探索大语言模型(LLM)结合有效信息检索机制的优势。实现重排序方法,并将其整合到您自己的LLM流程中。
想象一下,一个大语言模型(LLM)不仅能提供相关答案,还能根据您的具体需求进行精细筛选、优先级排序和优化。尽管LLM已经彻底改变了人工智能领域,但它们并非没有局限性。例如,幻觉问题和数据过时可能会影响其输出的准确性和相关性。这时,检索增强生成(RAG)和重排序技术应运而生,它们通过将LLM与动态、最新的信息检索流程相结合,显著提升了模型的表现。想了解具体实现步骤吗?请继续阅读。
为什么使用RAG增强LLM?
LLM已经彻底改变了人工智能领域,并拓展了AI的应用边界。它们成为几乎所有领域寻求多功能自然语言处理(NLP)解决方案的首选工具,能够处理各种自然语言理解和生成任务,如下图所示。
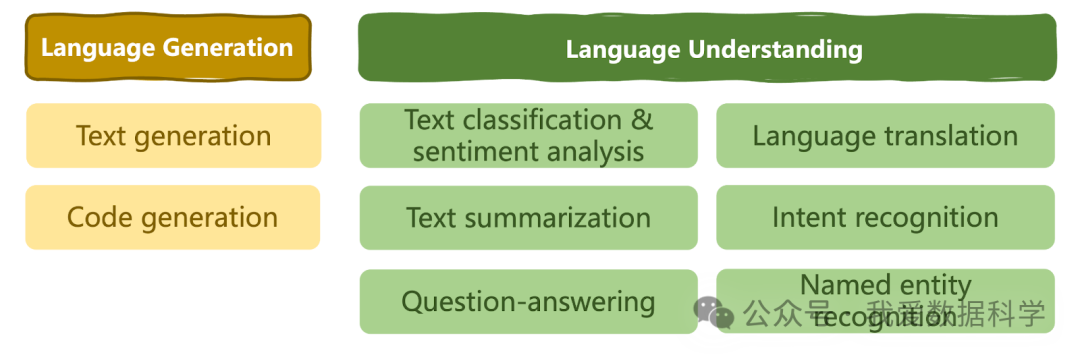
尽管LLM能力强大,但在某些场景下仍存在局限性。根据具体用例和训练数据的范围,LLM有时无法生成连贯、相关或上下文适宜的文本。甚至在某些情况下,当缺乏真实数据来回答用户查询时,它们可能会生成看似正确实则错误的荒谬信息。这种现象被称为“幻觉”。
例如,对于问题:“流感的常见症状有哪些?”
一个标准的LLM可能会基于通用知识生成答案,列出如发烧、咳嗽和身体疼痛等症状。然而,除非模型接受过特定领域的流感病毒数据训练,否则它可能无法考虑症状严重程度的变化或区分不同流感毒株,从而为不同用户提供千篇一律的“自动化”回答。
此外,如果模型的训练数据截至2023年12月,而2024年1月出现了一种新型流感毒株并迅速传播,那么独立的LLM将无法提供准确回答,因为它缺乏最新的领域知识。这种“数据过时”问题被称为知识截止。
在某些情况下,解决方案可能是频繁地重新训练和微调LLM以纳入最新信息。但这是最佳选择吗?
众所周知,LLM的训练过程复杂且计算成本高昂。它们需要数百万到数十亿的文本数据实例,通常还需要数千个特定领域的文本进行微调(如下图所示)。
这时,RAG(检索增强生成) 便派上了用场!
RAG是一种信息检索流程,通过优化LLM的输出,使其不仅依赖于训练数据的知识,还能从外部知识库中检索信息。通过结合这两种方法,RAG可以提升LLM生成答案的质量、用户相关性、连贯性和真实性,从而大大减少为适应新场景而频繁重新训练LLM的需求。
简化的RAG系统工作流程如下:
-
查询:LLM收集用户查询或提示。
-
检索:在运行时,LLM通过检索组件访问文本语料库,并识别与用户查询最匹配的前K个文档。
-
生成:LLM结合原始用户输入和检索到的文档,基于最大似然原则生成回答。
回到流感示例,通过RAG,模型可以从医学数据库或最新文章中检索到最新、相关的信息,从而为患者或医生提供更细致、准确的答案。它能够结合当前流感毒株、症状的地区差异或新出现的模式,生成更符合用户需求的回答。
什么是重排序?
