使用PaddleHub完成国庆祝福
祝福国家繁荣
本项目作为示例演示项目,用于体验飞桨平台的高效与便利。
各部分详细内容请点击相应链接学习
数据介绍
数据集收集自网络,包括100条国庆祝福。数据以txt形式提供,一条数据为一行。
国庆佳节,愿你与家人共度温馨时光,幸福常伴左右。祝愿我们的祖国更加繁荣昌盛,生活更加美好!国庆节到了,愿你放下工作的压力,享受生活的美好。愿祖国的每一寸土地都充满阳光,愿你的每一天都洋溢着欢乐!值此国庆佳节,愿你与家人欢聚一堂,分享快乐时光。愿祖国在新的时代里蒸蒸日上,愿你的人生如繁花似锦,未来一片光明!在这普天同庆的日子里,愿你心中有爱,眼中有光,生活里充满了无尽的希望和美好。愿祖国更加繁荣昌盛,愿你的人生越走越宽!国庆节到了,愿你在假期里放松身心,享受快乐。愿我们伟大的祖国更加富强,人民的生活更加幸福美满!值此国庆佳节,愿你与亲朋好友共度美好时光,享受宁静与安逸。愿祖国的未来如旭日初升,光芒四射,愿你的人生道路充满希望与成功!在这举国欢庆的日子里,愿你与家人共享天伦之乐,愿幸福与健康常伴左右。祝祖国繁荣昌盛,人民安居乐业,国泰民安!国庆节到来,愿你抛开一切烦恼,放松身心,享受生活中的美好时光。愿祖国更加富强,愿你未来的每一步都充满阳光!国庆佳节,愿你与亲友共度美好时光,享受假期的放松与惬意。愿祖国的每一个角落都充满生机,愿你的生活充满欢声笑语!在这国庆佳节,愿你心怀感恩,感受生活的美好与幸福。愿祖国繁荣昌盛,愿你的人生如星空般璀璨夺目!国庆节到了,愿你与家人共度美好时光,感受节日的喜庆气氛。愿祖国繁荣昌盛,愿你的未来充满希望与幸福!
飞桨平台介绍
飞桨(PaddlePaddle)是集深度学习核心框架、工具组件和服务平台为一体的技术先进、功能完备的开源深度学习平台,已被中国企业广泛使用,深度契合企业应用需求,拥有活跃的开发者社区生态。
-
作为深度学习的一站式供应商,百度飞桨提供了从入门资料及数据集,到模型训练算力再到模型落地部署。你可以从零基础开始,通过学习飞桨上的课程及项目,在手机上部署一个人脸识别的系统。
-
飞桨提供了在线的编程环境NOTEBOOK和V100算力,只需要一台能上网的电脑,立刻就能开始深度学习之旅。
-
PaddlePaddle是国产自研的深度学习框架,而且语法已经与PyTorch,TensorFlow2高度类似,短时间内能快速上手。
-
在飞桨(PaddlePaddle)平台向优秀项目的开发者提供算力,专家指导甚至落地必需的资金支持,适合有好的想法但不知道如何实现的开发者。
PaddleHub介绍
便捷地获取PaddlePaddle生态下的预训练模型,完成模型的管理和一键预测。配合使用Fine-tune API,可以基于大规模预训练模型快速完成迁移学习,让预训练模型能更好地服务于用户特定场景的应用。
-
基于优秀的社区生态和持续的投入,飞桨(PaddlePaddle)已经有一批可以直接调用的模型,可以快速实现想法。
-
这些模型被根据不同方向存在不同的套件中,例如:基于NLP的PaddleNLP,基于GAN的PaddleGAN等
PaddleHub
ERNIE-GEN 介绍
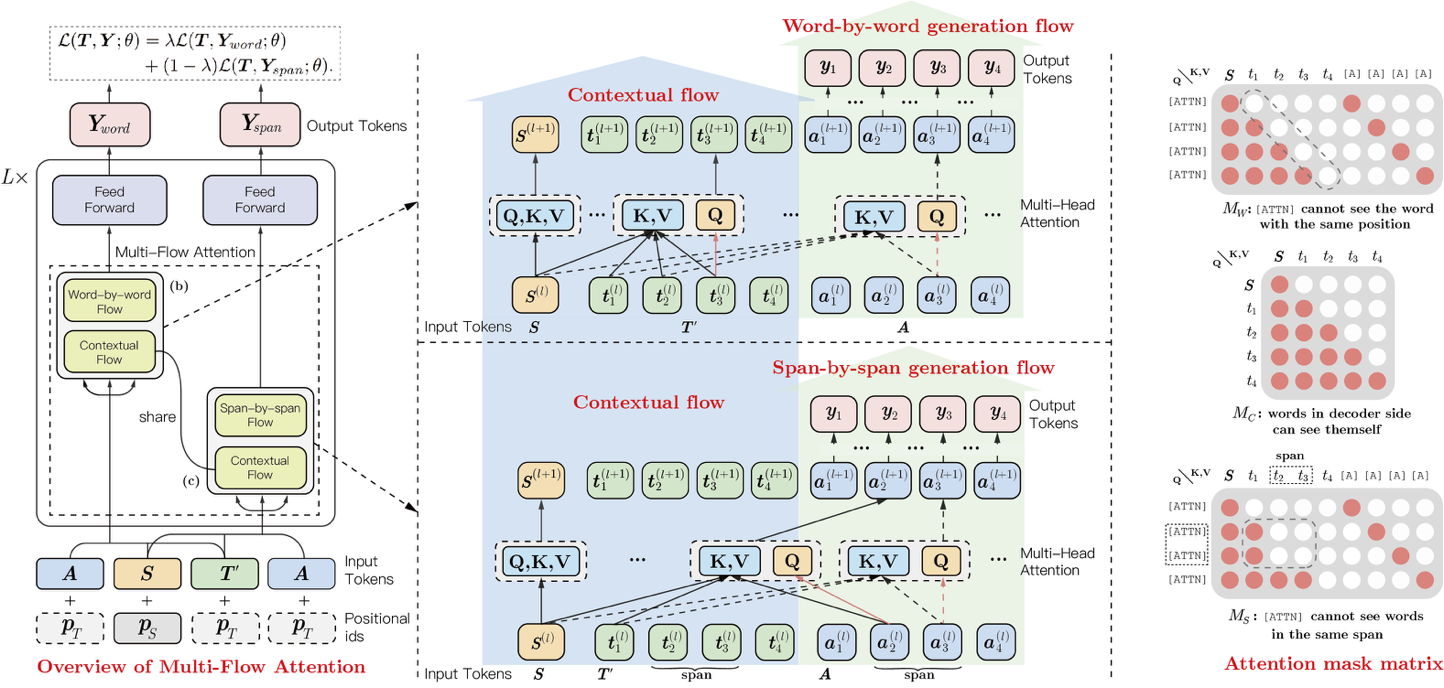
ERNIE-GEN 是面向生成任务的预训练-微调框架,首次在预训练阶段加入span-by-span 生成任务,让模型每次能够生成一个语义完整的片段。在预训练和微调中通过填充式生成机制和噪声感知机制来缓解曝光偏差问题。
此外, ERNIE-GEN 采样多片段-多粒度目标文本采样策略, 增强源文本和目标文本的关联性,加强了编码器和解码器的交互。ernie_gen module是一个具备微调功能的module,可以快速完成特定场景module的制作。
def finetune(train_path,dev_path=None,save_dir="ernie_gen_result",init_ckpt_path=None,use_gpu=True,max_steps=500,batch_size=8,max_encode_len=15,max_decode_len=15,learning_rate=5e-5,warmup_proportion=0.1,weight_decay=0.1,noise_prob=0,label_smooth=0,beam_width=5,length_penalty=1.0,log_interval=100,save_interval=200,
):
| API | 参数 |
|---|---|
