YOLO V10安装、使用、训练大全
- 一、下载官方源码
- 二、配置conda环境
- 三、安装YOLOV10依赖
- 四、使用官方YOLO V10模型
- 1.下载模型
- 2.使用模型
- 2.1 图片案例
- 五、制作数据集
- 1.数据集目录结构
- 2.标注工具
- 2.1 安装标注工具
- 2.2 运行标注工具
- 2.3 设置自动保存
- 2.4 切换yolo模式
- 2.5 开始标注
- 2.6 数据集准备
- 2.6.1 数据集文件夹准备
- 2.6.2 xml格式转yolo的txt训练格式
- 3.训练
- 3.1 创建训练配置文件
- 3.2 命令训练
- 3.3 代码训练
- 4.测试模型
- 4.1 图片
- 4.1.1 命令行
- 4.1.2 代码
- 4.2 视频
- 4.2.1 命令行
- 4.2.2 代码
一、下载官方源码
- 源码点击下载
二、配置conda环境
# 1.在conda创建python3.9环境
conda create -n yolov10 python=3.9
# 2.激活切换到创建的python3.9环境
conda activate yolov10
三、安装YOLOV10依赖
# 1.切换到yolov10源码根目录下,安装依赖
# 注意:会自动根据你是否有GPU自动选择pytorch版本进行按照,这里不需要自己去选择pytorch和cuda按照,非常良心
pip install -r requirements.txt -i https://pypi.doubanio.com/simple
# 2.运行下面的命令,才可以在命令行使用yolo等命令
pip install -e .
四、使用官方YOLO V10模型
1.下载模型
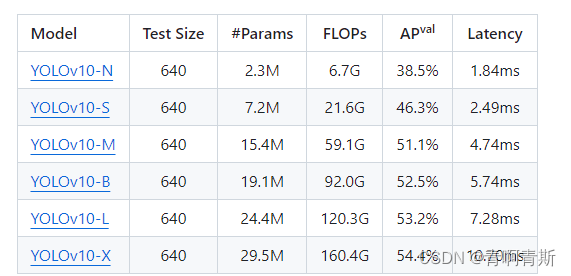
- 模型下载
- YOLOv10-N:https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10n.pt
- YOLOv10-S:https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10s.pt
- YOLOv10-M:https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10m.pt
- YOLOv10-B:https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10b.pt
- YOLOv10-L:https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10l.pt
- YOLOv10-X:https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10x.pt
- 下载完放入源码根目录
2.使用模型
2.1 图片案例
import cv2
from ultralytics import YOLOv10# 加载模型
model = YOLOv10("yolov10m.pt")# 批量运算
results = model(["./datasets/group1/images/train/9597185011003UY_20240610_092234_555.png"], stream=True)for result in results:boxes_cls_len = len(result.boxes.cls)if not boxes_cls_len:# 没有检测到内容continuefor boxes_cls_index in range(boxes_cls_len):# 获取类别idclass_id = int(result.boxes.cls[boxes_cls_index].item())# 获取类别名称class_name = result.names[class_id]# 获取相似度similarity = result.boxes.conf[boxes_cls_index].item()# 获取坐标值,左上角 和 右下角:lt_rb的值:[1145.1351318359375, 432.6763000488281, 1275.398681640625, 749.5224609375]lt_rb = result.boxes.xyxy[boxes_cls_index].tolist()# 转为:[[1145.1351318359375, 432.6763000488281], [1275.398681640625, 749.5224609375]]lt_rb = [[lt_rb[0], lt_rb[1]], [lt_rb[0], lt_rb[1]]]print("类别:", class_name, "相似度:", similarity, "坐标:", lt_rb)# 图片展示annotated_image = result.plot()annotated_image = annotated_image[:, :, ::-1]if annotated_image is not None:cv2.imshow("Annotated Image", annotated_image)cv2.waitKey(0)cv2.destroyAllWindows()
