Redis常见问题解决
要求
只用一种缓存技术,从实验点中挑一些试验进行试验原理。
1.缓存原理
目标:理解缓存的基本原理和工作机制。
实验步骤:
- 阅读各缓存技术机制的文档和官方资料。
- 实现一个简单的应用程序,模拟数据的读写和缓存操作。
- 观察实时操作日志,了解缓存的实际运行情况。
实验
-
缓存的基本原理主要围绕以下几个核心概念:
-
时间局部性与空间局部性:缓存利用了程序访问数据的时间局部性和空间局部性,即如果一个数据被访问过,它很可能在不久的将来再次被访问;并且,如果一个数据被访问,其相邻的数据也可能很快被访问。
-
高速存储介质:缓存通常位于更快的存储介质上,比如内存,相比硬盘等慢速存储,能显著提升数据访问速度。
-
缓存命中与未命中:当请求的数据在缓存中存在时称为缓存命中,此时直接从缓存返回数据,无需访问较慢的后端存储;反之,如果数据不在缓存中,则称为缓存未命中,需要从后端加载数据并存储到缓存中,以便下次快速访问。
-
缓存策略:包括但不限于LRU(Least Recently Used,最近最少使用)、LFU(Least Frequently Used,最不经常使用)和FIFO(First In First Out,先进先出)等淘汰策略,以及过期策略、缓存更新策略等。
-
缓存一致性:在多线程或多进程环境下,确保缓存与数据源保持一致性的机制,如写直达、写回等。
-
-
以下是一个简化的Java示例,使用HashMap模拟内存缓存:
import java.util.HashMap; import java.util.Map;public class SimpleCacheExample {private final Map<String, String> cache = new HashMap<>();public String getUserInfo(String userId) {// 先尝试从缓存中获取数据String userInfo = cache.get(userId);if (userInfo == null) {// 如果缓存中没有,模拟从数据库读取userInfo = fetchFromDatabase(userId);// 将数据放入缓存cache.put(userId, userInfo);System.out.println("缓存未命中!!!");} else {System.out.println("缓存命中!!!");} return userInfo;}private String fetchFromDatabase(String userId) {// 这里实际应调用数据库查询逻辑,这里简单模拟return "UserInfo of " + userId;}public static void main(String[] args) {SimpleCacheExample cacheExample = new SimpleCacheExample();System.out.println(cacheExample.getUserInfo("1001")); // 首次访问,会从数据库获取System.out.println(cacheExample.getUserInfo("1001")); // 再次访问,直接从缓存获取} } -
实时操作日志:
-
观察首次访问

-
未命中缓存,查询数据库

-
观察第二次访问
-
命中缓存!直接返回结果。

-
程序运行结果(首次访问,会从数据库获取。再次访问,直接从缓存获取。)
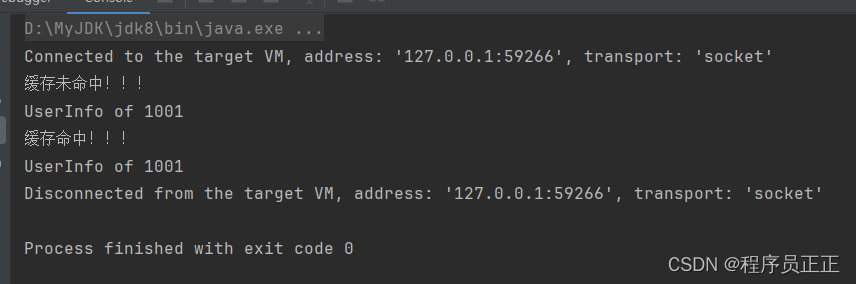
-
2.缓存击穿
目标:模拟和解决缓存击穿问题。
实验步骤:
- 设计一个常被请求的热点数据。
- 启动多个并发请求同时访问该热点数据,观察缓存是否会因此而失效。
- 实现解决缓存击穿的方法,比如使用互斥锁或者提前加载数据。
实验
-
我们首先模拟实验环境(使用Redis作为缓存)
查询心理健康产品详情接口:
@Resource private RedisTemplate redisTemplate; int count = 1;@ApiOperation("查询心理健康产品详情") @GetMapping("/detail") public R<MentalHealthProduce> detail(@RequestParam(value = "id") String id) {MentalHealthProduce mentalHealthProduce;// 动态构造keyString key = "produce_" + id; // 例:produce_1397844391040167938// 