文章目录
- CAT-ViL: Co-attention Gated Vision-Language Embedding for Visual Question Localized-Answering in Robotic Surgery
- 摘要
- 方法
- 实验结果
CAT-ViL: Co-attention Gated Vision-Language Embedding for Visual Question Localized-Answering in Robotic Surgery
摘要
- 医学生和初级外科医生经常依赖于资深外科医生和专家来回答他们在学习手术过程中的问题,但专家通常忙于临床和学术工作,很难提供指导。
- 现有基于深度学习的外科视觉问题回答(VQA)系统只能提供简单的答案,而无法给出答案的位置信息。同时,视觉-语言(ViL)嵌入在这类任务中也鲜有研究。
- 因此,一个能够提供视觉问题定位回答(VQLA)的系统对于医学生和初级外科医生学习和理解手术视频会很有帮助。
论文提出了一种基于端到端Transformer的CAT-ViL (Co-Attention gaTed Vision-Language)嵌入模型用于外科VQLA任务,不需要通过检测模型进行特征提取。
代码地址
方法

实验结果
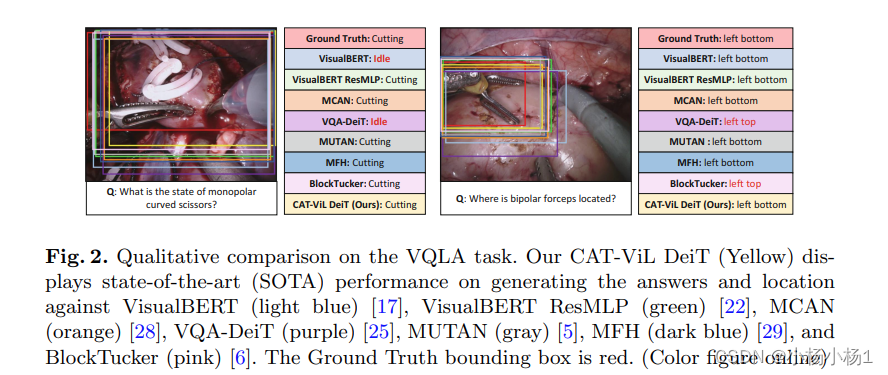
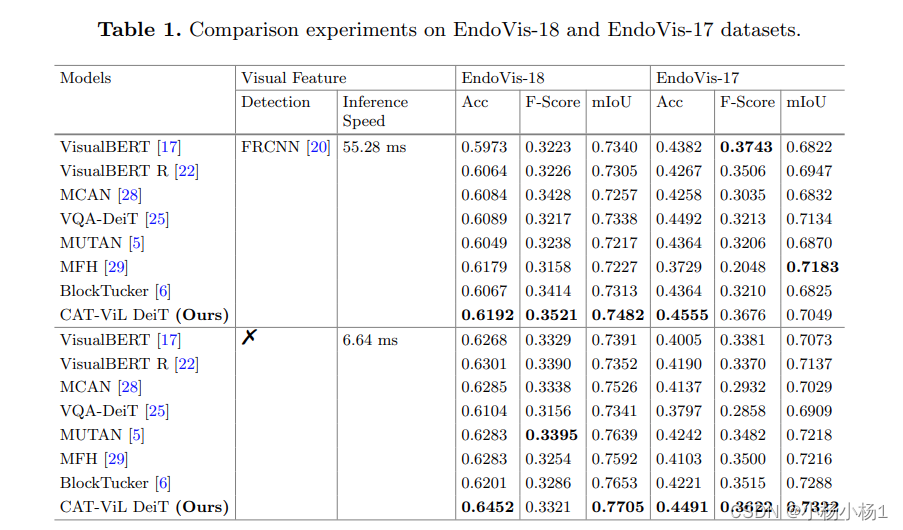
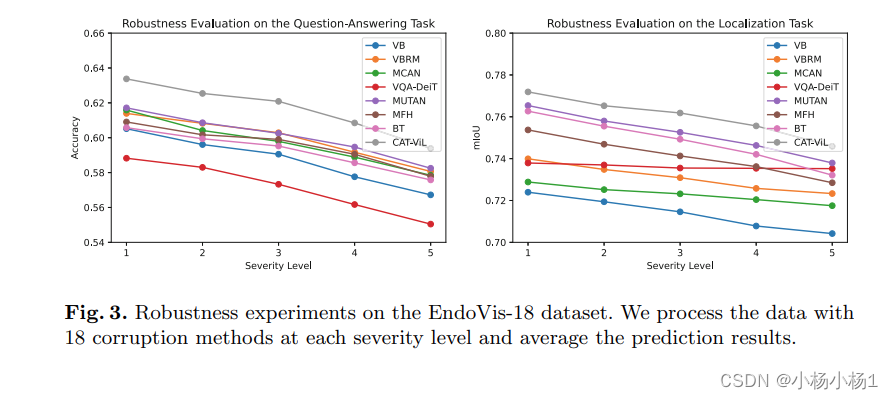
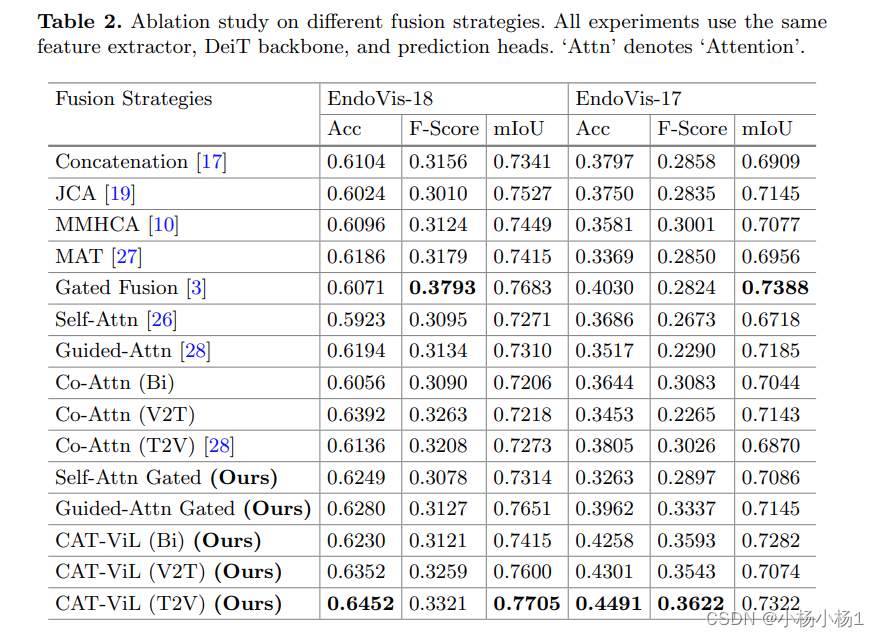
![洛谷题单2-P1046 [NOIP 2005 普及组] 陶陶摘苹果-python-流程图重构](http://pic.xiahunao.cn/nshx/洛谷题单2-P1046 [NOIP 2005 普及组] 陶陶摘苹果-python-流程图重构)




【本期题目:回文数组,挖矿】)
