目录
窗口函数:
为何要学习窗口函数,与mysql5.7实现语句对比
现在我们介绍一下窗口函数:
函数规则
1序号函数
2分布函数
3前后函数
5其他函数
总结
窗口函数:
首先数据库的迁移是非常慢的,大家学习新特性的时候要考虑自己公司的数据库版本是不是和自己学习的吻合
为何要学习窗口函数,与mysql5.7实现语句对比
这里先建立一个表:我们看看窗口函数的使用比基础sql的实现优势在哪
CREATE TABLE sales(
id INT PRIMARY KEY AUTO_INCREMENT,
city VARCHAR(15),
county VARCHAR(15),
sales_value DECIMAL
);
INSERT INTO sales(city,county,sales_value)
VALUES
('北京','海淀',10.00),
('北京','朝阳',20.00),
('上海','黄埔',30.00),
('上海','长宁',10.00);
需求是现在计算这个网站在每个城市的销售总额、在全国的销售总额、每个区的销售额占所在城市销售
额中的比率,以及占总销售额中的比率。
创建两个个临时表,总销售额,比率,总比率(是数据库系统中一种特殊类型的表,它只在当前会话或事务期间存在,当会话结束或事务完成后会自动删除。)
CREATE TEMPORARY TABLE a -- 创建临时表
SELECT SUM(sales_value) AS sales_value -- 计算总计金额
FROM sales;
CREATE TEMPORARY TABLE b -- 创建临时表
SELECT city,SUM(sales_value) AS sales_value -- 计算城市销售合计
FROM sales;
SELECT s.city AS 城市,s.county AS 区,s.sales_value AS 区销售额,
b.sales_value AS 市销售额,s.sales_value/b.sales_value AS 市比率,
a.sales_value AS 总销售额,s.sales_value/a.sales_value AS 总比率
FROM sales s
JOIN b ON (s.city=b.city) -- 连接市统计结果临时表
JOIN a -- 连接总计金额临时表
ORDER BY s.city,s.county;
如果我们使用窗口函数可以做到一次性实现这个功能吗,答案是可以的.
需求是现在计算这个网站在每个城市的销售总额、在全国的销售总额、每个区的销售额占所在城市销售
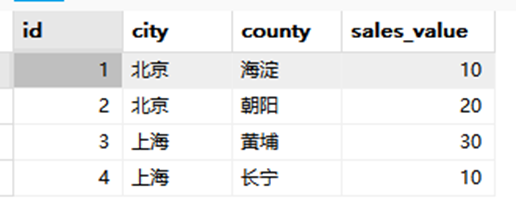
这是我们的表.
#首先是我们的基础表格内容
SELECT sales.*
#第一个是每个城市的销售总额
,sum(sales_value) over(partition by city)
#第二个是在全国的销售总额,这里全部汇总就不需要填写参数.
,sum(sales_value) over()
#第三个是每个区的销售额
,sum(sales_value) over(partition by county)
#第四个是每个区的销售额占城市的占比
,sales_value/sum(sales_value) over(partition by city) as ‘区占比’
#第四个是每个区的销售额占全国的占比
,sales_value/sum(sales_value) over() as ‘全国占比’
#最后表来源
FROM sales

现在我们介绍一下窗口函数:
窗口函数就是group by的另一种形式,group by是分组后放在一条记录上,而窗口函数就是分类后把这些记录都保留下来在每一条记录后面
窗口函数介于单行函数和分组函数之间,单行函数不会把数据库进行一个分类,分组函数会把数据进行一个分类然后聚合为一条,窗口函数会把数据进行一个分类,