先从Redis中获取缓存数据mentalHealthProduce = (MentalHealthProduce) redisTemplate.opsForValue().get(key);// 如果存在, 直接返回, 无需查询数据库if (mentalHealthProduce != null) {return R.success(mentalHealthProduce);}mentalHealthProduce = mentalHealthProduceService.getById(id);// 这里每一次进行数据库查询我们进行打印日志System.out.println("查询数据库次数:" + count++);if (mentalHealthProduce == null) {return R.error("心理健康产品不存在");}// 将查询到的热点数据缓存到Redis中,过期时间为3秒redisTemplate.opsForValue().set(key, mentalHealthProduce, 3, TimeUnit.SECONDS);return R.success(mentalHealthProduce); } -
我们进行压测,查看效果(开启10个线程,压测10秒)
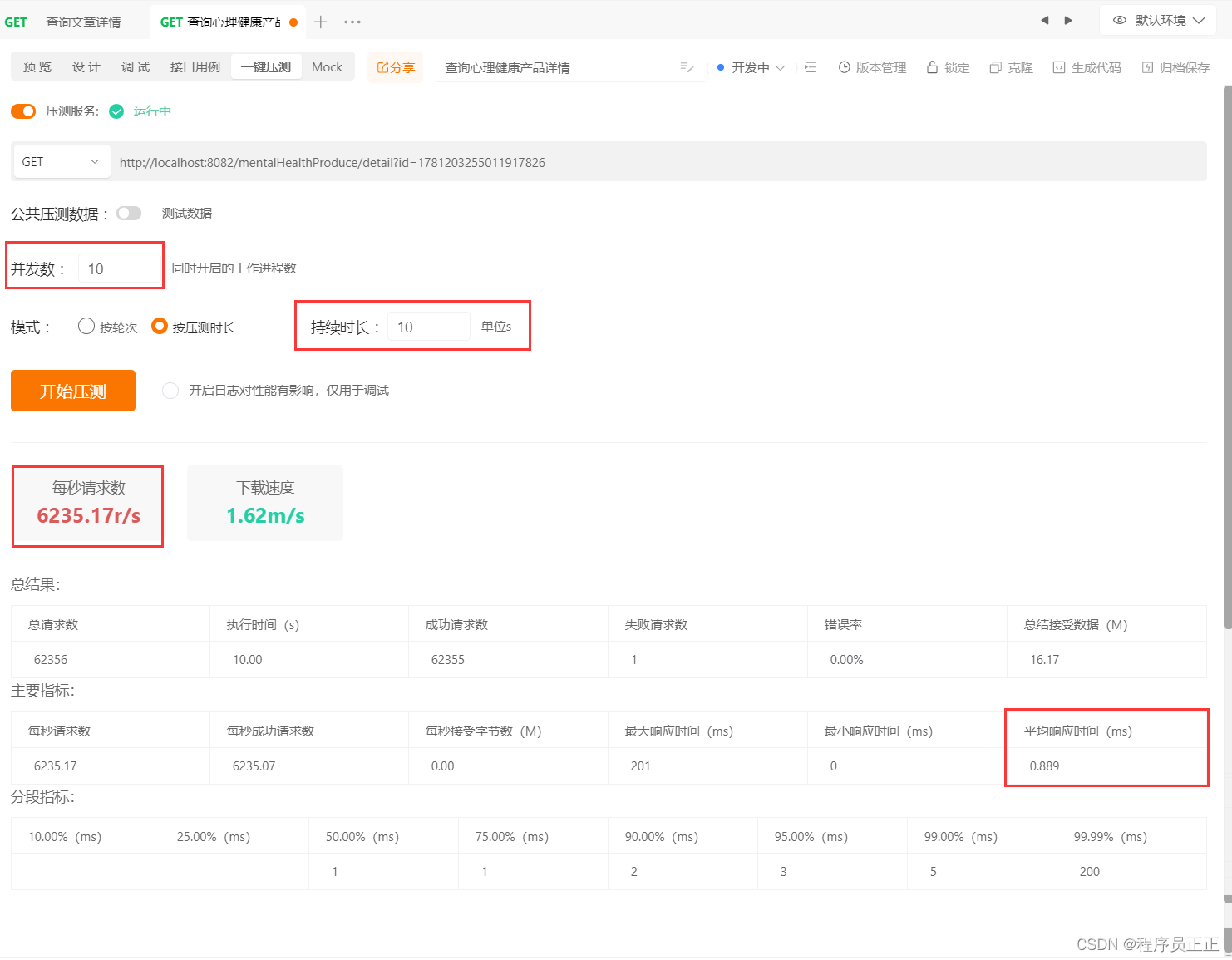
我们观察控制台:即使我们开启了缓存,但在失效的时间内仍然请求了38次,在高并发中还是存在风险

-
我们进行对缓存击穿的解决
-
热点数据永不过期(把过期时间取消即可,不再演示)
-
添加互斥锁
-
修改代码逻辑(加锁再去获取数据)
// 动态构造key String key = "produce_" + id; // 例:produce_1397844391040167938 // 创建基于id的唯一锁 String lockKey = "lock_produce_" + id;// 尝试获取基于id的锁 RLock lock = redissonClient.getLock(lockKey); lock.lock(); // 先加锁,确保并发安全try {// 先从Redis中获取缓存数据mentalHealthProduce = (MentalHealthProduce) redisTemplate.opsForValue().get(key);// 