服务雪崩
服务雪崩效应是一种因“服务提供者的不可用”(原因)导致“服务调用者不可用”(结果),并将不可用逐渐放大的现象。如下图所示:
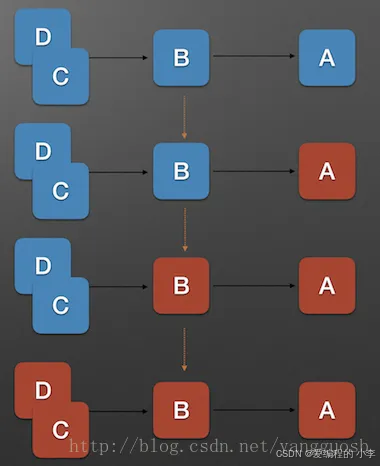
上图中, A为服务提供者, B为A的服务调用者, C和D是B的服务调用者. 当A的不可用,引起B的不可用,并将不可用逐渐放大C和D时, 服务雪崩就形成了。
可以通过引入超时机制解决
grpc的超时和重试
超时
timeout是为了保护服务,避免consumer服务因为provider 响应慢而也变得响应很慢,这样consumer可以尽量保持原有的性能。
重试
如果provider只是偶尔抖动,那么超时后直接放弃,不做后续处理,就会导致当前请求错误,也会带来业务方面的损失。对于这种偶尔抖动,可以在超时后重试一下,重试如果正常返回了,那么这次请求就被挽救了,能够正常给前端返回数据,只不过比原来响应慢一点。重试可以考虑切换一台机器来进行调用,因为原来机器可能由于临时负载高而性能下降,重试会更加剧其性能问题,而换一台机器,得到更快返回的概率也更大一些。
幂等
如果允许consumer重试,那么provider就要能够做到幂等。同一个请求被consumer多次调用,对provider产生的影响是一致的。而且这个幂等应该是服务级别的,而不是某台机器层面的,重试调用任何一台机器,都应该做到幂等。

同样的数据提交两次,因为重试机制调用了多次,数据库中只能有一份数据
一个订单扣款两次
常见的幂等性解决方案
哪些情况下需要考虑幂等性 - 同样的请求发送多次:
- http请求的类型:
1.1. get(获取商品信息, 这个会引起商品的数据的变化吗?)
1.2. post(比较常见,这种接口需要考虑到幂等性)
1.3. put:
1.3.1.不一定要实现幂等性
a. put 把1号商品的价格改为200,网络返回的时候抖动了,重试
b. 第二次接口还是会把1号商品的价格改为200 - 这种情况下没有幂等的问题
1.3.2.出现幂等性问题的情况:
a. 购物车中的商品,调用一次 这个商品的数量加一
ⅰ. 第一次调用 原本的值 10 之后价格变为11 - 但是返回的时候出现了网络抖动
ⅱ. 第二次发送 原本的值 11 之后价格变为12 - 但是返回的时候出现了网络抖动
ⅲ. 第三次发送 原本的值 12 之后价格变为13- 但是返回的时候出现了网络抖动
1.4. delete
1.4.1. 一般不具备幂等性的要求
1.4.2. 第一次调用 删除数据
1.4.3. 第二次调用 还是删除当前的数据
grpc重试
重试库
服务端
package mainimport ("context""fmt""net""time""google.golang.org/grpc""GolangStudy/Introduction/grpc/interpretor/proto"
)type Server struct{}func (s *Server) SayHello(ctx context.Context, request *proto.HelloRequest) (*proto.HelloReply,error) {time.Sleep(3 * time.Second)return &proto.HelloReply{Message: "hello " + request.Name,}, nil
}func main() {var interceptor grpc.UnaryServerInterceptorinterceptor = func(ctx context.Context, req interface{}, info *grpc.UnaryServerInfo, handler grpc.UnaryHandler) (resp interface{}, err error) {// 继续处理请求fmt.Println("接收到新请求")res, err := handler(ctx, req)fmt.Println("请求处理完成")return res, err}var opts []grpc.ServerOptionopts = append(opts, grpc.UnaryInterceptor(interceptor))g := grpc.NewServer(opts...)proto.RegisterGreeterServer(g, &Server{})lis, err := net.Listen("tcp", "0.0.0.0:50051")if err != nil {panic("failed to listen:" + err.Error())}err = g.Serve(lis)if err != nil {panic("failed to start grpc:" + err.Error())}
}客户端
package mainimport ("context""fmt""time""google.golang.org/grpc""google.golang.org/grpc/codes""GolangStudy/Introduction/grpc/interpretor/proto"grpc_retry "github.com/grpc-ecosystem/go-grpc-middleware/retry"
)func interceptor(ctx context.Context, method string, req, reply interface{}, cc *grpc.ClientConn, invoker grpc.UnaryInvoker, opts ...grpc.CallOption) error {start := time.Now()err := invoker(ctx, method, req, reply, cc, opts...)fmt.Printf("method=%s req=%v rep=%v duration=%s error=%v\n", method, req, reply, time.Since(start), err)return err