重排序是一种信息检索流程,通过对初始检索结果重新排序,以提升其与用户查询、需求和上下文的相关性,从而优化整体输出质量。其工作原理如下:
-
首先,检索器进行初步文档检索,获取K个相关文档。常用方法包括TF-IDF、向量空间模型等。
-
随后,排序器介入,这是一种比初始检索器更复杂或更专业的机制。排序器基于额外标准(如用户偏好、上下文或更复杂的算法)重新评估检索结果,以提升结果的针对性。
以下图表展示了重排序流程:
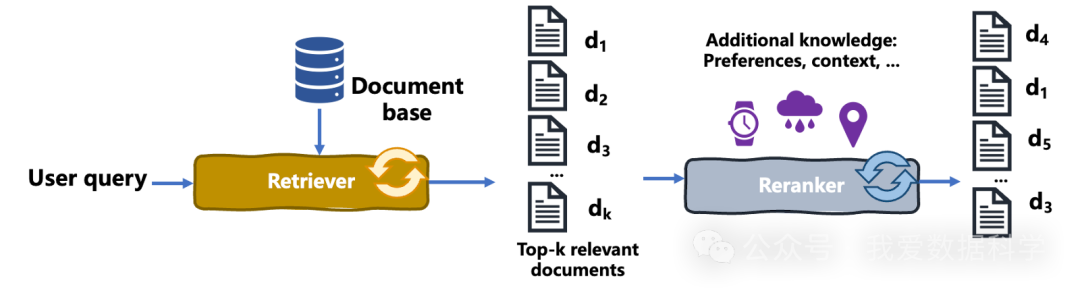
需要明确的是,重排序是基于多种标准(如用户偏好)对检索文档重新排序。但重排序不同于推荐引擎,后者是根据用户长期交互和偏好主动生成个性化建议,而重排序则用于实时响应用户查询的搜索场景。
以流感为例,假设一位医疗专业人员搜索“流感症状的最佳治疗方法”。初始检索系统可能返回一系列文档,包括通用流感信息、治疗指南和研究文章。而重排序模型可以结合患者特定数据和上下文信息,将这些文档重新排序,优先显示最相关、最新的治疗协议和同行评审研究,从而直接命中问题核心。
为什么重排序对结合RAG的LLM有用?
重排序对于结合检索增强生成(RAG)的大语言模型(LLM)尤为有用。RAG通过将LLM与外部文档检索相结合,提供更准确和全面的回答。在初始检索完成后,重排序可以进一步优化文档选择,确保LLM处理的是最相关和高质量的信息。这一流程显著提升了LLM的整体表现,尤其在需要精确信息的专业领域。
重排序器的类型
实现重排序器的方法多种多样,以下是几种常见类型:
-
多向量重排序器:为文档和用户查询分配多个向量表示,通过向量相似性对结果重新排序。
-
学习排序(LTR):广泛应用于推荐算法,通过机器学习原理和训练数据预测最优结果排序。
-
基于BERT的重排序器:利用BERT模型理解检索文档的语义细微差别,并优化其排序。
-
强化学习重排序器:基于持续的用户交互数据,通过长期奖励函数(如用户满意度)优化排序。
-
混合重排序器:结合多种重排序策略,例如将LTR与多种机器学习或深度学习模型结合。
构建带重排序的RAG流程
现在,我们已经了解了将RAG整合到LLM中的优势,以及知识检索中的重排序机制。接下来,我们将通过一个示例展示如何将这些元素整合并实际应用。
本示例使用Langchain库(社区版)构建一个简单的带重排序的RAG流程。
代码已在Google Colab笔记本中实现。
版本1 - 不带重排序
pip install -U langchain-community首先,我们在笔记本中安装langchain-community。
接下来,导入必要的包、类和函数。
import osfrom langchain.vectorstores import FAISSfrom langchain.embeddings import OpenAIEmbeddingsfrom langchain.llms import OpenAIfrom langchain.prompts import PromptTemplatefrom langchain.text_splitter import CharacterTextSplitterfrom langchain.schema import Documentfrom langchain.chains.qa_with_sources import load_qa_with_sources_chainfrom sklearn.metrics.pairwise import cosine_similarityimport numpy as np
以下函数用于从本地目录加载文档(.txt文件),这些文档将被检索并用于增强LLM的输出:
# 从目录加载文档的函数def load_documents_from_directory(directory_path):documents = []for filename in os.listdir(directory_path):if filename.endswith(".txt"):with open(os.path.join(directory_path, filename), 'r') as file:documents.append(file.read())return documents# 从指定目录加载文档directory_path = "./sample_data"documents = load_documents_from_directory(directory_path)
为了优化文本文档的嵌入表示性能,我们将其大小限制为1000个字符,并使用CharacterTextSplitter将较长的文档分割为小块。chunk_overlap参数设置为0,以避免文本块之间的重叠。
# 将文档分割为小块以优化嵌入性能text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)docs = text_splitter.split_documents(documents)
我们使用OpenAI嵌入构建嵌入向量存储。根据运行环境,可能需要从OpenAI获取验证密钥并定义在OPENAI_API_KEY中。
# 初始化OpenAI嵌入embeddings = OpenAIEmbeddings()# 基于文档块嵌入构建FAISS向量存储vector_store = FAISS.from_documents(docs, embeddings)# 加载并初始化OpenAI LLMllm = OpenAI(model="text-davinci-003", temperature=0.7)
FAISS通过from_documents()函数从嵌入创建向量存储。我们需要传递两个参数:文档块和通过OpenAIEmbeddings初始化的嵌入实例。接下来,我们引入主角之一:LLM!这里使用OpenAI加载text-davinci-003模型,并将温度设置为0.7,以允许一定程度的文本生成原创性。