| train_path(str): | 训练集路径。训练集的格式应为:“序号\t输入文本\t标签”,例如:“1\t床前明月光\t疑是地上霜” |
| dev_path(str): | 验证集路径。验证集的格式应为:“序号\t输入文本\t标签”,例如:“1\t举头望明月\t低头思故乡” |
| save_dir(str): | 模型保存以及验证集预测输出路径。 |
| init_ckpt_path(str): | 模型初始化加载路径,可实现增量训练。 |
| use_gpu(bool): | 是否使用GPU。 |
| max_steps(int): | 最大训练步数。 |
| batch_size(int): | 训练时的batch大小。 |
| max_encode_len(int): | 最长编码长度。 |
| max_decode_len(int): | 最长解码长度。 |
| learning_rate(float): | 学习率大小。 |
| warmup_proportion(float): | 学习率warmup比例。 |
| weight_decay(float): | 权值衰减大小。 |
| noise_prob(float): | 噪声概率,详见ernie gen论文。 |
| label_smooth(float): | 标签平滑权重。 |
| beam_width(int): | 验证集预测时的beam大小。 |
| length_penalty(float): | 验证集预测时的长度惩罚权重。 |
| log_interval(int): | 训练时的日志打印间隔步数。 |
| save_interval(int): | 训练时的模型保存间隔部署。验证集将在模型保存完毕后进行预测。 |
PaddleHub-ERNIE-GEN
ERNIE-GEN: An Enhanced Multi-Flow Pre-training and Fine-tuning Framework for Natural Language Generation
项目实现
-
准备数据集
-
关键词提取
-
安装ernie_gen模型并训练
-
模型推理
# 安装jieba_paddle
!hub install jieba_paddle==1.0.0
!pip install --upgrade paddlehub -i https://pypi.tuna.tsinghua.edu.cn/simple
!hub install jieba_paddle
准备数据集
输入准备好的数据集并查看数据集长度分布
# 读入数据
import pandas as pd
data_ori = pd.read_table("/home/aistudio/国庆节祝福.txt",header=None)
print(data_ori.head(5)) # 查看前五行
!pip install seaborn
# 查看数据的长度分布
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
len_list = []
for i in range(len(data_ori)):temp_data = data_ori.iloc[i,0]len_list.append(len(temp_data))import seaborn as sns
import matplotlib.pyplot as pltplt.figure(figsize=(5,5))
sns.distplot(len_list)
plt.show()
关键词提取
使用jieba_paddle 进行处理
该Module是jieba使用PaddlePaddle深度学习框架搭建的切词网络(双向GRU)。
同时也支持jieba的传统切词方法,如精确模式、全模式、搜索引擎模式等切词模式,使用方法和jieba保持一致。 更多信息参考:jieba
本项目需要的输入为:标签 + 文本,由于数据集不包括标签,因此使用关键词提取算法生成标签。
本项目使用的两种关键词提取方法如下:
-
textrank 方法
基于 TextRank 算法的关键词抽取
- 参数
sentence(str): 待提取的文本
topK(int): 返回几个 TF/IDF 权重最大的关键词,默认值为 20
withWeight(bool): 为是否一并返回关键词权重值,默认值为 False
allowPOS(tuple): 仅包括指定词性的词,默认值为(‘ns’, ‘n’, ‘vn’, ‘v’)
