文章目录
- 前言
- 注册驱动
- 连接器
- 创建连接
- 交互协议
- 读写数据
- 读数据
- 写数据
- mysqlConn
- context超时控制
- 查询
- 发送查询请求
- 读取查询响应
- Exec
- 发送exec请求
- 读取响应
- 预编译
- 客户端预编译
- 服务端预编译
- 生成prepareStmt
- 执行查询操作
- 执行Exec操作
- 事务
- 读取响应
- query响应
- exec响应
- 总结
前言
go-sql-driver/mysql 的核心功能是,实现 database/sql/driver 中定义的接口,提供mysql版本的驱动实现,主要完成以下功能:
- 根据交互协议,完成往mysql server发送请求和解析响应的具体操作
- 执行客户端预编译操作
驱动需要实现的接口,和接口之间的关系如下:

本文阅读源码:https://github.com/go-sql-driver/mysql,版本:v1.8.1
注册驱动
要使用mysql驱动,首先需要注册驱动,注册方式如下:
import ( // 注册驱动_ "github.com/go-sql-driver/mysql"
)
这个包会用通过init函数注册驱动:
var driverName = "mysql"func init() {if driverName != "" {sql.Register(driverName, &MySQLDriver{})}
}
往database/sql包的map全局变量注册驱动:
func Register(name string, driver driver.Driver) {driversMu.Lock()defer driversMu.Unlock()if driver == nil {panic("sql: Register driver is nil")}if _, dup := drivers[name]; dup {panic("sql: Register called twice for driver " + name)}// 注册drivers[name] = driver
}
这样sql.Open("mysql", XXX)时就能根据mysql的driver生成connecter,然后创建sql.DB实例
连接器
继续看sql.Open方法:
func Open(driverName, dataSourceName string) (*DB, error) {// 校验驱动是否注册driversMu.RLock() driveri, ok := drivers[driverName] driversMu.RUnlock() if !ok { return nil, fmt.Errorf("sql: unknown driver %q (forgotten import?)", driverName) } // mysql的驱动会命中这个分支if driverCtx, ok := driveri.(driver.DriverContext); ok { connector, err := driverCtx.OpenConnector(dataSourceName) if err != nil { return nil, err } return OpenDB(connector), nil } return OpenDB(dsnConnector{dsn: dataSourceName, driver: driveri}), nil
}
MySQLDriver实现了driver.DriverContext接口,根据dsn解析出配置,生成driver.Connector实例,让sql.DB持有
func (d MySQLDriver) OpenConnector(dsn string) (driver.Connector, error) { cfg, err := ParseDSN(dsn) if err != nil { return nil, err } return newConnector(cfg), nil
}
newConnector:让connector持有cfg配置
func newConnector(cfg *Config) *connector { encodedAttributes := encodeConnectionAttributes(cfg) return &connector{ cfg: cfg, encodedAttributes: encodedAttributes, }
}
config里有各种配置,例如:
- 账号密码,连接地址
- 超时配置:连接超时时间
Timeout,读超时时间ReadTimeout,写超时时间WriteTimeout - 是否开启客户端预编译:
InterpolateParams
完整的配置如下:
type Config struct { // non boolean fields User string // Username Passwd string // Password (requires User) Net string // Network (e.g. "tcp", "tcp6", "unix". default: "tcp") Addr string // Address (default: "127.0.0.1:3306" for "tcp" and "/tmp/mysql.sock" for "unix") DBName string // Database name Params map[string]string // Connection parameters ConnectionAttributes string // Connection Attributes, comma-delimited string of user-defined "key:value" pairs Collation string // Connection collation Loc *time.Location // Location for time.Time values MaxAllowedPacket int // Max packet size allowed ServerPubKey string // Server public key name TLSConfig string // TLS configuration name TLS *tls.Config // TLS configuration, its priority is higher than TLSConfig Timeout time.Duration // Dial timeout ReadTimeout time.Duration // I/O read timeout WriteTimeout time.Duration // I/O write timeout Logger Logger // Logger // boolean fields AllowAllFiles bool // Allow all files to be used with LOAD DATA LOCAL INFILE AllowCleartextPasswords bool // Allows the cleartext client side plugin AllowFallbackToPlaintext bool // Allows fallback to unencrypted connection if server does not support TLS AllowNativePasswords bool // Allows the native password authentication method AllowOldPasswords bool // Allows the old insecure password method CheckConnLiveness bool // Check connections for liveness before using them ClientFoundRows bool // Return number of matching rows instead of rows changed ColumnsWithAlias bool // Prepend table alias to column names InterpolateParams bool // Interpolate placeholders into query string MultiStatements bool // Allow multiple statements in one query ParseTime bool // Parse time values to time.Time RejectReadOnly bool // Reject read-only connections // unexported fields. new options should be come here beforeConnect func(context.Context, *Config) error // Invoked before a connection is established pubKey *rsa.PublicKey // Server public key timeTruncate time.Duration // Truncate time.Time values to the specified duration}
