new VoicePlayer();
//开始播放
player.play("12345678abcdef", 1, 200);
iphone 平台声波通讯发送端接口:
/************************************************************************
声波通讯库示例,iphone平台声波通讯发送端
声波通讯库特征:
准确性98%以上,其实一般是不会出错的。
接口非常简单,有完整的示例,3分钟就可以让你的应用增加声波通讯功能
抗干扰性强,基本上无论外界怎么干扰,信号都是准确的
基本的编码为16进制,而通过编码可传输任何字符
性能非常强,没有运行不了的平台,而且通过内存池优化,长时间解码不再分配新内存,可7*24小时运行
可支持任何平台,常见的平台android, iphone, windows, linux, arm, mipsel都有示例
详情可查看:[softlgh-CSDN博客](http://blog.csdn.net/softlgh)
作者: 夜行侠 QQ:3116009971 邮件:3116009971@qq.com
************************************************************************/NSAutoreleasePool *tempPool = [[NSAutoreleasePool alloc] init];
//创建声波通讯播放器
VoicePlayer *player=[[VoicePlayer alloc] init];
//播放
[player play:@"12345678" playCount:1 muteInterval:0];
//没播放完之前,不要释放内存
while (![player isStopped]) {usleep(300 * 1000);//300ms
}
[tempPool drain];
Android 平台声波通信解码端代码:
/************************************************************************
声波通讯库示例,Android平台声波通讯解码端
声波通讯库特征:
准确性98%以上,其实一般是不会出错的。
接口非常简单,有完整的示例,3分钟就可以让你的应用增加声波通讯功能
抗干扰性强,基本上无论外界怎么干扰,信号都是准确的
基本的编码为16进制,而通过编码可传输任何字符
性能非常强,没有运行不了的平台,而且通过内存池优化,长时间解码不再分配新内存,可7*24小时运行
可支持任何平台,常见的平台android, iphone, windows, linux, arm, mipsel都有示例
详情可查看:[softlgh-CSDN博客](http://blog.csdn.net/softlgh)
作者: 夜行侠 QQ:3116009971 邮件:3116009971@qq.com
************************************************************************/
VoiceRecognition mRecognition = new VoiceRecognition();
mRecognition.setListener(new VoiceRecognitionListener()
{@Overridepublic void onRecognitionStart() {}public void onRecognitionEnd(int _recogStatus, String _val){if(_recogStatus == VoiceRecognition.Status_Success){System.out.println(_val);}}
});
mRecognition.start();
c 通用声波通讯解码端接口:
/************************************************************************
声波通讯库示例,声波通讯库c解码接口
声波通讯库特征:
准确性98%以上,其实一般是不会出错的。
接口非常简单,有完整的示例,3分钟就可以让你的应用增加声波通讯功能
抗干扰性强,基本上无论外界怎么干扰,信号都是准确的
基本的编码为16进制,而通过编码可传输任何字符
性能非常强,没有运行不了的平台,而且通过内存池优化,长时间解码不再分配新内存,可7*24小时运行
可支持任何平台,常见的平台android, iphone, windows, linux, arm, mipsel都有示例
详情可查看:[softlgh-CSDN博客](http://blog.csdn.net/softlgh)
作者: 夜行侠 QQ:3116009971 邮件:3116009971@qq.com
************************************************************************/
#ifdef VOICE_RECOG_DLL
#define VOICERECOGNIZEDLL_API __declspec(dllexport)
#else
#ifdef WIN32
#define VOICERECOGNIZEDLL_API __declspec(dllimport)
#else
#define VOICERECOGNIZEDLL_API
#endif
#endif
#ifndef VOICE_RECOG_H
#define VOICE_RECOG_H
#ifdef __cplusplus
extern "C" {
#endifenum VRErrorCode{VR_SUCCESS = 0};enum DecoderPriority{CPUUsePriority = 1//不占内存,但CPU消耗比较大一些, MemoryUsePriority = 2//不占CPU,但内存消耗大一些};typedef enum {vr_false = 0, vr_true = 1} vr_bool;typedef void (*vr_pRecognizerStartListener)(void);//_result如果为VR_SUCCESS,则表示识别成功,否则为错误码,成功的话_data才有数据typedef void (*vr_pRecognizerEndListener)(int _result, char *_data, int _dataLen);//创建声波识别器VOICERECOGNIZEDLL_API void *vr_createVoiceRecognizer(DecoderPriority _decoderPriority = CPUUsePriority);//销毁识别器VOICERECOGNIZEDLL_API void vr_destroyVoiceRecognizer(void *_recognizer);//设置识别到信号的监听器VOICERECOGNIZEDLL_API void vr_setRecognizerListener(void *_recognizer, vr_pRecognizerStartListener _startListener, vr_pRecognizerEndListener _endListener);//开始识别//这里一般是线程,这个函数在停止识别之前不会返回VOICERECOGNIZEDLL_API void vr_runRecognizer(void *_recognizer);//停止识别,该函数调用后vr_runRecognizer会返回//该函数只是向识别线程发出退出信号,判断识别器是否真正已经退出要使用以下的vr_isRecognizerStopped函数VOICERECOGNIZEDLL_API void vr_stopRecognize(void *_recognizer);//判断识别器线程是否已经退出VOICERECOGNIZEDLL_API vr_bool vr_isRecognizerStopped(void *_recognizer);//要求输入数据要求为44100,单声道,16bits采样精度,小端编码的音频数据//小端编码不用特别处理,一般你录到的数据都是小端编码的VOICERECOGNIZEDLL_API int vr_writeData(void *_recognizer, char *_data, int _dataLen);
#ifdef __cplusplus
}
#endif
#endif
使用 c 声波通讯接口从 wav 文件中解码的例子:
/************************************************************************
声波通讯库示例,从wav文件中读取音频信号进行解码,该工程示例是可跨平台的
声波通讯库特征:
准确性98%以上,其实一般是不会出错的。
接口非常简单,有完整的示例,3分钟就可以让你的应用增加声波通讯功能
抗干扰性强,基本上无论外界怎么干扰,信号都是准确的
基本的编码为16进制,而通过编码可传输任何字符
性能非常强,没有运行不了的平台,而且通过内存池优化,长时间解码不再分配新内存,可7*24小时运行
可支持任何平台,常见的平台android, iphone, windows, linux, arm, mipsel都有示例
详情可查看:[softlgh-CSDN博客](http://blog.csdn.net/softlgh)
作者: 夜行侠 QQ:3116009971 邮件:3116009971@qq.com
************************************************************************/
//当次解码结束的回调函数
void waveRecognizerEnd(int _recogStatus, char *_data, int _dataLen)
{if (_recogStatus == VR_SUCCESS){char buf[51];memcpy(buf, _data, _dataLen);buf[_dataLen] = 0;printf("------------------recognized data:%s\n", buf);}else{printf("------------------recognize invalid data, errorCode:%d\n", _recogStatus);}
}
//识别到有信号时开始解码回调函数
void waveRecognizerStart()
{printf("------------------recognize start\n");
}
//WIN32与linux所需的线程函数原型有点不一样
#ifdef WIN32
DWORD WINAPI waveRunVoiceRecognize( LPVOID _recognizer)
{
#else
void *waveRunVoiceRecognize( void * _recognizer)
{printf("voice recognizer thread start:%d\n", getpid());
#endifvr_runRecognizer(_recognizer);return 0;
}
//从wav文件中装载数据进入声波识别器
void test_voiceRecog_from_wav(int argc, char* argv[])
{char *wavFile = (char *)"data.wav";if(argc > 1){wavFile = argv[1];}//读入wav文件struct WavData wavData;memset(&wavData, 0, sizeof(wavData));readWave(wavFile, &wavData);printf("%s data size:%d\n", wavFile, (int)wavData.size);//创建识别器,并开始运行void *recognizer = vr_createVoiceRecognizer(MemoryUsePriority);vr_setRecognizerListener(recognizer, waveRecognizerStart, waveRecognizerEnd);
#ifdef WIN32HANDLE recogThread = CreateThread( NULL, 0, waveRunVoiceRecognize, recognizer, 0, 0 );//_beginthread(waveRunVoiceRecognize, 0, recognizer);
#elsepthread_t recogThread;pthread_create(&recogThread, NULL, waveRunVoiceRecognize, recognizer);//printf("voice recognizer thread id:%lu\n", (recogThread));
#endif//往识别器写入数据,这里可以反复写vr_writeData(recognizer, wavData.data, wavData.size);//通知识别器停止,并等待识别器真正退出do {vr_stopRecognize(recognizer);printf("recognizer is quiting\n");
#ifdef WIN32Sleep(1000);
#elsesleep(1);
#endif} while (!vr_isRecognizerStopped(recognizer));//销毁识别器vr_destroyVoiceRecognizer(recognizer);printf("press enter key to exit.......\n");char c;scanf("%c", &c);
}
使用 c 声波通讯接口从实时录音数据中解码的例子:
/************************************************************************
声波通讯库示例,从实时录音数据获取音频信号进行解码,该工程示例是可跨平台的
声波通讯库特征:
准确性98%以上,其实一般是不会出错的。
接口非常简单,有完整的示例,3分钟就可以让你的应用增加声波通讯功能
抗干扰性强,基本上无论外界怎么干扰,信号都是准确的
基本的编码为16进制,而通过编码可传输任何字符
性能非常强,没有运行不了的平台,而且通过内存池优化,长时间解码不再分配新内存,可7*24小时运行
可支持任何平台,常见的平台android, iphone, windows, linux, arm, mipsel都有示例
详情可查看:[softlgh-CSDN博客](http://blog.csdn.net/softlgh)
作者: 夜行侠 QQ:3116009971 邮件:3116009971@qq.com
************************************************************************/
//识别到有信号时开始解码回调函数
void recorderRecognizerStart()
{printf("------------------recognize start\n");
}
//当次解码结束的回调函数
void recorderRecognizerEnd(int _recogStatus, char *_data, int _dataLen)
{if (_recogStatus == VR_SUCCESS){char buf[51];memcpy(buf, _data, _dataLen);buf[_dataLen] = 0;printf("------------------recognized data:%s\n", buf);}else{printf("------------------recognize invalid data, errorCode:%d\n", _recogStatus);}
}
#ifdef WIN32
void runRecorderVoiceRecognize( void * _recognizer)
#else
void *runRecorderVoiceRecognize( void * _recognizer)
#endif
{vr_runRecognizer(_recognizer);
}
int recorderShortWrite(void *_writer, const void *_data, unsigned long _sampleCout)
{char *data = (char *)_data;void *recognizer = _writer;return vr_writeData(recognizer, data, (int)_sampleCout);
}
void test_recorderVoiceRecog()
{//创建识别器,并设置监听器void *recognizer = vr_createVoiceRecognizer();vr_setRecognizerListener(recognizer, recorderRecognizerStart, recorderRecognizerEnd);//创建录音机void *recorder = NULL;int r = initRecorder(44100, 1, 16, 512, &recorder);//要求录取short数据if(r != 0){printf("recorder init error:%d", r);return;}//开始录音//r = startRecord(recorder, recognizer, recorderFloatWrite);//float数据r = startRecord(recorder, recognizer, recorderShortWrite);//short数据if(r != 0){printf("recorder record error:%d", r);return;}//开始识别
#ifdef WIN32//CreateThread( NULL, 0, runRecorderVoiceRecognize, recognizer, 0, 0 );_beginthread(runRecorderVoiceRecognize, 0, recognizer);
#elsepthread_t ntid;pthread_create(&ntid, NULL, runRecorderVoiceRecognize, recognizer);
#endifprintf("\n\n\nrecognize start, waiting for signals ............\n");char c = 0;do {printf("press q to end recognize\n");scanf_s("%c", &c);} while (c != 'q');//停止录音r = stopRecord(recorder);if(r != 0){printf("recorder stop record error:%d", r);}r = releaseRecorder(recorder);if(r != 0){printf("recorder release error:%d", r);}//通知识别器停止,并等待识别器真正退出do {vr_stopRecognize(recognizer);printf("recognizer is quiting\n");
#ifdef WIN32Sleep(1000);
#elsesleep(1);
#endif} while (!vr_isRecognizerStopped(recognizer));//销毁识别器vr_destroyVoiceRecognizer(recognizer);
}
相应的录音机抽象接口:
/************************************************************************
声波通讯库示例,录音机抽象接口,该工程示例是可跨平台的
声波通讯库特征:
准确性98%以上,其实一般是不会出错的。
接口非常简单,有完整的示例,3分钟就可以让你的应用增加声波通讯功能
抗干扰性强,基本上无论外界怎么干扰,信号都是准确的
基本的编码为16进制,而通过编码可传输任何字符
性能非常强,没有运行不了的平台,而且通过内存池优化,长时间解码不再分配新内存,可7*24小时运行
可支持任何平台,常见的平台android, iphone, windows, linux, arm, mipsel都有示例
详情可查看:[softlgh-CSDN博客](http://blog.csdn.net/softlgh)