- 返回
results(list): 关键词结果
-
extract_tags 方法
基于 TF-IDF 算法的关键词抽取
- 参数
sentence(str): 待提取的文本
topK(int): 返回几个 TF/IDF 权重最大的关键词,默认值为 20
withWeight(bool): 为是否一并返回关键词权重值,默认值为 False
allowPOS(tuple): 仅包括指定词性的词,默认值为空,即不筛选
- 返回
results(list): 关键词结果
jieba_paddle
## 关键词提取
import paddlehub as hub
module = hub.Module(name="jieba_paddle")
# extract_tags 方法提取
with open(f'data/extract_tags.txt', 'w') as f:for i in range(len(data_ori)):temp_data = data_ori.iloc[i,0]results = module.extract_tags(sentence=temp_data,topK=1,withWeight=False,allowPOS=())if results:f.write(f'{i}\t{results[0]}\t{temp_data}\r\n')# textrank 方法提取
with open(f'data/textrank.txt', 'w') as f:for i in range(len(data_ori)):temp_data = data_ori.iloc[i,0]results = module.textrank(sentence=temp_data,topK=1,withWeight=False,allowPOS=('ns', 'n', 'vn', 'v'))if results:f.write(f'{i}\t{results[0]}\t{temp_data}\r\n')
安装ernie_gen模型并训练
安装最新ernie_gen模型,并设置使用序号为0的GPU进行训练。最后导出为HUB模型
# 安装ernie_gen模型,设置GPU
!hub install ernie_gen==1.1.0
!export CUDA_VISIBLE_DEVICES=0
#开始训练
# 训练时长约40min
module = hub.Module(name="ernie_gen")
fiction_name = 'junxun'
result = module.finetune(train_path=f'data/textrank.txt',save_dir=f'save_model',init_ckpt_path=None,use_gpu=True,max_steps=4000,batch_size=16,max_encode_len=10,max_decode_len=200,learning_rate=5e-5,warmup_proportion=0.1,noise_prob=0.2,label_smooth=0,beam_width=5,length_penalty=1.0,log_interval=100,save_interval=2000,
)print(result)
模型推理
安装已经训练完成并导出的模型,设置GPU后进行预测。通过test_texts输入预测关键词
默认预测关键词为:军训
# 安装模型
!hub install ernie_gen_textrank
!export CUDA_VISIBLE_DEVICES=0
# 开始预测
import paddlehub as hub
module = hub.Module(name='ernie_gen_textrank')
test_texts = ['军训']
results = module.generate(texts=test_texts, # 输入的关键词use_gpu=True, # 是否使用GPUbeam_width=4 # 输出的前N个答案
)for result in results[0]:print(result)
总结
-
本项目对基于飞桨2.1.2版本的PaddleHub的ERNIE-GEN模型进行了演示
-
作为演示项目,整个项目运行时间约1H,帮助大家感受深度学习的魅力
如果后续需要进行其他类型文本的生成,可以根据本项目数据集简单修改实现。






)