1.HTTP协议
HTTP协议是客户端与服务器之间通信的基础。客服端通过HTTP协议向服务器发送请求,服务器收到请求后处理并响应。HTTP协议是无连接,无状态的协议,每次请求都需要建立新的连接,且服务器不会保存客服端的状态信息。
URL

user:pass表示登陆认证信息,包括登陆用户的用户名和密码。现在不用这样形式,以前台方案交割服务器认证信息。
常用协议
1. HTTP/HTTPS
-
功能:用于网页浏览和数据传输。
-
特点:HTTP 是明文传输,HTTPS 是加密传输,更安全。
2. FTP/SFTP
-
功能:用于文件传输。
-
特点:FTP 是明文传输,SFTP 是加密传输。
3. SMTP/POP3/IMAP
-
功能:用于电子邮件的发送和接收。
-
特点:SMTP 发送邮件,POP3 和 IMAP 接收邮件,IMAP 支持邮件同步。
4. DNS
-
功能:域名解析,将域名转换为IP地址。
-
特点:互联网的基础服务,确保域名可访问。
5. SSH
-
功能:安全的远程登录和管理。
-
特点:加密通信,安全性高。
服务器地址
www.qq.com表示的是服务器的地址,也叫域名。
但是用IP地址标识公网内的一台主机,当IP地址本身并不适合展示出来,实际域名和IP地址是等价的,为了让用户能更好的理解,就是用域名而不是地址了。URL当中是以域名形式表示服务器地址的。
服务器端口号
80表示 服务器端口号,HTTP协议和套接字编程都是一样位于应用层,在进行套接字编程时需要给服务器绑定对应的IP和端口号,而这里的应用层协议也同样需要有明确的端口号。
使用某种协议时,协议实际就是为我们提供服务,常用的服务与端口之间对应的关系是不需要指明该协议对应的端口号的,在URL当中,服务器的端口号一般是被省略的。
常见的协议端口号:
HTTP:80 HTTPS:443 SSH:22
带层次的文件路径
/dir/index.htm表示要访问的资源所在的路径,访问服务器的目的是获取服务器上的某种资源,通过前面的域名和端口号能找到对应的服务器进程了,又有指明资源的所在的路径,就可以精准定位到要访问的资源。还有视频,音频和视频等资源,HTTP之所以叫超文本传输协议,即超过文本,很多资源实际都不是普通的文本资源。
在浏览器打开CSDN域名后,浏览器就会获取CSDN首页,发起网页请求时,就会获取一张网页信息,后缀是html,就可以看到网页界面了。
可以看路径用的是" / "还是" \ ",这里是/就说明服务器是部署在Linux上的。
2.urlencode和urldecode
像 / ?:这些字符,已经被url当作特殊意义理解了,这些字符不能随意出现,比如参数中带有这些特殊字符,就必须先对特殊字符进行转义。
3. HTTP请求协议格式
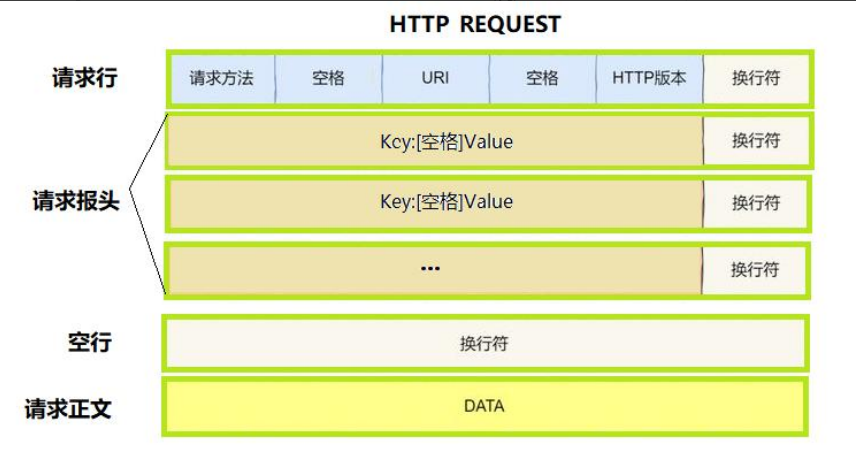
由四部分组成:
请求行:请求方法 空格 URI 空格 HTTP版本
请求报头:请求的属性,属性都是key和value组成的
空行:遇到空行就说明请求报头结束(\r\n)
请求正文:请求正文可以是空字符串,如果请求正文存在,则在请求报头中会有一个Content-Length属性来标识请求正文的长度
而前三部分一般是HTTP协议自有的,设置好的,用户不发送信息,则请求正文就为空字符串。
url中的 / 不是服务器上的根目录,/ 代表的是web根目录(wwwroot),这个目录下存储的是网站静态资源,如网页html,web根目录可以是你机器上的任何一个目录,由自己指定,urI的值为/时,http协议会默认拼接上站短的首页(index.html)。
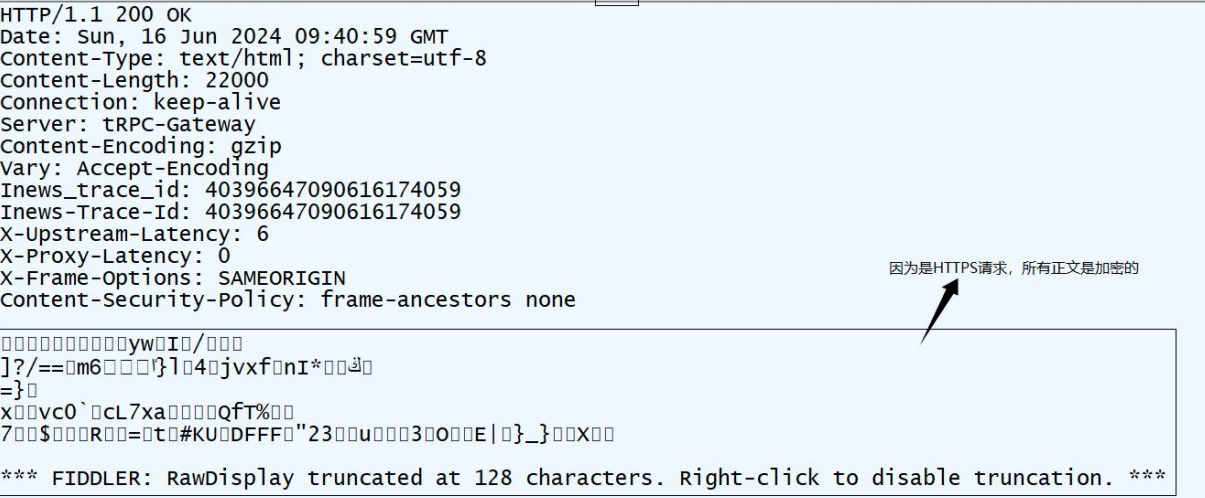
4.HTTP响应
首行:版本号+状态码+状态码解释
Header:请求的属性,冒号分割的键值对,每组属性之间用\r\n分隔,遇到空行表示Header部分结束
Body:空行后面的内容都是Body,Body允许为空字符串,如果Body存在,则在Header中会有一个Content-Length属性来标识Body的长度,如果服务返回了一个html界面,那么html界面就是在body中
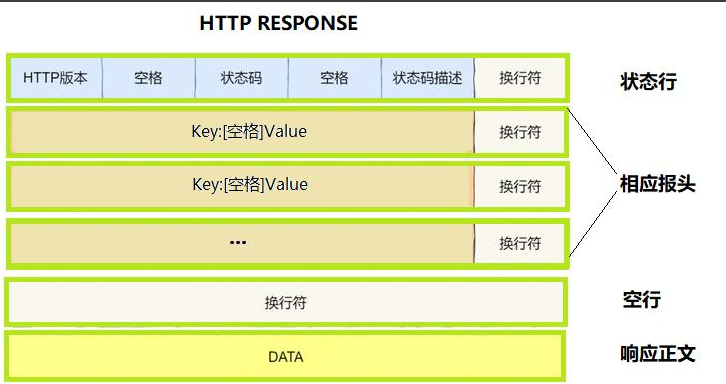
基本的应答格式
HTTP状态码
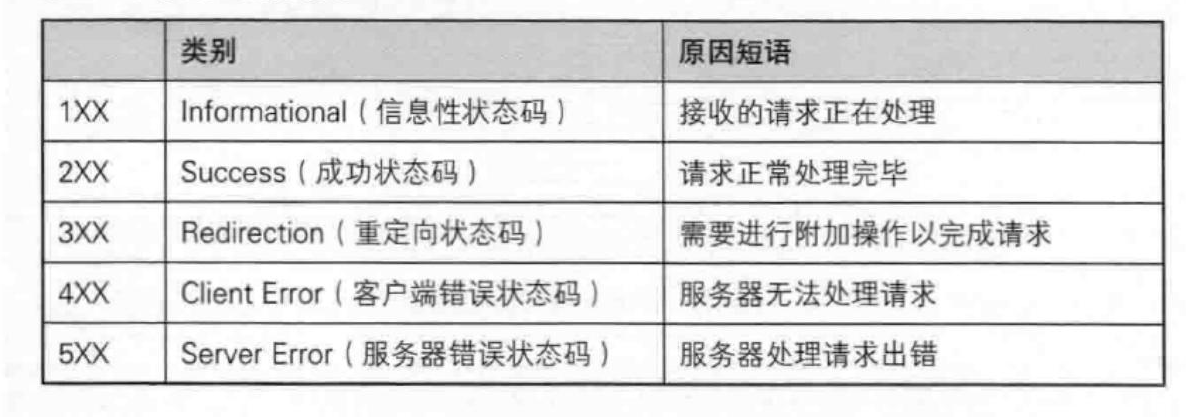
常见的状态码
| 200 | OK | 访问网站首页,服务器返回网页内容 |
| 201 | Created | 发布新文章,服务器返回文章创建成功的信息 |