如果存在, 直接返回, 无需查询数据库if (mentalHealthProduce != null) {return R.success(mentalHealthProduce);}mentalHealthProduce = mentalHealthProduceService.getById(id);// 这里每一次进行数据库查询我们进行打印日志System.out.println("查询数据库次数:" + count++);if (mentalHealthProduce == null) {return R.error("心理健康产品不存在");}// 将查询到的热点数据缓存到Redis中redisTemplate.opsForValue().set(key, mentalHealthProduce, 3, TimeUnit.SECONDS); } catch (Exception e) {e.printStackTrace(); } finally {// 3、释放锁lock.unlock(); } -
再次进行压测:开启10个线程,压测10秒

-
观察控制台日志:我们过期时间设置为3秒,正常来说10秒压测只会进行四次数据库查询

-
-
3.缓存穿透
目标:模拟和解决缓存穿透问题。
实验步骤:
- 构造一个不存在于缓存和数据库中的无效数据。
- 启动多个并发请求同时访问该无效数据,观察缓存是否被绕过直接访问数据库。
- 实现解决缓存穿透的方法,比如使用布隆过滤器或者空对象缓存。
实验
-
我们首先模拟实验环境(使用Redis作为缓存)
查询文章接口:
@ApiOperation("查询文章详情") @GetMapping("/detail") public R<ArticleResp> detail(@RequestParam(value = "id") String id) {// 构造返回参数ArticleResp articleResp;// 动态构造keyString key = "article_" + id; // 例:article_1397844391040167938// 先从Redis中获取缓存数据articleResp = (ArticleResp) redisTemplate.opsForValue().get(key);// 