在一个案例中,大表 100GB、小表 10GB,它们全都远超广播变量阈值(默认 10MB)。因为小表的尺寸已经超过 8GB,在大于 8GB 的数据集上创建广播变量,Spark 会直接抛出异常,中断任务执行,所以 Spark 是没有办法应用 BHJ 机制的。那我们该怎么办呢?
先别急,我们来看看这个案例的业务需求。这个案例来源于计算广告业务中的流量预测,流量指的是系统中一段时间内不同类型用户的访问量。这里有三个关键词,第一个是“系统”,第二个是“一段时间”,第三个是“用户类型”。时间粒度好理解,就是以小时为单位去统计流量。用户类型指的是采用不同的维度来刻画用户,比如性别、年龄、教育程度、职业、地理位置。系统指的是流量来源,比如平台、站点、频道、媒体域名。在系统和用户的维度组合之下,流量被细分为数以百万计的不同“种类”。比如,来自 XX 平台 XX 站点的在校大学生的访问量,或是来自 XX 媒体 XX 频道 25-45 岁女性的访问量等等。
我们知道,流量预测本身是个时序问题,它和股价预测类似,都是基于历史、去预测未来。在我们的案例中,为了预测上百万种不同的流量,咱们得先为每种流量生成时序序列,然后再把这些时序序列喂给机器学习算法进行模型训练。统计流量的数据源是线上的访问日志,它记录了哪类用户在什么时间访问了哪些站点。要知道,我们要构建的,是以小时为单位的时序序列,但由于流量的切割粒度非常细致,因此有些种类的流量不是每个小时都有访问量的,如下图所示。
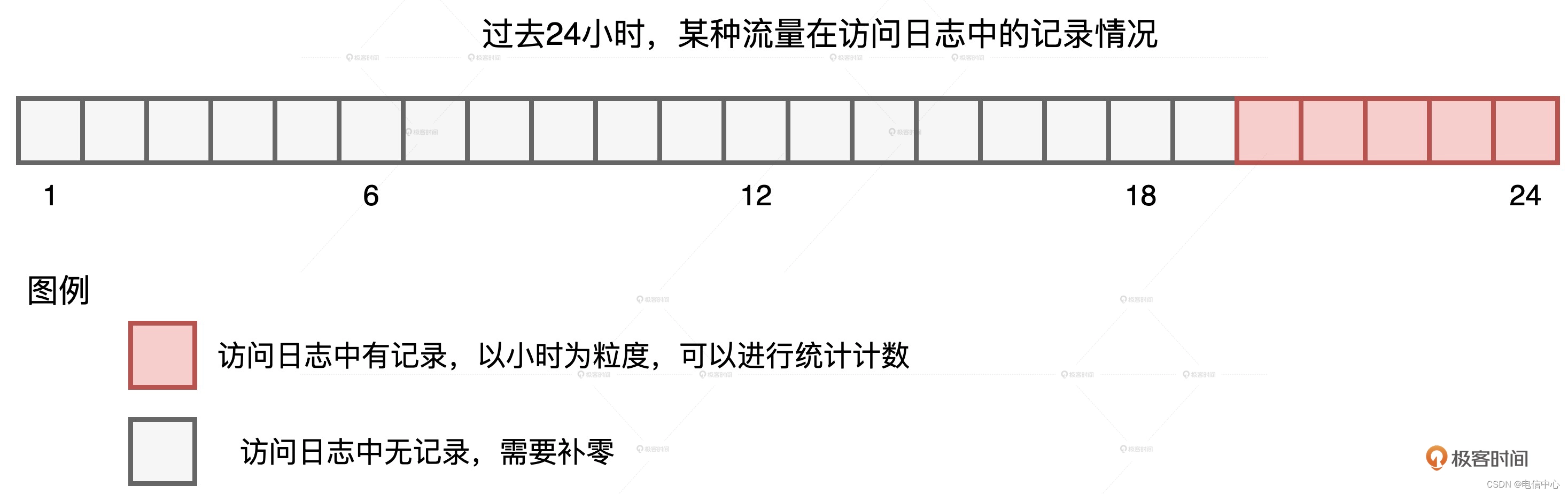