}func main() {//streamvar opts []grpc.DialOptionretryOpts := []grpc_retry.CallOption{grpc_retry.WithMax(3),grpc_retry.WithPerRetryTimeout(1 * time.Second),grpc_retry.WithCodes(codes.Unknown, codes.DeadlineExceeded, codes.Unavailable),}opts = append(opts, grpc.WithInsecure())// 指定客户端interceptoropts = append(opts, grpc.WithUnaryInterceptor(interceptor))opts = append(opts, grpc.WithUnaryInterceptor(grpc_retry.UnaryClientInterceptor(retryOpts...)))conn, err := grpc.Dial("localhost:50051", opts...)if err != nil {panic(err)}defer conn.Close()c := proto.NewGreeterClient(conn)r, err := c.SayHello(context.Background(),&proto.HelloRequest{Name: "bobby"},)if err != nil {panic(err)}fmt.Println(r.Message)
}幂等解决方案
1.唯一索引(防止新增脏数据)
比如:新建用户的时候将手机号码设置为唯一索引,那么即使你重试,也只会新建一个用户,不会因为重试导致当前用户注册了两个用户
要点:
唯一索引或唯一组合索引来防止新增数据存在脏数据 (当表存在唯一索引,并发时新增报错时,再查询一次就可以了,数据应该已经存在了,返回结果即可)
2. token机制(防止页面重复提交 )
业务要求: 页面的数据只能被点击提交一次
发生原因: 由于重复点击或者网络重发,或者nginx重发等情况会导致数据被重复提交
解决办法:
集群环境:采用token加redis(redis单线程的,处理需要排队)
处理流程:
- 数据提交前要向服务的申请token,token放到redis或内存,token有效时间
- 提交后后台校验token,同时删除token,生成新的token返回
token特点:
要申请,一次有效性,可以限流
注意:redis要用删除操作来判断token,删除成功代表token校验通过,如果用select+delete来校验token,存在并发问题,不建议使用
3. 悲观锁 (扣减库存)
获取数据的时候加锁获取
select * from table_xxx where id=‘xxx’ for update;
注意:id字段一定是主键或者唯一索引,不然是锁表,会死人的
悲观锁使用时一般伴随事务一起使用,数据锁定时间可能会很长,根据实际情况选用
4. 乐观锁
乐观锁只是在更新数据那一刻锁表,其他时间不锁表,所以相对于悲观锁,效率更高。
乐观锁的实现方式多种多样可以通过version或者其他状态条件:
- 通过版本号实现
update table_xxx set name=#name#,version=version+1 where version=#version#

- 通过条件限制
update table_xxx set avai_amount=avai_amount-#subAmount# where avai_amount-#subAmount# >= 0
要求:quality-#subQuality# >= ,这个情景适合不用版本号,只更新是做数据安全校验,适合库存模型,扣份额和回滚份额,性能更高
注意:乐观锁的更新操作,最好用主键或者唯一索引来更新,这样是行锁,否则更新时会锁表,上面两个sql改成下面的两个更好
update table_xxx set name=#name#,version=version+1 where id=#id# and version=#version#
update table_xxx set avai_amount=avai_amount-#subAmount# where id=#id# and avai_amount-#subAmount# >= 0
5. 分布式锁
还是拿插入数据的例子,如果是分布是系统,构建全局唯一索引比较困难,例如唯一性的字段没法确定,这时候可以引入分布式锁,通过第三方的系统(redis或zookeeper),在业务系统插入数据或者更新数据,获取分布式锁,然后做操作,之后释放锁,这样其实是把多线程并发的锁的思路,引入多多个系统,也就是分布式系统中得解决思路。
要点:某个长流程处理过程要求不能并发执行,可以在流程执行之前根据某个标志(用户ID+后缀等)获取分布式锁,其他流程执行时获取锁就会失败,也就是同一时间该流程只能有一个能执行成功,执行完成后,释放分布式锁(分布式锁要第三方系统提供)
6. select + insert
并发不高的后台系统,或者一些任务JOB,为了支持幂等,支持重复执行,简单的处理方法是,先查询下一些关键数据,判断是否已经执行过,在进行业务处理,就可以了
注意:核心高并发流程不要用这种方法
7. 对外提供接口的api如何保证幂等
如银联提供的付款接口:需要接入商户提交付款请求时附带:source来源,seq序列号
source+seq在数据库里面做唯一索引,防止多次付款,(并发时,只能处理一个请求)
重点:
对外提供接口为了支持幂等调用,接口有两个字段必须传,一个是来源source,一个是来源方序列号seq,这个两个字段在提供方系统里面做联合唯一索引,这样当第三方调用时,先在本方系统里面查询一下,是否已经处理过,返回相应处理结果;没有处理过,进行相应处理,返回结果。注意,为了幂等友好,一定要先查询一下,是否处理过该笔业务,不查询直接插入业务系统,会报错,但实际已经处理了。
总结
幂等与你是不是分布式高并发没有关系。关键是你的操作是不是幂等的。一个幂等的操作典型如:把编号为5的记录的A字段设置为0这种操作不管执行多少次都是幂等的。一个非幂等的操作典型如:把编号为5的记录的A字段增加1这种操作显然就不是幂等的。要做到幂等性,从接口设计上来说不设计任何非幂等的操作即可。譬如说需求是:当用户点击赞同时,将答案的赞同数量+1。改为:当用户点击赞同时,确保答案赞同表中存在一条记录,用户、答案。赞同数量由答案赞同表统计出来。总之幂等性应该是合格程序员的一个基因,在设计系统时,是首要考虑的问题,尤其是在像支付宝,银行,互联网金融公司等涉及的都是钱的系统,既要高效,数据也要准确,所以不能出现多扣款,多打款等问题,这样会很难处理,用户体验也不好。
)
)
![[OS_9] C 标准库和实现 | musl libc | offset](http://pic.xiahunao.cn/nshx/[OS_9] C 标准库和实现 | musl libc | offset)