五、制作数据集
- 一般会将所有图片放到一个文件夹,打完标注后,从总的文件夹中,分别分不同的图片到训练集和数据集
1.数据集目录结构
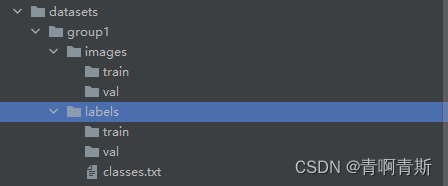
2.标注工具
- Labelimg是一款开源的数据标注工具,可以标注三种格式。
- VOC标签格式,保存为xml文件。
- yolo标签格式,保存为txt文件。
- createML标签格式,保存为json格式。
2.1 安装标注工具
pip install labelimg -i https://pypi.doubanio.com/simple
2.2 运行标注工具
- labelimg:运行工具
- images:图片文件夹路径
- classes.txt:类别的文件
labelimg images label/classes.txt
2.3 设置自动保存
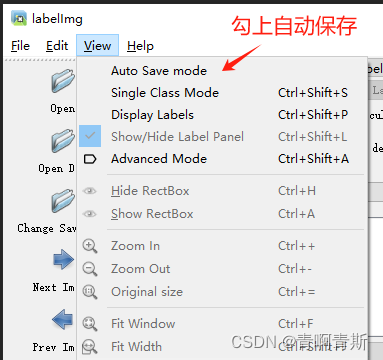
2.4 切换yolo模式
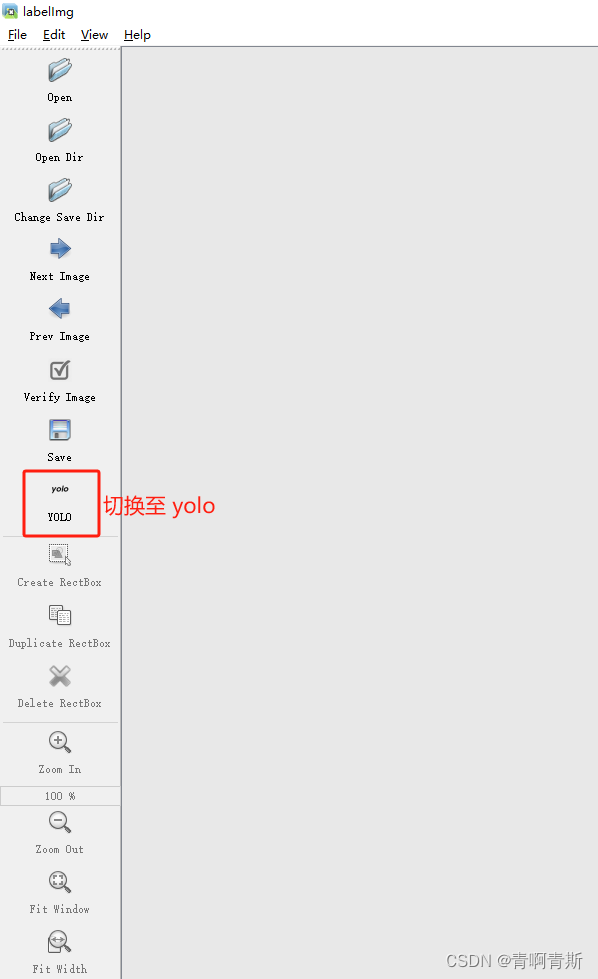
2.5 开始标注

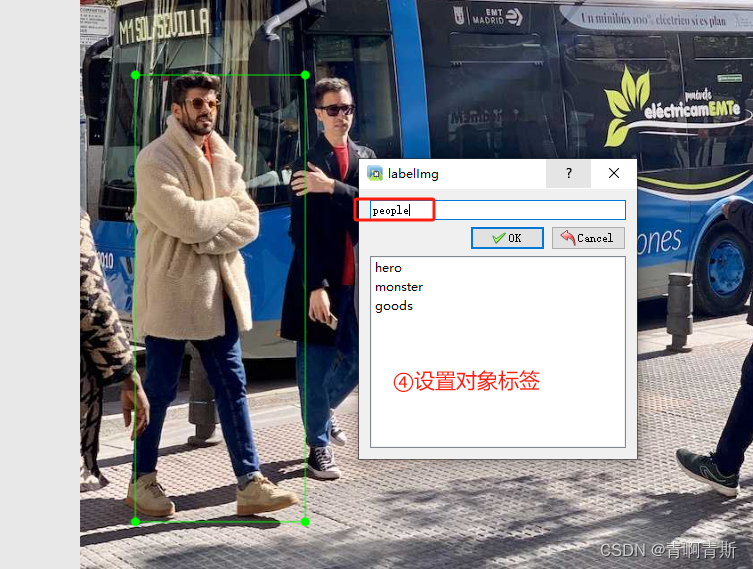
标注完退出软件即可
2.6 数据集准备
2.6.1 数据集文件夹准备
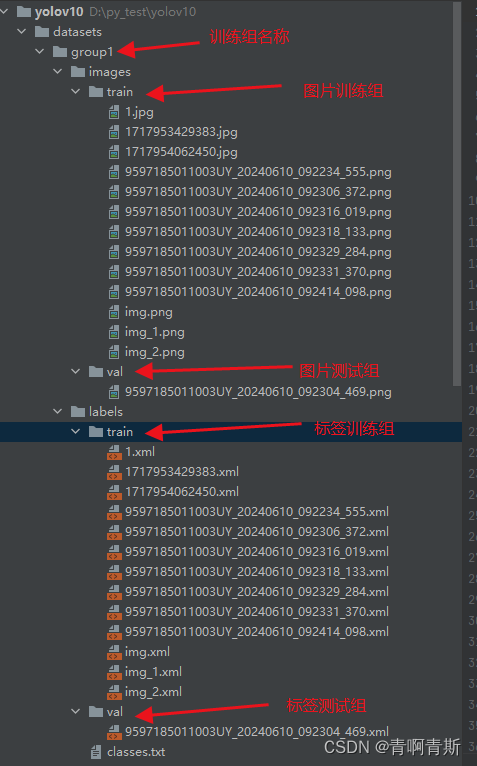
yolo的label文件内容:
<class_index> <x_center> <y_center> <width> <height>
2.6.2 xml格式转yolo的txt训练格式
- 运行下面脚本,就会转换
import os
import xml.etree.ElementTree as ETclasses = ['hero', 'monster', 'goods']def convert(size, box):dw = 1. / size[0]dh = 1. / size[1]x = (box[0] + box[1]) / 2.0y = (box[2] + box[3]) / 2.0w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn (x, y, w, h)def convert_annotation(xml_file_paths, is_delete=False):"""将某个文件夹下面所有的xml转换为yolo格式"""for xml_file_path in xml_file_paths:xml_file_dir, xml_file_name = os.path.split(xml_file_path)in_file = open(xml_file_path, 'r')out_file = open(os.path.join(xml_file_dir, xml_file_name[:-4]) + '.txt', 'w')tree = ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):cls = obj.find('name').textif cls not in classes:print(cls)continuecls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))bb = convert((w, h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')def traverse_folder(folder_path):"""获取某个文件夹下面所有的xml文件"""for root, dirs, files in os.walk(folder_path):for file in files:if file.lower().endswith(('.xml')):yield os.path.join(root, file)if __name__ == '__main__':convert_annotation(traverse_folder(os.path.join(".", "datasets", "group1", "labels")))
- txt格式就是yolo训练的格式
3.训练
3.1 创建训练配置文件
- group1.yaml:文件和datasets文件夹同一个目录
path: group1 # dataset root dir