例如客户端预编译参数interpolateParams:
- 如果dsn中有
interpolateParams=true参数,就会被解析到cfg.InterpolateParams中,值为true - cfg被connector持有
- 用connector新建连接时,将cfg传给
mysqlConn - 用该连接查询时,如果
cfg.InterpolateParams=true,就会启用客户端预编译
创建连接
根据上一篇文章的分析,sql包要新建连接时,都调Connector.Connect方法
- 和mysql服务器建立连接,类型为
net.TCPConn - 创建读缓冲区
- 设置读写超时时间
- 处理握手,鉴权,不是本文的重点,这里省略
func (c *connector) Connect(ctx context.Context) (driver.Conn, error) {var err errorcfg := c.cfg// ...// New mysqlConnmc := &mysqlConn{maxAllowedPacket: maxPacketSize,maxWriteSize: maxPacketSize - 1,closech: make(chan struct{}),// 使用cfgcfg: cfg,connector: c,}mc.parseTime = mc.cfg.ParseTime// Connect to ServerdialsLock.RLock()dial, ok := dials[mc.cfg.Net]dialsLock.RUnlock()if ok {// ...} else {// 设置建立连接的timeout = cfg.Timeoutnd := net.Dialer{Timeout: mc.cfg.Timeout}// 创建net.Conn类型的连接mc.netConn, err = nd.DialContext(ctx, mc.cfg.Net, mc.cfg.Addr)}if err != nil {return nil, err}mc.rawConn = mc.netConn// Enable TCP Keepalives on TCP connectionsif tc, ok := mc.netConn.(*net.TCPConn); ok {// 设为长连接if err := tc.SetKeepAlive(true); err != nil {c.cfg.Logger.Print(err)}}// Call startWatcher for context support (From Go 1.8)mc.startWatcher()if err := mc.watchCancel(ctx); err != nil {mc.cleanup()return nil, err}defer mc.finish()// 创建缓冲区mc.buf = newBuffer(mc.netConn)// 设置读写超时时间mc.buf.timeout = mc.cfg.ReadTimeoutmc.writeTimeout = mc.cfg.WriteTimeout// 处理握手,鉴权,这里忽略// Handle DSN Paramserr = mc.handleParams()if err != nil {mc.Close()return nil, err}return mc, nil
}
交互协议

mysql client和mysql server采用特殊的交互协议:每个报文的结构如下:
- 前3字节为数据包长度,也就是每个报文最多传输
2^24 = 16MB的数据。如果一次请求或响应需要传输的数据量超过这个大小,需要拆分成多个报文传输 - 第4个字节为序列号sequence,每次读写之前都会对
sequence+1,接收到mysql server的响应后,检查报文里的sequence是否和本地相同 - 第5个字节:
- 读:表示mysql server返回的响应状态,0为成功,255为出错
- 写:表示client本次请求的类型,例如Query,Ping,Prepare
- 剩下的字节:报文数据
读写数据
接下来看mysql client如何根据通信协议和mysql server交互,也就是如何读写数据
读数据

readPacket用于读一个完整的数据包:
由于每个报文有3个字节表示数据长度,也就是最多表示2^24个字节=16MB,如果数据包超过这个字节数,就要多次读取报文。最后一个报文的长度为0表示数据读完了
func (mc *mysqlConn) readPacket() ([]byte, error) {var prevData []bytefor {// 先读头部的4个字节data, err := mc.buf.readNext(4)if err != nil {// ...return nil, ErrInvalidConn}// 前3个字节为包的长度pktLen := int(uint32(data[0]) | uint32(data[1])<<8 | uint32(data[2])<<16)// 第4个字节为序列号,必须要和本地的序列号一致if data[3] != mc.sequence {mc.Close()if data[3] > mc.sequence {return nil, ErrPktSyncMul}return nil, ErrPktSync}// 本地序列号自增mc.sequence++// 包长度为0,代表终结上一次的读取,上一次的读取很长if pktLen == 0 {// there was no previous packetif prevData == nil {mc.log(ErrMalformPkt)mc.Close()return nil, ErrInvalidConn}// 返回之前读取的数据return prevData, nil}// 读pktLen长度的数据data, err = mc.buf.readNext(pktLen)if err != nil {if cerr := mc.canceled.Value(); cerr != nil {return nil, cerr}mc.log(err)mc.Close()return nil, ErrInvalidConn}// 包长度小于最大长度,说明读一次就行if pktLen < maxPacketSize {// zero allocationsfor non-split packetsif prevData == nil {return data, nil}return append(prevData, data...), nil}// 否则需要读多次,先把这次读到的暂存起来prevData = append(prevData, data...)}
}
缓冲区buffer定义如下:
type buffer struct {// 都缓冲区buf []byte // 缓冲区数据不够时,从什么连接读数据nc net.Conn// 下次从哪开始读idx int// 还剩多少个字节未读length int// 读超时时间timeout time.Duration// ...