如果存在, 直接返回, 无需查询数据库if (articleResp != null) {return R.success(articleResp);}Article article = articleService.getById(id);if (article == null) {return R.error("文章不存在");}articleResp = new ArticleResp();BeanUtils.copyProperties(article, articleResp);// 设置点赞数int count = likeService.count(new LambdaQueryWrapper<Like>().eq(Like::getEventId, id));articleResp.setLikeNum(count);// 设置评论列表List<CommentResp> commentRespList = commentService.list(new LambdaQueryWrapper<Comment>().eq(Comment::getEventId, id)).stream().map(comment -> {// ......return commentResp;}).collect(Collectors.toList());articleResp.setCommentRespList(commentRespList);// 将查询到的文章数据缓存到Redis中redisTemplate.opsForValue().set(key, articleResp, 1, TimeUnit.HOURS);return R.success(articleResp); } -
我们请求一个不存在的
id值(id=1)来查看查询情况
可以看到,确实是请求了数据库的(缓存失效),如果黑客进行大量请求,系统将存在巨大隐患。
-
我们进行压测,查看效果(开启10个线程,压测10轮)
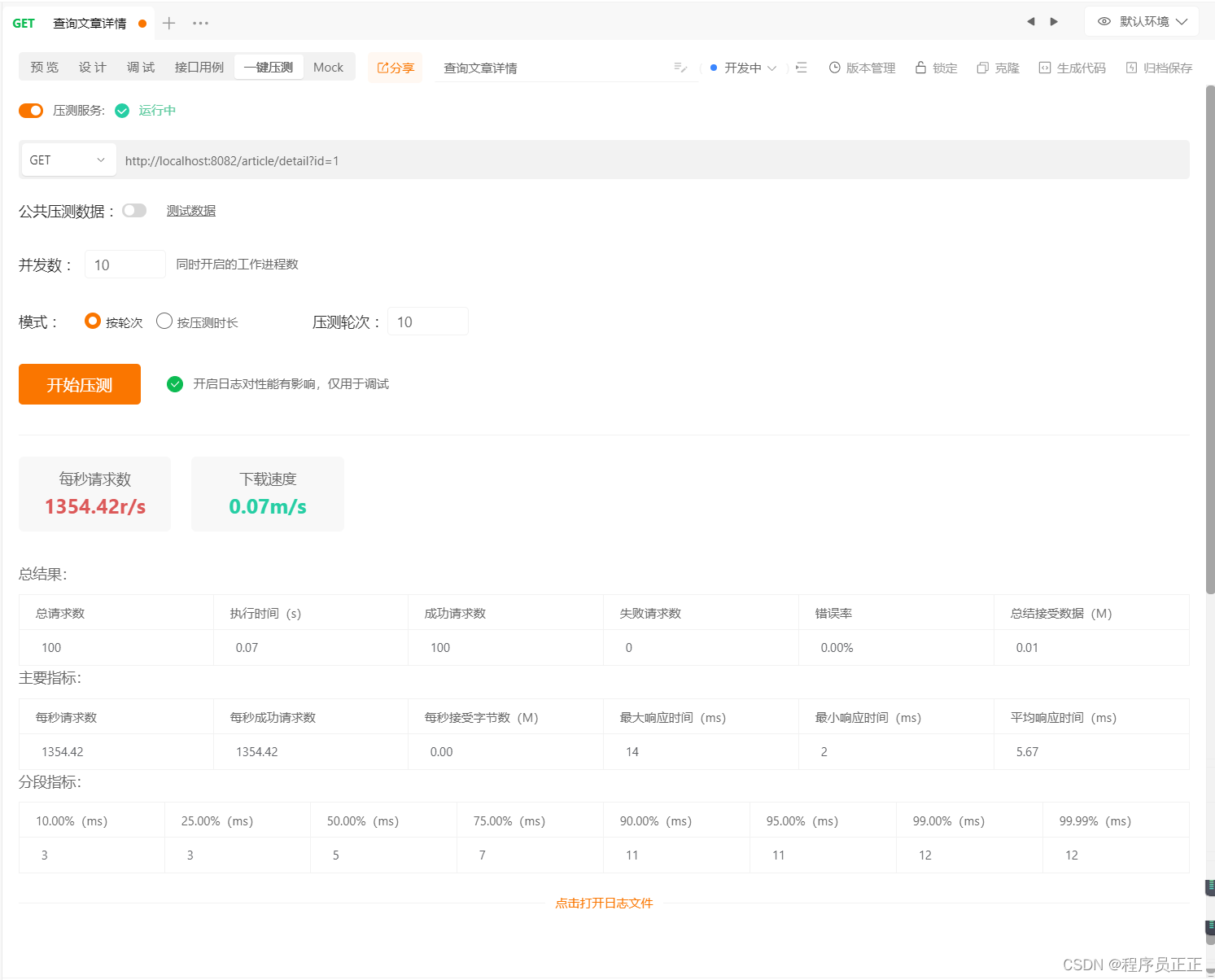
-
我们进行对缓存穿透的解决
-
缓存无效数据
-
修改代码(无效数据同样进行缓存)

-
再次进行压测:同样10个线程进行10轮压测,请求数增多(150%)的情况下平均响应时间还缩短了将近35%!!!

