当我们部署了大模型并对外提供服务时,我们通常都想了解一下大模型能够支持多少个并发访问,在不同的并发数下,模型的性能如何。了解这些信息有助于我们更好的对算力进行评估,为用户带来更好的性能体验。
大模型通常是通过API接口的方式对外提供访问,因此在做性能测试的时候,很自然的我们会想到通过设置并发调用接口来衡量模型的性能。Python有一个很好的做性能测试的库叫做Locust,这是一个开源的性能测试框架,专为模拟高并发用户负载而设计。它以轻量级、灵活性和分布式扩展能力著称,允许开发者通过编写纯Python代码定义测试场景,并通过Web界面实时监控系统性能表现。Locust 使用gevent 库实现协程(coroutine),避免了传统线程/进程的资源调度开销,单台机器可模拟数千并发用户,这种非阻塞I/O模型使其在高并发场景下效率显著优于JMeter等工具。
通常衡量大模型的性能有两个指标,一个是TTFT,即首Token生成时间,测量模型从收到用户请求到生成回复的第一个Token的时间。另一个指标是TPUT,衡量模型每秒生成Token的数量。
首先我先启动一个大模型,通过VLLM来启动模型的服务化接口,VLLM提供了OpenAI兼容的API格式。
然后编写一个python程序llm_test.py,代码如下:
from locust import HttpUser, task
from openai import OpenAI