| 204 | No Content | 删除文章后,服务器返回“无内容”表示操作成功 |
| 301 | Moved Permanently | 网站换域名后,自动跳转到新域名;搜索引擎更新网站链接时使用 |
| 302 | Found | 临时重定向,访问的资源临时移动到另一个位置 |
| 400 | Bad Request | 请求有语法错误,服务器无法理解 |
| 401 | Unauthorized | 请求要求用户的身份认证 |
| 403 | Forbidden | 服务器理解请求但拒绝执行,可能是权限问题 |
| 404 | Not Found | 请求的资源不存在,无法找到 |
| 500 | Internal Server Error | 服务器内部错误,无法完成请求 |
| 502 | Bad Gateway | 作为网关或代理工作的服务器,从上游服务器收到无效响应 |
| 503 | Service Unavailable | 服务器暂时过载或维护,无法处理请求 |
HTTP常见Header
Content-Type:数据类型(text/html)
Content-Length:Body长度
Host:客服端告知服务器,所请求的资源是在那个主机的端口号上
User-Agent:声明用户的操作系统和浏览器基本信息
referer:当前页面是从那个页面跳转过来的
补充:
GET https://www.sogou.com/ HTTP/1.1
1.GET
这是HTTP的请求方法,表示客服端希望从服务器获取资源,GET通常用于请求数据,不会改变服务器上的数据。
2. https://www.sogou.com/
这是请求的URL,指定了客服端想要访问的资源位置
3.HTTP/1.1
这是HTTP协议的版本号,表示客服端希望使用HTTP/1.1版本进行通信,如微信可能通信双方的版本是不一样的,所以需要告诉服务器版本号是什么,就可以执行对应的代码,而不会使用高版本的代码。
5.代码实现构建一个网页并访问创建的网页
TCPServer.hpp文件
全局定义一个回调函数,类构造函数要有端口号,会初始化端口号,套接字和运行状态,还会调用Socket类的类方法。Start函数需要传一个ioservice_t类型的回调函数,进入后改变isrunning状态,进入循环体,构建cInetAddr类型对象client,调用Socket类方法Accept,client作为参数传入进去,接着创建子进程,子进程的执行部分调用Socket类方法Close关掉套接字,子进程再创建一个子进程,创建完子进程后就退出,创建的子进程会执行回调函数callback函数,调用Socket类方法关闭文件并退出。
#include "Socket.hpp"
#include <iostream>
#include <memory>
#include <sys/wait.h>
#include <functional>using namespace SocketModule;
using namespace LogModule;using ioservice_t = std::function<void(std::shared_ptr<Socket> &sock, InetAddr &client)>;class TcpServer
{
public:TcpServer(uint16_t port) : _port(port),_listensockptr(std::make_unique<TcpSocket>()),_isrunning(false){_listensockptr->BuildTcpSocketMethod(_port);}void Start(ioservice_t callback){_isrunning = true;while (_isrunning){InetAddr client;auto sock = _listensockptr->Accept(&client); // 1. 