}
readNext:从buffer中读need个字节
func (b *buffer) readNext(need int) ([]byte, error) {// 剩余字节数不够本次要读的if b.length < need {// 调fill从连接中读到缓冲区if err := b.fill(need); err != nil {return nil, err}}// 从offset开始读offset := b.idx// 更新idxb.idx += need// 还能读的字节数减少b.length -= needreturn b.buf[offset:b.idx], nil
}
当缓冲区中字节数不够时,调fill填充:
- 如果buf不够need,扩容
- 将buf中还能读的部分,拷贝到开头
- 每次读之前,设置读超时时间
- 调net.Conn的Read方法,把数据读到缓冲区中
func (b *buffer) fill(need int) error {n := b.length// 如果flipcnt一直是0,那就一直用第一个bufdest := b.dbuf[b.flipcnt&1]// 如果buf不够need,扩容if need > len(dest) {// 容量按照4096的整数倍向上对齐dest = make([]byte, ((need/defaultBufSize)+1)*defaultBufSize)// 如果新分配的buf不是太大,就放到下一个buf中if len(dest) <= maxCachedBufSize {b.dbuf[b.flipcnt&1] = dest}}if n > 0 {// 将buf中还能读的部分,拷贝到开头copy(dest[:n], b.buf[b.idx:])}b.buf = destb.idx = 0for {if b.timeout > 0 {// 每次读之前,设置读超时时间if err := b.nc.SetReadDeadline(time.Now().Add(b.timeout)); err != nil {return err}}// 从连接中读数据,写到n开始的位置nn, err := b.nc.Read(b.buf[n:])n += nnswitch err {case nil:// 如果还读到需要的字节数,继续读if n < need {continue}b.length = nreturn nilcase io.EOF:if n >= need {b.length = nreturn nil}return io.ErrUnexpectedEOFdefault:return err}}
}
写数据

往mysql server写数据没用缓冲区,直接往连接写。如果一次写不完,拆分成多个报文写
func (mc *mysqlConn) writePacket(data []byte) error {// 包长度pktLen := len(data) - 4// mc.maxAllowedPacket为配置的最大包长度if pktLen > mc.maxAllowedPacket {return ErrPktTooLarge}for {var size int// 前3个字节为包长度if pktLen >= maxPacketSize {data[0] = 0xffdata[1] = 0xffdata[2] = 0xffsize = maxPacketSize} else {data[0] = byte(pktLen)data[1] = byte(pktLen >> 8)data[2] = byte(pktLen >> 16)size = pktLen}// 第4个字节为序列号data[3] = mc.sequence// 设置本次的写超时if mc.writeTimeout > 0 {if err := mc.netConn.SetWriteDeadline(time.Now().Add(mc.writeTimeout)); err != nil {return err}}// 执行写操作n, err := mc.netConn.Write(data[:4+size])if err == nil && n == 4+size {// 写完了,序列号++mc.sequence++if size != maxPacketSize {return nil}// 接着写下一个包pktLen -= sizedata = data[size:]continue}// 处理错误return ErrInvalidConn}
}
mysqlConn
mysqlConn实现了driver.Conn接口:
type Conn interface {// 预编译Prepare(query string) (Stmt, error)Close() error// 开启事务Begin() (Tx, error)
}
mysqlConn字段如下:
type mysqlConn struct {// 缓冲区buf buffer// TCP连接netConn net.ConnrawConn net.Conn // underlying connection when netConn is TLS connection.// sql执行结果result mysqlResult // managed by clearResult() and handleOkPacket().// 连接相关配置cfg *Config// 由哪个连接器创建的connector *connectormaxAllowedPacket intmaxWriteSize int// 一次写报文的超市时间writeTimeout time.Duration// 客户端状态标识flags clientFlag// 服务端状态标识status statusFlag// 序列号sequence uint8parseTime bool// for context support (Go 1.8+)watching boolwatcher chan<- context.Contextclosech chan struct{}finished chan<- struct{}canceled atomicError // set non-nil if conn is canceledclosed atomicBool // set when conn is closed, before closech is closed
}
context超时控制
每个mysqlConn会启动一个Watcher,用于监听一旦ctx的Done后,关闭tcp连接
func (mc *mysqlConn) startWatcher() { watcher := make(chan context.Context, 1) mc.watcher = watcher finished := make(chan struct{}) mc.finished = finished go func() { for { var ctx context.Context select { // 从watcher接受一个ctxcase ctx = <-watcher: case <-mc.closech: return } select { case <-ctx.Done(): // ctx.Done后,关闭连接mc.cancel(ctx.Err()) case <-finished: case <-mc.closech: return } } }()
}
mysqlConn.cancal
func (mc *mysqlConn) cancel(err error) { mc.canceled.Set(err) mc.cleanup()
}func (mc *mysqlConn) cleanup() { if mc.closed.Swap(true) { return } // Makes cleanup idempotent close(mc.closech) conn := mc.rawConn if conn == nil { return } // 关闭底层tcp连接if err := conn.Close(); err != nil { mc.log(err) }
}
那啥时候往mc.watcher推ctx呢?每次调QueryContext,ExecContext时,将参数传入的ctx推给后台watcher,后台监听这个ctx的Done信号。如果sql执行超时,会关闭tcp连接
通过这种方式来实现ctx的超时控制
查询
当调用sql.DB的QueryContext方法时,如果驱动的连接实现了driver.QueryerContext接口,会转化为调该接口的QueryContext方法,而mysql驱动 mysqlConn实现了该接口:
func (mc *mysqlConn) QueryContext(ctx context.Context, query string, args []driver.NamedValue) (driver.Rows, error) { dargs, err := namedValueToValue(args) if err != nil { return nil, err } // 将ctx通过channel推给后台go,监控ctx的退出if err := mc.watchCancel(ctx); err != nil { return nil, err } // 执行查询rows, err := mc.query(query, dargs) if err != nil { mc.finish() return nil, err } rows.finish = mc.finish return rows, err