import timeclass OpenAIChatUser(HttpUser):host = "http://localhost:8000/v1" def __init__(self, *args, **kwargs):super().__init__(*args, **kwargs)self.client = OpenAI(api_key="sk-your-api-key",base_url=self.host)@taskdef test_streaming_api(self):start_time = time.time()first_token_received = Falsetokens = 0try:stream = self.client.chat.completions.create(model="Qwen2.5-3B-Instruct-AWQ",messages=[{"role": "user", "content": "解释量子纠缠"}],stream=True)for chunk in stream:# 检测首个有效Tokenif chunk.choices[0].delta.content:if not first_token_received:first_token_time = time.time() - start_timefirst_token_received = Trueself.environment.events.request.fire(request_type="TTFT",name="first_token",response_time=first_token_time * 1000, # 转毫秒response_length=1)# 统计Token总数tokens += len(chunk.choices[0].delta.content.split())# 记录总耗时与吞吐量total_time = time.time() - start_timeself.environment.events.request.fire(request_type="TPUT",name="throughput",response_time=tokens / total_time,response_length=tokens # tokens/s)except Exception as e:self.environment.events.request.fire(request_type="ERROR",name="stream_error",response_time=0,exception=e)以上代码中,定义一个继承HttpUser的类,@task装饰器定义了一个测试的任务。self.environment.events.request.fire表示当一个Http Request执行完毕后触发的事件。这里定义了两个Request事件,分别代表TTFT和TPUT。