和client通信sockfd 2. client 网络地址if (sock == nullptr){continue;}LOG(LogLevel::DEBUG) << "accept success ..." << client.StringAddr();// sock && clientpid_t id = fork();if (id < 0){LOG(LogLevel::FATAL) << "fork error ...";// excepter(sock); // exit(FORK_ERR);}else if (id == 0){// 子进程 -> listensock_listensockptr->Close();if (fork() > 0)exit(OK);// 孙子进程在执行任务,已经是孤儿了callback(sock, client);sock->Close();exit(OK);}else{// 父进程 -> socksock->Close();pid_t rid = ::waitpid(id, nullptr, 0);(void)rid;}}_isrunning = false;}~TcpServer() {}private:uint16_t _port;std::unique_ptr<Socket> _listensockptr;bool _isrunning;//func_t excepter; // 服务器异常的回调
};HTTP.hpp文件
HTTPRequest类是实现协议请求的,Serialize函数就是序列化功能,会返回序列化后的请求,ParseReqLine函数是解析首行用的,参数接收一个首行,创建stringstream字符串流,>>从字符串流中提取数据,分别存储到method,uri和version中,以空隔作为分隔符。Deeserialize函数是解析信息,调用Util类的方法ReadOneLine函数读取一行出来,再调用ParseReqLine函数提取数据,然后提取后的uri值进行判断,是 / 则就把webroot和uri和homepage进行拼接,得到一个指定路径(./wwwroot/index.html),否则是uri为webroot+uri。
#pragma once#include "Socket.hpp"
#include "TcpServer.hpp"
#include "Util.hpp"
#include "Log.hpp"
#include <iostream>
#include <string>
#include <memory>
#include <sstream>
#include <unordered_map>using namespace SocketModule;
using namespace LogModule;const std::string gspace = " ";
const std::string glinespace = "\r\n";
const std::string glinesep = ": ";const std::string webroot = "./wwwroot";
const std::string homepage = "index.html";
const std::string page_404 = "/404.html";class HttpRequest
{
public:HttpRequest(){}std::string Serialize(){return std::string();}void ParseReqLine(std::string &reqline){// GET / HTTP/1.1std::stringstream ss(reqline);ss >> _method >> _uri >> _version;}// 实现, 我们今天认为,reqstr是一个完整的http request stringbool Deserialize(std::string &reqstr){// 1. 提取请求行std::string reqline;bool res = Util::ReadOneLine(reqstr, &reqline, glinespace);LOG(LogLevel::DEBUG) << reqline;// 2. 对请求行进行反序列化ParseReqLine(reqline);if (_uri == "/")_uri = webroot + _uri + homepage; // ./wwwroot/index.htmlelse_uri = webroot + _uri; // ./wwwroot/a/b/c.htmlLOG(LogLevel::DEBUG) << "_method: " << _method;LOG(LogLevel::DEBUG) << "_uri: " << _uri;LOG(LogLevel::DEBUG) << "_version: " << _version;// ./wwwroot/XXX.YYYreturn true;}std::string Uri() { return _uri; }~HttpRequest(){}private:std::string _method;std::string _uri;std::string _version;std::unordered_map<std::string, std::string> _headers;std::string _blankline;std::string _text;