}
发送查询请求
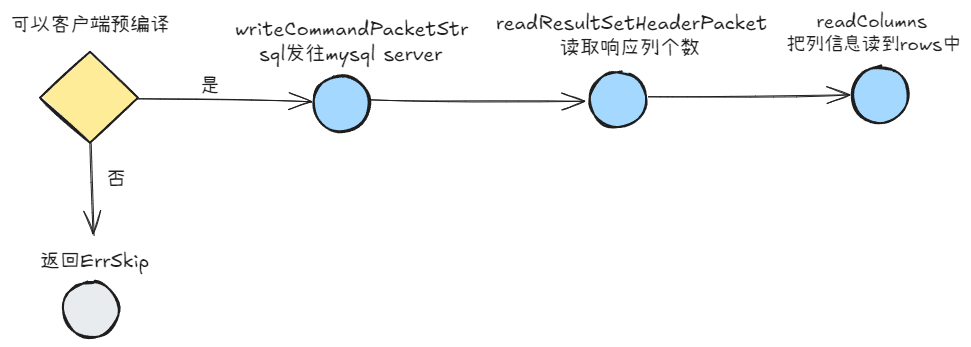
query:执行查询
- 如果有参数:
- 如果不允许客户端预编译,返回
driver.ErrSkip,让sql.DB走服务端预编译 - 否则执行客户端预编译
- 如果不允许客户端预编译,返回
- 将命令封装成符合交互协议的报文格式,发送到mysql server
- 读取响应结果,也就是列的信息
// query:sql模板,args:占位符
func (mc *mysqlConn) query(query string, args []driver.Value) (*textRows, error) {handleOk := mc.clearResult()if mc.closed.Load() {mc.log(ErrInvalidConn)return nil, driver.ErrBadConn}// 有参数if len(args) != 0 {// 如果不允许客户端预编译,返回driver.ErrSkip,让sql.DB走服务端预编译if !mc.cfg.InterpolateParams {return nil, driver.ErrSkip}// 尝试客户端的预编译,以减少网络消耗prepared, err := mc.interpolateParams(query, args)if err != nil {return nil, err}query = prepared}// 将sql发到服务端err := mc.writeCommandPacketStr(comQuery, query)if err == nil {// Read Resultvar resLen int// 读取列的个数resLen, err = handleOk.readResultSetHeaderPacket()if err == nil {rows := new(textRows)rows.mc = mcif resLen == 0 {rows.rs.done = trueswitch err := rows.NextResultSet(); err {case nil, io.EOF:return rows, nildefault:return nil, err}}// 读resLen个列信息到rows.rs.columns中rows.rs.columns, err = mc.readColumns(resLen)return rows, err}}return nil, mc.markBadConn(err)
}
将命令write到mysql server:
- 计算数据包长度,加上报文头部的长度,申请空间data
- 将数据拷贝到data中
- 一次性或分批写到mysql server
func (mc *mysqlConn) writeCommandPacketStr(command byte, arg string) error {// Reset Packet Sequencemc.sequence = 0// 数据包的长度=1 + len(arg)pktLen := 1 + len(arg)// 申请一块buf,尝试复用已经申请好的,长度为pktLen再加4,也就是加上报文头部的长度data, err := mc.buf.takeBuffer(pktLen + 4)if err != nil {mc.log(err)return errBadConnNoWrite}// 第4个字节为请求类型data[4] = command// 追加上argcopy(data[5:], arg)// 一次性或分批写到mysql serverreturn mc.writePacket(data)
}
读取查询响应
读取响应结果:
对query的响应来说,返回列的个数
func (mc *okHandler) readResultSetHeaderPacket() (int, error) {// handleOkPacket replaces both values; other cases leave the values unchanged.mc.result.affectedRows = append(mc.result.affectedRows, 0)mc.result.insertIds = append(mc.result.insertIds, 0)// 读一个响应包data, err := mc.conn().readPacket()if err == nil {switch data[0] {// data[0]=0代表响应成功,Exec函数会走到这,下文再分析case iOK:return 0, mc.handleOkPacket(data)case iERR:return 0, mc.conn().handleErrorPacket(data)case iLocalInFile:return 0, mc.handleInFileRequest(string(data[1:]))}// 查询走这// data[0]是其他值的话,从data里读取列的个数num, _, _ := readLengthEncodedInteger(data)return int(num), nil}return 0, err
}
先看两个小方法:如何从mysql server响应的字节流中读取一个数字,读一个字符串
readLengthEncodedInteger:从响应结果b里解析一个数字,返回数字本身,是否为null,数字占用多少个字节
根据b[0]的值不同,分3种情况处理:
- b[0]是251,说明结果是null
- b[0]是为0~250,那么b[0] 就是接下来的数字
- 否则数字由多个字节组成,根据b[0]的值使用的不同的解析方式
func readLengthEncodedInteger(b []byte) (uint64, bool, int) { // See issue #349 if len(b) == 0 { return 0, true, 1 } switch b[0] { // 251: NULL case 0xfb: return 0, true, 1 // 252: value of following 2 case 0xfc: return uint64(b[1]) | uint64(b[2])<<8, false, 3 // 253: value of following 3 case 0xfd: return uint64(b[1]) | uint64(b[2])<<8 | uint64(b[3])<<16, false, 4 // 254: value of following 8 case 0xfe: return uint64(b[1]) | uint64(b[2])<<8 | uint64(b[3])<<16 | uint64(b[4])<<24 | uint64(b[5])<<32 | uint64(b[6])<<40 | uint64(b[7])<<48 | uint64(b[8])<<56, false, 9 } // 0-250: value of first byte return uint64(b[0]), false, 1
}
readLengthEncodedString:从字节流b中读取一个字符串。先读一个数字num代表字符串的长度,然后读num个字节,就是字符串本身
func readLengthEncodedString(b []byte) ([]byte, bool, int, error) { // Get length num, isNull, n := readLengthEncodedInteger(b) if num < 1 { return b[n:n], isNull, n, nil } n += int(num) // Check data length if len(b) >= n { return b[n-int(num) : n : n], false, n, nil } return nil, false, n, io.EOF
}
现在有了列的个数,再从连接中读取mysql server返回的列的详情:
每个列有这些信息:
type mysqlField struct { tableName string name string length uint32 flags fieldFlag fieldType fieldType decimals byte charSet uint8
}
mysqlConn.readColumns要干的事就是从连接中的字节流中读取并解析数据,为mysqlField的每个字段赋值
整体来说就是对每个字段都读一个报文,解析报文中的字节流到mysqlField中