-
但这种处理方式是有问题的,假如传进来的这个不存在的Key值每次都是随机的,那存进Redis也没有意义。
-
-
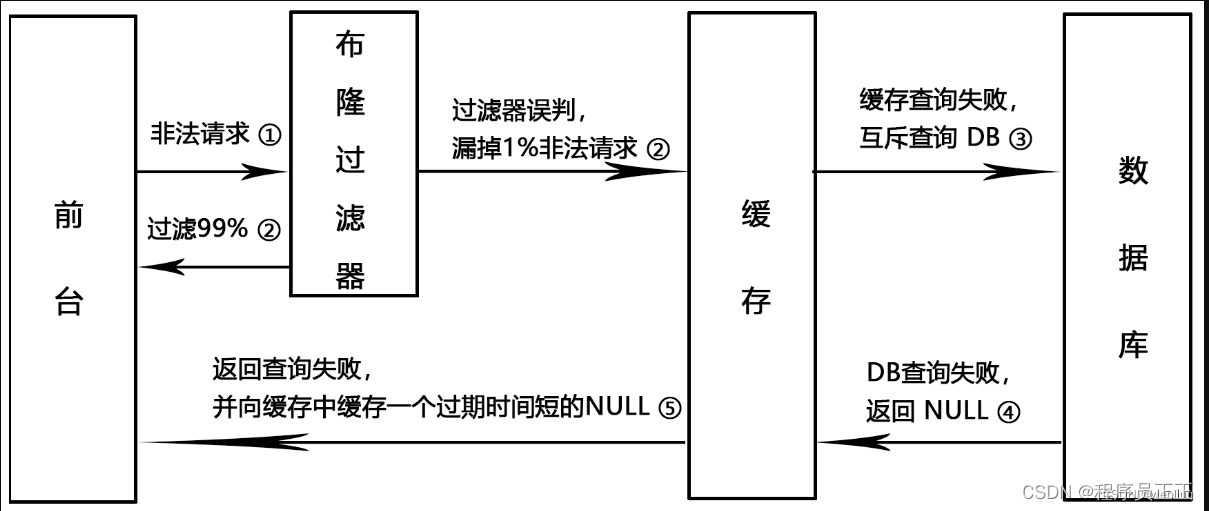
布隆过滤器(Redisson实现)
-
pom.xml中导入Redisson依赖<!--Redisson--> <dependency><groupId>org.redisson</groupId><artifactId>redisson-spring-boot-starter</artifactId><version>3.17.6</version> </dependency> -
RedisConfig中添加以下配置(Redis进行正常配置即可)@Value("${spring.redis.host}") private String host;@Value("${spring.redis.port}") private String port;@Bean public RedissonClient redisson() {//创建配置Config config = new Config();config.useSingleServer().setAddress("redis://" + host + ":" + port);//根据config创建出RedissonClient实例return Redisson.create(config); } -
项目中使用
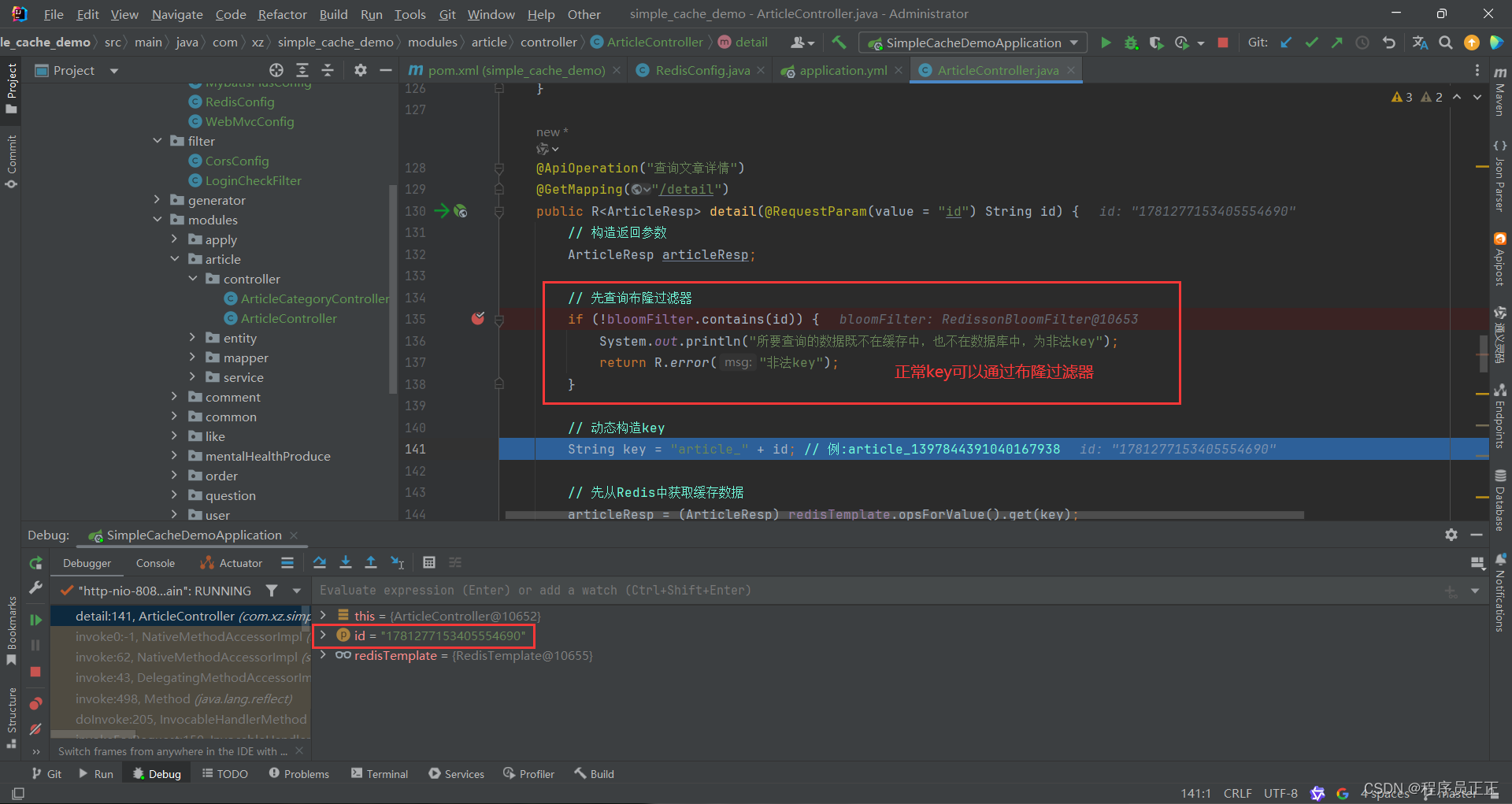
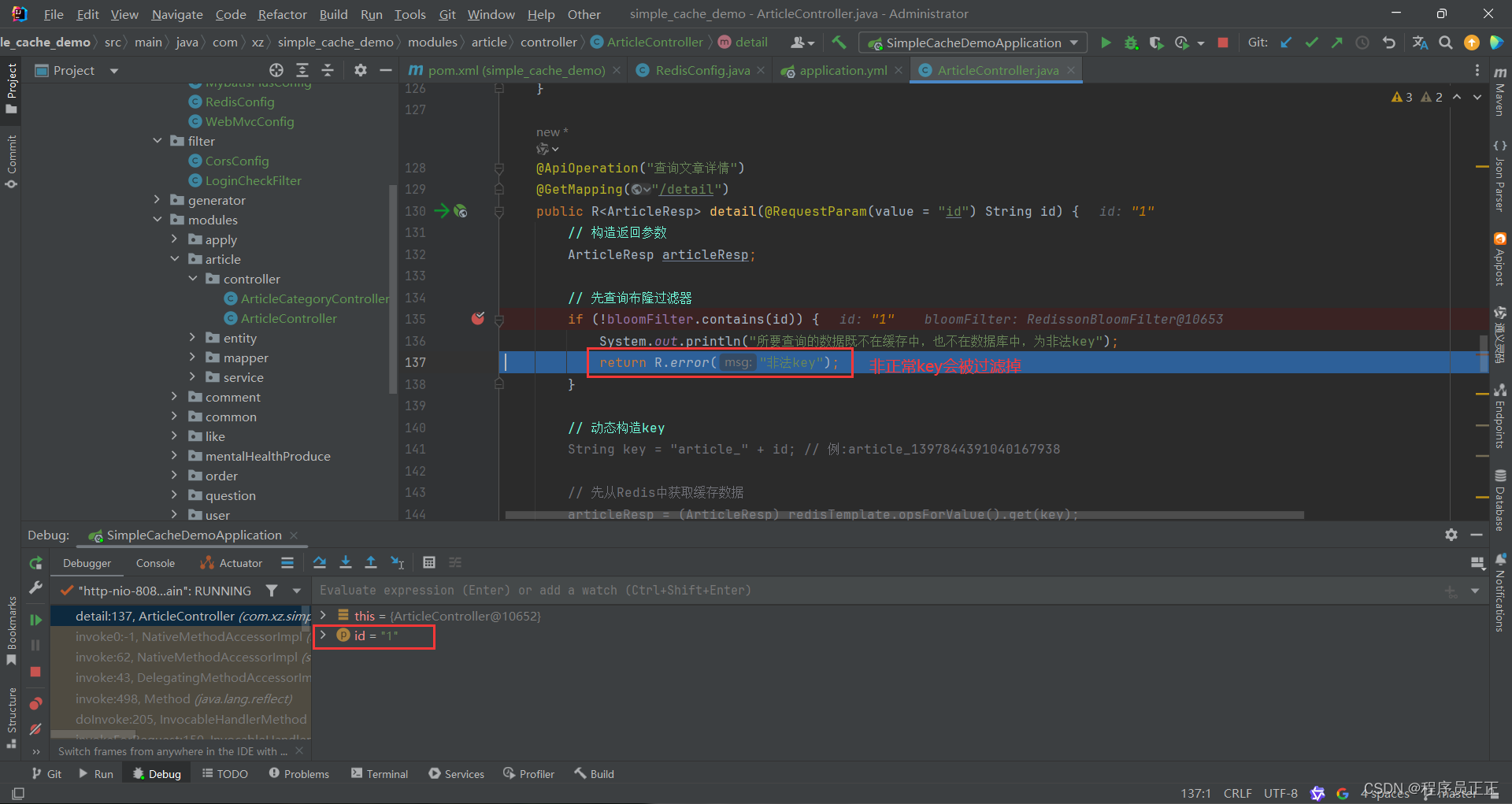
@Resource private RedissonClient redissonClient; private RBloomFilter<String> bloomFilter;@PostConstruct // 项目启动的时候执行该方法,也可以理解为在spring容器初始化的时候执行该方法 public void init() {// 启动项目时初始化bloomFilterList<Article> articleList = articleService.list();//参数:布隆过滤器的名字bloomFilter = redissonClient.getBloomFilter("articleFilter");// 初始化布隆过滤器 预计数据量 误判率bloomFilter.tryInit(1000L, 0.01);for (Article article : articleList) {bloomFilter.add(article.getId());} }因为我们已经初始化过数据,所以在查询时可以先查询布隆过滤器

-
观察实际运行情况
-
-
4.缓存雪崩
目标:模拟和解决缓存雪崩问题。
实验步骤:
- 设定多个缓存数据的失效时间相同,并在某一时刻让它们同时失效。
- 启动多个并发请求,观察在缓存数据失效时的响应时间和Redis服务器的负载情况。
- 实现解决缓存雪崩的方法,比如使用不同的失效时间或者限流策略。
实验
-
我们首先模拟实验环境(使用Redis作为缓存)
我们事先将全部数据存入数据库,并把所有数据存活时间都设置为60秒:
@PostConstruct // 项目启动的时候执行该方法,也可以理解为在spring容器初始化的时候执行该方法 public void init() {// 启动项目时事先存入Redis热点数据List<MentalHealthProduce> produceList = mentalHealthProduceService.list();for (MentalHealthProduce produce : produceList) {String key = "produce_" + produce.getId(); // 例:produce_1397844391040167938redisTemplate.opsForValue().set(key, produce, 60, TimeUnit.SECONDS);}System.out.println("当前时间" + new Date()); } -
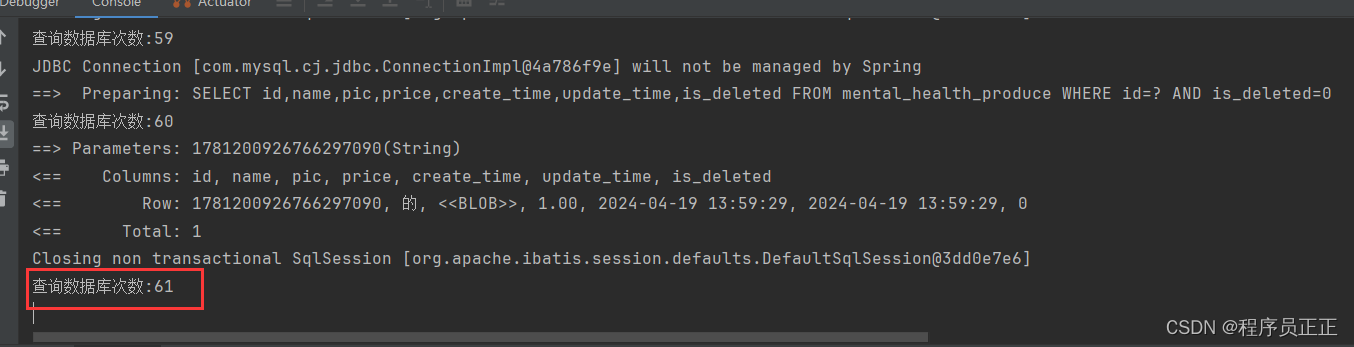
在缓存快要失效时,我们进行压测查看效果(开启10000个线程,压测10秒)
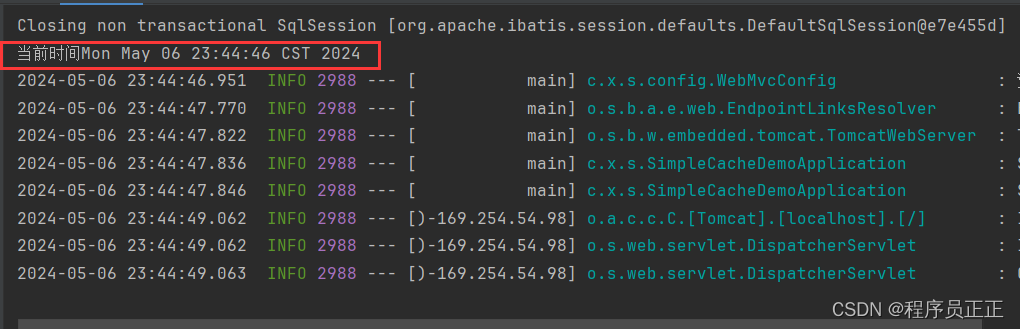
可以看到,在缓存同一时间失效的情况下,还是会有很多请求同时请求数据库,给数据库造成一定的压力!