};
假设
reqline的值为"GET / HTTP/1.1",那么解析后的结果是:
_method为"GET"
_uri为"/"
_version为"HTTP/1.1"
这个类是用来响应请求,响应请求需要传入版本号,Serialize函数作用是构建状态行,包括版本号,空格,状态码和空格,范围for来构建报头的键+ :+报头值+\r\n形式,然后都存储到resp_header中,最后返回状态行+resp_header+\r\n+_text,与响应图内容一致。SetTargetFile函数接收一个string,然后把接收的赋值给成员变量_targetfile。函数SetCode作用是修改_code值,根据_code值来判断状态信息是是什么。SetHeader函数是构建报头信息,要传入键和值,先查询是否存在,不存在就新建并插入进去。Uri2Suffix是来找到网页类型的,并初始化_targetfile的值,从后往前找 .号,把点号开始到最后的位置形成子串赋值给_targetfile,下面根据suffix的值来返回不同的网页类型。
MakeResponse函数功能是做出响应,先读取文件内容调用Util类的方法ReadFileContent,如果失败了就执行if,文本内容_text初始化,设置状态码404SetCode函数,_targetfile变量赋值,文件大小获取通过调用Util类方法FilzeSize函数,调用Uri2Suffix函数获取访问资源以及网页类型,suffix存储网页类型,然后调用SetHeader函数把内容类型以及内容长度放进去。读取成功就执行设置状态码为200,也要获取文件大小,文件类型以及放入报头关于文件大小和类型信息。
class HttpResponse
{
public:HttpResponse() : _blankline(glinespace), _version("HTTP/1.0"){}// 实现: 成熟的http,应答做序列化,不要依赖任何第三方库!std::string Serialize(){std::string status_line = _version + gspace + std::to_string(_code) + gspace + _desc + glinespace;std::string resp_header;for (auto &header : _headers){std::string line = header.first + glinesep + header.second + glinespace;resp_header += line;}return status_line + resp_header + _blankline + _text;}void SetTargetFile(const std::string &target){_targetfile = target;}void SetCode(int code){_code = code;switch (_code){case 200:_desc = "OK";break;case 404:_desc = "Not Found";break;default:break;}}void SetHeader(const std::string &key, const std::string &value){auto iter = _headers.find(key);if (iter != _headers.end())return;_headers.insert(std::make_pair(key, value));}std::string Uri2Suffix(const std::string &targetfile){// ./wwwroot/a/b/c.htmlauto pos = targetfile.rfind(".");if(pos == std::string::npos){return "text/html";}std::string suffix = targetfile.substr(pos);if(suffix == ".html" || suffix == ".htm")return "text/html";else if(suffix == ".jpg")return "image/jpeg";else if(suffix == "png")return "image/png";elsereturn "";}bool MakeResponse(){if (_targetfile == "./wwwroot/favicon.ico"){LOG(LogLevel::DEBUG) << "用户请求: " << _targetfile << "忽略它";return false;}int filesize = 0;bool res = Util::ReadFileContent(_targetfile, &_text); // 浏览器请求的资源,一定会存在吗?出错呢?if (!res){_text = "";LOG(LogLevel::WARNING) << "client want get : " << _targetfile << " but not found";SetCode(404);_targetfile = webroot + page_404;filesize = Util::FileSize(_targetfile);Util::ReadFileContent(_targetfile, &_text);std::string suffix = Uri2Suffix(_targetfile);SetHeader("Content-Type", suffix);SetHeader("Content-Length", std::to_string(filesize));}else{LOG(LogLevel::DEBUG) << "读取文件: " << _targetfile;SetCode(200);filesize = Util::FileSize(_targetfile);std::string suffix = Uri2Suffix(_targetfile);SetHeader("Conent-Type", suffix);SetHeader("Content-Length", std::to_string(filesize));}return true;}bool Deserialize(std::string &reqstr){return true;}~HttpResponse() {}// private:
public:std::string _version;int _code; // 404std::string _desc; // "Not Found"std::unordered_map<std::string, std::string> _headers;std::string _blankline;std::string _text;// 其他属性std::string _targetfile;
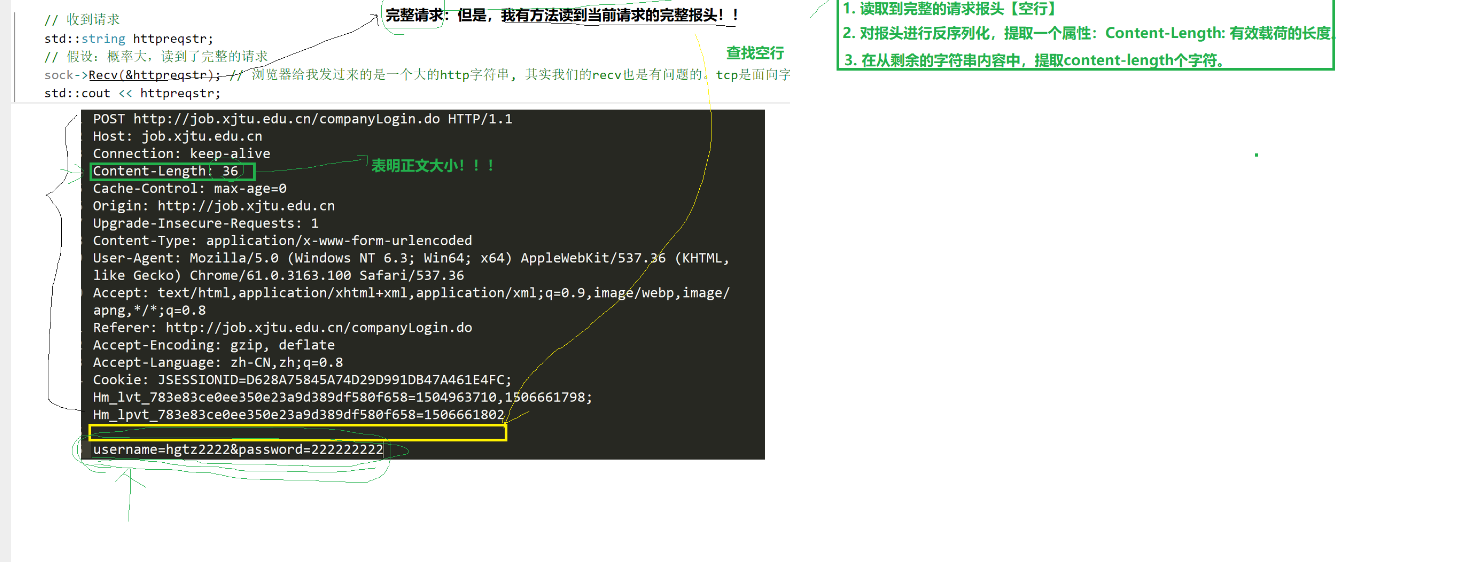
};类HTTP是处理网络请求的地方,HandlerHttpRequest函数要传入Socket类引用和InetAddr类型引用,调用Socket类方法读取套接字内容,存储到httpreqstr中,读取成功走if,构建一个HttpRequest类型对象,执行这个类的方法提取请求行信息,接着再创建HttpResponse类型对象,调用这个类的方法SetTargetFile函数去设置_targetfile的值,执行MakeResponse函数进行处理响应,处理成功就把响应的数据进行序列化,然后调用Send函数发送出去。
class Http
{
public:Http(uint16_t port) : tsvrp(std::make_unique<TcpServer>(port)){}void HandlerHttpRquest(std::shared_ptr<Socket> &sock, InetAddr &client){// 收到请求std::string httpreqstr;// 假设:概率大,读到了完整的请求// bug!int n = sock->Recv(&httpreqstr); // 浏览器给我发过来的是一个大的http字符串, 其实我们的recv也是有问题的。tcp是面向字节流的.if (n > 0){std::cout << "##########################" << std::endl;std::cout << httpreqstr;std::cout << "##########################" << std::endl;// 对报文完整性进行审核 -- 缺// 所以,今天,我们就不在担心,用户访问一个服务器上不存在的资源了.