train: images/train # train images (relative to 'path') 128 images
val: images/val # val images (relative to 'path') 128 images
test: # test images (optional)# Classes
names:0: hero1: monster2: goods
3.2 命令训练
yolo task=detect mode=train data=group1.yaml model=yolov10m.pt epochs=100 batch=16 device=cpu plots=True
- 上述各个参数解释如下,请根据自己的情况修改。
- yolo:运行yolo程序
- task=detect:指定任务为检测(detect)。YOLO模型可以用于不同的任务,如检测、分类等,这里明确指定为检测任务。
- mode=train:指定模式为训练(train)。这意味着你将使用提供的数据集来训练模型。
- data=group1.yaml:指定你自己的数据集yaml文件
- model=yolov10m.pt: 指定下载的yolov10预训练权重文件
- epochs=100:设置训练轮次,可以先设置一个5轮或者10轮,测试看看,顺利进行再设置大一点进行下一步训练。
- batch=4:设置训练集加载批次,主要是提高训练速度,具体得看你的显卡或者内存容量。如果显存大,则可以设置大一些。或许训练再详细讲解如何设置
- device=0:指定训练设备,如果没有gpu,则令device=cpu,如果有一个gpu,则令device=0,有两个则device=0,1以此类推进行设置。
- plots:指定在训练过程中生成图表(plots)。这可以帮助你可视化训练进度,如损失函数的变化等。
3.3 代码训练
- 待补充
4.测试模型
4.1 图片
4.1.1 命令行
yolo task=detect mode=predict conf=0.25 save=True model=runs/detect/train/weights/best.pt source=test_images_1/veh2.jpg
- 上述各个参数解释如下,请根据自己的情况修改。
- yolo:运行yolo程序
- task=detect:指定任务为检测(detect)。YOLO模型可以用于不同的任务,如检测、分类等,这里明确指定为检测任务。
- mode=predict:设置模式为预测(predict)。这意味着模型将使用提供的权重和图像进行预测,而不是进行训练。
- conf=0.25:设置置信度阈值为0.25。这意味着只有模型预测置信度大于或等于0.25的检测结果才会被考虑。
- save=True:指示模型保存预测结果。这通常会将结果保存为图像文件,其中检测到的对象会被标记出来。
- model=runs/detect/train/weights/best.pt:指定模型权重文件的位置。这里,best.pt是训练过程中保存的最佳权重文件,用于进行预测。
- source=test_images_1/veh2.jpg:指定要检测的源图像。这里,veh2.jpg是要进行对象检测的图像文件。
4.1.2 代码
from ultralytics import YOLOv10
import supervision as sv
import cv2classes = {0: 'licence'}model = YOLOv10('runs/detect/train6/weights/best.pt')
image = cv2.imread('veh2.jpg')results = model(source=image, conf=0.25, verbose=False)[0]
detections = sv.Detections.from_ultralytics(results)
# 使用新的标注器
bounding_box_annotator = sv.BoundingBoxAnnotator()
label_annotator = sv.LabelAnnotator()labels = [f"{classes[class_id]} {confidence:.2f}"for class_id, confidence in zip(detections.class_id, detections.confidence)
]# 首先使用边界框标注器
annotated_image = bounding_box_annotator.annotate(image.copy(), detections=detections
)# 然后使用标签标注器
annotated_image = label_annotator.annotate(annotated_image, detections=detections, labels=labels
)cv2.imshow('result', annotated_image)