比如我想计算每个人的工资和部门最大工资的差值,那么我们就可以对部门工资进行分类,各自部门排序,然后使用窗口函数选择最后一个,,再用它减去公司的值,就可以达到差值的效果
只分类,只计算,不聚合记录,记录条数不变
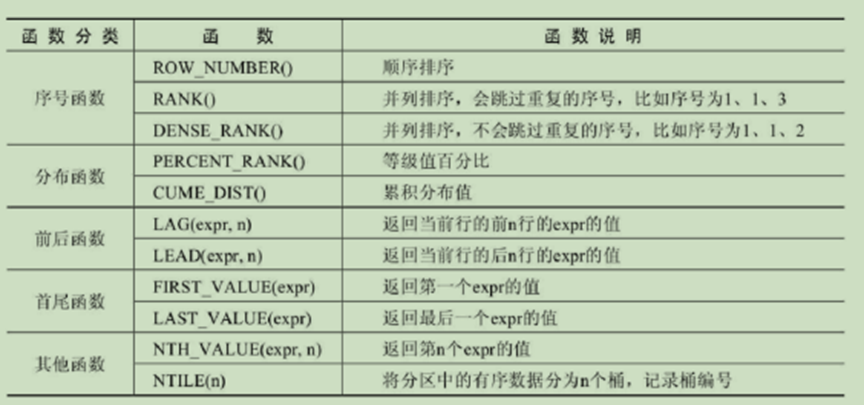
函数规则
函数 OVER([PARTITION BY 字段名 ORDER BY 字段名 ASC|DESC])
函数 OVER 窗口名 … WINDOW 窗口名 AS ([PARTITION BY 字段名 ORDER BY 字段名 ASC|DESC])
1序号函数
1.1row_number()函数
#查询 goods 数据表中每个商品分类下价格降序排列的各个商品信息。
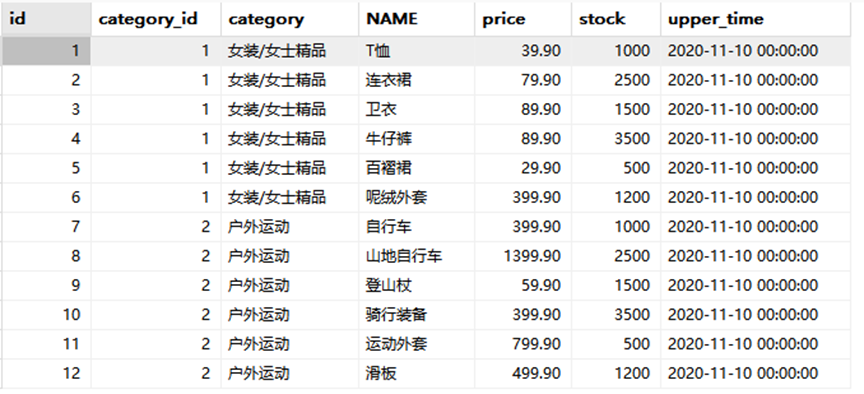
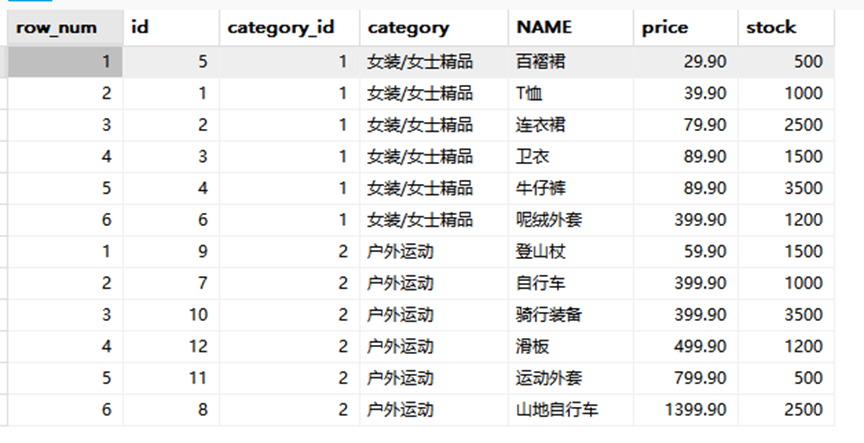
#这里要根据商品分类然后进行价格降序,单行函数不能分类,聚合函数不能分类后单独排序所以使用窗口函数中的排序函数,ROW_NUMBER(这里根据实际情况决定使用rank,还是dense_rank),函数即使没有参数也要记得加括号
SELECT ROW_NUMBER() OVER(PARTITION BY category ORDER BY price) AS row_number
#保留原表需要的字段
,id, category_id, category, NAME, price, stock
FROM goods;
结果如下
#查询 goods 数据表中每个商品分类下价格最高的3种商品信息。因为这里的排序要用到新表
#这里由于需要只选择3种商品,所以我们先按商品价格进行排序,建立rownum字段之后的新表,在新表中把字段rownum进行筛选就可以.
SELECT * FROM (
#建立一个子查询表
SELECT ROW_NUMBER() OVER(PARTITION BY category ORDER BY price desc) AS
row_num,
id, category_id, category, NAME, price, stock
FROM goods) t#要给表命名,不然不能from
WHERE row_num >=3
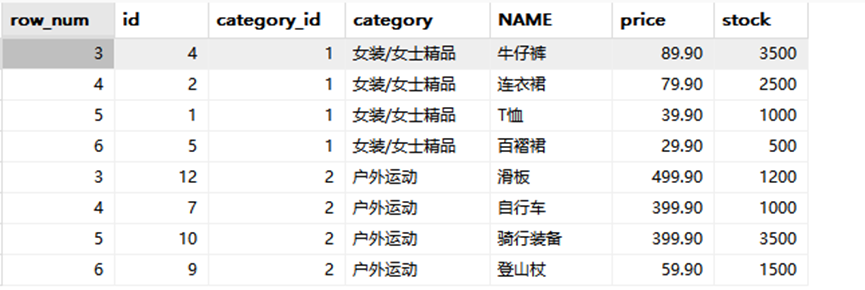
RANK()函数,使用RANK()函数能够对序号进行并列排序,并且会跳过重复的序号,比如序号为1、1、3。
SELECT RANK() OVER(PARTITION BY category_id ORDER BY price DESC) AS#PARTITION BY
row_num,id, category_id, category, NAME, price, stock
FROM goods;
#DENSE_RANK()函数DENSE_RANK()函数对序号进行并列排序,并且不会跳过重复的序号,比如序号为1、1、2。
举例:使用DENSE_RANK()函数获取 goods 数据表中各类别的价格从高到低排序的各商品信息。
SELECT DENSE_RANK() OVER(PARTITION BY category_id ORDER BY price DESC) AS#PARTITION BY
row_num,id, category_id, category, NAME, price, stock
FROM goods;
2分布函数
2.1.PERCENT_RANK()函数
SELECT RANK() OVER w AS r,
-> PERCENT_RANK() OVER w AS pr,
-> id, category_id, category, NAME, price, stock
-> FROM goods
-> WHERE category_id = 1 WINDOW w AS (PARTITION BY category_id ORDER BY price
DESC);
+---+---
(rank - 1) / (rows - 1)