// 我们更加不担心,给用户返回任何网页资源(html, css, js, 图片,视频)..., 这种资源,静态资源!!HttpRequest req;req.Deserialize(httpreqstr);HttpResponse resp;resp.SetTargetFile(req.Uri());if (resp.MakeResponse()){std::string response_str = resp.Serialize();sock->Send(response_str);}// HttpResponse resp;// resp._version = "HTTP/1.1";// resp._code = 200; // success// resp._desc = "OK";// //./wwwroot/a/b/c.html// LOG(LogLevel::DEBUG) << "用户请求: " << filename;// bool res = Util::ReadFileContent(filename, &(resp._text)); // 浏览器请求的资源,一定会存在吗?出错呢?// (void)res;}// #ifndef DEBUG
// #define DEBUG
#ifdef DEBUG// 收到请求std::string httpreqstr;// 假设:概率大,读到了完整的请求sock->Recv(&httpreqstr); // 浏览器给我发过来的是一个大的http字符串, 其实我们的recv也是有问题的。tcp是面向字节流的.std::cout << httpreqstr;// 直接构建http应答. 内存级别+固定HttpResponse resp;resp._version = "HTTP/1.1";resp._code = 200; // successresp._desc = "OK";std::string filename = webroot + homepage; // "./wwwroot/index.html";bool res = Util::ReadFileContent(filename, &(resp._text));(void)res;std::string response_str = resp.Serialize();sock->Send(response_str);
#endif// 对请求字符串,进行反序列化}void Start(){tsvrp->Start([this](std::shared_ptr<Socket> &sock, InetAddr &client){ this->HandlerHttpRquest(sock, client); });}~Http(){}private:std::unique_ptr<TcpServer> tsvrp;
};Util.hpp文件
这个类实现都是读取文件功能,ReadFileContent函数,传入文件路径,然后调用FileSize函数获取文件大小,大于0就走if,创建一个输入文件流对象in,从filename的文中中读取数据,in.is_open判断文件是否打开,string类型out重新设置大小与filesize一致,read函数从文件中读取filesize字节的数据,并存储到out字符串对象中,(char*)是要按char大小读取,避免超出filesize大小,最后关闭文件。ReadOneLine是读取单行内容,find找到sep(\r\n)位置,然后把0到sep位置字符串形成子串并存储到out中,再把bigstr的0到pos+sep的内容删除,因为已经读取到了。FileSize函数创建一个in的输入流文件对象,从文件中读取数据,std::ios::binary标志表示以二进制模式打开文件,再二进制模式下,文件的字节不会被转换或解释,而是直接读取,seekg函数把文件的位置指针移动到文件的末尾,tellg函数是回去当前文件流位置指针的位置,也就是文件的大小(一个字节距离,总距离就是表示有多少个字节),seekg函数把位置指针移到最后,然后用tellg函数得到当前位置的大小就可以获取到文件的大小了。tsvrp是TcpServer对象的智能指针,调用TcpServrer类方法Start函数,Start函数会传入一个lambda表达式,参数要Socket和InetAddr类型,执行部分时调用HandlerHttpRquest函数。