继续以下步骤:
# 定义LLM的提示模板prompt_template = PromptTemplate(template="Answer the question based on the context: {context}\n\nQuestion: {question}\nAnswer:")# 使用QA链定义带检索的RAG流程qa_chain = load_qa_with_sources_chain(llm, prompt_template=prompt_template, retriever=vector_store.as_retriever())# 示例问题question = "What are the common symptoms of the flu and how can it be treated?"# 使用QA链生成答案response = qa_chain(question=question)print(response)
上述代码首先定义了一个问答提示模板,然后调用load_qa_with_sources_chain()函数创建问答流程(在Langchain中称为“链”)。其retriever参数允许将检索组件整合到LLM流程中,从而实现RAG。最后,我们提出问题并运行定义的流程qa_chain。完成!
以下是输出(具体内容取决于读取的文档):
"流感的常见症状包括发烧、咳嗽、喉咙痛、流鼻涕或鼻塞、身体疼痛、头痛、发冷和疲劳。有些人可能会出现呕吐和腹泻,尤其是儿童。流感可以通过抗病毒药物治疗,这些药物可以减轻症状并缩短病程。抗病毒药物还可以预防肺炎等严重并发症。建议病情严重或并发症高风险人群及时治疗。"
版本2 - 带重排序
之前的示例看起来不错,但缺少重排序环节。修改代码以加入重排序相对简单。
导入列表与之前相同,因为我们已经为重排序环节导入了所有必要的包(尽管之前并未使用部分包):
# 之前的代码...# 定义LLM的提示模板prompt_template = PromptTemplate(template="Answer the question based on the context: {context}\n\nQuestion: {question}\nAnswer:")# 重排序函数def rerank_documents(question, retrieved_docs, top_n=5):question_embedding = embeddings.embed_text(question)doc_embeddings = [doc.embedding for doc in retrieved_docs]similarities = cosine_similarity([question_embedding], doc_embeddings)[0]ranked_indices = np.argsort(similarities)[::-1] # 按相似度降序排序ranked_docs = [retrieved_docs[i] for i in ranked_indices[:top_n]]return ranked_docs
如上所示,我们首先定义了一个rerank_documents函数,该函数使用嵌入的余弦相似度来计算问题嵌入与文档嵌入之间的相似性,并返回排名前n的文档。
# 自定义带重排序的QA链class CustomQAWithReranking:def __init__(self, llm, retriever, prompt_template, top_n=5):self.llm = llmself.retriever = retrieverself.prompt_template = prompt_templateself.top_n = top_ndef __call__(self, question):retrieved_docs = self.retriever.retrieve_documents(question)ranked_docs = rerank_documents(question, retrieved_docs, self.top_n)context = "\n".join([doc.page_content for doc in ranked_docs])prompt = self.prompt_template.format(context=context, question=question)return self.llm(prompt)
CustomQAWithReranking类将检索和重排序步骤整合到LLM流程中,通过调用该类的__call__函数实现。
# 定义带重排序的自定义QA链qa_chain = CustomQAWithReranking(llm, vector_store.as_retriever(), prompt_template)# 示例问题question = "What are the benefits of using multi-vector rerankers?"# 使用自定义QA链生成答案response = qa_chain(question)
剩下的就是再次实例化qa_chain。这次我们通过定义刚刚创建的类的对象来实现,该类封装了之前版本的大部分逻辑以及我们的自定义重排序机制。最后,我们提出问题并调用链以获取回答。
了解更多关于AI的内容
在LLM和AI领域,RAG无疑已成为一项重要技术。通过让LLM在生成回答时访问和检索外部知识源,RAG已成为频繁重新训练和微调LLM的广泛替代方案。
本文讨论了重排序作为一种有效的信息检索方法,可以整合到LLM流程中。它详细介绍了重排序的工作原理、不同类型的重排序器,以及一个使用Langchain和OpenAI API的实际示例。
2022 版安装与下载教程)
)




