多层感知机(MLP)实现Fashion-MNIST分类
import torch
from torch import nn
from d2l import torch as d2l
# 使用d2l库加载Fashion-MNIST数据集
# 批量大小设为256,适合中等规模GPU训练
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
4.2.1 初始化模型参数
num_inputs, num_outputs, num_hiddens = 784, 10, 256W1 = nn.Parameter(torch.randn(num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
输入维度784(28x28图像展平)
隐藏层256个神经元
输出10类(对应10种服装类别)
权重使用randn初始化并缩小100倍(*0.01)
偏置初始化为0
4.2.2 激活函数
def relu(X):a = torch.zeros_like(X)return torch.max(X, a)
实现ReLU函数:max(0, x)
比Sigmoid/Tanh更高效且缓解梯度消失
4.2.3 模型
def net(X):X = X.reshape(-1, num_inputs)H = relu(X@W1 + b1) # @=矩阵乘法return (H@W2 + b2)
前向传播流程:输入 → 展平 → 线性变换 → ReLU → 线性变换 → 输出
4.2.4 损失函数
loss = nn.CrossEntropyLoss(reduction='none') # 交叉熵损失
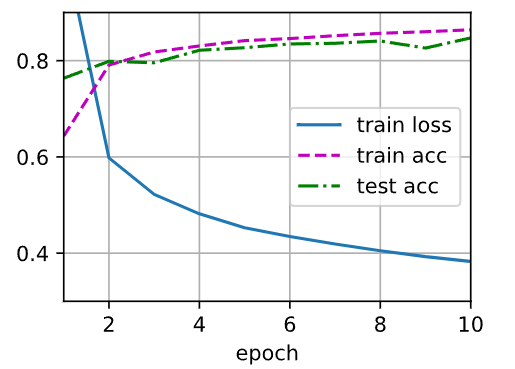
4.2.5 训练
num_epochs, lr = 10, 0.1 # 10轮训练,学习率0.1
updater = torch.optim.SGD(params, lr=lr) # SGD优化器
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
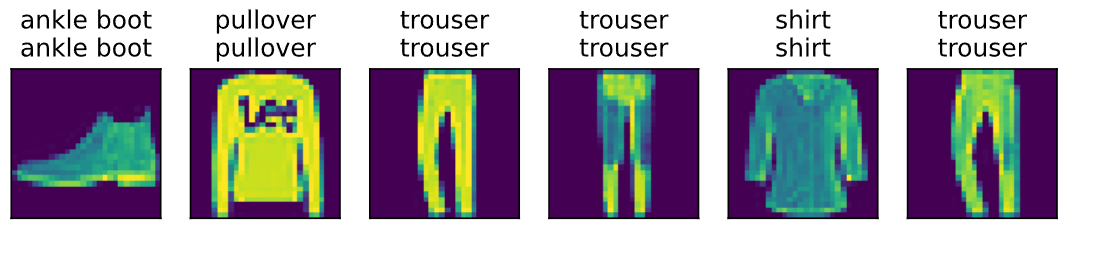
d2l.predict_ch3(net, test_iter)
![高级java每日一道面试题-2025年4月28日-基础篇[反射篇]-反射操作中,`invoke()`方法的作用是什么?](http://pic.xiahunao.cn/nshx/高级java每日一道面试题-2025年4月28日-基础篇[反射篇]-反射操作中,`invoke()`方法的作用是什么?)



![零基础上手Python数据分析 (终章):[综合案例实战] 视频游戏销售分析 - 全流程演练,从数据到洞察](http://pic.xiahunao.cn/nshx/零基础上手Python数据分析 (终章):[综合案例实战] 视频游戏销售分析 - 全流程演练,从数据到洞察)

:大模型NL2SQL绘制城市之间连线)