cv2.waitKey()
cv2.destroyAllWindows()
4.2 视频
4.2.1 命令行
yolo task=detect mode=predict conf=0.25 save=True model=runs/detect/train/weights/best.pt source=b.mp4
- 上述各个参数解释如下,请根据自己的情况修改。
- yolo:运行yolo程序
- task=detect:指定任务为检测(detect)。YOLO模型可以用于不同的任务,如检测、分类等,这里明确指定为检测任务。
- mode=predict:设置模式为预测(predict)。这意味着模型将使用提供的权重和图像进行预测,而不是进行训练。
- conf=0.25:设置置信度阈值为0.25。这意味着只有模型预测置信度大于或等于0.25的检测结果才会被考虑。
- save=True:指示模型保存预测结果。这通常会将结果保存为图像文件,其中检测到的对象会被标记出来。
- model=runs/detect/train/weights/best.pt:指定模型权重文件的位置。这里,best.pt是训练过程中保存的最佳权重文件,用于进行预测。
- source=b.mp4:指定要检测的源视频。
4.2.2 代码
from ultralytics import YOLOv10
import supervision as sv
import cv2classes = {0: 'licence'}model = YOLOv10('runs/detect/train6/weights/best.pt')def predict_and_detect(image):results = model(source=image, conf=0.25, verbose=False)[0]detections = sv.Detections.from_ultralytics(results)# 使用新的标注器bounding_box_annotator = sv.BoundingBoxAnnotator()label_annotator = sv.LabelAnnotator()labels = [f"{classes[class_id]} {confidence:.2f}"for class_id, confidence in zip(detections.class_id, detections.confidence)]# 首先使用边界框标注器annotated_image = bounding_box_annotator.annotate(image.copy(), detections=detections)# 然后使用标签标注器annotated_image = label_annotator.annotate(annotated_image, detections=detections, labels=labels)return annotated_imagedef create_video_writer(video_cap, output_filename):# grab the width, height, and fps of the frames in the video stream.frame_width = int(video_cap.get(cv2.CAP_PROP_FRAME_WIDTH))frame_height = int(video_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))fps = int(video_cap.get(cv2.CAP_PROP_FPS))# initialize the FourCC and a video writer objectfourcc = cv2.VideoWriter_fourcc(*'MP4V')writer = cv2.VideoWriter(output_filename, fourcc, fps,(frame_width, frame_height))return writervideo_path = 'b.mp4'
cap = cv2.VideoCapture(video_path)output_filename = "out.mp4"
writer = create_video_writer(cap, output_filename)while True:success, img = cap.read()if not success:breakframe = predict_and_detect(img)writer.write(frame)cv2.imshow("frame", frame)if cv2.waitKey(1) & 0xFF == 27: # 按下Esc键退出breakcap.release()
writer.release()


)
——动画数据的优化)
)