func (mc *mysqlConn) readColumns(count int) ([]mysqlField, error) { columns := make([]mysqlField, count) for i := 0; ; i++ { // 读一个报文 data, err := mc.readPacket() if err != nil { return nil, err } // 读完了,返回 if data[0] == iEOF && (len(data) == 5 || len(data) == 1) { if i == count { return columns, nil } return nil, fmt.Errorf("column count mismatch n:%d len:%d", count, len(columns)) } // Catalog pos, err := skipLengthEncodedString(data) if err != nil { return nil, err } // ... 跳过一些字节// 读列名name, _, n, err := readLengthEncodedString(data[pos:]) if err != nil { return nil, err } columns[i].name = string(name) pos += n // ... 跳过一些字节// Filler [uint8] pos++ // 读charset columns[i].charSet = data[pos] pos += 2 // 读length columns[i].length = binary.LittleEndian.Uint32(data[pos : pos+4]) pos += 4 // 读字段类型 columns[i].fieldType = fieldType(data[pos]) pos++ // Flags [uint16] columns[i].flags = fieldFlag(binary.LittleEndian.Uint16(data[pos : pos+2])) pos += 2 // Decimals [uint8] columns[i].decimals = data[pos]
}
Exec
当调用sql.DB的ExecContext方法时,如果驱动的连接实现了driver.ExecerContext接口,会转化为调该接口的ExecContext方法,而mysql驱动 mysqlConn实现了该接口:
func (mc *mysqlConn) ExecContext(ctx context.Context, query string, args []driver.NamedValue) (driver.Result, error) { dargs, err := namedValueToValue(args) if err != nil { return nil, err } // 监听ctx的退出信号if err := mc.watchCancel(ctx); err != nil { return nil, err } defer mc.finish() return mc.Exec(query, dargs)
}
调mysqlConn.Exec方法
func (mc *mysqlConn) Exec(query string, args []driver.Value) (driver.Result, error) { if mc.closed.Load() { mc.log(ErrInvalidConn) return nil, driver.ErrBadConn } // 客户端预编译相关,和query流程类似if len(args) != 0 { if !mc.cfg.InterpolateParams { return nil, driver.ErrSkip } prepared, err := mc.interpolateParams(query, args) if err != nil { return nil, err } query = prepared } err := mc.exec(query) if err == nil { copied := mc.result return &copied, err } return nil, mc.markBadConn(err)
}
发送exec请求
func (mc *mysqlConn) exec(query string) error { handleOk := mc.clearResult() // 将query发往mysql serverif err := mc.writeCommandPacketStr(comQuery, query); err != nil { return mc.markBadConn(err) } // 处理响应结果resLen, err := handleOk.readResultSetHeaderPacket() if err != nil { return err } // ...
}
读取响应
readResultSetHeaderPacket:读取响应
func (mc *okHandler) readResultSetHeaderPacket() (int, error) { // handleOkPacket replaces both values; other cases leave the values unchanged. mc.result.affectedRows = append(mc.result.affectedRows, 0) mc.result.insertIds = append(mc.result.insertIds, 0) data, err := mc.conn().readPacket() if err == nil { switch data[0] { // 进入这个分支case iOK: return 0, mc.handleOkPacket(data) // ...} return 0, err
}
handleOkPacket:处理OK的响应结果:
就是从字节流中读取本次exec影响的行数affectedRows,上次插入id insertId,保存到连接中,供应用层获取
func (mc *okHandler) handleOkPacket(data []byte) error {var n, m intvar affectedRows, insertId uint64// 影响行数,n代表了几个字节affectedRows, _, n = readLengthEncodedInteger(data[1:])// insertId,m代表读了几个字节insertId, _, m = readLengthEncodedInteger(data[1+n:])if len(mc.result.affectedRows) > 0 {// 保存affectedRowsmc.result.affectedRows[len(mc.result.affectedRows)-1] = int64(affectedRows)}if len(mc.result.insertIds) > 0 {// 保存insertIdmc.result.insertIds[len(mc.result.insertIds)-1] = int64(insertId)}// server_status [2 bytes]mc.status = readStatus(data[1+n+m : 1+n+m+2])if mc.status&statusMoreResultsExists != 0 {return nil}// warning count [2 bytes]return nil
}
预编译
预编译操作是将一个sql模板提前发往mysql server. 后续在该 sql 模板下的多笔操作,只需要将对应的参数发往服务端,即可实现对模板的复用,有以下优点:
- 模板复用:sql 模板一次编译,多次复用,可以提高性能
- 语法安全:模板不变的部分和参数可变的部分隔离,防止sql注入
客户端预编译
客户端预编译只有语法安全的效果,没有模板服用的优点,客户端预编译只有语法安全的效果,没有模板服用的优点,但是能减少和mysql server交互的次数
当配置mysql驱动的参数interpolateParams为true,且没有用预编译时(直接调db.Query,db.Exec),会使用客户端预编译
mysql驱动层面会将query和args拼接成一个完整的sql,怎么防止sql注入?拼接字符串时,在其前后加上\'
客户端预编译函数interpolateParams的代码如下:
- 校验sql中
?的个数要个args的长度相同 - 将每个
?替换成实际的参数。如果参数是字符串,在前后拼接\'
// 客户端预编译