某种流量在过去24小时的记录情况我们可以看到,在过去的 24 小时中,某种流量仅在 20-24 点这 5 个时段有数据记录,其他时段无记录,也就是流量为零。在这种情况下,我们就需要用“零”去补齐缺失时段的序列值。那么我们该怎么补呢?因为业务需求是填补缺失值,所以在实现层面,我们不妨先构建出完整的全零序列,然后以系统、用户和时间这些维度组合为粒度,用统计流量去替换全零序列中相应位置的“零流量”。这个思路描述起来比较复杂,用图来理解会更直观、更轻松一些。
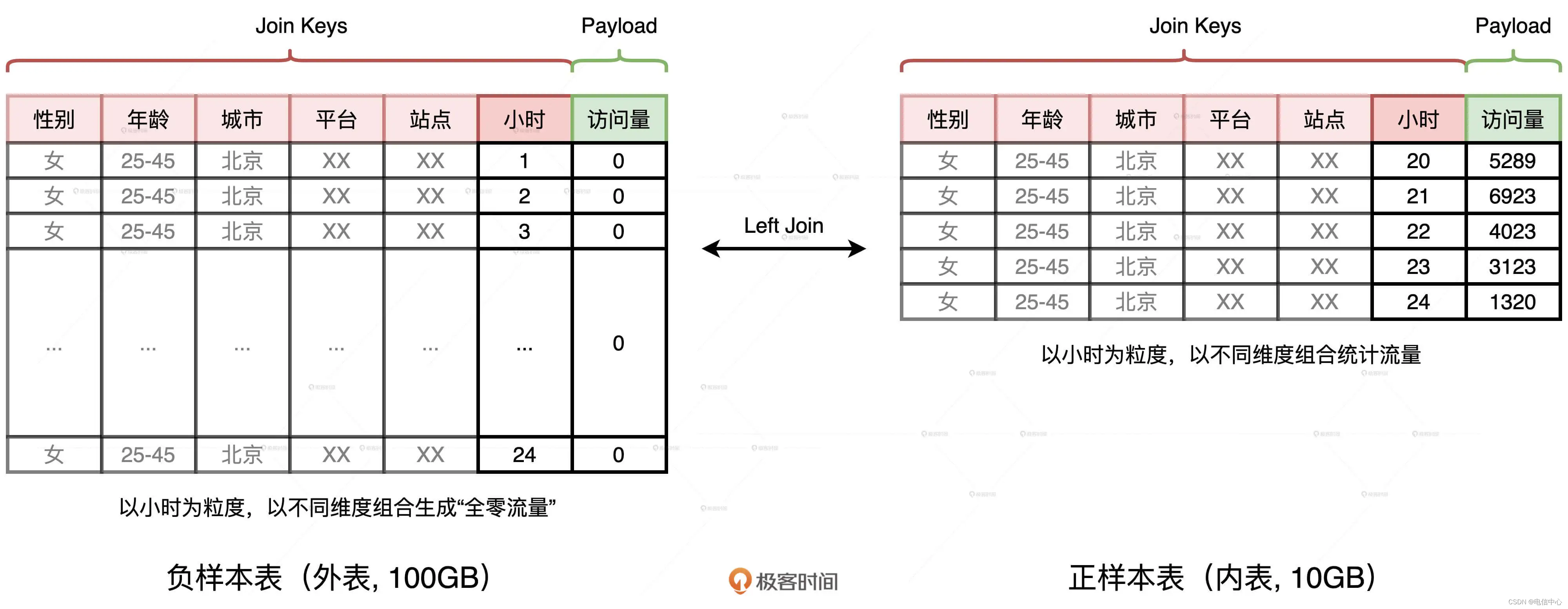
首先,我们生成一张全零流量表,如图中左侧的“负样本表”所示。这张表的主键是划分流量种类的各种维度,如性别、年龄、平台、站点、小时时段等等。表的 Payload 只有一列,也即访问量,在生成“负样本表”的时候,这一列全部置零。
然后,我们以同样的维度组合统计日志中的访问量,就可以得到图中右侧的“正样本表”。不难发现,两张表的 Schema 完全一致,要想获得完整的时序序列,我们只需要把外表以“左连接(Left Outer Join)”的形式和内表做关联就好了。具体的查询语句如下:
//左连接查询语句
select t1.gender, t1.age, t1.city, t1.platform, t1.site, t1.hour, coalesce(t2.access, t1.access) as access
from t1 left join t2 on
t1.gender = t2.gender and
t1.age = t2.age and
t1.city = t2.city and