作者: 夜行侠 QQ:3116009971 邮件:3116009971@qq.com
************************************************************************/
//_data的数据格式是根据initRecorder传入的数据类型定的,一般可能为short。
//_sampleCout是表示_data中含有的样本数,不是指_data的长度
//返回已经处理的信号数,如果返回-1,则录音线程应退出
typedef int (*r_pwrite)(void *_writer, const void *_data, unsigned long _sampleCout);
/************************************************************************/
/* 创建录音机
/* _sampleRateInHz为44100
/* _channel为单声道,1为单声道,2为立体声
/* _audioFormat为一个信号的bit数,单声道双字节精度的话为16
/************************************************************************/
int initRecorder(int _sampleRateInHz, int _channel, int _audioFormat, int _bufferSize, void **_precorder);
/************************************************************************/
/* 开始录音
/************************************************************************/
int startRecord(void *_recorder, void *_writer, r_pwrite _pwrite);
/************************************************************************/
/* 停止录音
/************************************************************************/
int stopRecord(void *_recorder);
/************************************************************************/
/* 释放录音器的资源
/************************************************************************/
int releaseRecorder(void *_recorder);
使用 PA 实现的录音机接口,可跨平台:
/************************************************************************
声波通讯库示例,PA库实现的录音机接口,该库是跨平台的
声波通讯库特征:
准确性98%以上,其实一般是不会出错的。
接口非常简单,有完整的示例,3分钟就可以让你的应用增加声波通讯功能
抗干扰性强,基本上无论外界怎么干扰,信号都是准确的
基本的编码为16进制,而通过编码可传输任何字符
性能非常强,没有运行不了的平台,而且通过内存池优化,长时间解码不再分配新内存,可7*24小时运行
可支持任何平台,常见的平台android, iphone, windows, linux, arm, mipsel都有示例
详情可查看:[softlgh-CSDN博客](http://blog.csdn.net/softlgh)
作者: 夜行侠 QQ:3116009971 邮件:3116009971@qq.com
************************************************************************/
#include "record.h"
#include <stdio.h>
#include <stdlib.h>
//#include <syslib.h>
#include "portaudio.h"
#pragma comment(lib, "portaudio_x86.lib")
#define SAMPLE_RATE (44100)
#define FRAMES_PER_BUFFER (512)
#define NUM_SECONDS (5)
#define NUM_CHANNELS (2)
#define DITHER_FLAG (0) /**/
#define WRITE_TO_FILE (0)
/* Select sample format. */
#if 1
#define PA_SAMPLE_TYPE paFloat32
typedef float SAMPLE;
#define SAMPLE_SILENCE (0.0f)
#define PRINTF_S_FORMAT "%.8f"
#elif 1
#define PA_SAMPLE_TYPE paInt16
typedef short SAMPLE;
#define SAMPLE_SILENCE (0)
#define PRINTF_S_FORMAT "%d"
#elif 0
#define PA_SAMPLE_TYPE paInt8
typedef char SAMPLE;
#define SAMPLE_SILENCE (0)
#define PRINTF_S_FORMAT "%d"
#else
#define PA_SAMPLE_TYPE paUInt8
typedef unsigned char SAMPLE;
#define SAMPLE_SILENCE (128)
#define PRINTF_S_FORMAT "%d"
#endif
struct PARecorder
{PaStream* stream;PaStreamParameters inputParameters,outputParameters;int sampleRateInHz, channel, audioFormat, bufferSize;void *writer;r_pwrite write;
};
/* This routine will be called by the PortAudio engine when audio is needed.
** It may be called at interrupt level on some machines so don't do anything
** that could mess up the system like calling malloc() or free().
*/
static int recordCallback( const void *inputBuffer, void *outputBuffer,unsigned long framesPerBuffer,const PaStreamCallbackTimeInfo* timeInfo,PaStreamCallbackFlags statusFlags,void *userData )
{//void *recognizer = userData;PARecorder *recorder = (PARecorder *)userData;int r = recorder->write(recorder->writer, inputBuffer, framesPerBuffer);if (r >= 0){return paContinue;}else{return paComplete;}
}
int initRecorder(int _sampleRateInHz, int _channel, int _audioFormat, int _bufferSize, void **_precorder)
{PaError err = Pa_Initialize();if( err != paNoError ) {Pa_Terminate();}PARecorder *recorder = new PARecorder();recorder->stream = NULL;recorder->sampleRateInHz = _sampleRateInHz;recorder->channel = _channel;recorder->audioFormat = _audioFormat;recorder->bufferSize = _bufferSize;recorder->writer = NULL;*_precorder = recorder;return err;
}
int startRecord(void *_recorder, void *_writer, r_pwrite _pwrite)
{PARecorder* recorder = (PARecorder*)_recorder;recorder->write = _pwrite;recorder->writer = _writer;PaStreamParameters *inputParameters = &recorder->inputParameters;inputParameters->device = Pa_GetDefaultInputDevice(); /* default input device */if (inputParameters->device == paNoDevice) {fprintf(stderr,"Error: No default input device.\n");Pa_Terminate();return -1;//这个编号要与PA的其它编号不重复}inputParameters->channelCount = recorder->channel;if(recorder->audioFormat == 0)inputParameters->sampleFormat = paFloat32;else inputParameters->sampleFormat = paInt16;//inputParameters->sampleFormat = PA_SAMPLE_TYPE;inputParameters->suggestedLatency = Pa_GetDeviceInfo( inputParameters->device )->defaultLowInputLatency;inputParameters->hostApiSpecificStreamInfo = NULL;/* Record some audio. -------------------------------------------- */PaError err = Pa_OpenStream(&recorder->stream,&recorder->inputParameters,NULL, /* &outputParameters, */recorder->sampleRateInHz,recorder->bufferSize,paClipOff, /* we won't output out of range samples so don't bother clipping them */recordCallback,recorder );if (err == paNoError){err = Pa_StartStream( recorder->stream );}if( err != paNoError ) {delete recorder;}return err;
}
int stopRecord(void *_recorder)
{PaError err = paNoError;if(_recorder != NULL){PARecorder *recorder = (PARecorder *)_recorder;PaError err = Pa_CloseStream( recorder->stream );}return err;
}
int releaseRecorder(void *_recorder)
{PaError err = paNoError;err = Pa_Terminate();if(_recorder != NULL){PARecorder *recorder = (PARecorder *)_recorder;delete recorder;}return err;
}
所有代码都在附件中。
附件说明:
各平台相应的文件在相应平台的文件夹下,有些平台文件夹下只有编码端或者解码端,或者是因为不需要,或者是我自己现在没用到,也懒得去编译了,你自己如果真正需要相应的正式版,再找我吧。各平台的库是 demo 版,c 语言版是限制了解码次数,android 的 java 版是没有去除噪音功能,你自己如果真正需要相应的正式版,再找我吧。各个平台的编码端都没有任何限制。
本文件夹下包含:
-
VoiceRecogFromRecorder.exe:从 windows 录音设备读取音频数据解码信号的示例程序,其代码在 windows 文件夹下。该示例工程是可跨平台编译的,链接时去链接相应平台的 .so 文件就可以了。使用时确保 windows 录音正常,然后从 android 手机播放信号后 windows 上就能识别到了。
-
VoiceRecogFromWav.exe:从本目录下的 data.wav 文件读取音频数据解码信号的示例,代码在 windows 文件夹下。该示例工程是可跨平台编译的,链接时去链接相应平台的 .so 文件就可以了。
-
声波通讯测试.apk:android 平台上同时进行音频编码和解码的示例,其代码在 android 文件夹下
-
voiceDemoWithNoise.jar:android 平台上同时进行音频编码和解码库,此库为没有处理噪音的开发版,不是正式版
各平台文件夹:
-
android:示例 apk,java 版的编码和解码库,相应的解码、解码使用示例代码,但解码库没有降噪处理,错误率比正式版高。
-
iphone:现在我只用到了编码端和使用示例代码,解码端没有编译。
-
windows:现在我只用到了解码端,所以只有解码库,限制了使用次数。windows 平台文件夹下有使用声波通讯库的完整示例代码,这些示例代码实际上是跨平台的,可在任何支持 c 的平台上编译运行,包括 linux,arm,mipsel 等平台,arm 平台,linux 平台,mipsel 平台上使用解码库与 windows 相同,链接时去链接相应平台的 .so 文件就可以了。示例中包括从 wav 文件读取音频数据,或者从录音机读取音频数据。
-
arm:现在我只用到了解码端,所以只有解码库,限制了使用次数。解码使用示例代码见 windows 文件夹下
-
linux:现在我只用到了解码端,所以只有解码库,限制了使用次数。解码使用示例代码见 windows 文件夹下
-
mipsel:现在我只用到了解码端,所以只有解码库,限制了使用次数。解码使用示例代码见 windows 文件夹下
android/iphone/windows/linux/微信 声波通信库及源码:
百度盘下载:https://pan.baidu.com/s/1co0TaQ5KAFFc-MBdrIA6MA
直接下载: https://www.51tage.com/voiceRecogDemo.zip
效果超牛的基于声波通信和声音指纹的微信互动平台
softlgh 已于 2025-03-13 22:18:34 修改
一、背景及流程
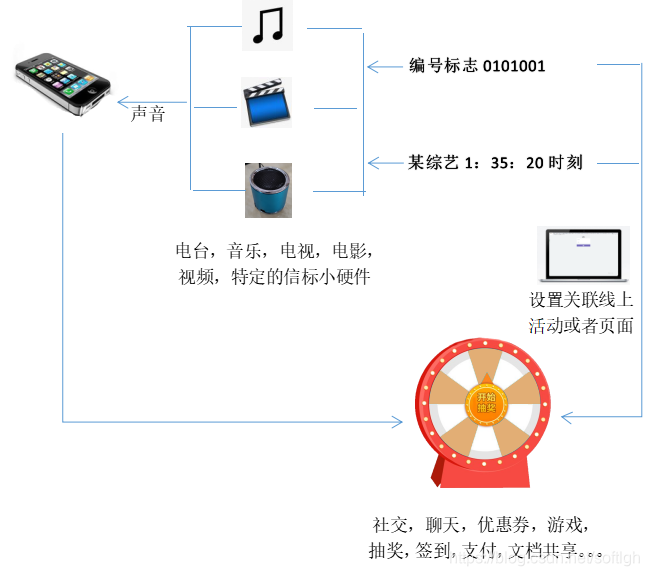
声音作为一种无处不在的信息传播媒介,在现代生活中扮演着重要角色。无论是电视、电脑、手机、平板、收音机,还是各种大屏小屏设备,都广泛应用于办公室、会议室、展会、电影院、旅游景点、演讲和表演等场所。这些场景中不仅存在各种声音播放设备,还可以布设声音信标小硬件,或者利用其独特的声音(从哲学上来说,世界上没有两个完全相同的声音)。智能手机能够识别这些声音中的信号,或者利用声音本身的唯一性来辨别用户所处的线下场景,并通过手机延伸到线上的互动或页面。
互动流程
- 各种音视频(电台、音乐、电视、电影、长视频、短视频等)播放出来的声音都可以作为传输信号的载体(声波通信方法),也可以作为声音指纹的载体(声音指纹方法)。
- 还可以布设声波信标小硬件来传输声音信号,布设的声波信标硬件比正常音视频播放时传输距离更远,且无杂音。
- 在后台,将声波编号标志或者声音文件 + 时刻关联到某一个活动或者线上页面。
- 手机识别到特定声音编号标志,或者特定声音指纹 + 时刻信息时,跳转到指定的线上活动或者页面。
- 声波关联的线上活动可以是各种社交、聊天、论坛、优惠券、游戏、抽奖、签到、支付、文档共享等。
二、过程原理
1. 声波通信
手机通过提取声音中的特定编号,实现跳转到与该编号关联的线上页面。这依赖于声波通信技术。其前提是音频的播放是可以编程控制的,即在播放时主动加工音频,嵌入超声编号信号。人类的听力范围为 0-20 kHz,但正常主要听力范围在 0-4 kHz 左右,绝大多数人对 16 kHz 以上的频段不敏感。因此,超声频率范围一般在 18.5-20 kHz 之间,人们实际听不到这些超声信号,但手机可以完全识别。
2. 声音指纹
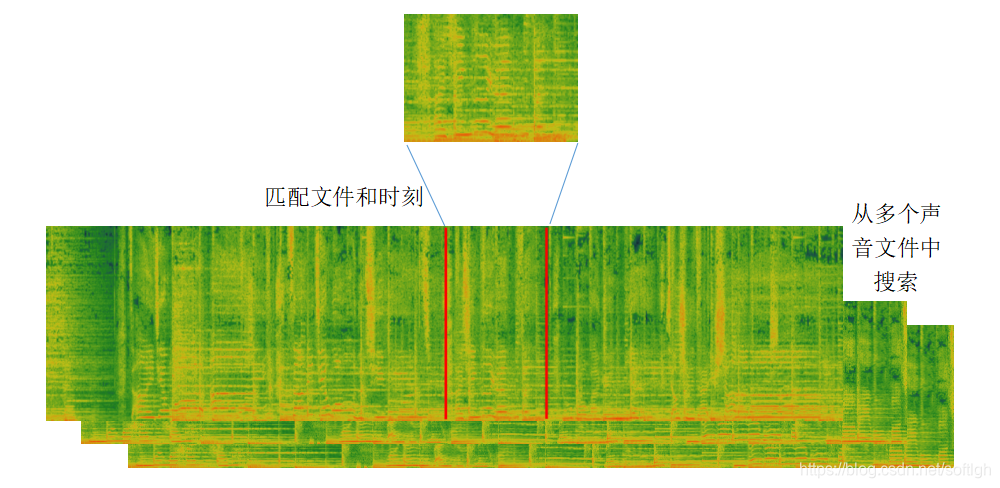
通过识别某个特定的声音(和该声音所在的时刻),跳转到与该音频(和时刻)绑定的页面,这是通过声音指纹技术实现的。例如,通过识别电台声音,跳转到该电台的互动页面。与声波通信技术不同,声音指纹技术不需要对播放的音频进行加工(或者无法加工,如电台声音)。只需在用户识别的同时,将该路声音传送到后台进行特征抽取即可。
声音指纹技术的具体实现是:在用户处录取 6-9 秒的声音片段,在后台与目标声音进行匹配,从成千上万个声音文件中得到匹配声音文件和匹配时间,从而得到与此文件和匹配时刻相关联的线上活动或者页面,进而控制客户端进入相应的页面。
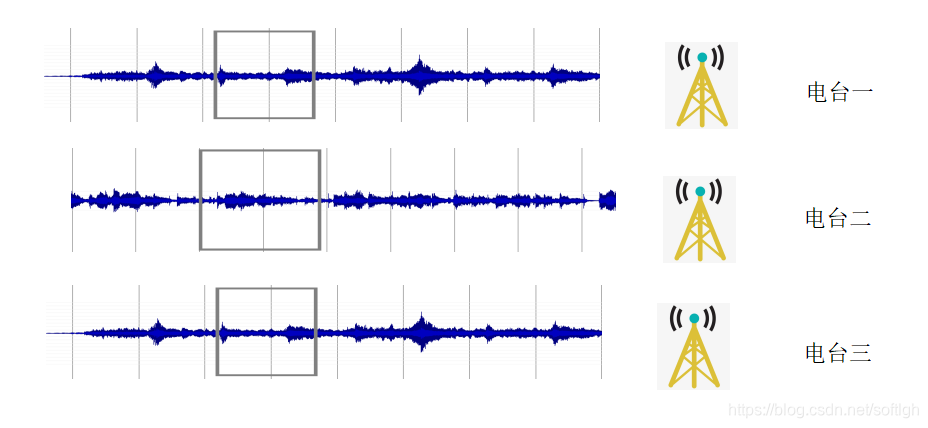
对于电台的互动,与音乐不同,一般是实时的,不需要识别特定时刻。因此可以在内存中使用流式识别。不需要识别时刻的实时互动,每路电台保留一个滑动的内存窗口用于识别即可。识别到某路电台后直接跳转到该电台的互动页面。
3. 相互优势
声波通信和声音指纹都是以声音为媒介实现线下线上互动的方法,但各有特点,某些方面是互补的。
-
声波通信:
- 识别速度快,一般为 1-2 秒。
- 识别距离远,测试表明布设的小设备可以达到 50-100 米的距离,家庭电视音量中的信号也可以轻松达到 20 米以上。
- 通信数据准确,因为数据传输时有纠错和校验,所以信号一旦接收到就一定是准确的。
- 但声波通信方式需要对播放的信号进行预加工,把超声信号嵌入到播放的音视频中去;或者是可以另外播放一路超声信号;或者是能布设特定的声音信标小硬件。
-
声音指纹:
- 识别速度较慢,一般需录取 6 秒左右的声音来识别,如果没有录到有效声音,客户端会自动延长到 9 秒。
- 有一定的误识别率,因为某一段时间的声音可能与当前声音相似度很高,从而被系统误判断。但可以通过在客户端把疑似入口列出来让用户选择来优化。
- 突出优点是无需对播放音视频预先做任何加工处理,也不需要布设任何声音信标硬件。例如在某些电视电台的互动中无法去嵌入信号。
4. 相比二维码
当前其他完成线下到线上互动的技术主要是二维码。与二维码相比,声音具有以下独特优势:
- 操作简单:声音识别操作更简单,识别速度快,不需要用户手机对准一个地方,声波识别速度为 1-2 秒。
- 无需占用屏幕或物理位置:二维码需要占用屏幕或者一个物理位置,在场地很大、距离很远(如超过 10 米)、人很多时,或者互动时间长时,二维码很不方便。而声音可以全程互动。
- 适用范围广:在某些场景下,二维码无法使用,如收听电台时用户的互动,因为没有屏幕也没有物理的码,二维码完全无法应用,而声音可以正常使用。
三、软件、硬件及效果
1. 微信识别
识别客户端主要在手机上执行,因此一般支持 Android 和 iOS 平台。在国内,微信是基础软件,微信小程序使得用户不需要下载安装软件的繁琐过程。在小程序内,不管是声波通信还是声音指纹,都可以快速正常识别。
微信小程序的识别客户端如下:img
测试方法:在播放 测试信号视频 时,使用微信小程序客户端接收信号。识别到信号后,客户端即跳转到预先设置好的活动页面。
-
电脑播放可以点此链接 测试信号视频点这里
-
手机播放可以扫描这个 img
2. 软件界面
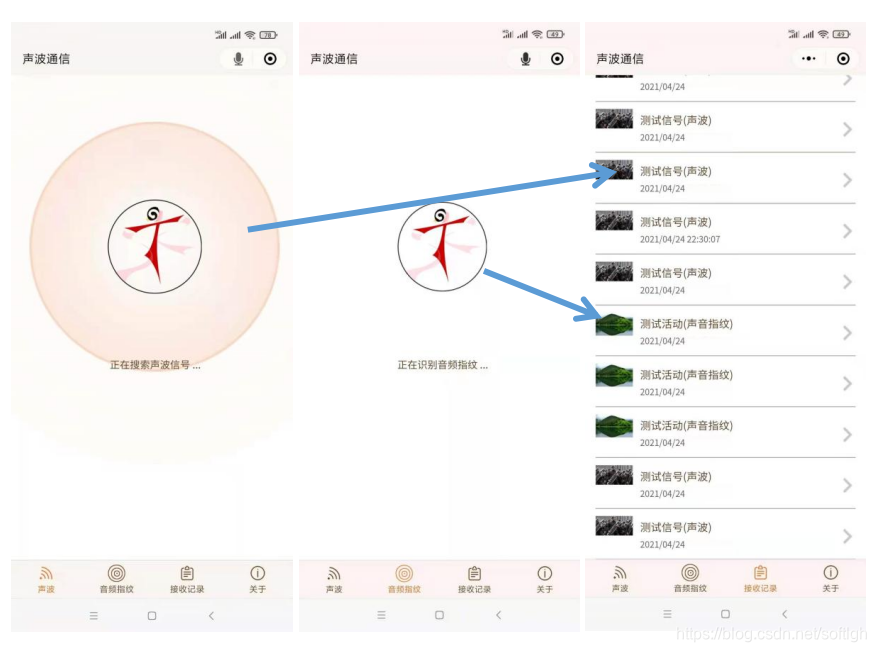
微信小程序通过识别声波信号,或者识别声音指纹来实现线下到线上的连通。
3. 硬件载体
例如,可以改造一个小音箱:

4. 声波现场互动的效果
- 15% 的音量:
- 开阔地带:40 米稳定接收,到 50 米断断续续。
- 室内:两个房间拐弯后,大概 15 米(没有更大的房间了,应该还可以更远)。更有趣的是,15 米外的玻璃门,关死的话,识别不到信号了,开出 2 厘米的空隙,则在玻璃门外接收信号正常。
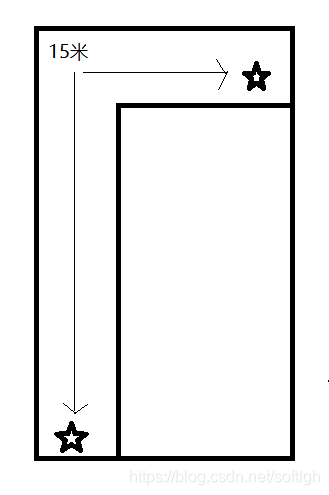
15 米外的玻璃门 2 cm 间隙泄露出信号:

- 100% 音量:
- 开阔地带:70 米正常接收,到 100 米左右断断续续识别。
android/iphone/windows/linux/ 微信声波通信库及示例源码:
- 百度盘下载:https://pan.baidu.com/s/1co0TaQ5KAFFc-MBdrIA6MA
- 直接下载:https://www.51tage.com/voiceRecogDemo.zip
android/iphone/windows/linux/ 微信声波通讯库
softlgh 已于 2025-03-13 22:20:35 修改
一、声波通讯库特征
- 可传输数字、字母、汉字等任意字符。
- 支持双向传输。
- 支持设置声音传输频段。
- 支持设置声音采样率。
- 准确性 95% 以上,一般不会出错。
- 接口非常简单,有完整的示例,3 分钟即可让应用增加声波通讯功能。
- 抗干扰性强,无论外界如何干扰,信号都是准确的。
- 基本编码为 16 进制,通过编码可传输任何字符。
- 性能强大,无运行不了的平台,且通过内存池优化,长时间解码不再分配新内存,可 7×24 小时运行。
- 可支持任何平台,常见的平台 Android、iPhone、Windows、Linux、arm、mipsel 都有示例。
- 库大小(Android 版):jar + so 一起大概 90k 左右。.a 链接的话,加入声波通讯后可能使原可执行文件增加 40k-60k。
二、Android 工程示例

Android 工程项目使用步骤
-
添加录音权限:
<uses-permission android:name="android.permission.RECORD_AUDIO" /> -
加入库到工程中:
- 将
armeabi\libvoiceRecog.so和voiceRecog.jar加入到库路径下(一般为 libs 目录)。
- 将
-
导入 so 库:
static {System.loadLibrary("voiceRecog"); }
三、iOS 版工程示例