func (mc *mysqlConn) interpolateParams(query string, args []driver.Value) (string, error) {// ?的个数要个args的长度相同if strings.Count(query, "?") != len(args) {return "", driver.ErrSkip}buf, err := mc.buf.takeCompleteBuffer()if err != nil {// can not take the buffer. Something must be wrong with the connectionmc.log(err)return "", ErrInvalidConn}buf = buf[:0]argPos := 0for i := 0; i < len(query); i++ {// 下一个?的位置q := strings.IndexByte(query[i:], '?')// 后面没有?了,跳出循环if q == -1 {buf = append(buf, query[i:]...)break}// 拼接上?前面的部分buf = append(buf, query[i:i+q]...)i += qarg := args[argPos]argPos++// 对应arg如果是nil,拼接NULLif arg == nil {buf = append(buf, "NULL"...)continue}switch v := arg.(type) {// 参数为其他类型// 重点在这,如果对应arg是字符串,在其前后拼接上 ' case string:buf = append(buf, '\'')if mc.status&statusNoBackslashEscapes == 0 {buf = escapeStringBackslash(buf, v)} else {// 将v写进去buf = escapeStringQuotes(buf, v)}buf = append(buf, '\'')default:return "", driver.ErrSkip}if len(buf)+4 > mc.maxAllowedPacket {return "", driver.ErrSkip}}if argPos != len(args) {return "", driver.ErrSkip}return string(buf), nil
}
服务端预编译
生成prepareStmt
通过mysqlConn.Prepare得到
func (mc *mysqlConn) Prepare(query string) (driver.Stmt, error) {if mc.closed.Load() {mc.log(ErrInvalidConn)return nil, driver.ErrBadConn}// Send command// 将sql模板发往mysql servererr := mc.writeCommandPacketStr(comStmtPrepare, query)if err != nil {// STMT_PREPARE is safe to retry. So we can return ErrBadConn here.mc.log(err)return nil, driver.ErrBadConn}// 构造mysqlStmt实例stmt := &mysqlStmt{mc: mc,}// 读取prepare响应,主要获得statmentId,由mysql server生成返回columnCount, err := stmt.readPrepareResultPacket()if err == nil {if stmt.paramCount > 0 {if err = mc.readUntilEOF(); err != nil {return nil, err}}if columnCount > 0 {err = mc.readUntilEOF()}}return stmt, err
}
mysqlStmt如下:
type mysqlStmt struct {// 关联的mysqlConnmc *mysqlConn// mysql server返回的stmtIdid uint32// 参数个数paramCount int
}
读prepare的响应,获得statmentId
func (stmt *mysqlStmt) readPrepareResultPacket() (uint16, error) {// 都一个报文data, err := stmt.mc.readPacket()if err == nil {// packet indicator [1 byte]if data[0] != iOK {return 0, stmt.mc.handleErrorPacket(data)}// 前4个字节为 statement id,保存到stmt实例里stmt.id = binary.LittleEndian.Uint32(data[1:5])// Column count [16 bit uint]columnCount := binary.LittleEndian.Uint16(data[5:7])// 保存sql模板中的参数个数,用于driverStmt.NumInput方法stmt.paramCount = int(binary.LittleEndian.Uint16(data[7:9]))return columnCount, nil}return 0, err
}
拿到stmt后,看看怎么基于stmt执行query和exec操作
执行查询操作
mysqlStmt实现driver.StmtQueryContext接口方法,只用传参数即可
func (stmt *mysqlStmt) QueryContext(ctx context.Context, args []driver.NamedValue) (driver.Rows, error) { dargs, err := namedValueToValue(args) if err != nil { return nil, err } // 将ctx通过channel推给后台go,监听ctx的Doneif err := stmt.mc.watchCancel(ctx); err != nil { return nil, err } rows, err := stmt.query(dargs) if err != nil { stmt.mc.finish() return nil, err } rows.finish = stmt.mc.finish return rows, err
}
mysqlStmt.query
- 将参数发往mysql server
- 读取响应,列的信息,这部分同普通的query流程
func (stmt *mysqlStmt) query(args []driver.Value) (*binaryRows, error) {if stmt.mc.closed.Load() {stmt.mc.log(ErrInvalidConn)return nil, driver.ErrBadConn}// 将参数args发往mysql servererr := stmt.writeExecutePacket(args)if err != nil {return nil, stmt.mc.markBadConn(err)}mc := stmt.mc// Read ResulthandleOk := stmt.mc.clearResult()// 读取列的个数resLen, err := handleOk.readResultSetHeaderPacket()if err != nil {return nil, err}rows := new(binaryRows)if resLen > 0 {rows.mc = mc// 读取列的元数据信息rows.rs.columns, err = mc.readColumns(resLen)} else {rows.rs.done = trueswitch err := rows.NextResultSet(); err {case nil, io.EOF:return rows, nildefault:return nil, err}}return rows, err
}
writeExecutePacket发送参数:
除了报文头部4个字节加操作类型1个字节外,接下来写4个字节的stmtId
然后往字节数组里写参数,对于每个参数来说,先写数据类型,再写数据的值