t1.platform = t2.platform and
t1.site = t2.site and
t1.hour = t2.hour
使用左连接的方式,我们刚好可以用内表中的访问量替换外表中的零流量,两表关联的结果正是我们想要的时序序列。“正样本表”来自访问日志,只包含那些存在流量的时段,而“负样本表”是生成表,它包含了所有的时段。因此,在数据体量上,负样本表远大于正样本表,这是一个典型的“大表 Join 小表”场景。
尽管小表(10GB)与大表(100GB)相比,在尺寸上相差一个数量级,但两者的体量都不满足 BHJ 的先决条件。因此,Spark 只好退而求其次,选择 SMJ(Shuffle Sort Merge Join)的实现方式。我们知道,SMJ 机制会引入 Shuffle,将上百 GB 的数据在全网分发可不是一个明智的选择。那么,根据“能省则省”的开发原则,我们有没有可能“省去”这里的 Shuffle 呢?
要想省去 Shuffle,我们只有一个办法,就是把 SMJ 转化成 BHJ。你可能会说:“都说了好几遍了,小表的尺寸 10GB 远超广播阈值,我们还能怎么转化呢?”办法总比困难多,我们先来反思,关联这两张表的目的是什么?目的是以维度组合(Join Keys)为基准,用内表的访问量替换掉外表的零值。那么,这两张表有哪些特点呢?首先,两张表的 Schema 完全一致。其次,无论是在数量、还是尺寸上,两张表的 Join Keys 都远大于 Payload。