#pragma once #include <iostream>
#include <fstream>
#include <string>// 工具类class Util
{
public:static bool ReadFileContent(const std::string &filename /*std::vector<char>*/, std::string *out){// version1: 默认是以文本方式读取文件的. 图片是二进制的.// std::ifstream in(filename);// if (!in.is_open())// {// return false;// }// std::string line;// while(std::getline(in, line))// {// *out += line;// }// in.close();// version2 : 以二进制方式进行读取int filesize = FileSize(filename);if(filesize > 0){std::ifstream in(filename);if(!in.is_open())return false;out->resize(filesize);in.read((char*)(out->c_str()), filesize);in.close();}else{return false;}return true;}static bool ReadOneLine(std::string &bigstr, std::string *out, const std::string &sep/*\r\n*/){auto pos = bigstr.find(sep);if(pos == std::string::npos)return false;*out = bigstr.substr(0, pos);bigstr.erase(0, pos + sep.size());return true;}static int FileSize(const std::string &filename){std::ifstream in(filename, std::ios::binary);if(!in.is_open())return -1;in.seekg(0, in.end);int filesize = in.tellg();in.seekg(0, in.beg);in.close();return filesize;}
};
Main.cc文件
创建Http智能指针,调用Http的Start函数。
#include "Http.hpp"// http port
int main(int argc, char *argv[])
{if(argc != 2){std::cout << "Usage: " << argv[0] << " port" << std::endl;exit(USAGE_ERR);}uint16_t port = std::stoi(argv[1]);std::unique_ptr<Http> httpsvr = std::make_unique<Http>(port);httpsvr->Start();return 0;
}流程:
在main里创建了httpsvr并调用了start函数,在创建类对象Http时会调用Http的构造函数,初始化了tsvrp,是一个指向TcpServer类的智能指针,并且传入了端口号,而创建TcpServrer类也会执行构造函数,就会初始化TcpServer类的成员变量信息,得到端口号,套接字和运行状态,会调用Socket类的方法 BuildTcpSocketMethod(_port)来设置sockaddr_in信息之类,Socket类也会执行构造函数初始化_cocket成员变量,Http的Start函数会执行tsvrp->Start函数,Start函数要传入一个回调函数,这个回调函数就是lambda表达式,会执行Http类的HandlerHttpRquest函数,网络的套接字,连接绑定之类的事设置完就会调用这个函数进行处理请求以及处理响应。
注意:
还需要一个wwwroot的目录存放html文件,文件内容由ai生成,然后就可以在浏览器上看到自己的网页,而这之前需要端口开放,在安全组中打开端口8080和其它,就可以在浏览器上看到了。
网络请求的完整性这里没写,可以根据报头的信息得到内容大小,在读取这么多的大小就可以获取到请求。


详解)



