ClickHouse语言类似Mysql,如果熟悉Mysql,那么学习ClickHouse的语言还是比较容易上手的。
1、建表语法(CREATE TABLE)
(1)、表引擎(Engine)
- MySQL:
默认使用 InnoDB 引擎,无需显式指定(除非使用其他引擎如 MyISAM)。
CREATE TABLE users (id INT PRIMARY KEY,name VARCHAR(255),created_at DATETIME);
- ClickHouse:
必须显式指定表引擎(如 MergeTree、TinyLog 等),且语法更复杂,支持更多字段特性。
CREATE TABLE users (id UInt32,name String,created_at DateTime) ENGINE = MergeTree()PARTITION BY toYYYYMM(created_at)ORDER BY id;
(2)、字段特性
- MySQL:
支持 PRIMARY KEY、FOREIGN KEY、DEFAULT等,但无 MATERIALIZED 或 ALIAS。
CREATE TABLE orders (order_id INT PRIMARY KEY,user_id INT,amount DECIMAL(10,2) DEFAULT 0.00);
- ClickHouse:
支持 DEFAULT、MATERIALIZED(计算列)、ALIAS(派生列)等。
CREATE TABLE orders (order_id UInt32,user_id UInt32,amount Float64 DEFAULT 0.0,year UInt16 MATERIALIZED toYear(created_at), -- 计算列,持久化存储total_price ALIAS amount * 1.1 -- 派生列,不存储) ENGINE = MergeTree()ORDER BY order_id;
(3)、分区(Partition)
- MySQL:
通过 PARTITION BY 显式定义分区策略:
CREATE TABLE logs (id INT,log_date DATE) PARTITION BY RANGE (YEAR(log_date)) (PARTITION p0 VALUES LESS THAN (2020),PARTITION p1 VALUES LESS THAN (2025));
- ClickHouse:
结合 MergeTree 家族引擎,通过 PARTITION BY 指定分区键(如日期函数):
CREATE TABLE logs (id UInt32,log_date Date) ENGINE = MergeTree()PARTITION BY toYYYYMM(log_date) -- 按年月分区ORDER BY id;
2、增删改查(DML)
(1)、插入数据(INSERT)
- MySQL:
INSERT INTO users (id, name, created_at) VALUES (1, 'Alice', NOW());
- ClickHouse:
支持指定数据格式(如 CSV、JSONEachRow),适合批量导入:
INSERT INTO users (id, name, created_at) VALUES (1, 'Alice', '2024-01-01');
- 或批量插入(性能更高)
INSERT INTO users FORMAT CSV2,Bob,2024-01-023,Charlie,2024-01-03
(2)、查询数据(SELECT)
- MySQL:
支持子查询中的 ORDER BY 和 LIMIT:
SELECT * FROM users WHERE id IN (SELECT id FROM orders WHERE amount > 100 ORDER BY created_at DESC LIMIT 10);
- ClickHouse:
不支持子查询中的 ORDER BY 和 LIMIT(需在外层查询使用):
SELECT * FROM users WHERE id IN (SELECT id FROM orders WHERE amount > 100 -- 无法在此添加 ORDER BY 或 LIMIT);
(3)、更新数据(UPDATE)
- MySQL:
支持灵活的 UPDATE,可结合 WHERE 条件:
UPDATE users SET name = 'Alicia' WHERE id = 1;
- ClickHouse:
性能较差(追加写入模式),需通过 ALTER TABLE … UPDATE:
ALTER TABLE users UPDATE name = 'Alicia' WHERE id = 1;
(4)、删除数据(DELETE)
- MySQL:
支持直接删除:
DELETE FROM users WHERE id = 1;
- ClickHouse:
删除操作性能极低(需合并数据块),使用 ALTER TABLE … DELETE:
ALTER TABLE users DELETE WHERE id = 1;
3、查询特性差异
(1)、聚合函数与窗口函数
- MySQL:
支持标准聚合函数(如 SUM、AVG),但窗口函数(如 ROW_NUMBER())在 MySQL 8.0+ 中才支持。
SELECT user_id, SUM(amount) AS total, ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY created_at) AS rn FROM orders GROUP BY user_id;
- ClickHouse:
内置大量聚合函数(如 MEDIAN、QUANTILE)和窗口函数,并支持 ARRAY 操作:
SELECT user_id, MEDIAN(amount) AS median_amount, arrayJoin([1,2,3]) AS arr_element -- 数组展开FROM orders GROUP BY user_id;
解释:
MEDIAN(amount) 是一个聚合函数,用于计算 amount 列的中位数。
arrayJoin([1,2,3]) 的作用是将数组中的每个元素单独展开成一行,类似展示分组行。
如:

(2)、时间函数
- MySQL:
使用 DATE_FORMAT 格式化日期:
SELECT DATE_FORMAT(created_at, '%Y-%m-%d') AS formatted_date FROM users;
- ClickHouse:
使用 formatDateTime 函数:
SELECT formatDateTime(created_at, '%Y-%m-%d') AS formatted_date FROM users;
4、数据类型差异
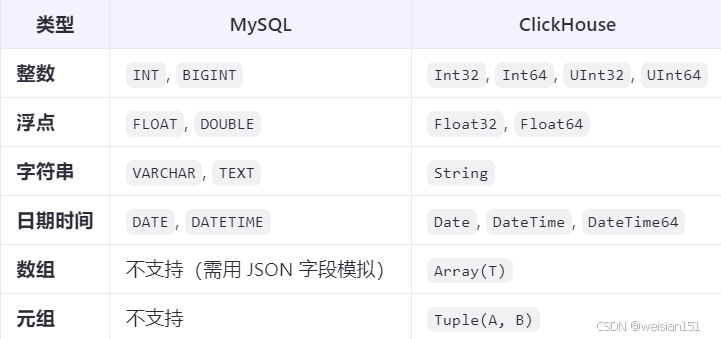
5、索引与查询优化
(1)、索引
- MySQL:
通过 CREATE INDEX 显式创建 B-Tree 索引:
CREATE INDEX idx_user_id ON orders(user_id);
- ClickHouse:
无需显式索引,依赖数据的 排序(ORDER BY) 和 分块(Mark) 优化查询:
– 数据按 user_id 排序,自动优化查询
CREATE TABLE orders ... ORDER BY user_id;
(2)、分布式查询
-
MySQL:
需借助外部工具(如 FederatedX)或分库分表中间件。 -
ClickHouse:
内置分布式表支持,通过 Distributed 引擎协调分片:
CREATE TABLE distributed_orders ENGINE = Distributed('cluster', 'default', 'orders');
6、适用场景总结
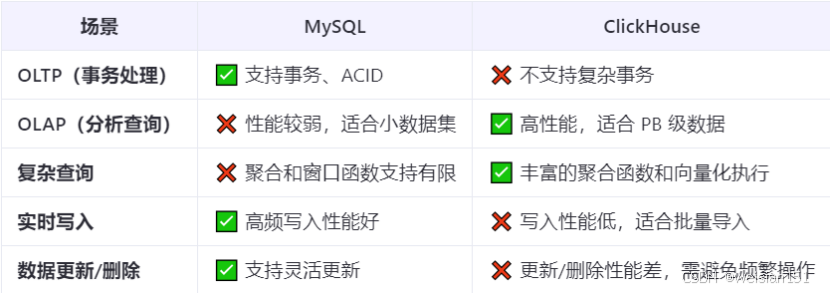
7、示例对比
(1)创建用户表
- MySQL:
CREATE TABLE users (id INT PRIMARY KEY,name VARCHAR(255),created_at DATETIME) ENGINE=InnoDB;
- ClickHouse:
CREATE TABLE users (id UInt32,name String,created_at DateTime) ENGINE = MergeTree()PARTITION BY toYYYYMM(created_at)ORDER BY id;
(2)、查询用户订单的总金额
- MySQL:
SELECT u.name, SUM(o.amount) AS total FROM users u JOIN orders o ON u.id = o.user_id GROUP BY u.name;
- ClickHouse:
SELECT name, SUM(amount) AS total FROM users ANY LEFT JOIN orders USING id GROUP BY name;
8、关键差异总结
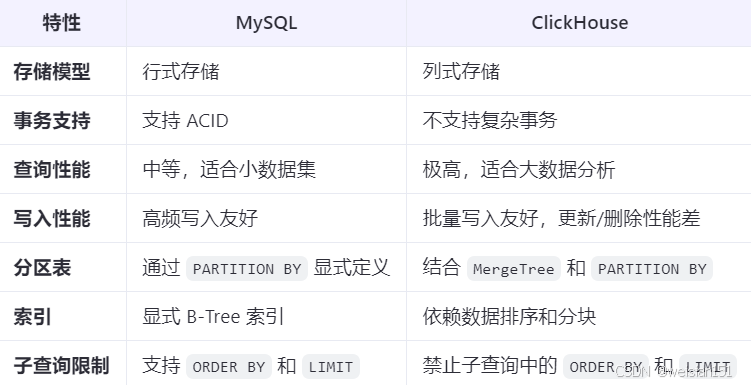
9、选择建议
总的来说,尽管两者都使用SQL作为接口语言,但ClickHouse更侧重于高效的读取和分析大规模数据集的能力,而MySQL则是一个全面的关系型数据库管理系统,更适合事务处理和动态的数据修改。因此,在选择合适的工具时,应根据具体的业务需求来决定。
如:
- 选 MySQL:
需要事务、高并发写入、小数据集的 OLTP 场景(如订单系统)。 - 选 ClickHouse:
需要处理PB级数据、复杂分析查询、读多写少的场景(如日志分析、报表系统)。
逆风翻盘,Dare To Be!!!


)

,源码可白嫖!)