在下载的工程源码中,在工程目录下有 libcvoiceRecognize.a 是真机版的库,libcvoiceRecognize_simulator.a 是模拟器版的库,自己在 Xcode 环境中根据需要链接不同的库即可。
四、Windows 工程示例
可传输任意数据内容,包括数字、字母、各种语言字符:

支持双向传输:
双向传递时一般设置为“不接收自己发送的信号”模式。

各平台的 demo 工程需注意
- Windows 音频支持:
- 有麦克风,音量,是否静音,不要打开“增强音效”功能。

五、Linux 工程示例
Linux 下识别数字、字母、SSID 和密码组成的 WiFi 信息:

编程接口
发送端接口
/************************************************************************
android/iphone/windows/linux 声波通讯库
声波通讯库特征:
准确性 95% 以上,其实一般是不会出错的。
接口非常简单,有完整的示例,3 分钟就可以让你的应用增加声波通讯功能
抗干扰性强,基本上无论外界怎么干扰,信号都是准确的
基本的编码为 16 进制,而通过编码可传输任何字符
性能非常强,没有运行不了的平台,而且通过内存池优化,长时间解码不再分配新内存,可 7*24 小时运行
可支持任何平台,常见的平台 android, iphone, windows, linux, arm, mipsel 都有示例
详情可查看:http://blog.csdn.net/softlgh
作者:夜行侠 QQ:3116009971 邮件:3116009971@qq.com
************************************************************************/
#ifdef VOICE_RECOG_DLL
#define VOICERECOGNIZEDLL_API __declspec (dllexport)
#else
#define VOICERECOGNIZEDLL_API
#endif
#ifndef VOICE_PLAY_H
#define VOICE_PLAY_H
#ifdef __cplusplus
extern "C" {
#endif
typedef void (*vp_pPlayerStartListener)(void *_listener);
typedef void (*vp_pPlayerEndListener)(void *_listener);
/************************************************************************/
/* 创建编码端发送对象
/************************************************************************/
VOICERECOGNIZEDLL_API void * vp_createVoicePlayer ();
/************************************************************************/
/* 发送端编码并发送数据
/* 该函数以异步的形式工作,不阻塞主线程,判断是否发送完成由下面的 vp_isStopped
/* _data 为任意数据,以十六进制的形式发送
/* _dataLen 为需发送的数据内容长度
/************************************************************************/
VOICERECOGNIZEDLL_API void vp_play (void *_player, char *_data, int _dataLen, int _playCount, int _muteInterval);
// 设置播放监听器
VOICERECOGNIZEDLL_API void vp_setPlayerListener (void *_player, void *_listener, vp_pPlayerStartListener _startListener, vp_pPlayerEndListener _endListener);
/************************************************************************/
/* 设置声波发送端音量
/* _volume 为 0-1 之间的浮点数,0 为无声,1 为最大
/************************************************************************/
VOICERECOGNIZEDLL_API void vp_setVolume (void *_player, double _volume);
/************************************************************************/
/* 设置声波发送端频段
/************************************************************************/
VOICERECOGNIZEDLL_API void vp_setFreqs (void *_player, int *_freqs, int _freqCount);
/************************************************************************/
/* play 函数以异步的方式播放并发送,在销毁对象之前需确保播放已经完成
/************************************************************************/
VOICERECOGNIZEDLL_API int vp_isStopped (void *_player);
/************************************************************************/
/* 销毁声波发送端对象
/************************************************************************/
VOICERECOGNIZEDLL_API void vp_destoryVoicePlayer (void *_player);
// 应用层发送方接口
// 返回 4bit 个数
int vp_encodeData (char *_data, int _dataLen, char *_result);
VOICERECOGNIZEDLL_API void vp_playString (void *_player, char *_str, int _playCount, int _muteInterval);
/************************************************************************/
/* 发送端编码并发送 wifi 信息,以 mac,pwd 的形式
/************************************************************************/
VOICERECOGNIZEDLL_API void vp_playWiFi (void *_player, char *_mac, int _macLen, char *_pwd, int _pwdLen, int _playCount, int _muteInterval);
/************************************************************************/
/* 发送端编码并发送 wifi 信息,以 ssid,pwd 的形式
/************************************************************************/
VOICERECOGNIZEDLL_API void vp_playSSIDWiFi (void *_player, char *_ssid, int _ssidLen, char *_pwd, int _pwdLen, int _playCount, int _muteInterval);
/************************************************************************/
/* 发送端编码并发送手机标志信息,(imei, 手机名字)
/************************************************************************/
VOICERECOGNIZEDLL_API void vp_playPhone (void *_player, char *_imei, int _imeiLen, char *_phoneName, int _nameLen, int _playCount, int _muteInterval);
#ifdef __cplusplus
}
#endif
#endif
接收端接口
/************************************************************************
android/iphone/windows/linux 声波通讯库
声波通讯库特征:
准确性 95% 以上,其实一般是不会出错的。
接口非常简单,有完整的示例,3 分钟就可以让你的应用增加声波通讯功能
抗干扰性强,基本上无论外界怎么干扰,信号都是准确的
基本的编码为 16 进制,而通过编码可传输任何字符
性能非常强,没有运行不了的平台,而且通过内存池优化,长时间解码不再分配新内存,可 7*24 小时运行
可支持任何平台,常见的平台 android, iphone, windows, linux, arm, mipsel 都有示例
详情可查看:http://blog.csdn.net/softlgh
作者:夜行侠 QQ:3116009971 邮件:3116009971@qq.com************************************************************************/#ifdef VOICE_RECOG_DLL
#define VOICERECOGNIZEDLL_API __declspec (dllexport)
//#else
//#ifdef WIN32
//#define VOICERECOGNIZEDLL_API __declspec (dllimport)
#else
#define VOICERECOGNIZEDLL_API
//#endif
#endif
#ifndef VOICE_RECOG_H
#define VOICE_RECOG_H
#ifdef __cplusplus
extern "C" {
#endif
enum VRErrorCode
{
VR_SUCCESS = 0, VR_NoSignal = -1, VR_ECCError = -2, VR_NotEnoughSignal = 100
, VR_NotHeaderOrTail = 101, VR_RecogCountZero = 102
};
enum DecoderPriority
{
CPUUsePriority = 1// 不占内存,但 CPU 消耗比较大一些
, MemoryUsePriority = 2// 不占 CPU,但内存消耗大一些
};
typedef enum {vr_false = 0, vr_true = 1} vr_bool;
typedef void (*vr_pRecognizerStartListener)(void *_listener, float _soundTime);
//_result 如果为 VR_SUCCESS,则表示识别成功,否则为错误码,成功的话_data 才有数据
typedef void (*vr_pRecognizerEndListener)(void *_listener, float _soundTime, int _result, char *_data, int _dataLen);
// 创建声波识别器
VOICERECOGNIZEDLL_API void *vr_createVoiceRecognizer (enum DecoderPriority _decoderPriority);
VOICERECOGNIZEDLL_API void *vr_createVoiceRecognizer2 (enum DecoderPriority _decoderPriority, int _sampleRate);
// 销毁识别器
VOICERECOGNIZEDLL_API void vr_destroyVoiceRecognizer (void *_recognizer);
// 设置解码频率
// 总共需 16+3 个频率,依次为 1 个开始字符, 0-f 的 16 进制字符,1 个重复标志字符,1 个结束字符
//_freqs 数组是静态的,整个解码过程中不能释放
VOICERECOGNIZEDLL_API void vr_setRecognizeFreqs (void *_recognizer, int *_freqs, int _freqCount);
// 设置识别到信号的监听器
VOICERECOGNIZEDLL_API void vr_setRecognizerListener (void *_recognizer, void *_listener, vr_pRecognizerStartListener _startListener, vr_pRecognizerEndListener _endListener);
// 开始识别
// 这里一般是线程,这个函数在停止识别之前不会返回
VOICERECOGNIZEDLL_API void vr_runRecognizer (void *_recognizer);
// 暂停信号分析
VOICERECOGNIZEDLL_API void vr_pauseRecognize (void *_recognizer, int _microSeconds);
// 停止识别,该函数调用后 vr_runRecognizer 会返回
// 该函数只是向识别线程发出退出信号,判断识别器是否真正已经退出要使用以下的 vr_isRecognizerStopped 函数
VOICERECOGNIZEDLL_API void vr_stopRecognize (void *_recognizer);
// 判断识别器线程是否已经退出
VOICERECOGNIZEDLL_API vr_bool vr_isRecognizerStopped (void *_recognizer);
// 要求输入数据要求为 44100,单声道,16bits 采样精度,小端编码的音频数据
// 小端编码不用特别处理,一般你录到的数据都是小端编码的
VOICERECOGNIZEDLL_API int vr_writeData (void *_recognizer, char *_data, int _dataLen);
// 应用层解码接口
int vr_decodeData (char *_hexs, int _hexsLen, int *_hexsCostLen, char *_result, int _resultLen);
VOICERECOGNIZEDLL_API vr_bool vr_decodeString (int _recogStatus, char *_data, int _dataLen, char *_result, int _resultLen);
// 传输层中数据类型标志
enum InfoType
{
IT_WIFI = 0// 说明传输的数据为 WiFi
, IT_SSID_WIFI = 1//ssid 编码的 WIFI
, IT_PHONE = 2// 说明传输的数据为手机注册信息
, IT_STRING = 3// 任意字符串
};
VOICERECOGNIZEDLL_API enum InfoType vr_decodeInfoType (char *_data, int _dataLen);
//wifi 解码
struct WiFiInfo
{
char mac [8];
int macLen;
char pwd [80];
int pwdLen;
};
VOICERECOGNIZEDLL_API vr_bool vr_decodeWiFi (int _result, char *_data, int _dataLen, struct WiFiInfo *_wifi);
struct SSIDWiFiInfo
{
char ssid [32];
int ssidLen;
char pwd [80];
int pwdLen;
};
VOICERECOGNIZEDLL_API vr_bool vr_decodeSSIDWiFi (int _result, char *_data, int _dataLen, struct SSIDWiFiInfo *_wifi);
struct PhoneInfo
{
char imei [18];
int imeiLen;
char phoneName [20];
int nameLen;
};
VOICERECOGNIZEDLL_API vr_bool vr_decodePhone (int _result, char *_data, int _dataLen, struct PhoneInfo *_phone);
#ifdef __cplusplus
}
#endif
#endif
android/iphone/windows/linux/ 微信声波通信库及源码:
- 百度盘下载:https://pan.baidu.com/s/1co0TaQ5KAFFc-MBdrIA6MA
- 直接下载:https://www.51tage.com/voiceRecogDemo.zip
Android/iphone/ 微信 手机通过声波初始化智能设备的 WIFI 信息
softlgh 已于 2025-03-13 22:20:02 修改
一、背景
2014 年随着智能硬件的兴起,很多智能硬件通过 Android/iPhone 手机进行控制。但设备在初始化时需先连接上 WiFi,并由手机进行识别后才能在手机和设备之间进行对话。然而,这些智能硬件很多没有屏幕、键盘或其他输入设备,无法输入 WiFi 初始化信息,而其他流程又很繁琐。在 iPhone 中,由于 Apple 对手机 WiFi 操作的严格控制,这一过程更加复杂。因此,通过手机声波将 WiFi 的初始化连接信息传递给设备,从而实现设备识别并建立手机与设备之间的网络连接,是最简化的设备识别和 WiFi 初始化流程。
二、流程

使用声波传输 WiFi 信息给智能设备,使得用户对设备的初始化流程非常简单:

Android 传输和接收 WiFi 信息的例子
该程序列出当前环境下的 WiFi,并在点击任一 WiFi 时传输该条 WiFi 信息出去:

Linux 下接收由 SSID 和密码组成的 WiFi 信息

android/iphone/windows/linux/ 微信声波通信库及源码:
- 百度盘下载:https://pan.baidu.com/s/1co0TaQ5KAFFc-MBdrIA6MA
- 直接下载:https://www.51tage.com/voiceRecogDemo.zip
一种短距离声波通信的方案
cfw 在路上 于 2024-09-30 11:47:50 发布
短距离通信方法众多,包括 NFC、二维码、蓝牙等,它们各有特点与限制。例如,NFC 和蓝牙需要硬件支持,二维码虽解决了诸多问题,但需图像采集单元。声波通信则通过发送端播放含信息的音频,接收端采集音频分析数据,其限制在于通信双方需具备音频输入输出单元。目前声波通信方案众多,如支付宝的“咻咻咻”,不同方案在采样率、性能消耗和自动增益单元等方面存在差异。
因项目需求,需在 ARM 32bit 500M 单核 CPU 的嵌入式设备上实现声波通信接收端,要求 CPU 使用率低,音频输入设备为固定增益。产品需求为一次传输约 64 字节数据,3~4 秒内完成,且成功率高。
实际设计分为物理层和链路层,具体如下:
一、声波物理层
1. 音频信道采样率
音频处理采用 FFT 实现,为降低 CPU 使用率,本方案选用 16 kHz 采样率、16 bit 的音频。
2. 比特数据的调制
传输 1 bit 数据时,发送端发送两个相邻频率中的一个,分别代表 0 和 1,如图 1 所示。

图 1
图中黑色粗线表示发送端信号中存在频率 f 1 f_1 f1 或 f 2 f_2 f2,对应下方值为 0 和 1。图中后两种情况在发送端不会出现。
另一种方法是发送端通过一段时间内频率 f f f 的有无来代表 1 和 0,如图 2 所示。

图 2
该方法优点在于仅用一个频率点,但缺点严重。开发中发现,接收端难以准确判定频率 f 1 f_1 f1 的有无。例如,用 FFT 结果中 f 1 f_1 f1 的振幅 A A A 与阈值 B B B 比较,若 B B B 太大,发送端声音小或接收端频率响应差时会误判;若 B B B 太小,易对噪声误判。理想情况是在特定设备上为每个频率点调出合适的阈值 B B B,但不具备通用性,且通信距离和音量也会影响振幅大小。
因此,图 1 的方法优势明显。接收端只需比较 f 1 f_1 f1 和 f 2 f_2 f2 的振幅大小,如 f 1 > f 2 f_1 > f_2 f1>f2,则存在频率 f 1 f_1 f1 而无 f 2 f_2 f2。一般情况下, f 1 f_1 f1 和 f 2 f_2 f2 的衰减和增大是同步的,不受硬件频率响应、传输距离和音量大小的影响,其原理类似于差分传输有效抑制共模干扰。
3. 前后帧判断
接收端通过 FFT 分析音频数据,即短时傅里叶变换,对信号加窗分别计算 FFT 结果,从而得知声波在哪些时间段拥有哪些频率,如图 3 所示。

图 3
FFT 时间为 T T T,理想情况下接收端在 T T T 时间内正好采到图 1 中黑色粗线,但实际不可能。因此,发送端数据帧长为 3 T T T,接收端 FFT 计算帧长为 T T T,这样无论接收端窗口与数据帧如何偏移,总会有一个完整的数据帧落在 FFT 窗口内,如图 4 所示。

图 4
图 4 中,FFT3 的数据可能计算出有频率 f 1 f_1 f1(即 f 1 f_1 f1 振幅 > f 2 f_2 f2 振幅)或无频率 f 1 f_1 f1(即 f 1 f_1 f1 振幅 < f 2 f_2 f2 振幅)。若多个 FFT 数据中 f 1 f_1 f1 连续出现 2~4 次,则认为发送了一帧数据。同理,若 FFT 计算结果为 5~7 个,则真实数据为 2 帧且两帧数据相同。
4. 数据帧长度
数据帧长度是 FFT 计算窗的 3 倍,不仅影响传输时间,还影响 FFT 结果中的频率分辨率(根据海森堡测不准原理,FFT 窗口小则频率分辨率低,窗口大则频率分辨率高)。数据帧长度除以 3 的采样点个数需为 2 的整次幂。一帧传输的不是 1 bit,而是多个 bit(下文将说明)。综合考虑,选取 24 ms 为一帧。16 kHz 采样下,FFT 窗口(8 ms)为 128 个采样点,对应频率的量化步进为 125 Hz,即 FFT 结果中依次为 0、125、250、375、500… 的振幅数据。
5. 多频同时传输
声波通信的基本原理和相关参数已论述,但上述方法仅适用于 1 bit 的传输。实际上,可在不同频率上同时传输多个比特,创建多个传输信道以提高传输速度。
实际录制的音频光谱图显示,1000 Hz 以下的环境噪声较大。根据采样定理,16 kHz 可采集的频率在 8 kHz 以下。因此,最终选取以下 10 个传输通道的相邻两个频率点:
通道 1:1375 Hz、1625 Hz
通道 2:2000 Hz、2250 Hz
通道 3:2625 Hz、2875 Hz
通道 4:3250 Hz、3500 Hz
通道 5:3875 Hz、4125 Hz
通道 6:4500 Hz、4750 Hz
通道 7:5125 Hz、5375 Hz
通道 8:5750 Hz、6000 Hz
通道 9:6375 Hz、6625 Hz
通道 10:7000 Hz、7250 Hz
6. 奇偶校验纠错
开发中发现,声波传输过程中,某通道内频率可能因距离或遮挡而衰减,甚至导致两个频率振幅无法判断,数据出错。因此,在 5 中所述的 10 个通道中,用一个通道传输一帧数据(24 ms)中其他 9 个通道的奇偶校验信息。物理层检验发现数据错误时(通常为 1 个比特位不对),会翻转各通道中振幅最小的比特,尝试纠错。实际环境中,频带衰减是导致数据传输错误的主要原因,因此可认为错误发生在振幅最小的比特通道。
二、声波链路层
链路层主要负责根据应用程序传输数据进行 RS 纠错编码和封包,包括包头(记录数据大小)、数据和纠错数据三部分。
1. 数据包的结构
上层每 4 字节数据为一个数据包,不足 4 字节的为一个包,如图 5 所示。

图 5
包头:用于识别数据包的开始,目前定为 0x34,最低两位记录数据大小(单位:字节)。
数据:即要传输的四个字节数据,数据流末尾不足四个字节也封为一个包。
RS 纠错位:声波应用场景多为单向传输,无法像 TCP 通过重传来解决误码问题,只能依靠包内信息还原错误数据。纠错段由数据段生成,纠错段和数据段总共可纠错 2 字节以下(含 2 字节)的错误。
2. 数据包的传输方式
发送时,链路层数据包由物理层拆分为一帧一帧的数据(一帧数据为 9 bit),接收端则解析一帧一帧数据,由链路层还原成数据包再传给上层。具体拆分方式有两种,如图 6 和图 7 所示。

图 6

图 7
图 6 和图 7 的区别在于数据的排列方式。最终选用图 7 的方式,图 6 的方式存在以下两个缺点:
缺点 1:包头数据难以确定,8 bit 的数据段可能出现与包头相同的数据,导致误判。虽然可通过给包头第 9 bit 数据置 1 来区分头数据和中间数据,但这并非主要问题。
缺点 2:实际通信中,如一中 6 所述,误码多因某通道频带衰减导致。在图 6 的方式中,若一条通道误码(假设物理层奇偶纠错未纠正),会导致当前数据包的每一字节都可能有 1 bit 错误,而 RS 纠错只能纠错 2 字节,因此在这种情况下 RS 纠错意义不大。
在图 7 的方式中,包头和数据包的其他部分不在同一通道内,易于区分,且仅为 1 字节。若某通道频率衰减导致误码,RS 纠错可正确纠正。
三、总结
上述方案是在实际开发中多次尝试后确定的较优方法,适用于嵌入式设备场景下的声波通信,对音频硬件模块要求不高,性能消耗小,已应用于当前项目产品中。
但该方案仍存在一些问题,如未解决声波在小空间反射的问题、遮挡严重或扬声器和麦克风背对时成功率低、声波音频不好听(提高采样率和各通道频率可改善,但当前项目不支持)。这些问题有待后续解决,也欢迎提出更好的方案和建议。
源码地址:声波通信源码
基于设置端的鼾声识别
softlgh 于 2025-03-13 21:16:15 发布
一、背景
全球约有三分之一的人口在睡眠中会出现打鼾现象,这一比例在中年男性中更是高达 50% 以上。很多打鼾现象不但严重影响生活质量,更可能是潜在健康问题的预警信号,如睡眠呼吸暂停综合征(SAS),这一病症在全球范围内影响着数亿人的健康。
二、鼾声识别的价值
场景与流程
医疗健康监测
鼾声识别在医疗领域主要用于睡眠呼吸暂停综合征 (OSAS) 的诊断和监测。系统通过分析鼾声特征,结合心率变异性 (HRV) 和血氧饱和度 (SpO2) 数据,可以准确识别呼吸暂停事件。为了实现精确监测,记录以下关键指标:
- 鼾声指数:每小时鼾声次数
- 持续时间:单次鼾声的持续长度
- 声强分布:鼾声强度的变化情况
- 频率特征:不同类型鼾声的频率特点
基于这些数据,系统生成专业的睡眠质量报告,为医生诊断和治疗提供客观依据。
智能家居应用
智能床垫系统通过实时监测鼾声,不仅可以根据鼾声生成用户的睡眠报告,还可以自动调整床头角度等。
智能枕头通过实时监测鼾声,内置的充气装置自动调整用户的睡眠角度,从而让用户以最舒服的角度进入睡眠,防止打鼾,给自己和伴侣一个优质的睡眠。
智能空调系统则从环境调节角度改善睡眠质量,监测鼾声自动调节温度、湿度、新风量等。
移动应用
移动 APP 可以利用用户自己的智能手机在睡眠时监测鼾声,从而以一种低成本的方式来生成自己的睡眠质量报告,了解自己的鼾声和睡眠质量情况,并在后续的流程中自动识别鼾声异常,并接入专业的医疗诊断,有需要时进入治疗流程。
鼾声的特点
鼾声声域特征
鼾声最显著的时域特征是其周期性,主要表现为:
- 与呼吸周期同步 (2-4 秒 / 周期)
- 吸气和呼气阶段能量分布不同
- 波形包络呈准周期性变化
在振幅特征方面,鼾声表现出相邻周期振幅变化平缓,单次持续时间通常在 0.5-2 秒,并且振幅呈现渐变特性。能量分布则呈现典型的三段式特征:
- 起始段:能量快速上升
- 中间段:能量相对稳定
- 结束段:能量缓慢衰减
频域特征