这里只是简单的一个测试,我们可以改进一下,例如输入不同字数的文章,让大模型进行文章摘要,测试在不同的输入长度下的性能。
运行以下命令
locust -f llm_test.py然后打开locust的web界面,在界面中启动测试,我们可以选择模拟多少并发用户数,以及测试多长时间,如下图:
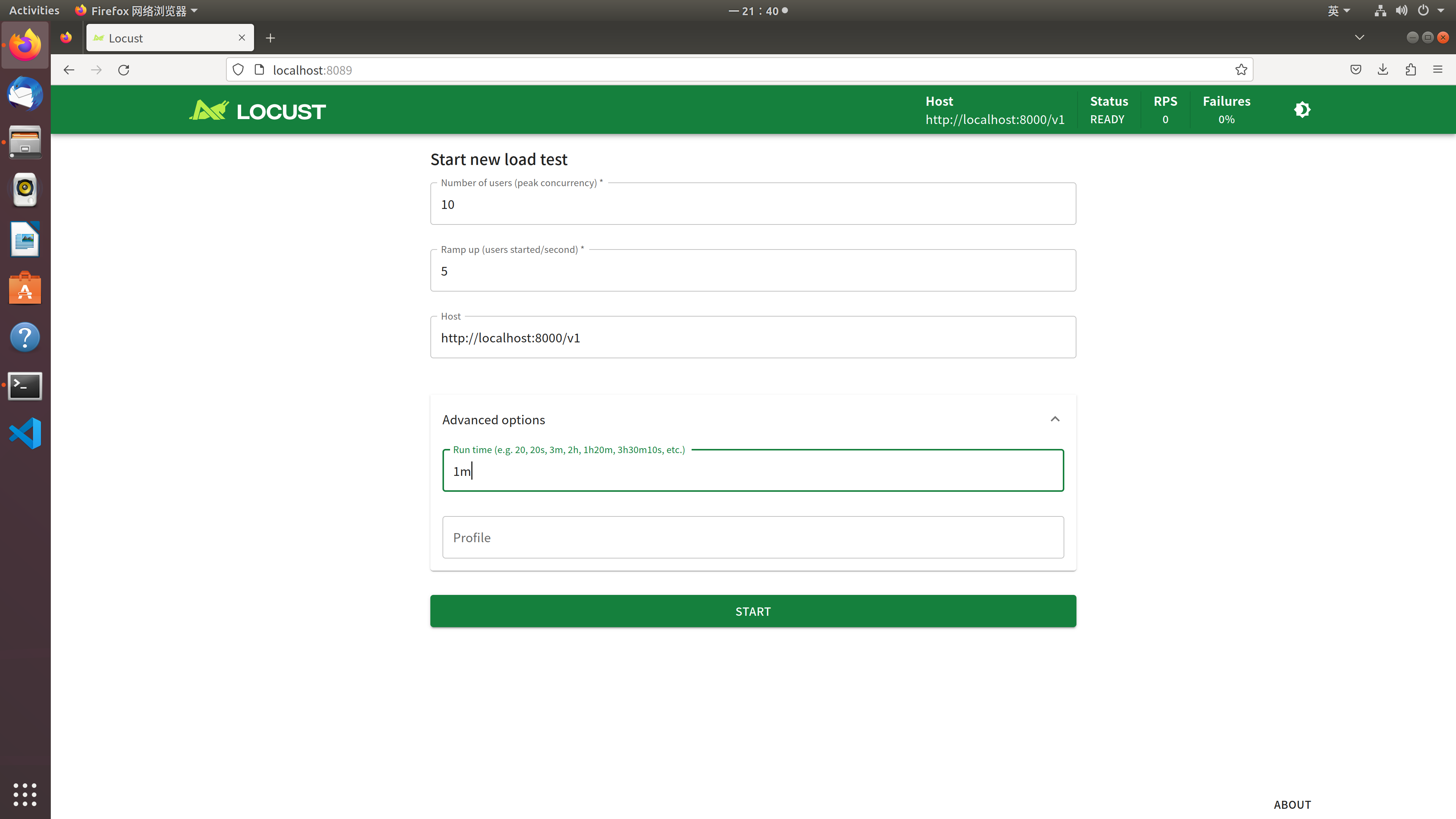
这里设置了模拟10个并发用户访问,每秒增加5个用户,测试1分钟。
测试结果如下:
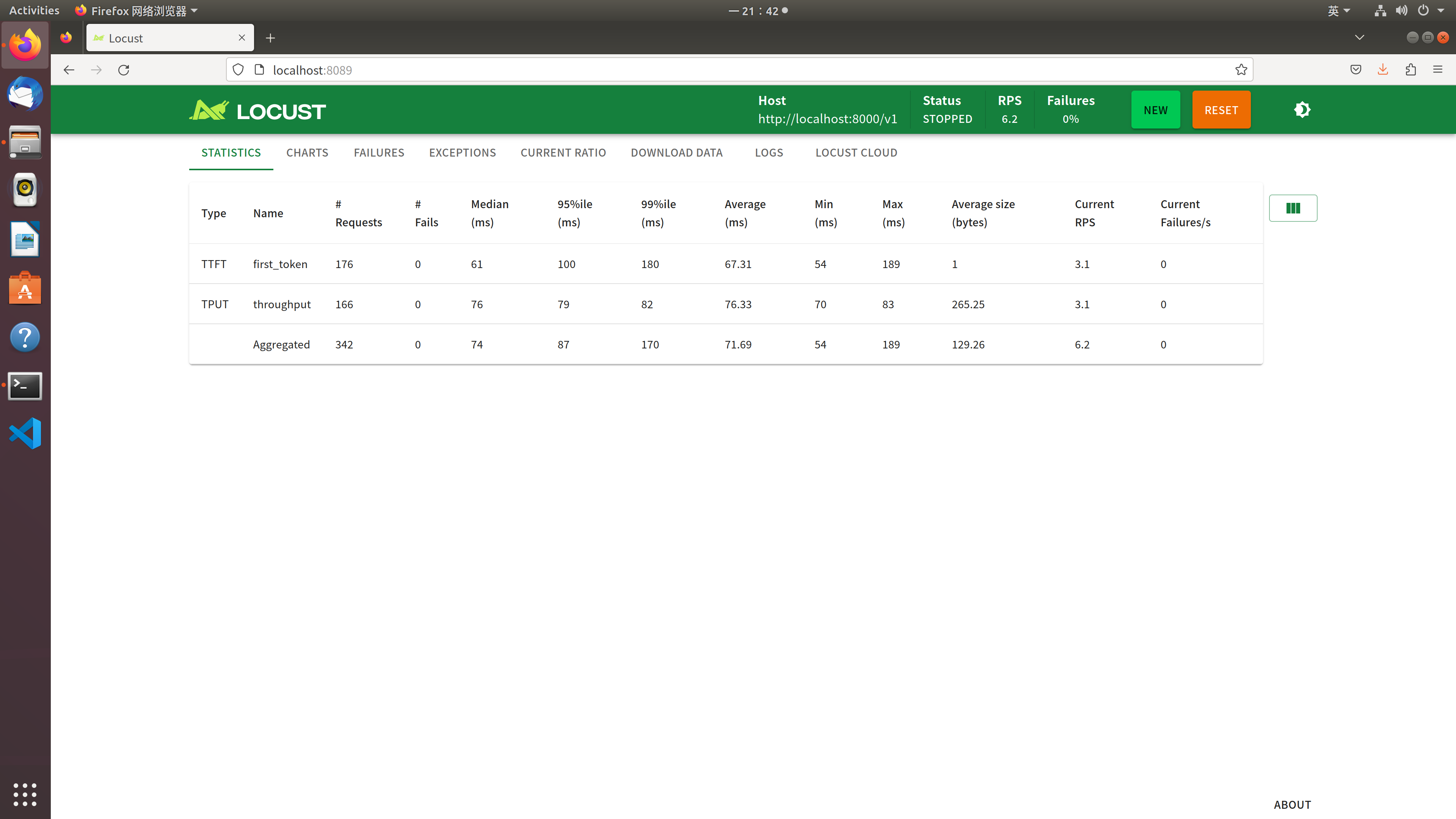
可见在10个用户并发访问下,首Token平均生成时间为67ms, 每秒生成Token的Throughput为70个。
修改测试条件,模拟20个用户并发访问,每秒增加5个用户,测试1分钟,测试结果如下:
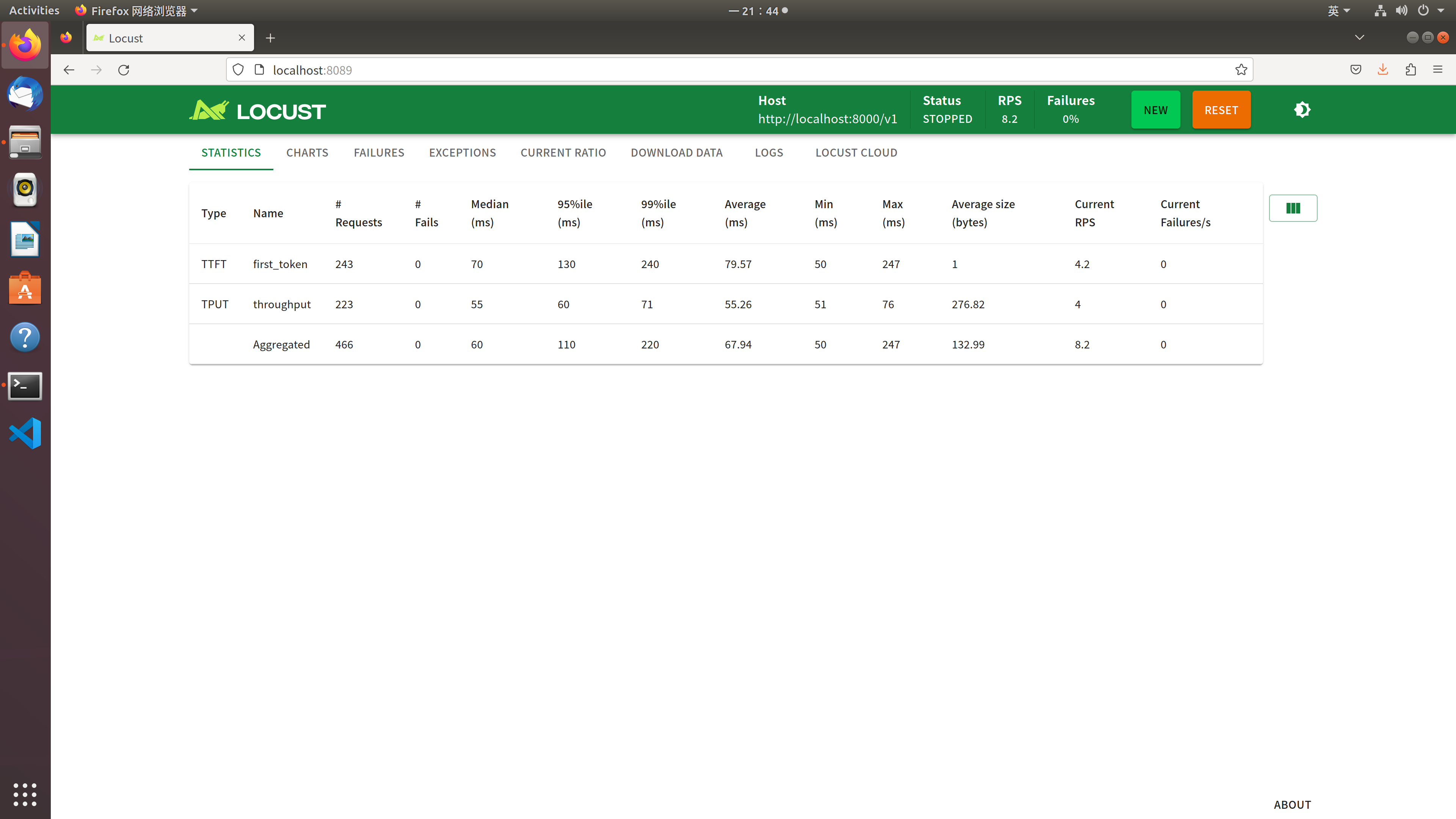
可见在20个用户并发访问下,首Token平均生成时间为79ms, 每秒生成Token的Throughput为55个。
通过Locust,可以快速的帮助我们了解大模型的性能。

: 深入剖析 PCA9450 驱动如何接入 regulator 子系统)