那么问题来了,要达到我们的目的,一定要用那么多、那么长的 Join Keys 做关联吗?答案是否定的。在上一讲,我们介绍过 Hash Join 的实现原理,在 Build 阶段,Hash Join 使用哈希算法生成哈希表。在 Probe 阶段,哈希表一方面可以提供 O(1) 的查找效率,另一方面,在查找过程中,Hash Keys 之间的对比远比 Join Keys 之间的对比要高效得多。受此启发,我们为什么不能计算 Join Keys 的哈希值,然后把生成的哈希值当作是新的 Join Key 呢?
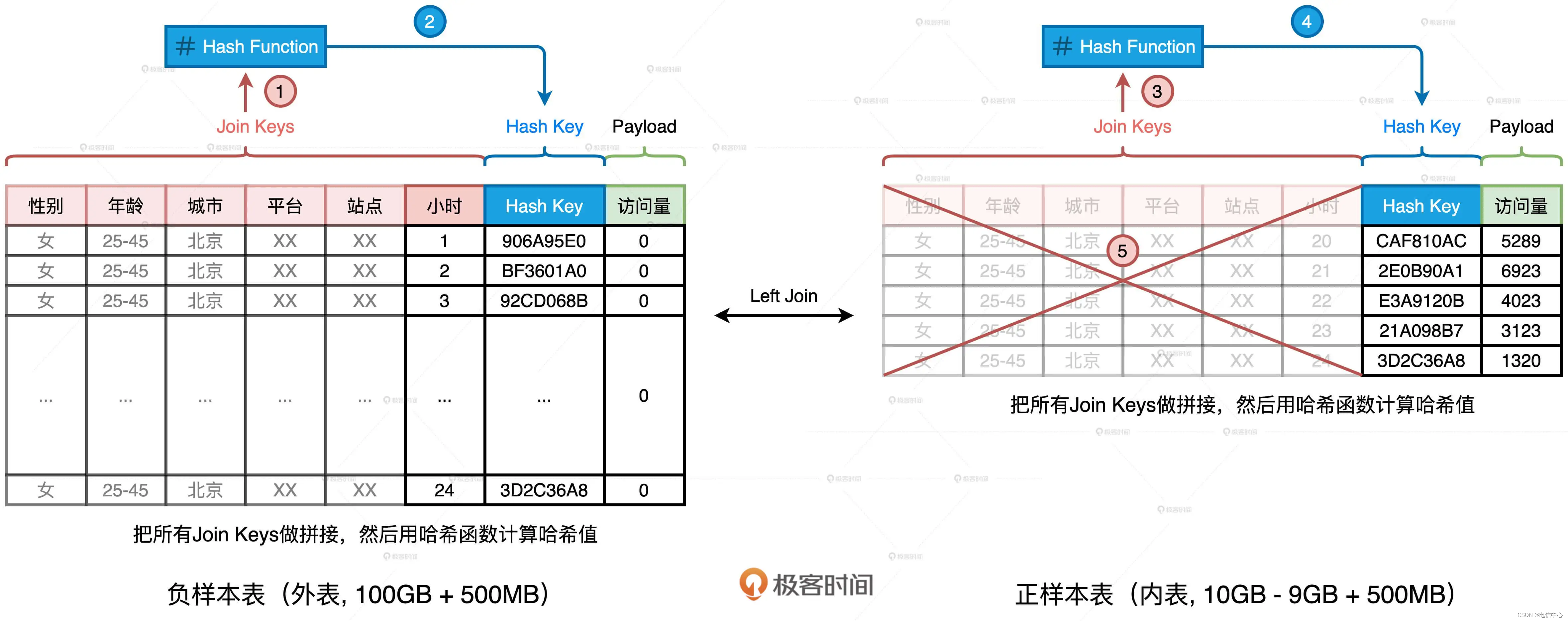
我们完全可以基于现有的 Join Keys 去生成一个全新的数据列,它可以叫“Hash Key”。生成的方法分两步:把所有 Join Keys 拼接在一起,把性别、年龄、一直到小时拼接成一个字符串,如图中步骤 1、3 所示使用哈希算法(如 MD5 或 SHA256)对拼接后的字符串做哈希运算,得到哈希值即为“Hash Key”,如上图步骤 2、4 所示在两张表上,我们都进行这样的操作。
如此一来,在做左连接的时候,为了把主键一致的记录关联在一起,我们不必再使用数量众多、冗长的原始 Join Keys,用单一的生成列 Hash Key 就可以了。相应地,SQL 查询语句也变成了如下的样子。
//调整后的左连接查询语句
select t1.gender, t1.age, t1.city, t1.platform, t1.site, t1.hour, coalesce(t2.access, t1.access) as access
from t1 left join t2 on
t1.hash_key = t2. hash_key