PERCENT_RANK()可以计算百分比,
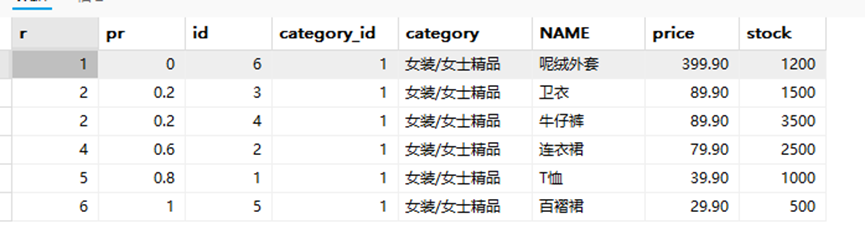
第一个就是1-1除以总行数减1以此类推
2.2CUME_DUST
主要用于查询小于或等于某个值的比例。
举例:查询goods数据表中小于或等于当前价格的比例
SELECT CUME_DIST() OVER(PARTITION BY category_id ORDER BY price ASC) AS cd,
id, category, NAME, price
FROM goods;
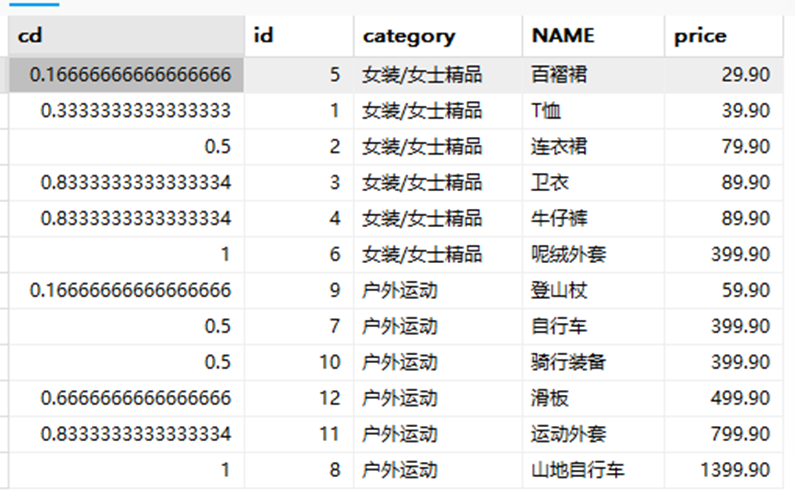
小于各个价格的比例是多少.P(x<=p)
3前后函数
3.1LAG(expr,n)函数
LAG(expr,n)函数返回当前行的前n行的expr的值。
举例:查询goods数据表中前一个商品价格与当前商品价格的差值。
SELECT id, category, NAME, price, pre_price, price - pre_price AS diff_price
FROM (
SELECT id, category, NAME, price,LAG(price,1) OVER w AS pre_price
FROM goods
WINDOW w AS (PARTITION BY category_id ORDER BY price)) t;
2.LEAD(expr,n)函数
LEAD(expr,n)函数返回当前行的后n行的expr的值。
举例:查询goods数据表中后一个商品价格与当前商品价格的差值。
12 rows in set (0.00 sec)
SELECT id, category, NAME, behind_price, price,behind_price - price AS
diff_price
FROM(
SELECT id, category, NAME, price,LEAD(price, 1) OVER w AS behind_price
FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price)) t;
4首尾函数
4.1FIRST_VALUE(expr)函数返回第一个expr的值。expr代表字段
SELECT id, category, NAME, price, stock,FIRST_VALUE(price) OVER w AS
first_price
FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price);
取最小值,最大值都可以,看你要使用asc,还是desc
4.2LAST_VALUE
5其他函数
5.1NTH_VALUE(expr,n)函数
NTH_VALUE(expr,n)函数返回第n个expr的值。
举例:查询goods数据表中排名第2和第3的价格信息。
SELECT id, category, NAME, price,NTH_VALUE(price,2) OVER w AS second_price,
NTH_VALUE(price,3) OVER w AS third_price
FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price);
NTILE(n)函数NTILE(n)函数将分区中的有序数据分为n个桶,记录桶编号。
SELECT NTILE(3) OVER w AS nt,id, category, NAME, price
-> FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price)
把数据根据你设定的顺序来分为几个组.
总结
窗口函数的特点是可以分组,而且可以在分组内排序。另外,窗口函数不会因为分组而减少原表中的行数,这对我们在原表数据的基础上进行统计和排序非常有用。


)