频域分析显示,鼾声的频率分布具有明显的集中性。基频通常在 80-120 Hz 之间,主要能量集中在 100-850 Hz 频带,高频分量最高可达 2000 Hz。
在谐波结构上,鼾声通常具有 3-5 个明显谐波,能量随频率升高逐级衰减,形成特征频谱包络。频谱能量分布也表现出规律性:低频段占 40-60%,中频段占 30-40%,高频段不超过 10%。
三、鼾声的识别方法
鼾声识别的技术实现主要包括信号预处理、特征提取和识别算法三个环节。每个环节都针对鼾声的特点进行了专门优化。
信号预处理
原始音频信号首先需要经过降噪处理,然后对降噪后的信号进行分帧:
- 帧长设置为 25 ms,保证信号的短时平稳性
- 帧移选择 10 ms,确保帧间信息的连续性
- 使用汉明窗减少频谱泄漏
特征提取
特征提取分为时域和频域两个维度。时域特征主要包括:
- 短时能量:反映信号强度变化
- 过零率:表征信号频率特性
- 自相关系数:描述信号的周期性
频域特征则着重提取:
- 梅尔频率倒谱系数 (MFCC):模拟人耳听觉特性
- 频谱质心:表征频率分布重心
- 频带能量比:刻画能量分布特征
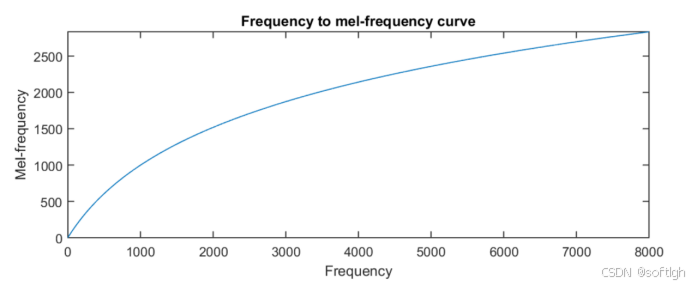
Mel 频率:
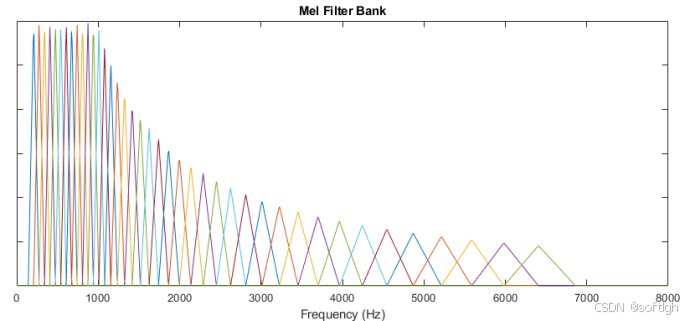
Mel 滤波器:
频谱图:
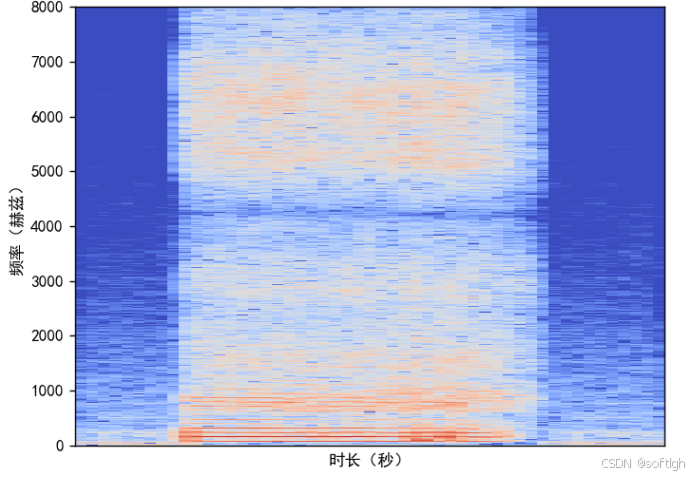
Mel 谱图:
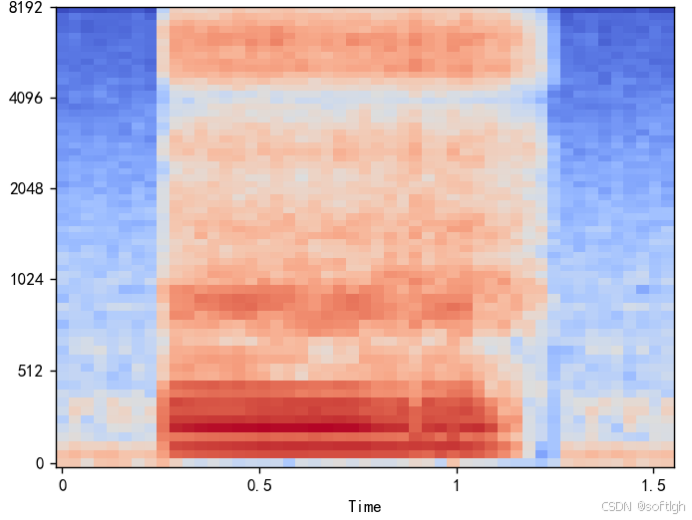
MFCC:

识别算法
采用深度学习方法构建识别模型。CNN 用于提取声音的局部特征,LSTM 处理时序依赖关系,注意力机制则帮助模型关注关键信息。
为提升模型性能,采取了以下优化措施:
- 通过数据增强提高模型泛化能力
- 引入迁移学习加速模型收敛
- 使用模型量化降低资源占用
四、鼾声的难点
鼾声识别面临三个主要挑战:
- 环境适应性:不同环境下的背景噪声、房间混响以及设备放置位置的变化都会影响识别效果。通过自适应降噪、模型适应技术来应对这些挑战。
- 个体差异:不同人的鼾声特征存在明显差异,同一个人在不同状态下的鼾声也会发生变化。
- 实时性要求:在保证准确率的同时,确保设备资源占用在合理范围内。
五、效果准确性
经过大量测试,系统达到了:
- 检测准确率超过 95%-98%
下载链接
鼾声库及 demo 源码下载:snore.zip
基于设备端的婴儿哭声识别
softlgh 已于 2024-10-1123:21:40布
一、主要特点
- 基于 C/C++ 开发,主要目标是运行在计算能力较弱的终端设备,如各类 arm v7/v8/v9 的开发板,甚至主频 100 MHz 的芯片都可以运行。
- 可运行在多个平台:Windows、Linux、macOS、Android、iOS,甚至各类 RTOS 平台上。
- 资源占用低:内存占用可低至 100k 以下,CPU 资源占用低。
- 高准确率:准确率可达 95-98%。
- 模型可自动升级。
二、婴儿哭声识别的价值
场景与流程
婴幼儿时期的哭声不仅是他们表达需求的主要方式,也是健康状况的直接反映。主要需求场景是实时哭声监测与报警/反馈机制,例如在婴儿哭闹时及时通知父母并采取实时安抚措施。调研显示,夜间或短暂离开时的哭声监测需求尤为迫切。主要产品包括智能婴儿床和婴儿监视器等。
哭声的特点
一段哭声的时域图如下:
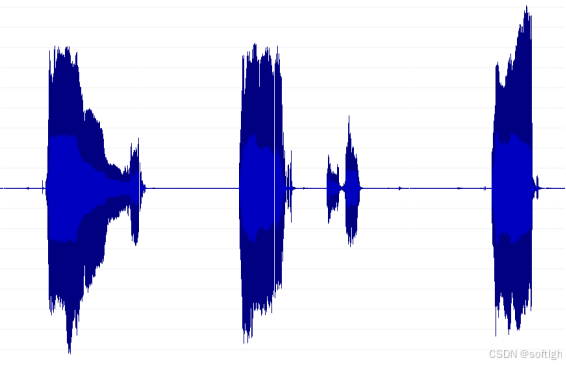
一段典型的哭声频谱如下:
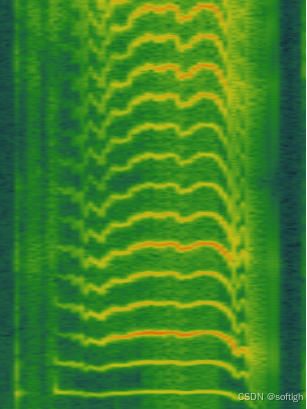
从频谱上看,哭声的特征比较明显,与正常的说话声区别较大,表现为明显的基频 - 共振峰的特征,且呈现一个起落的过程,基频大约在 300 Hz 至 500 Hz 之间,并持续相对比较长的一小段时间。
三、婴儿哭声的识别方法
婴儿哭声的识别过程主要包括:哭声音频信号的预处理、特征提取和算法识别等步骤,构建高效、准确的哭声识别模型。模型特征主要包括时域和频域特征。
音频信号预处理
音频信号预处理主要包括噪声抑制、信号增强、端点检测等步骤。考虑到实际应用场景中可能存在的复杂环境噪声,例如家庭环境中的电视声、谈话声,或是公共场所的嘈杂声,因此采用了基于自适应降噪的噪声抑制算法。该算法能有效抑制噪声,提高信噪比。实验数据显示,在典型家庭环境噪声下,该算法能将信噪比提升约 5-10 dB,显著改善了哭声识别的准确性。
此外,数据预处理还包括使用数据增强技术,如音频变速、加噪等,增加模型的泛化能力。
特征提取
从哭声的时域来看,特征相对不明显。主要从频域提取数据特征,频谱图反映了哭声在不同频率上的能量分布情况。通过对哭声进行傅里叶变换,从时域转换到频域,进而提取出频谱特征。
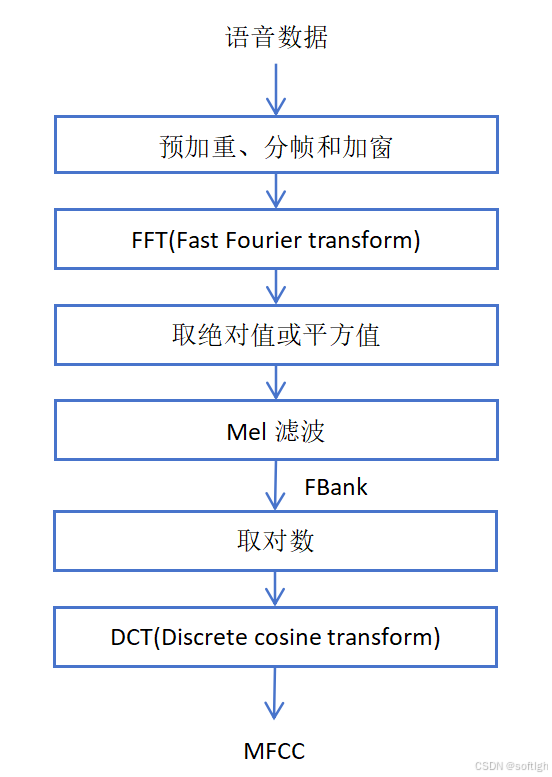
提取 Mel 谱,因为人的听觉系统是一个特殊的非线性系统,它对不同频率信号的灵敏度不同。Mel 频率分析基于人类听觉感知实验:
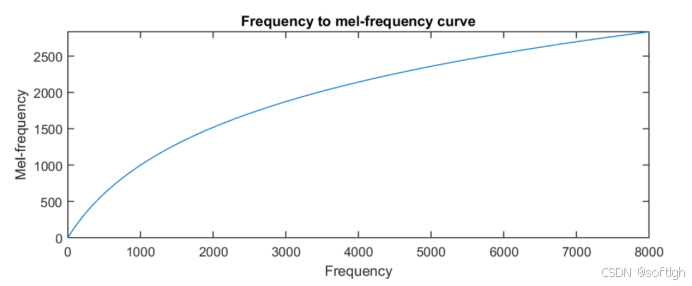
低频区域有许多滤波器,分布较密集;而在高频区域,滤波器数目较少,分布稀疏:
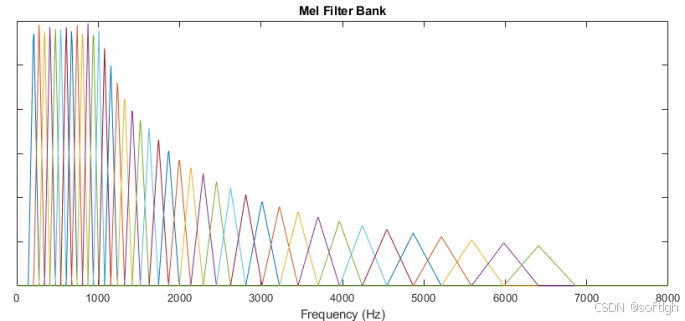
在 Mel 频谱上进行倒谱分析(取对数,做逆变换,实际逆变换一般通过 DCT 离散余弦变换实现,取 DCT 后的第 2 个到第 13 个系数作为 MFCC 系数),获得 Mel 频率倒谱系数 MFCC。如果是 CNN 等深度模型,则不需要做倒谱分析,使用 FBank 即可使深度模型充分学习到数据的细节;如果是传统机器学习模型,则可以取倒谱系数 MFCC。
其他特征还包括时频参数 zcr、energy、energy_entropy、chroma1-12 等,以及这些特征的 delta 和 delta-delta。
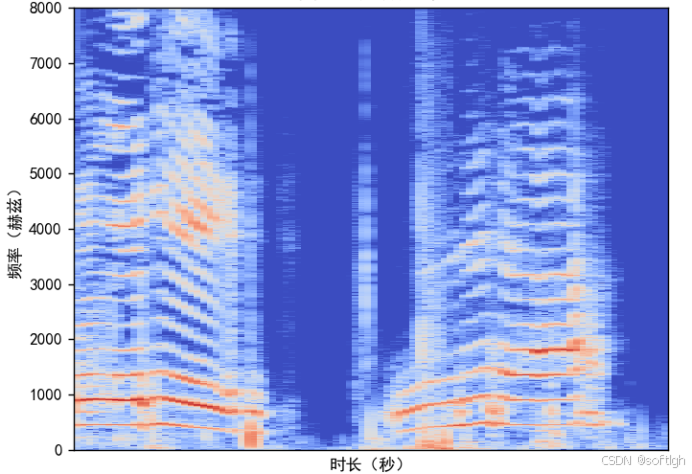
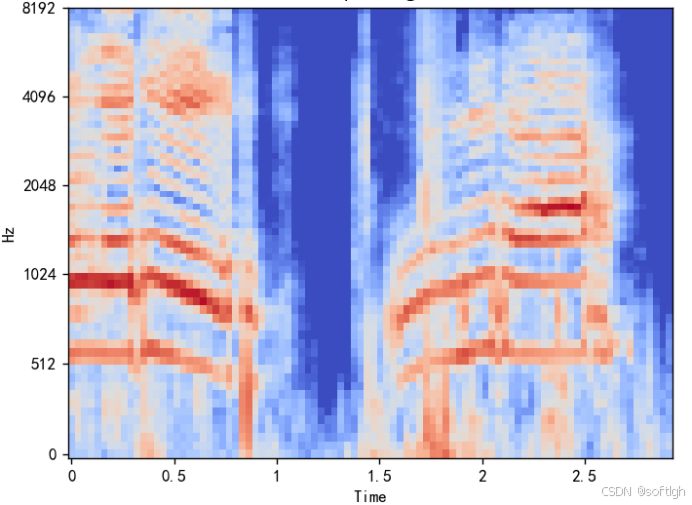
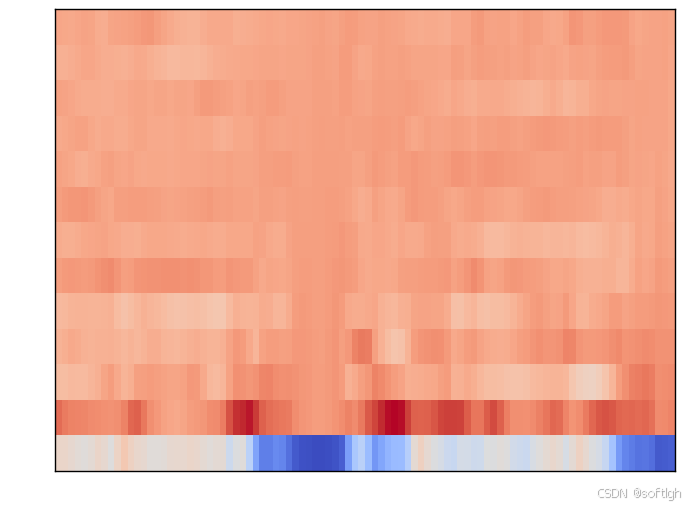
同一段语音的频谱图、Mel 频谱图和 MFCC 如下:
-
频谱图:
-
Mel 频谱图:
-
MFCC:
算法
哭声识别的主要算法包括支持向量机(SVM)、随机森林(Random Forest)、DNN 神经网络以及深度卷积神经网络(CNN),而时序模型 RNN 和 LSTM 也可以用于与 CNN 结合来提取哭声中的时序模式。
- 支持向量机(SVM):以其在小样本、高维数据及非线性分类中的良好表现著称,适用于哭声特征较为明确且数据集规模适中的情况。然而,SVM 在处理大规模数据集时可能面临计算效率的挑战。
- 随机森林(Random Forest):通过构建多个决策树并集成其预测结果,展现出强大的抗过拟合能力和稳定性,尤其适合处理包含噪声和复杂交互作用的哭声数据。
- 卷积神经网络(CNN):擅长捕捉音频信号中的局部特征,如频率、振幅等,通过卷积层、池化层的堆叠,能够自动提取并学习哭声的高级特征表示。
通过各种模型的对比实验,发现结合 CNN 和 LSTM 的混合模型在保持高准确率的同时,也具备较好的实时性,能够满足系统需求。此外,还借鉴了行业内的最佳实践,如利用迁移学习技术,在预训练的模型基础上进行微调,以加速模型收敛并提升识别效果。
同时,使用了集成学习的方法,将多个机器学习算法(如支持向量机 SVM、随机森林 RF 和深度学习模型 CNN)进行融合,通过投票或加权平均的方式得出最终识别结果。这种策略不仅提高了识别准确率,还增强了模型的鲁棒性。
此外,程序还引入了实时反馈机制,通过用户反馈不断优化模型参数和算法逻辑。
四、哭声识别的难点
- 哭声信号的复杂性和多样性:婴儿哭声不仅不同个体频率和模式不同,同一个体在不同年龄、健康状况、情绪状态等情况下也会有很大变化,这使得哭声特征参数的提取与识别变得尤为复杂。
- 复杂环境下的噪声干扰:家庭环境中常见的背景噪声,如电视声、谈话声、厨房烹饪声等都对识别有很大的影响。在嘈杂环境中,哭声识别的误报率可高达 30% 以上,这直接影响了用户体验。为解决这一问题,引入了先进的自适应噪声消除技术,自适应噪声消除算法通过实时估计并消除背景噪声,提高信噪比,从而增强哭声信号的清晰度。通过大量样本训练,使系统能在不同噪声背景下准确识别哭声,有效降低了误报率至 5% 以下。
- 婴儿的哭声与笑声的相似性:以及与猫叫声的相似性也是识别难点之一。
五、准确性
测试结果显示,程序在识别准确率上达到了 95% 以上,且在不同场景下的表现均较为稳定。
六、运行平台
本程序可以运行在以下平台:
- Windows 平台(所有 Windows 系统)
- Linux 平台
- MIPSel 平台
- ARM 平台
- iPhone 平台
- Android 平台
各平台均有 SDK,附件中提供了各个平台的库,可根据需要自行选择下载。
七、性能及硬件要求
- CPU 要求:主频 100 MHz 以上。
- 内存要求:50k-100k。
八、代码及示例
定义
#ifndef SPEECH_RECOGNIZER_H
#define SPEECH_RECOGNIZER_H
#ifdef __cplusplus
extern "C" {
#endif
typedef enum SR_RECOGNIZE_MODE_ {
SR_RECOGNIZE_VAD = 1, // 速度快的 vad
SR_RECOGNIZE_VAD2 = 2, // 比较敏感的 vad
SR_RECOGNIZE_WAKEUP = 4, // 唤醒
SR_RECOGNIZE_KEYWORD = 8, // 离线词识别
SR_RECOGNIZE_BREAK = 16, // 打断
SR_RECOGNIZE_NS_MONO1 = 256, // 降噪 1
SR_RECOGNIZE_NS_MONO2 = 512, // 降噪 2
SR_RECOGNIZE_CRY_DETECT = 2048, // 哭声检测
SR_RECOGNIZE_CRY_DETECT2 = 4096, // 哭声检测
SR_RECOGNIZE_FINAL = 0x40000000
} SR_RECOGNIZE_MODE;
typedef enum sr_bool_ {sr_false = 0, sr_true = 1} sr_bool;
typedef enum SR_VAD_STATUS_ {SR_VAD_STATUS_SILENCE = 0, SR_VAD_STATUS_MAYBE = 1, SR_VAD_STATUS_ACTIVITY = 2} SR_VAD_STATUS;
//_voicePos 是指送入数据(字节)的位置
typedef void (*sr_pVADListener)(void *_listener, SR_VAD_STATUS _vadStatus, long long _voicePos);
typedef void (*sr_pVAD2Listener)(void *_listener, long long _voicePos, char *_data, int _dataLen);
typedef void (*sr_pVAD3Start)(void *_listener, long long _pos);
typedef void (*sr_pVAD3Data)(void *_listener, long long _pos, char *_data, int _len);
typedef void (*sr_pVAD3End)(void *_listener, long long _pos);
typedef void (*sr_pWakeUpListener)(void *_listener, long long _voiceStartPos, long long _voiceEndPos, float _confidence);
typedef void (*sr_pKeywordListener)(void *_listener, int _keyword, const char *_keywordStr, long long _voiceStartPos, long long _voiceEndPos, float _confidence);
typedef void (*sr_pTimeOut)(void *_listener);
typedef void (*sr_pData)(void *_listener, char *_data, int _len);
typedef void (*sr_pCryDetectListener)(void *_listener, long long _voicePos, float _confidence);
// 创建识别器
void *sr_createRecognizer (int _mode);
void *sr_createRecognizer2 (int _sampleRate, int _mode);
void *sr_createRecognizer3 (int _sampleRate, int _mode, int _channel);
// 销毁识别器
void sr_destroy (void *_recognizer);
// 设置 VAD 监听器
void sr_setVADListener (void *_recognizer, void *_listener, sr_pVADListener _flistener);
void sr_setVADListener2 (void *_recognizer, void *_listener, sr_pVAD2Listener _flistener);
void sr_setVADListener3 (void *_recognizer, void *_listener, sr_pVAD3Start _fonVADStart, sr_pVAD3Data _fonVADData, sr_pVAD3End _fonVADEnd);
void sr_setVADMaxGapsilence (void *_recognizer, int _microSeconds);
void sr_setVADMaxStartsilence (void *_recognizer, int _microSeconds);
void sr_setVADMinLen (void *_recognizer, int _microSeconds);
void sr_setVADLevel (void *_recognizer, int _level);
void sr_setKeywordListener (void *_recognizer, void *_listener, sr_pKeywordListener _flistener);
void sr_loadKeywordModel (void *_recognizer, const char *_modelDir, const char *_modelName);
void sr_setNSMonoListener (void *_recognizer, void *_listener, sr_pData _flistener);
void sr_setNSMonoLevel (void *_recognizer, int _level);
void sr_loadCryDetectModel (void *_recognizer, const char *_modelDir, const char *_modelName);
void sr_setCryDetectListener (void *_recognizer, void *_listener, sr_pCryDetectListener _flistener);
void sr_setCryThresh (void *_recognizer, float _cryTime);
void sr_setFinalDataListener (void *_recognizer, void *_listener, sr_pData _flistener);
void sr_setTimeOutListener (void *_recognizer, int _msTime, void *_listener, sr_pTimeOut _fonTimeOut);
// 开始识别
// 这里一般是线程,这个函数在停止识别之前不会返回
void sr_run (void *_recognizer);
// 识别一小段时间,该函数处理片断时刻后返回
sr_bool sr_runOnce (void *_recognizer);
// 暂停信号分析
void sr_pause (void *_recognizer, sr_bool _isPause);
//void sr_reset (void *_recognizer);
// 停止识别,该函数调用后 sr_run 会返回
// 该函数只是向识别线程发出退出信号,判断识别器是否真正已经退出要使用以下的 sr_isStopped 函数
void sr_stop (void *_recognizer);
// 判断识别器线程是否已经退出
sr_bool sr_isStopped (void *_recognizer);
// 要求输入数据单声道,16bits 采样精度,小端编码的音频数据
int sr_writeData (void *_recognizer, char *_data, int _dataLen);
int sr_writePlayData (void *_recognizer, char *_data, int _dataLen);
int sr_getVer ();
#ifdef __cplusplus
}
#endif
#endif
使用示例
#include <stdio.h>
#include <stdlib.h>
#include "speechRecog.h"
#ifdef WIN32
#include <Windows.h>
#include <process.h>
#else
#include<pthread.h>
#include <unistd.h>
#endif
#ifdef WIN32
#define mysleep Sleep
#else
#define mysleep (_ms) usleep (_ms * 1000)
#endif
void myCryDetected_Em (void *_listener, long long _voicePos, float _confidence)
{
printf ("-----------------cry detected (% f)------------\n", _confidence);
};
int main (int argc, char* argv [])
{
void *recognizer = NULL;
char *buf [512];
recognizer = sr_createRecognizer2 (SAMPLE_RATE,
SR_RECOGNIZE_CRY_DETECT2
//| SR_RECOGNIZE_VAD
);
//sr_loadCryDetectModel (recognizer, "./crydetect", "crydetect");
sr_setCryDetectListener (recognizer, NULL, myCryDetected_Em);
while (true)
{
// 这里假定录音数据不断在写到 buf 中
//...
// 把语音数据写到识别器
sr_writeData (recognizer, buf, sizeof (buf));
// 执行一帧的识别
while (sr_runOnce (recognizer));
}
sr_stop (recognizer);
while (sr_runOnce (recognizer));
while (!sr_isStopped (recognizer)) mysleep (1);// 让异步线程执行完
sr_destroy (recognizer);
return 0;
}
下载链接
婴儿哭声库及 demo 源码下载:babyCry.zip
婴儿哭声分类识别实现(准确率 99.3%)(深度学习、迁移学习、音频分类、TensorFlow)
高锰酸钾嘿嘿嘿 于 2022-07-07 20:26:40 发布 已于 2024-04-07 18:42:09 修改
一、项目概述
本文是婴儿哭声分类识别系统的主体部分,旨在解决智能音频分类问题。为达成这一目标,作者查阅了大量资料并进行了大量实验,最终构建了一个基于迁移学习 Urbansound 数据模型的深度学习模型,其婴儿哭声分类识别准确率相对较高。
本文将从问题出发,依次阐述如何提出问题、分析问题、解决问题,并逐步获得满意的结果。
二、项目规划
1. 项目要点问题
- 婴儿哭声数据集 —— 从何处获取?
- 音频数据如何预处理?
- 音频如何分类?
- 神经网络结构如何设计?(DNN、DNN+CNN、迁移学习)
- 实验如何设计?
- …
2. 项目开发工具
- 模型训练(GPU)—— Colab
- 本地环境管理 —— Anaconda
- 本地开发 —— PyCharm
3. 项目涉及代码
- DNN 模型
- DNN 迁移 Urbansound 模型
- CNN 模型
- CNN 迁移 Urbansound 模型
- 迁移 VGGish 模型
三、项目要点
1. 婴儿哭声数据集
本项目首先面临的关键问题是数据集的获取。起初,作者在一个音频共享网站找到了许多婴儿哭声音频,但数量有限且音频分类标签的准确性存在不确定性。因此,作者转向寻找现成的婴儿哭声数据集。
经过在各大机器学习比赛网站、数据集网站以及国内外音频分类相关论文中的查找,最终在**飞桨数据集**中找到了有标签的婴儿啼哭数据集。数据集包含 train 和 test 两个文件夹,如图 1 所示。由于 test 文件夹中的音频没有标签,因此只能使用 train 文件夹数据进行训练,数据集类别如图 2 所示。