-
我们进行对缓存雪崩的解决
-
使用随机或梯度失效时间(为每项数据设置一个随机范围内的过期时间,或者采用梯度失效策略,即相近的数据项过期时间错开一定间隔),示例代码:
Random random = new Random(); for (String user : users) {long expireTime = 24 * 60 * 60 + random.nextInt(300); // 基础24小时过期时间加上0-5分钟的随机偏移RBucket<Object> bucket = redisson.getBucket("user:" + user);bucket.set(userDetails, expireTime, TimeUnit.SECONDS); } -
限流与降级(在服务端实施请求限流,避免在缓存失效瞬间服务被大量请求压垮。同时,可以设置服务降级策略,当请求超过阈值时返回降级内容(如静态数据、默认值或部分数据)而非直接失败)
-
限流实现
Redisson 提供了
RRateLimiter接口来实现限流功能,支持固定窗口、滑动窗口、令牌桶等多种限流算法。例如,使用令牌桶算法进行限流,可以这样配置:// 创建一个令牌桶限流器,每秒填充5个令牌,最多存储10个令牌 RRateLimiter rateLimiter = redisson.getRateLimiter("myRateLimiter"); rateLimiter.trySetRate(RateType.OVERALL, 5, 10, RateIntervalUnit.SECONDS);// 在需要限流的地方尝试获取令牌,如果获取不到则说明限流 boolean permit = rateLimiter.tryAcquire(1); if (!permit) {// 限流逻辑,比如抛出异常或者返回错误信息 } -
降级实现
在限流逻辑中加入降级逻辑,当检测到请求量过大或系统资源紧张时,主动返回简化版的服务响应或者错误信息,避免进一步加重系统负担。
例如,可以在限流失败时,执行降级逻辑:
if (!rateLimiter.tryAcquire(1)) {// 降级处理,例如返回默认值或者错误提示return "服务繁忙,请稍后再试"; }另外,结合Spring框架或AOP(面向切面编程),可以更加灵活地在应用层面实现更复杂的降级策略。例如,通过自定义注解和切面来判断服务是否需要降级:
@Retention(RetentionPolicy.RUNTIME) @Target(ElementType.METHOD) public @interface RateLimitAndFallback {// 可以定义一些配置属性,如降级时的返回值 }@Aspect @Component public class RateLimitAndFallbackAspect {@Around("@annotation(rateLimitAndFallback)")public Object handleMethodWithRateLimit(ProceedingJoinPoint joinPoint, RateLimitAndFallback rateLimitAndFallback) throws Throwable {// 这里可以结合Redisson的限流逻辑if (!rateLimiter.tryAcquire(1)) {// 根据注解或配置返回降级内容return "降级响应内容";}// 正常执行方法return joinPoint.proceed();} }通过上述方式,我们可以结合Redisson的限流功能和自定义的降级策略,有效地应对高并发场景下的系统稳定性问题。
-
-
总结与优化
总结
- 缓存基本原理的实践揭示了缓存机制的核心优势,包括时间与空间局部性、高速存储介质的使用、命中与未命中的处理机制、多样化淘汰策略以及确保一致性的方法。通过简单的Java示例,我们直观体验了缓存对提升数据访问效率的显著作用。
- 缓存击穿问题通过模拟高并发访问热点数据,发现即使使用了缓存,数据过期时仍会导致数据库负载激增。采用永不过期策略和互斥锁(Mutex)解决了这一问题,有效降低了数据库压力,但需要注意永不过期策略需谨慎使用,以免造成内存压力。
- 缓存穿透现象通过构造不存在的数据请求,观察到直接绕过缓存访问数据库的现象。采用缓存无效数据(null值)以及布隆过滤器有效减少了无效数据库查询,提高了系统效率。布隆过滤器虽有误报可能,但在多数场景下能有效减轻数据库负担。
- 缓存雪崩的模拟与解决展示了当大量缓存同时过期时,系统响应时间和数据库负载的剧增。通过为数据设置随机或梯度过期时间以及实施限流与降级策略,显著改善了这一问题。限流保证了系统在高并发下的稳定性,而降级策略保证了即使在资源紧张时也能提供一定程度的服务。
优化与改进建议
- 精细化配置缓存策略:根据业务特点调整缓存过期时间,避免集中失效,使用梯度过期或随机过期策略分散风险。
- 动态调整限流阈值:根据系统实时负载动态调整限流阈值,以适应不同时间段的访问压力,避免过度限制或限制不足。
- 监控与预警系统:建立完善的监控体系,实时监测缓存命中率、系统负载、以及Redis服务器状态,设置阈值预警,及时发现并处理潜在问题。
- 优化缓存更新机制:采用异步更新策略,减少因更新缓存造成的阻塞,确保数据新鲜度的同时不影响用户体验。
- 分布式锁的优化:优化互斥锁的使用,减少锁等待时间,避免因锁竞争导致的性能瓶颈。探索使用读写锁或乐观锁机制,提高并发效率。
- 持续性能测试与调优:定期进行压力测试,模拟各种极端场景,根据测试结果不断调整和优化缓存策略和系统配置。
- 完善降级策略:细化降级逻辑,根据不同场景提供更合理的降级内容,如提供有限功能、默认数据或历史数据,确保用户体验。
通过上述措施,可以显著增强缓存系统性能,提高系统的稳定性和用户体验,降低运营成本。



)