添加了这一列之后,我们就可以把内表,也就是“正样本表”中所有的 Join Keys 清除掉,大幅缩减内表的存储空间,上图中的步骤 5 演示了这个过程。当内表缩减到足以放进广播变量的时候,我们就可以把 SMJ 转化为 BHJ,从而把 SMJ 中的 Shuffle 环节彻底省掉。这样一来,清除掉 Join Keys 的内表的存储大小就变成了 1.5GB。对于这样的存储量级,我们完全可以使用配置项或是强制广播的方式,来完成 Shuffle Join 到 Broadcast Join 的转化,具体的转化方法你可以参考广播变量那一讲(第 13 讲)。
案例 1 说到这里,其实已经基本解决了,不过这里还有一个小细节需要我们特别注意。案例 1 优化的关键在于,先用 Hash Key 取代 Join Keys,再清除内表冗余数据。Hash Key 实际上是 Join Keys 拼接之后的哈希值。既然存在哈希运算,我们就必须要考虑哈希冲突的问题。
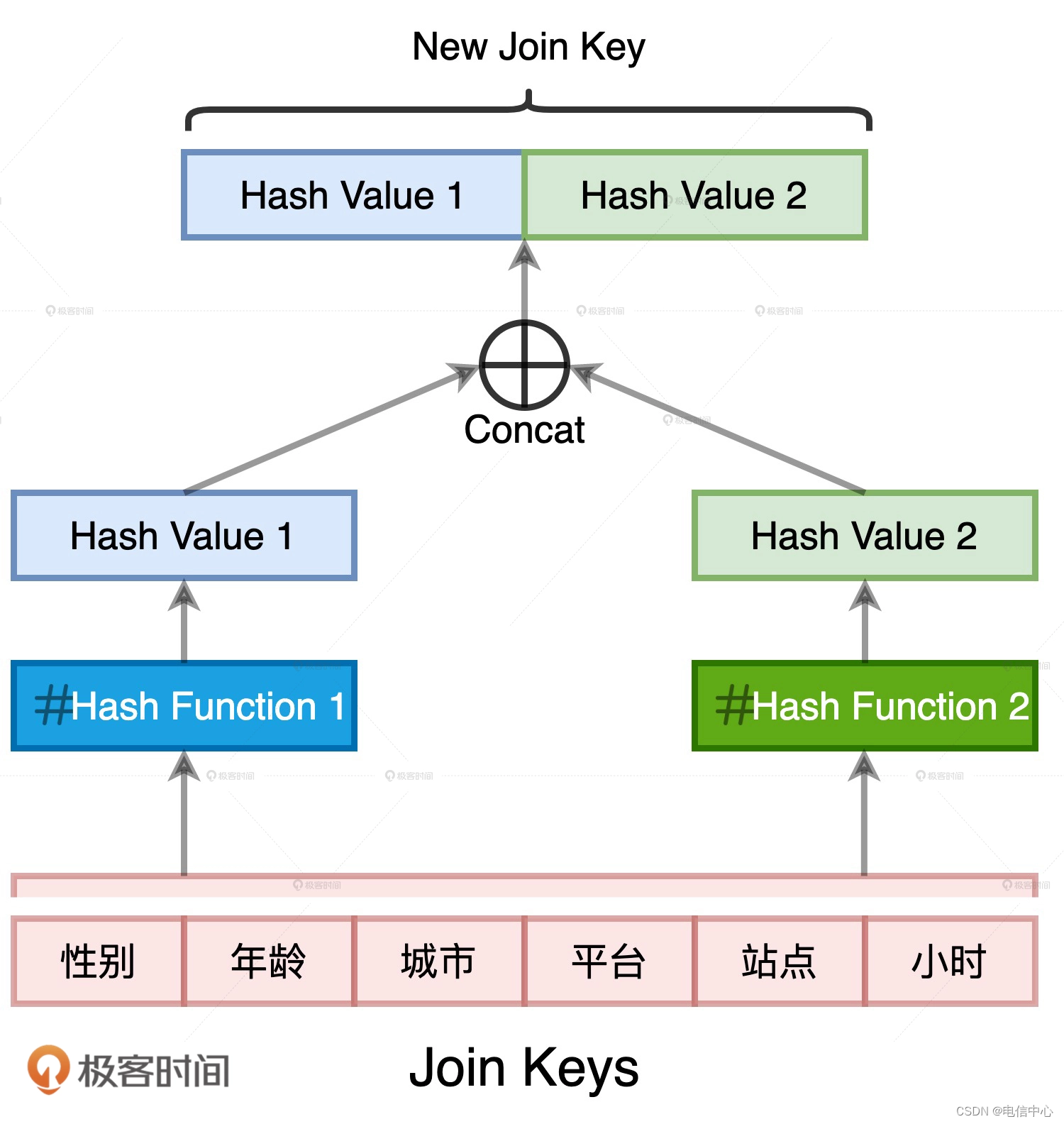
哈希冲突我们都很熟悉,它指的就是不同的数据源经过哈希运算之后,得到的哈希值相同。在案例 1 当中,如果我们为了优化引入的哈希计算出现了哈希冲突,就会破坏原有的关联关系。比如,本来两个不相等的 Join Keys,因为哈希值恰巧相同而被关联到了一起。显然,这不是我们想要的结果。消除哈希冲突隐患的方法其实很多,比如“二次哈希”,也就是我们用两种哈希算法来生成 Hash Key 数据列。两条不同的数据记录在两种不同哈希算法运算下的结果完全相同,这种概率几乎为零。
)
)

)
)