图 1 数据集文件

图 2 (train 文件夹)训练集
- 训练集中共有数据 918 条,音频格式为 WAV,数据长度 5s~30s 不等。
2. 音频处理
2.1 音频问题
解决了数据集问题后,下一步需要考虑音频数据问题:
- 数据量是否足够训练出符合要求的模型?
- 数据长度是否符合神经网络需求?
- 数据应如何送入网络?
- …
2.2 解决音频问题
作者在研究生阶段研究的是图像处理,图像可以被看作是一个多维矩阵,具有长、宽、高,自然可以送入神经网络中。音频该如何处理呢?
通过查找资料发现,音频实际是以波的形式存在,若以时间为横轴、振幅为纵轴绘制图像,则如图 3 所示。

图 3 波形图
通过查看原始音频文件数据存储发现,虽然音频文件同样可表现为张量数据,如图 4 所示,但在深度学习方面通常不会将其直接放入网络。通常的做法是将音频转换为频谱图,如图 5 所示。频谱图是音频波的简洁“快照”,因为它是图像,所以非常适合输入到为处理图像而开发的基于 CNN 的架构中。图 6 展示了音频深度学习流程图。

图 4 音频文件

图 5 频谱图(spectrogram)

图 6 音频深度学习流程图
3. 深度学习网络结构
针对本项目,作者考虑了几种可能的深度学习网络结构,如全连接神经网络(DNN)、卷积神经网络(CNN+DNN)、迁移学习(VGGish)。
4. 音频数据
- 婴儿哭声音频
本文所使用的婴儿哭声数据集并非标准数据集,且数据量较小,因此在判断网络模型优劣方面并不具有权威性。本文将使用婴儿哭声测试集作为评估模型的一个参考,同时使用标准音频分类数据集(Urbansound8K)对模型进行辅助评估,并最终找到识别效果较好的深度学习分类模型。
- 实验数据集
本项目希望音频的最大长度不超过 10s,故针对所使用的数据需要经过裁剪处理,并映射到指定长度。
Urbansound8K 是包含 10 类声音的数据集,包括狗叫、汽车喇叭等声音,音频长度均在 10s 以内;
Babysound 是一类包含 6 类声音的数据集,包括饿了、想睡觉等声音,音频长度为 5s~30s 不等,如图 7 所示。本项目将通过裁剪、分割不符合条件的音频,最终音频如图 8 所示。

图 7 原始婴儿哭声音频

图 8 分割之后的婴儿哭声音频数据
- 关于婴儿哭声数据集的测试集
由于分割后的婴儿哭声数据集数量依然很小(共 2184 条),并不足以满足训练集、验证集、测试集的各部分需求。因此,本项目采用随机从原始婴儿哭声数据集中(长度 5s~30s 的数据)抽取一定量的数据,并随机对抽到的每条数据进行裁剪,使得每条数据长度为 10s,由此获得的有标签的 294 条音频数据将作为最终的婴儿哭声测试集。
四、实验
1. DNN 网络
- DNN 网络结构如图 9 所示;

图 9 DNN 网络结构
- Urbansound 数据集在该网络中的表现如图 10 所示;

图 10 Urbansound 数据集在 DNN 网络中的表现
- Babysound 数据集在该网络中的表现如图 11 所示;

图 11 Babysound 数据集在 DNN 网络中的表现
- 该模型在 Babysound 测试集上的准确率为 (0.8163265306122449),如图 12 所示。

图 12 婴儿哭声测试集在该模型上的准确率
2. DNN+CNN
- CNN 卷积神经网络结构如图 13 所示;

图 13 CNN 卷积神经网络结构
- Urbansound 数据在 CNN 网络中的表现如图 14 所示;

图 14 Urbansound 数据在 CNN 网络中的表现
- Babysound 数据在 CNN 网络中的表现如图 15 所示;

图 15 Babysound 数据在 CNN 网络中的表现
- CNN 网络模型在 Babysound 测试集上的准确率为 (0.9081632653061225),如图 16 所示;

图 16 Babysound 测试集在 CNN 网络模型中的准确率
- 在此网络结构下,通过迁移学习 Urbansound 数据集训练的模型,Babysound 数据在此网络结构下的表现如图 17 所示;

图 17 Babysound 数据在迁移学习 Urbansound 数据模型的表现
- 迁移学习 Urbansound 模型在 Babysound 测试集上的准确率为 (0.9931972789115646),如图 18 所示。

图 18 Babysound 测试集在迁移学习 Urbansound 模型上的准确率
3. 迁移学习 VGGish 模型
VGGish 模型 是在 YouTube 的 AudioSet 数据上预训练得到的模型,VGGish 支持从音频波形中提取具有语义的 128 维 embedding 特征向量,网络结构如图 19 所示。

图 19 VGGish 网络结构
在迁移学习 VGGish 模型的基础上,实验在网络后添加长短时记忆网络(Long Short Term Memory Network, LSTM)和一个全连接层,最终将婴儿哭声数据分成 6 类,网络结构如图 20 所示。

图 20 在 VGGish 网络后添加短时记忆网络并添加一层全连接
图 21 展示了实验相关参数和实验结果;

图 21 Babysound 数据在迁移学习 VGGish 网络模型上的表现
图 22 为 VGGish 迁移模型在 Babysound 测试集上的准确率为 (0.8639455782312925)。

图 22 Babysound 测试集在迁移学习 VGGish 模型上的准确率
4. 实验结果汇总
| 深度网络 | 在 Babysound 测试集中的准确率 |
|---|---|
| DNN 网络模型 | 0.8163265306122449 |
| 迁移学习 Urbansound 的 DNN 网络模型 | 0.5578231292517006 |
| CNN 网络模型 | 0.9081632653061225 |
| 迁移学习 Urbansound 数据集的 CNN 网络模型 | 0.9931972789115646 |
| 迁移学习 VGGish 模型 | 0.8639455782312925 |
五、总结
本文所述实验内容是婴儿哭声分类识别系统的主体部分,涉及 5 种网络模型,分别是 DNN 深度学习模型、迁移学习 Urbansound 的 DNN 网络模型、CNN 深度学习模型、迁移学习 Urbansound 数据模型 和 迁移学习 VGGish 模型。其中,迁移学习 Urbansound 数据模型在婴儿哭声测试集上的准确率最高,为 0.9931972789115646。
- 微信小程序 —— 微信搜索🔍“婴儿啼哭” 或扫描图 24;
- PC 管理后台;
- 后端等。

图 23 完整的项目结构图
图 24 婴儿啼哭小程序 img
六、后记
项目始于 2022 年 3 月,从构思到完成本文提到的内容用时约两周。这是作者第一次尝试将项目总结并发布,希望通过写作戒骄戒躁、重拾信心。
回顾项目那几周,压力巨大,不仅面临项目截止日期的压力,身体也出现问题,情感上也遭遇挫折,导致失眠、抑郁、自闭等情绪。但正如那句话所说,“打不倒我的只会让我更强大”。梦想仍未实现,仍需努力!挺起胸膛,撑开旗帜,刀锋向前!
七、参考文献
- Audio Deep Learning Made Simple: Sound Classification, Step-by-Step
- Simple audio recognition: Recognizing keywords
- A Gentle Introduction to Audio Classification With Tensorflow
- 应用深度学习使用 Tensorflow 对音频进行分类
- SENGUPTA, NANDINI, SAHIDULLAH, MD, SAHA, GOUTAM. Lung sound classification using cepstral-based statistical features [J]. Computers in Biology and Medicine, 2016, 75: 118-129. DOI:10.1016/j.compbiomed.2016.05.013.
- Tensorflow-Audio-Classification
via:
-
声波通讯的原理_声波通信原理-CSDN博客 softlgh 已于 2023-12-17 23:39:13 修改
https://blog.csdn.net/softlgh/article/details/43428407 -
3分钟为你的应用添加声波通信功能-CSDN博客 softlgh 已于 2023-12-17 23:35:45 修改
https://blog.csdn.net/softlgh/article/details/40507623 -
效果超牛的基于声波通信和声音指纹的微信互动平台 - CSDN 博客 softlgh 已于 2021-05-0315:31:06 发布
https://blog.csdn.net/softlgh/article/details/116375944 -
android/iphone/windows/linux/ 微信声波通讯库_android 实现声波通信 - CSDN 博客 softlgh 于 2015-02-02 00:54:19 发布
https://blog.csdn.net/softlgh/article/details/43390755 -
Android/iphone/ 微信 手机通过声波初始化智能设备的 WIFI 信息_无线信号识别安卓或者苹果 - CSDN 博客 softlgh 于2015-02-0300:34:41 发布
https://blog.csdn.net/softlgh/article/details/43427279 -
一种短距离声波通信的方案-CSDN博客 cfw在路上 于 2024-09-30 11:47:50 发布
https://blog.csdn.net/u013095415/article/details/79930354 -
基于设置端的鼾声识别_睡眠鼾声检测开发 github-CSDN 博客 softlgh 于 2025-03-13 21:16:15 发布
https://blog.csdn.net/softlgh/article/details/146242015 -
基于设备端的婴儿哭声识别_哭声检测算法 - CSDN 博客 softlgh 于 2024-10-11 23:21:40 发布
https://blog.csdn.net/softlgh/article/details/142864973 -
婴儿哭声分类识别实现(准确率99.3%)(深度学习、迁移学习、音频分类、tensorflow)_8k哭声检测-CSDN博客
https://blog.csdn.net/weixin_43028946/article/details/125556250






