总述:
-
undolog日志是inndb存储引擎层生成的日志,实现了事务的原子性,主要用于事务回滚和MVCC。
-
redolog日志是inndb存储引擎层生成的日志,实现了事务的持久性,主要用于掉电等故障恢复。
-
binlog日志是Server层生成的日志,主要用于数据备份和主从复制。
undolog回滚日志
undolog是如何实现事务回滚和MVCC?
三个隐藏字段:事务id、回滚指针、主键(如果我们在表中没有指定主键,则会创建一个默认的隐藏主键row_id,如果表中有主键,则不会创建)。
在我们开启事务后,执行事务的过程中,如果我们对数据进行增删改操作,会先记录undolog日志,记录数据变更之前的信息,然后更新数据库中的记录,并且记录本次操作的事务ID、回滚指针。通过回滚指针,我们可以构建出每条记录的版本链,即数据库中每一条记录的历史版本信息。
通过构建的版本链,如果我们在执行事务的过程中发生了异常,这时候就会根据版本链的信息将每条记录中回滚到旧值。
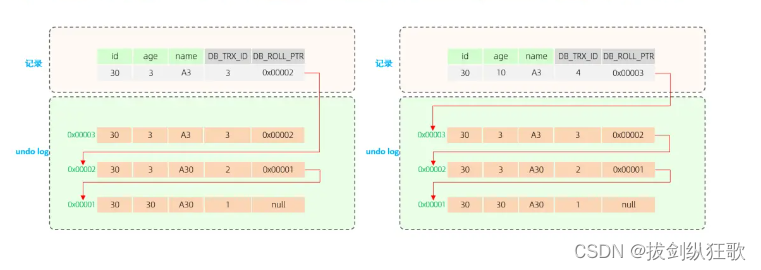
MVCC的实现是利用版本链和开启ReadView快照读时记录的信息,根据一定的规则去判断修改记录的事务是否已经提交。如果提交了,在读已提交的隔离级别下就可以读取到已提交事务的信息了;如果在可重复读隔离级别下,则会在后续的ReadView中复用之前的视图,只能看到第一次创建ReadView时候的数据信息。
redolog重做日志
为什么需要redolog,解决了什么问题?
我们做数据的增删改操作时,并不是直接将数据写入到磁盘中,而是先将数据写入到Buffer Pool缓存中。如果我们每次将数据都写入到磁盘,将会导致磁盘I/O频繁,内存开销大。有了Buffer Pool之后,我们的具体操作流程为:
-
读取数据时,如果数据存在于Buffer Pool中,客户端直接读取Buffer Pool中的数据,否则再去磁盘中读取。
-
当修改数据时,如果数据存在于Buffer Pool当中,那直接修改Buffer Pool所在的页,然后将其页设置为脏页(该页内存数据和磁盘数据已经不一致了),为了减少磁盘I/O,不会立即将脏页写入到磁盘,后续由后台线程在一个合适的时机将脏页写入磁盘。
引入Buffer Pool做数据缓存解决了频繁读写I/O的问题,但是又导致了缓存中的数据和磁盘中的数据存在不一致的问题。即我们更新完缓存中的数据,这时候还没来得及更新磁盘中的数据,mysql发生故障,导致缓存中的数据丢失,数据持久化失败。
为了解决这个问题,MySQL在Innodb存储引擎层引入了redolog日志。这时候,当有一条数据更新的时候,InnoDB引擎就会先更新内存(同时标记为脏页),然后将本次对这个页的修改以redo log的形式记录下来,这时候更新就算完成了。后续InnoDB存储引擎会在后台启动一个线程,将redolog中的记录写入到磁盘中,并将binlog中已经写入磁盘的内容清空,这时候更新操作最终完成。
有的同学可能会有疑问?我将更新的操作写入到redolog中也是做磁盘的IO操作,为什么不直接将数据写入到数据库中呢?先写入到redolog中,再写入到数据库中不是更加浪费开销吗?
要解答这个问题,首先我们需要先了解一下常见的两种写入磁盘的方式:
-
顺序写入:我们向磁盘中写入数据遵循一定的规则,比如从头到尾。
-
随机写入:我们向磁盘中写入数据是随机的,一会写到这里,一会写到那里。
打个比方:就像我们写作业一样,顺序写入是从第一页写到最后一页;而随机写入则是我们一会写到第一页,一会写到第五页。我们进行顺序写入是操作比随机写入的操作要快很多,这也是MySQL为什么引入redolog的另一个目的。
redolog的两大作用:
-
将脏页数据保存下来,实现事务的持久化。
-
提高读写效率,将MySQL的随机写入转变为顺序写入。
什么时候持久化:后台的进程会每隔一秒将redolog中的日志写入到磁盘中。即使目前事务还没有提交,如果没有提交,会在mysql异常重启之后进行回滚操作、
binlog记录日志
我们前面介绍的undolog和redolog都是InnDB存储引擎层生成的日志。
MySQL在完成一条更新操作后,Server层还会生成一条binlog,等之后事务提交的时候,会将该事务执行过程中产生的所有binlog统一写入binlog文件。
binlog文件记录了所有的数据库表结构变更和表数据修改的日志,不会记录查询类的操作,比如SELECT、SHOW操作。
为什么要有binlog日志,binlog和redolog的区别是什么?
我们先来谈一谈为什么要有binlog日志?
如果我们的数据库是因为磁盘故障或者损坏引起的,这时候可能发生数据丢失。在这种情况下,数据库可能无法正常启动或者无法读取先前持久化的数据。如果数据库中存储了重要的数据,必须进行恢复,这时候通过undolog和redolog都是没有办法恢复的。undolog记录的是当前事务的执行语句的相反操作,只能用于事务的回滚。redolog仅仅记录的是内存中已经更改的数据但是磁盘上未进行更改的数据,随着redolog刷盘条件的达成,redolog中的记录会删除,也就是说,通过redolog只能够恢复部分数据,仅为redolog记录的仅仅是一定范围内的数据,有限。
这时候,我们就想,如果能够一个日志系统,能够对数据库的所有DML语句都记录下来,并且不断地堆积,那该多好啊!这就是MySQL中binlog的作用,用于做数据备份和数据的恢复。
除了数据备份和恢复外,binlog还用于实现主从复制。因为binlog中记录的所有DML语句,如果想要在另一个服务器上复制这一个表,只需要将binlog文件在想要复制的服务器上重新执行一遍即可。
binlog只有在事务提交的时候,才会将binlog日志持久化到本地。
总结:
MySQL当中的三大日志,作用不同,互为补充,提高了数据存储的安全性和一致性。
其中,undolog和redolog用于实现InnoDB存储引擎中事务四大特性的原子性和持久性,保证小范围内的数据一致性。binlog用于实现数据库的全量备份,为数据恢复提供了一种重要的方式,值得注意的是,如果我们想要通过binlog恢复数据库中的所有信息,就需要定期的进行数据备份。因为 mysql仅会保证一定数量的数据文件,如果超过了该数量会将旧值删除。


全生态接入系统技术白皮书)