func (stmt *mysqlStmt) writeExecutePacket(args []driver.Value) error {// 参数个数必须要和预编译返回的参数个数一致if len(args) != stmt.paramCount {return fmt.Errorf("argument count mismatch (got: %d; has: %d)",len(args),stmt.paramCount,)}const minPktLen = 4 + 1 + 4 + 1 + 4mc := stmt.mc// ...// Reset packet-sequencemc.sequence = 0var data []bytevar err error// 复用bufferif len(args) == 0 {data, err = mc.buf.takeBuffer(minPktLen)} else {data, err = mc.buf.takeCompleteBuffer()// In this case the len(data) == cap(data) which is used to optimise the flow below.}if err != nil {// cannot take the buffer. Something must be wrong with the connectionmc.log(err)return errBadConnNoWrite}// 指令类型为stmtExecdata[4] = comStmtExecute// 接下来4个字节设为statmentIddata[5] = byte(stmt.id)data[6] = byte(stmt.id >> 8)data[7] = byte(stmt.id >> 16)data[8] = byte(stmt.id >> 24)// 接下来设一些固定值// flags (0: CURSOR_TYPE_NO_CURSOR) [1 byte]data[9] = 0x00// iteration_count (uint32(1)) [4 bytes]data[10] = 0x01data[11] = 0x00data[12] = 0x00data[13] = 0x00// 往data里填充argsif len(args) > 0 {// ...for i, arg := range args {// 先填充每个arg的类型,再填充每个arg的值}// ...}return mc.writePacket(data)
}
解析响应结果和普通query流程相同,这里不再分析
执行Exec操作
exec操作和query类型,类似只用传stmtId和参数,解析响应的流程和普通exec类似,这里不再分析
事务
sql标准库定义了driver.Tx,供各个驱动实现:
type Tx interface { Commit() error Rollback() error
}
mysql驱动的实现为:
type mysqlTx struct { mc *mysqlConn
}
mysqlConn调Begin生成一个driver.Tx:就是往mysql server发送START TRANSACTION指令
func (mc *mysqlConn) Begin() (driver.Tx, error) {return mc.begin(false)
}func (mc *mysqlConn) begin(readOnly bool) (driver.Tx, error) {if mc.closed.Load() {mc.log(ErrInvalidConn)return nil, driver.ErrBadConn}var q stringif readOnly {q = "START TRANSACTION READ ONLY"} else {q = "START TRANSACTION"}// 将开始事务命令发给mysql servererr := mc.exec(q)if err == nil {// 封装成mysqlTxreturn &mysqlTx{mc}, err}return nil, mc.markBadConn(err)
}
Commit和Rollback方法如下:
就是发送COMMIT和ROLLBACK命令,之后持有的mysqlConn置为空
func (tx *mysqlTx) Commit() (err error) {if tx.mc == nil || tx.mc.closed.Load() {return ErrInvalidConn}err = tx.mc.exec("COMMIT")tx.mc = nilreturn
}func (tx *mysqlTx) Rollback() (err error) {if tx.mc == nil || tx.mc.closed.Load() {return ErrInvalidConn}err = tx.mc.exec("ROLLBACK")tx.mc = nilreturn
}
下面串一下驱动实现的driver.Tx,怎么和sql.Tx配合,实现增删改查操作
我们知道,执行事务上的各种操作一定要在某个固定的连接上,也就是调Begin的那个连接,那sql包是怎么实现的呢?答案就在sql.Tx上
- 开启事务时,调驱动用连接dc.ci创建driver.Tx
- 将连接,driver.Tx绑定到sql.Tx返回
- 之后在Tx上执行exec,query操作,都用Tx上绑定的连接
在db.BeginTx时:
func (db *DB) BeginTx(ctx context.Context, opts *TxOptions) (*Tx, error) { var tx *Tx var err error err = db.retry(func(strategy connReuseStrategy) error { tx, err = db.begin(ctx, opts, strategy) return err }) return tx, err
}
DB.begin
func (db *DB) begin(ctx context.Context, opts *TxOptions, strategy connReuseStrategy) (tx *Tx, err error) { // 从连接池获取一个连接·dc, err := db.conn(ctx, strategy) if err != nil { return nil, err } return db.beginDC(ctx, dc, dc.releaseConn, opts)
}
DB.beginDC
func (db *DB) beginDC(ctx context.Context, dc *driverConn, release func(error), opts *TxOptions) (tx *Tx, err error) { var txi driver.Tx keepConnOnRollback := false withLock(dc, func() { _, hasSessionResetter := dc.ci.(driver.SessionResetter) _, hasConnectionValidator := dc.ci.(driver.Validator) keepConnOnRollback = hasSessionResetter && hasConnectionValidator // 调驱动用连接dc.ci创建driver.Txtxi, err = ctxDriverBegin(ctx, opts, dc.ci) }) if err != nil { release(err) return nil, err } // 将连接dc,驱动的事务txi绑定到sql.Tx上返回tx = &Tx{ db: db, dc: dc, releaseConn: release, txi: txi, cancel: cancel, keepConnOnRollback: keepConnOnRollback, ctx: ctx, } go tx.awaitDone() return tx, nil
}
上层sql.Tx在执行Exec,Query操作时,使用调Begin的那个连接,也就是和事务绑定的连接
例如:在事务Tx上执行ExecContext
func (tx *Tx) ExecContext(ctx context.Context, query string, args ...any) (Result, error) { // 获得一个连接dc, release, err := tx.grabConn(ctx) if err != nil { return nil, err } // 用连接dc执行execreturn tx.db.execDC(ctx, dc, release, query, args)
}
grabConn:返回Tx上绑定的那个连接
func (tx *Tx) grabConn(ctx context.Context) (*driverConn, releaseConn, error) { // ...// 返回tx.dcreturn tx.dc, tx.closemuRUnlockRelease, nil
}
读取响应
query响应
标准库sql/driver中定义了返回结果的接口Rows:
type Rows interface {// 查询结果的列名Columns() []stringClose() error// 将下一行的数据读到dest中,返回io.EOF代表没数据了Next(dest []Value) error
}
mysql实现的Rows如下:
type mysqlRows struct {mc *mysqlConnrs resultSetfinish func()
}type binaryRows struct {mysqlRows
}type textRows struct {mysqlRows
}
resultSet包含了列的元数据信息,列名信息
type resultSet struct {columns []mysqlFieldcolumnNames []stringdone bool
}
Colunms的实现:
之前读取query响应时,已经将columns信息解析到rows.rs.columns中了,这里只用提取columnNames
func (rows *mysqlRows) Columns() []string {// 已经解析过columnNamesif rows.rs.columnNames != nil {return rows.rs.columnNames}columns := make([]string, len(rows.rs.columns))if rows.mc != nil && rows.mc.cfg.ColumnsWithAlias {// ...} else {// 将columns中的name提取到columnNames中for i := range columns {columns[i] = rows.rs.columns[i].name}}rows.rs.columnNames = columnsreturn columns
}
Close的实现:
上层sql.Rows在close方法中会释放连接,驱动这一层的close主要将缓冲区的数据丢弃
func (rows *mysqlRows) Close() (err error) { if f := rows.finish; f != nil { f() rows.finish = nil } mc := rows.mc if mc == nil { return nil } if err := mc.error(); err != nil { return err } // Remove unread packets from stream if !rows.rs.done { err = mc.readUntilEOF() } if err == nil { handleOk := mc.clearResult() // 将缓冲区剩余的数据读完if err = handleOk.discardResults(); err != nil { return err } } // 将关联的连接置空rows.mc = nil return err
}
Next的实现:
分为textRows和binaryRows
- binaryRows:用于在预编译模式下接受查询结果
- textRows:用于非预编译模式下接受查询结果
我们看textRows:将数据从缓冲区读到dest中
func (rows *textRows) Next(dest []driver.Value) error {if mc := rows.mc; mc != nil {if err := mc.error(); err != nil {return err}// Fetch next row from streamreturn rows.readRow(dest)}return io.EOF
}
textRows.readRows:
- 从连接中读一个完整的包
- 根据dest的顺序,依次读取每个字符串,根据
rows.rs.columns的类型,将字符串转换为对应的类型,放到dest中
func (rows *textRows) readRow(dest []driver.Value) error {mc := rows.mcif rows.rs.done {return io.EOF}// 读一个包,一次性把这个包的数据都读完data, err := mc.readPacket()if err != nil {return err}// 读到EOF了,返回if data[0] == iEOF && len(data) == 5 {// server_status [2 bytes]rows.mc.status = readStatus(data[3:])rows.rs.done = trueif !rows.HasNextResultSet() {rows.mc = nil}return io.EOF}if data[0] == iERR {rows.mc = nilreturn mc.handleErrorPacket(data)}// RowSet Packetvar (n intisNull boolpos int = 0)// 依次读各个列for i := range dest {// Read bytes and convert to stringvar buf []byte// 读一个字符串buf, isNull, n, err = readLengthEncodedString(data[pos:])pos += nif err != nil {return err}if isNull {dest[i] = nilcontinue}// 根据不同的类型,解析成不同的列switch rows.rs.columns[i].fieldType {case fieldTypeTimestamp,fieldTypeDateTime,fieldTypeDate,fieldTypeNewDate:if mc.parseTime {dest[i], err = parseDateTime(buf, mc.cfg.Loc)} else {dest[i] = buf}case fieldTypeTiny, fieldTypeShort, fieldTypeInt24, fieldTypeYear, fieldTypeLong:dest[i], err = strconv.ParseInt(string(buf), 10, 64)case fieldTypeLongLong:if rows.rs.columns[i].flags&flagUnsigned != 0 {dest[i], err = strconv.ParseUint(string(buf), 10, 64)} else {dest[i], err = strconv.ParseInt(string(buf), 10, 64)}case fieldTypeFloat:var d float64d, err = strconv.ParseFloat(string(buf), 32)dest[i] = float32(d)case fieldTypeDouble:dest[i], err = strconv.ParseFloat(string(buf), 64)default:dest[i] = buf}if err != nil {return err}}return nil
}
binaryRows.readRows原理类似,这里不再做分析
exec响应
在driver.Result定义了驱动应该实现的接口:
type Result interface {LastInsertId() (int64, error)RowsAffected() (int64, error)
}
mysql驱动的实现为:
type mysqlResult struct {// One entry in both slices is created for every executed statement result.affectedRows []int64insertIds []int64
}
被mysqlConn持有:
type mysqlConn struct {buf buffernetConn net.ConnrawConn net.Conn// 持有mysqlResultresult mysqlResult
}
实现接口的两个方法:
func (res *mysqlResult) LastInsertId() (int64, error) {return res.insertIds[len(res.insertIds)-1], nil
}func (res *mysqlResult) RowsAffected() (int64, error) {return res.affectedRows[len(res.affectedRows)-1], nil
}
那这两个值啥时候塞到mysqlConn.result里呢?
执行完exec,读取响应时:
func (mc *okHandler) handleOkPacket(data []byte) error {var n, m intvar affectedRows, insertId uint64// 影响行数,n代表了几个字节affectedRows, _, n = readLengthEncodedInteger(data[1:])// insertId,m代表读了几个字节insertId, _, m = readLengthEncodedInteger(data[1+n:])if len(mc.result.affectedRows) > 0 {// 保存affectedRowsmc.result.affectedRows[len(mc.result.affectedRows)-1] = int64(affectedRows)}if len(mc.result.insertIds) > 0 {// 保存insertIdmc.result.insertIds[len(mc.result.insertIds)-1] = int64(insertId)}// server_status [2 bytes]mc.status = readStatus(data[1+n+m : 1+n+m+2])if mc.status&statusMoreResultsExists != 0 {return nil}// warning count [2 bytes]return nil
}
总结
至此,关于mysql驱动的源码本文已经分析完毕。下一篇文章分析gorm的orm架构设计以及实现原理






